Deploy and configure unstructured clinical notes enrichment (preview) in healthcare data solutions
[This article is prerelease documentation and is subject to change.]
Note
This content is currently being updated.
Unstructured clinical notes enrichment (preview) uses Azure AI Language's Text Analytics for health service to extract and add structure to unstructured clinical notes for analytics. You can deploy and configure the capability after deploying healthcare data solutions to your Fabric workspace and the healthcare data foundations capability.
Unstructured clinical notes enrichment (preview) is an optional capability under healthcare data solutions in Microsoft Fabric. You have the flexibility to decide whether or not to use it, depending on your specific needs or scenarios.
Prerequisites
- Deploy healthcare data solutions in Microsoft Fabric.
- Install the foundational notebooks and pipelines in Deploy healthcare data foundations.
Set up Azure Language service
Go to the Azure portal.
On the home page, select Create a resource, search for Resource group, and create a new Azure resource group.
Make sure you have the Azure role-based access control (RBAC) Owner or User Access Administrator role on the resource group. To assign the permissions, follow the steps in Grant access.
After creating the resource group, go back to the home page, select Create a resource, search for Language service, and deploy a new Azure Language service to your resource group. Use the default setup settings.
Important
Deploying the language service requires you to accept the Responsible AI Notice terms in the Azure portal. Make sure you review these terms when adding the language service to your resource group. For more information, see the following transparency notes:
Deploy unstructured clinical notes enrichment (preview)
You can deploy the capability using the setup module explained in Healthcare data solutions: Deploy healthcare data foundations. In the settings page, provide the Azure Key Vault value to link the data in your key vault.
If you didn't use the setup module to deploy the capability and want to use the capability tile instead, follow these steps:
Go to the healthcare data solutions home page on Fabric.
Select the unstructured clinical notes enrichment (preview) tile.
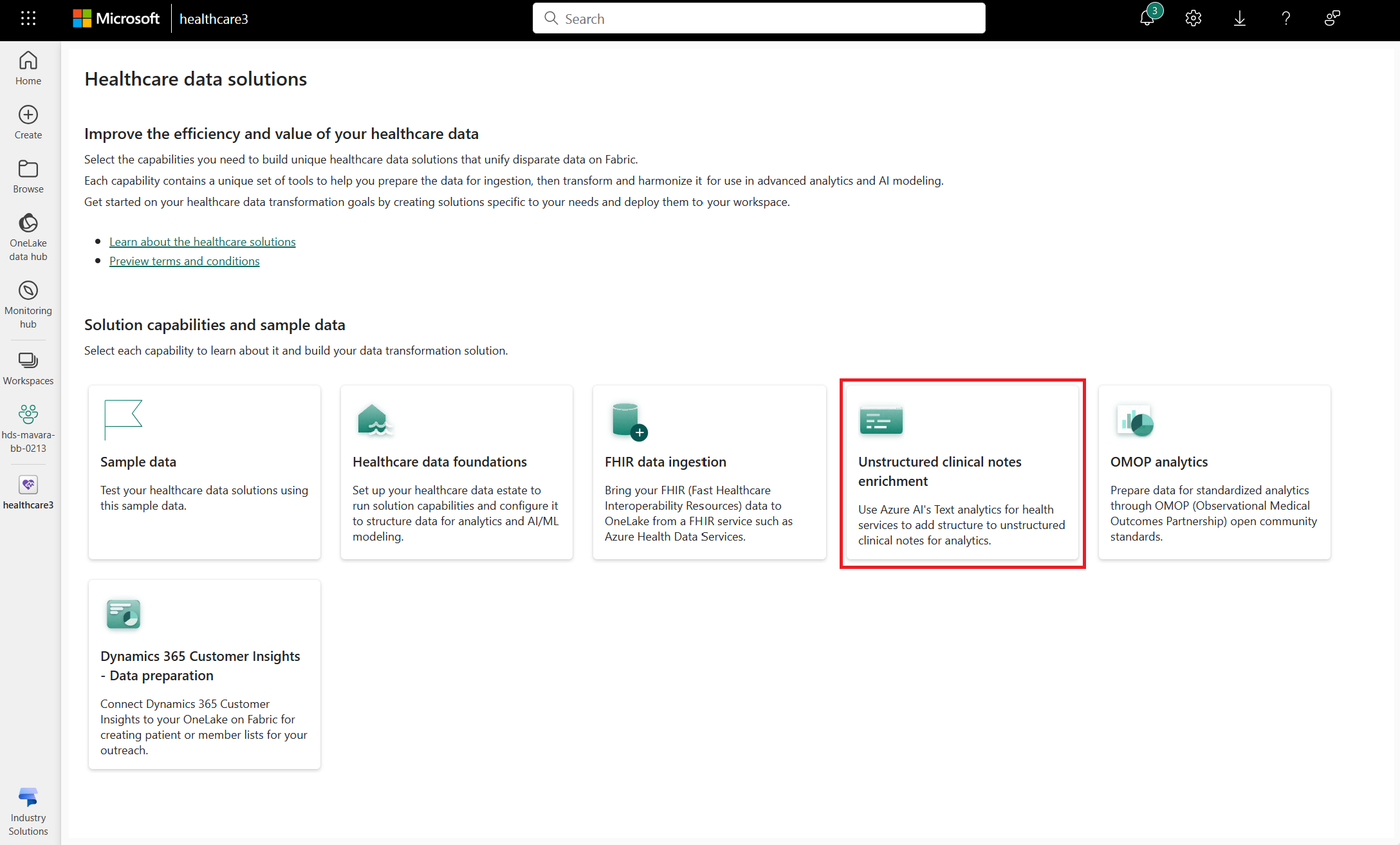
On the capability page, select Deploy to workspace.
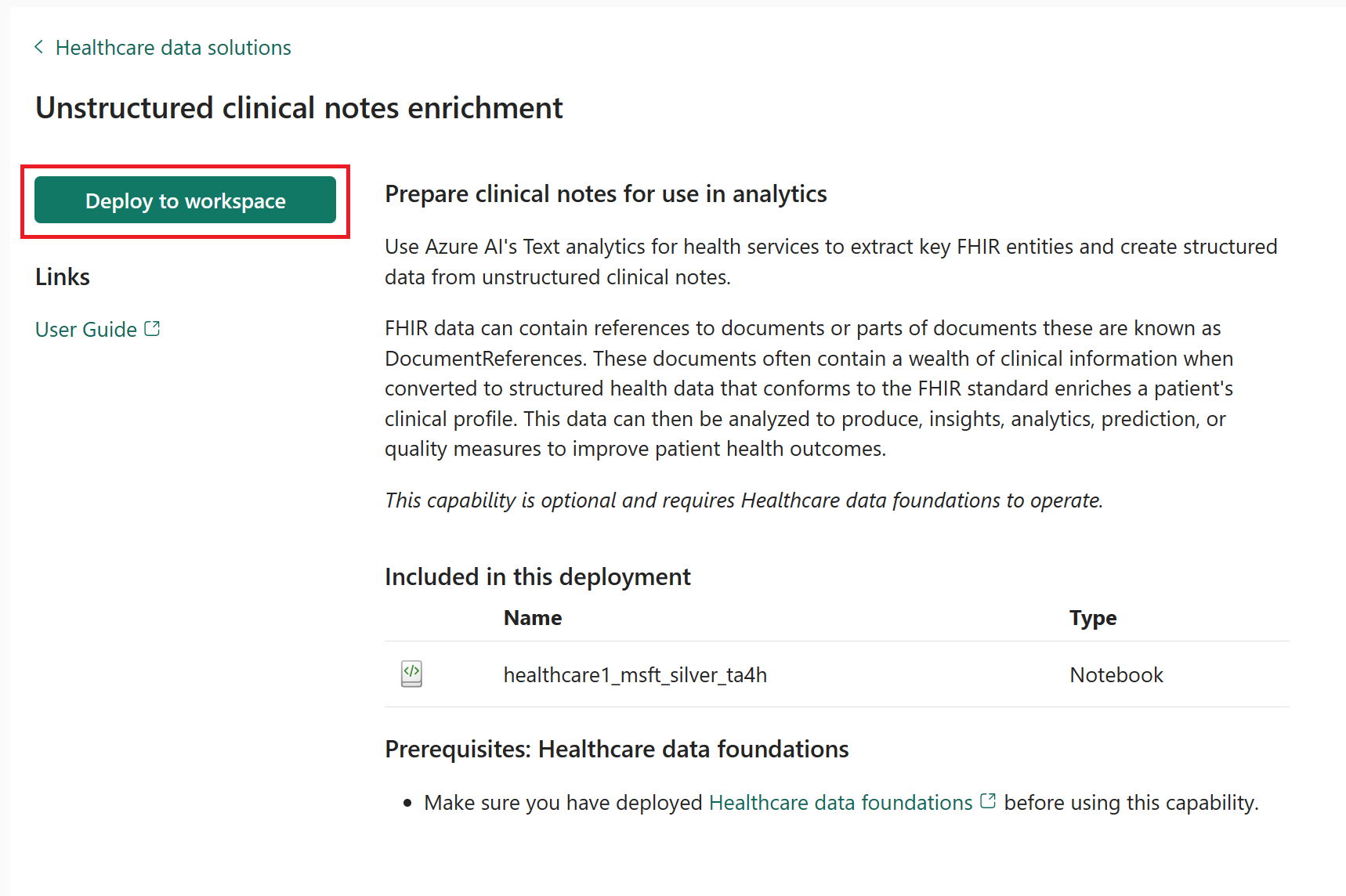
The deployment can take a few minutes to complete. Don't close the tab or the browser while deployment is in progress. While you wait, you can work in another tab.
After the deployment completes, you can see a notification on the message bar.
Select Manage capability from the message bar to go to the Capability management page.
Here, you can view, configure, and manage the artifacts deployed with the capability.


Artifacts
The capability installs a notebook and a data pipeline in your healthcare data solutions environment.
| Artifact | Type | Description |
|---|---|---|
| healthcare#_msft_ta4h_silver_ingestion | Notebook | Uses the Azure Text Analytics for health NLP API to process and analyze unstructured text data. |
| healthcare#_msft_clinical_notes_enrichment | Data pipeline | Sequentially runs a series of notebooks to extract key Fast Healthcare Interoperability Resources (FHIR) entities from unstructured clinical notes, structure the data, and store the results in the silver lakehouse. |
Review the notebook configuration
The healthcare#_msft_ta4h_silver_ingestion notebook runs the NLPIngestionService module in the healthcare data solutions library and uses the Azure Text Analytics for health service. This service is a natural language processing (NLP) API to process and analyze unstructured text data. The results are stored in the healthcare#_msft_silver lakehouse.
Following are the key configuration parameters of this notebook:
NLP Config: Lets you customize the NLP settings to align with specific user requirements.
enable_text_analytics_logs: Toggle the value toTrueorFalsefor activating or deactivating the API logs. The default value is set toFalse. To learn more about how to enable logging, see Enable logs.nlp_source_table_name: Identifies the source table for the Text Analytics for health service to process.nlp_document_limit: Sets the limit on the number of documents that the Text Analytics for health service can process. The default value is set to10, with a maximum fallback of 1,000 documents. You can adjust this value as needed. However, keep the cost implications in mind, as explained in Pricing model.
This notebook deploys with preconfigured values required to run the associated data pipeline. Some configuration parameters inherit from the global configuration. By default, you aren't expected to make any changes to the notebook configuration files. If needed, you can open the notebook and review the configuration.