Přehled typů modelů v Microsoft Syntex
Platí pro: ✓ Všechny vlastní modely | ✓ Všechny předem připravené modely
Porozumění obsahu v Microsoft Syntex začíná modely zpracování dokumentů. Modely zpracování dokumentů umožňují identifikovat a klasifikovat dokumenty nahrané do knihoven dokumentů SharePointu a pak extrahovat potřebné informace z každého souboru.
Při použití na knihovnu dokumentů SharePointu je model přidružený k typu obsahu a obsahuje sloupce pro uložení extrahovaných informací. Typ obsahu, který vytvoříte, je uložený v galerii typů obsahu SharePointu. Můžete se také rozhodnout použít existující typy obsahu k použití jejich schématu.
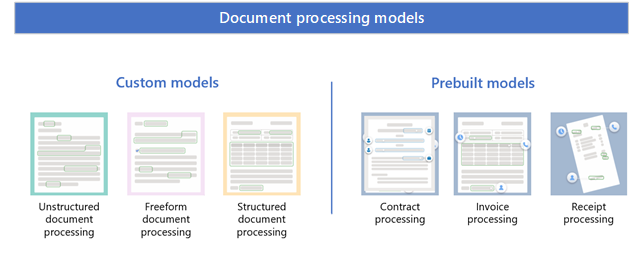
Syntex používá vlastní modely a předem připravené modely.
Modely můžou být buď podnikové modely vytvořené v centru obsahu, nebo místní modely vytvořené na místním sharepointovém webu.
Vlastní modely
Typ vlastního modelu, který zvolíte, bude záviset na typech souborů, které použijete, na formátu a struktuře souborů a na tom, kde chcete model použít.
Mezi vlastní modely patří:
- Nestrukturované zpracování dokumentů
- Zpracování dokumentů ve volném formátu
- Strukturované zpracování dokumentů
Pokud chcete zobrazit rozdíly vedle sebe ve vlastních modelech, přečtěte si téma Porovnání vlastních modelů.
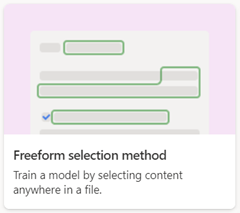
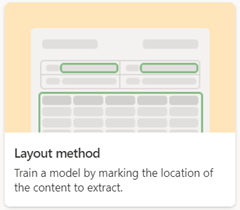
Při vytváření vlastního modelu vyberete metodu trénování přidruženou k danému typu modelu. Pokud například chcete vytvořit nestrukturovaný model zpracování dokumentů, na stránce Možnosti pro vytvoření modelu , kde vytvoříte model, zvolíte možnost Metoda výuky . Následující tabulka ukazuje metodu trénování přidruženou k jednotlivým vlastním typům modelu.
| Nestrukturované zpracování dokumentů |
Volný tvar zpracování dokumentů |
Strukturované zpracování dokumentů |
|---|---|---|
 |
 |
 |
Poznámka
Chcete-li uživatelům zpřístupnit metodu volného výběru a možnosti metody rozložení, musí být nejprve nakonfigurovány v Centrum pro správu Microsoftu 365.
Nestrukturované zpracování dokumentů
Pomocí modelu nestrukturovaného zpracování dokumentů můžete automaticky klasifikovat dokumenty a extrahovat z nich informace. Nejlépe funguje s nestrukturovanými dokumenty, jako jsou dopisy nebo kontrakty. Tyto dokumenty musí obsahovat text, který lze identifikovat na základě frází nebo vzorů. Identifikovaný text označuje jak typ souboru (jeho klasifikaci), tak to, co chcete extrahovat (jeho extrahovací moduly).
Nestrukturovaný dokument může být například dopisem o prodloužení smlouvy, který může být napsán různými způsoby. Informace však existují konzistentně v textu každého dokumentu o prodloužení platnosti smlouvy, například textový řetězec "Datum zahájení služby" následovaný skutečným datem.
Tento typ modelu podporuje nejširší škálu typů souborů a podporuje více než 40 jazyků.
Při vytváření nestrukturovaného modelu zpracování dokumentů použijte možnost Metoda Výuky .
Další informace najdete v tématu Přehled nestrukturovaného zpracování dokumentů.
Zpracování dokumentů ve volném formátu
Pomocí modelu zpracování dokumentů volného formátu můžete automaticky extrahovat informace z nestrukturovaných a volných dokumentů, jako jsou dopisy a kontrakty, kde se informace můžou zobrazit kdekoli v dokumentu.
Modely bezplatného zpracování dokumentů používají Microsoft Power Apps AI Builder k vytváření a trénování modelů v rámci syntexu.
Poznámka
Model pro zpracování dokumentů s volným formulářem ještě není v některých oblastech k dispozici. Další informace najdete v tématu Dostupnost funkcí podle oblastí.
Vzhledem k tomu, že vaše organizace dostává dopisy a dokumenty ve velkém množství z různých zdrojů, jako je pošta, fax a e-mail, může zpracování těchto dokumentů a jejich ruční zadávání do databáze trvat poměrně dlouho. Tento model tento proces automatizuje pomocí AI k extrahování textu a dalších informací z těchto dokumentů.
Tento typ modelu je nejlepší volbou pro dokumenty v pdf nebo obrázkových souborech, pokud nevyžadujete automatickou klasifikaci typu dokumentu a podporuje více než 40 jazyků.
Při vytváření modelu pro zpracování dokumentů volného formuláře použijte možnost Volný formulář pro výběr .
Další informace najdete v tématu Přehled strukturovaného a volného zpracování dokumentů.
Strukturované zpracování dokumentů
Pomocí modelu strukturovaného zpracování dokumentů můžete automaticky identifikovat hodnoty polí a tabulek. Nejvhodnější je pro strukturované nebo částečně strukturované dokumenty, jako jsou formuláře a faktury.
Modely strukturovaného zpracování dokumentů používají zpracování dokumentů Microsoft Power Apps AI Builder (dříve označované jako zpracování formulářů) k vytváření a trénování modelů v rámci syntexu.
Tento typ modelu podporuje nejširší škálu jazyků a je vytrénován tak, aby porozuměl rozložení formuláře z ukázkových dokumentů, a pak se naučí hledat data, která potřebujete extrahovat z podobných umístění. Formuláře mají obvykle strukturovanější rozložení, kde jsou entity ve stejném umístění (například číslo sociálního pojištění na daňovém formuláři).
Při vytváření modelu strukturovaného zpracování dokumentů použijte možnost Metoda rozložení .
Další informace najdete v tématu Přehled strukturovaného a volného zpracování dokumentů.
Předem připravené modely
Pokud nepotřebujete vytvářet vlastní model, můžete použít předem připravený model zpracování dokumentů , který už byl natrénovaný pro konkrétní strukturované dokumenty.
Mezi předem připravené modely patří:
Předem připravené modely jsou předem natrénované k rozpoznávání dokumentů a strukturovaných informací v dokumentech. Nemusíte vytvářet nový vlastní model úplně od začátku, ale můžete iterovat stávající předem vytrénovaný model a přidat konkrétní pole, která vyhovují potřebám vaší organizace.
Zpracování smlouvy
Model zpracování kontraktu analyzuje a extrahuje klíčové informace z dokumentů kontraktů. Rozhraní API analyzuje kontrakty v různých formátech a extrahuje informace o klíčových kontraktech, jako je název klienta nebo strany, fakturační adresa, jurisdikce a datum vypršení platnosti.
Další informace o předem připravených modelech zpracování kontraktů najdete v tématu Použití předem připraveného modelu k extrakci informací z kontraktů.
Zpracování faktur
Model zpracování faktur analyzuje a extrahuje klíčové informace z prodejních faktur. Rozhraní API analyzuje faktury v různých formátech a extrahuje klíčové informace o faktuře, jako je jméno zákazníka, fakturační adresa, datum splatnosti a splatná částka.
Další informace o předem připravených modelech zpracování faktur najdete v tématu Použití předem připraveného modelu k extrakci informací z faktur.
Zpracování příjmu
Předem připravený model zpracování účtenek analyzuje a extrahuje klíčové informace z prodejních tržeb. Rozhraní API analyzuje tištěné a ručně psané účtenky a extrahuje klíčové informace o účtenkách, jako je jméno obchodníka, telefonní číslo obchodníka, datum transakce, daň a celkový počet transakcí.
Další informace o předem připravených modelech zpracování účtenek najdete v tématu Použití předem připraveného modelu k extrakci informací z účtenek.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro