Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro: ✓ Nestrukturované zpracování dokumentů
Vysvětlení pomáhají definovat informace, které chcete v nestrukturovaných modelech zpracování dokumentů v Microsoft Syntex označit a extrahovat. Když vytváříte vysvětlení, musíte vybrat typ vysvětlení. Tento článek vám pomůže pochopit různé typy vysvětlení a jejich použití.
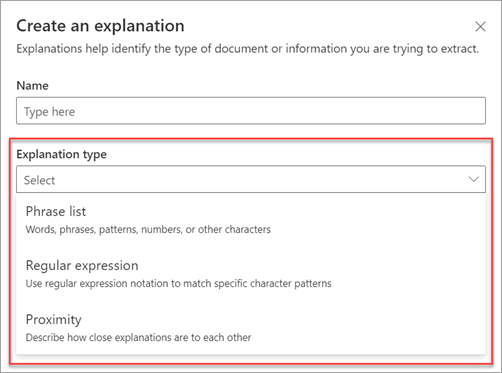
K dispozici jsou tyto typy vysvětlení:
Seznam frází: Seznam slov, frází, čísel nebo jiných znaků, které můžete použít v dokumentu nebo extrahovaných informacích. Například textový řetězec , který odkazuje na lékaře , je ve všech dokumentech, které identifikujete. Nebo telefonní číslo referenčního lékaře ze všech dokumentů se zdravotním doporučením, které identifikujete.
Regulární výraz: Používá zápis odpovídající vzorům k vyhledání konkrétních vzorů znaků. Regulární výraz můžete například použít k vyhledání všech instancí vzoru e-mailové adresy v sadě dokumentů.
Blízkost: Popisuje, jak blízko jsou vysvětlení k sobě navzájem. Například seznam frází číselných čísel je přímo před seznamem frází názvu ulice , mezi kterými nejsou žádné tokeny (o tokenech se dozvíte dál v tomto článku). Použití typu bezkontaktní komunikace vyžaduje, abyste v modelu měli aspoň dvě vysvětlení, jinak bude možnost zakázaná.
Seznam frází
Typ vysvětlení seznamu frází se obvykle používá k identifikaci a klasifikaci dokumentu prostřednictvím modelu. Jak je popsáno v příkladu popisku odkazujícího lékaře , jedná se o řetězec slov, frází, čísel nebo znaků, který je v dokumentech, které identifikujete, konzistentně.
I když to není požadavek, můžete s vysvětlením dosáhnout lepšího úspěchu, pokud se zachycená fráze nachází v dokumentu na konzistentním místě. Například popisek odkazujícího lékaře může být konzistentně umístěný v prvním odstavci dokumentu. Můžete také použít nastavení Konfigurovat, kde se fráze vyskytují v rozšířeném dokumentu a vybrat konkrétní oblasti, ve kterých se fráze nachází, zejména pokud existuje šance, že se fráze může v dokumentu objevit na více místech.
Pokud je při identifikaci popisku potřeba rozlišovat malá a velká písmena, můžete ho pomocí typu seznam frází zadat ve vysvětlení zaškrtnutím políčka Pouze přesná velká písmena .

Typ fráze je zvlášť užitečný, když vytváříte vysvětlení, které identifikuje a extrahuje informace v různých formátech, jako jsou kalendářní data, telefonní čísla a čísla platebních karet. Datum se například dá zobrazit v mnoha různých formátech (1. 1. 2020, 1. 1. 2020, 1. 1. 2020, 1. 1. 2020 nebo 1. ledna 2020). Definování seznamu frází zefektivňuje vysvětlení tím, že zachytí všechny možné odchylky v datech, která se pokoušíte identifikovat a extrahovat.
V příkladu telefonního čísla extrahujete telefonní číslo každého lékaře ze všech dokumentů, které model identifikuje. Při vytváření vysvětlení zadejte různé formáty, které se může v dokumentu zobrazovat, abyste mohli zachytit možné varianty.
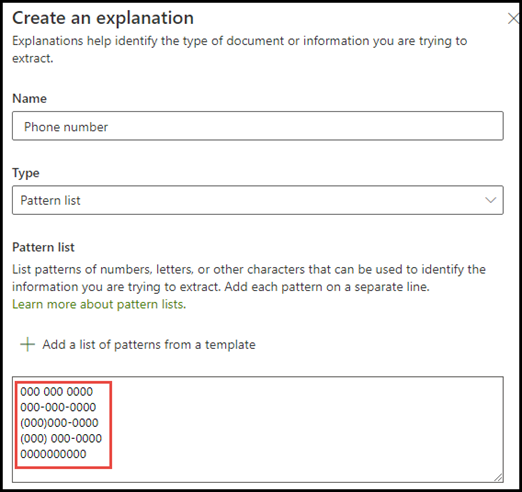
V tomto příkladu v upřesňujícím nastavení zaškrtněte políčko Libovolná číslice od 0 do 9 , aby každá hodnota "0" použitá v seznamu frází byla libovolná číslice od 0 do 9.

Podobně platí, že pokud vytvoříte seznam frází, který obsahuje textové znaky, zaškrtněte políčko Jakékoli písmeno z a–z , aby každý znak "a" použitý v seznamu frází byl libovolný znak od "a" do "z".
Pokud například vytvoříte seznam datových frází a chcete se ujistit, že je rozpoznán formát data , například 1. ledna 2020 , musíte:
- Přidejte do seznamu frází aaa 0, 0000 a aaa 00, 0000 .
- Ujistěte se, že je zaškrtnuté také jakékoli písmeno od a-z .

Pokud máte v seznamu frází požadavky na velká písmena, můžete zaškrtnout políčko Pouze přesná velká písmena . Pokud v příkladu s datem požadujete, aby první písmeno měsíce bylo velké, musíte:
- Přidejte do seznamu frází Aaa 0, 0000 a Aaa 00, 0000 .
- Ujistěte se, že je také vybraná možnost Pouze přesná velká písmena .

Poznámka
Místo ručního vytváření vysvětlení seznamu frází použijte knihovnu vysvětlení a použijte šablony seznamů frází pro běžný seznam frází, jako je datum, telefonní číslo nebo číslo platební karty.
Regulární výraz
Typ vysvětlení regulárního výrazu umožňuje vytvářet vzory, které pomáhají najít a identifikovat určité textové řetězce v dokumentech. Regulární výrazy můžete použít k rychlé parsování velkých objemů textu na:
- Vyhledejte konkrétní vzory znaků.
- Ověřte text, abyste měli jistotu, že odpovídá předdefinovanému vzoru (například e-mailové adrese).
- Extrahujte, upravujte, nahrazujte nebo odstraňujte textové podřetětce.
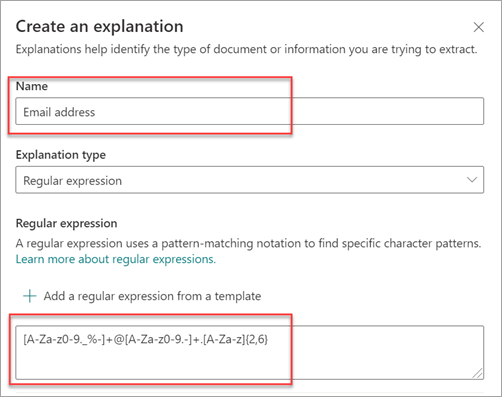
Typ regulárního výrazu je zvlášť užitečný, když vytváříte vysvětlení, které identifikuje a extrahuje informace v podobných formátech, jako jsou e-mailové adresy, čísla bankovních účtů nebo adresy URL. Například e-mailová adresa, například megan@contoso.com, se zobrazuje určitým způsobem ("megan" je první část a "com" je poslední část).
Regulární výraz e-mailové adresy je: [A-Za-z0-9._%-]+@[A-Za-z0-9.-]+.[ A-Za-z]{2,6}.
Tento výraz se skládá z pěti částí v tomto pořadí:
Libovolný počet následujících znaků:
a. Písmena od a do z
b. Čísla od 0 do 9
c. Tečka, podtržítko, procento nebo pomlčka
Symbol @
Libovolný počet stejných znaků jako první část e-mailové adresy
Tečka
Dvě až šest písmen
Přidání typu vysvětlení regulárního výrazu:
Na panelu Vytvořit vysvětlení v části Typ vysvětlení vyberte Regulární výraz.
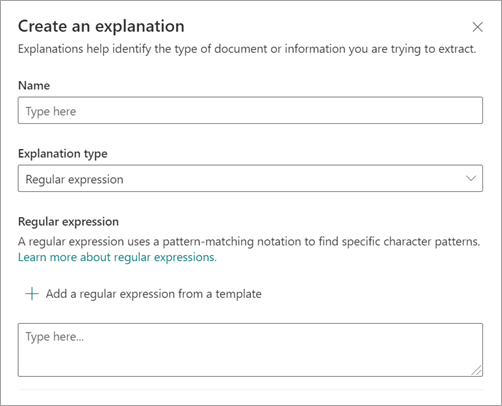
Můžete zadat výraz do textového pole Regulární výraz nebo vybrat Přidat regulární výraz ze šablony.
Když přidáte regulární výraz pomocí šablony, automaticky se do textového pole přidá název a regulární výraz. Pokud například zvolíte šablonu Email adresy, vyplní se panel Vytvořit vysvětlení.
Omezení
Následující tabulka uvádí možnosti vložených znaků, které v současné době nejsou k dispozici pro použití ve vzorech regulárních výrazů.
| Možnost | Stav | Aktuální funkce |
|---|---|---|
| Rozlišování velkých a malých písmen | V současné době není podporováno. | U všech provedených shod se nerozlišují malá a velká písmena. |
| Ukotvení čar | V současné době není podporováno. | Nelze zadat konkrétní pozici v řetězci, kde musí dojít k shodě. |
Blízkost
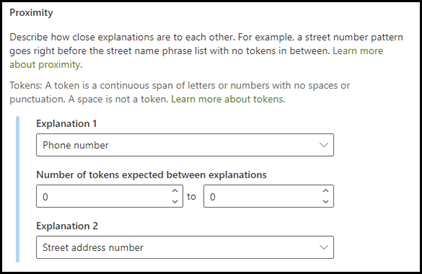
Typ vysvětlení blízkosti pomáhá vašemu modelu identifikovat data tím, že definuje, jak blízko k němu je jiná část dat. Řekněme například, že jste ve svém modelu definovali dvě vysvětlení, která označují jak číslo adresy zákazníka, tak telefonní číslo.
Všimněte si, že telefonní čísla zákazníka se vždy zobrazují před číslem adresy.
Alex Wilburn
555-555-5555
One Microsoft Way
Redmond, WA 98034
Pomocí vysvětlení blízkosti můžete definovat, jak daleko je vysvětlení telefonního čísla, abyste lépe identifikovali číslo adresy v dokumentech.
Poznámka
Regulární výrazy se v současné době nedají použít s typem vysvětlení blízkosti.
Co jsou tokeny?
Pokud chcete použít typ vysvětlení blízkosti, musíte pochopit, co je token. Počet tokenů je způsob, jakým vysvětlení blízkosti měří vzdálenost od jednoho vysvětlení k druhému. Token je souvislé rozpětí (bez mezer nebo interpunkce) písmen a čísel.
Následující tabulka uvádí příklady, jak určit počet tokenů ve frázi.
| Fráze | Počet tokenů | Vysvětlení |
|---|---|---|
Dog |
1 | Jedno slovo bez interpunkce nebo mezer. |
RMT33W |
1 | Číslo lokátoru záznamů. Může obsahovat číslice a písmena, ale nemá interpunkci. |
425-555-5555 |
5 | Telefonní číslo. Každá interpunkční znaméčka je jeden token, takže 425-555-5555 je to 5 tokenů:425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
Konfigurace typu vysvětlení bezkontaktní komunikace
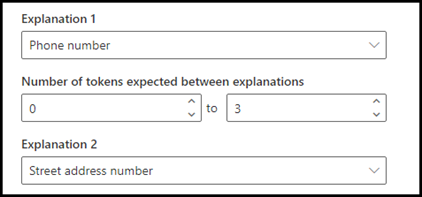
Například nakonfigurujte nastavení bezkontaktní komunikace tak, aby definovalo rozsah počtu tokenů ve vysvětlení telefonního čísla z vysvětlení čísla ulice . Všimněte si, že minimální rozsah je "0", protože mezi telefonním číslem a číslem adresy nejsou žádné tokeny.
Některá telefonní čísla v ukázkových dokumentech jsou ale připojená pomocí (mobilní).
Nestor Wilke
111-111-1111 (mobilní)
One Microsoft Way
Redmond, WA 98034
V (mobilní) jsou tři tokeny:
| Fráze | Počet tokenů |
|---|---|
| ( | 1 |
| mobilní | 2 |
| ) | 3 |
Nakonfigurujte nastavení bezkontaktní komunikace tak, aby měl rozsah od 0 do 3.
Konfigurace umístění frází v dokumentu
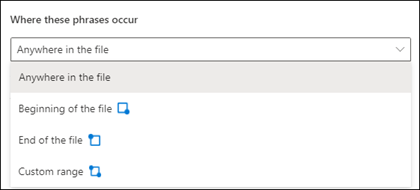
Když vytvoříte vysvětlení, ve výchozím nastavení se v celém dokumentu vyhledá fráze, kterou se pokoušíte extrahovat. Můžete ale použít upřesňující nastavení Kde se tyto fráze vyskytují , které vám pomůže izolovat konkrétní místo v dokumentu, kde se fráze vyskytuje. Toto nastavení je užitečné v situacích, kdy se podobné výskyty fráze můžou objevit někde jinde v dokumentu a chcete se ujistit, že je vybraná správná fráze.
S odkazem na příklad našeho dokumentu Medical Referral je referenční lékař vždy zmíněn v prvním odstavci dokumentu. Pomocí nastavení Kde se tyto fráze vyskytují můžete v tomto příkladu nakonfigurovat vysvětlení tak, aby se tento popisek hledal pouze v počáteční části dokumentu nebo v jakémkoli jiném umístění, ve kterém by k němu mohlo dojít.
Pro toto nastavení můžete zvolit následující možnosti:
Kdekoli v souboru: Fráze se vyhledá v celém dokumentu.
Začátek souboru: Dokument se prohledá od začátku do umístění fráze.
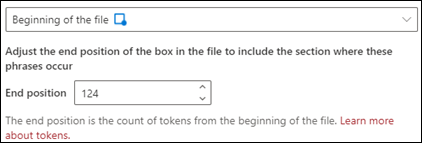
V prohlížeči můžete ručně upravit pole pro výběr tak, aby zahrnovalo umístění, ve kterém fáze probíhá. Hodnota Koncová pozice se aktualizuje tak, aby zobrazovala počet tokenů, které vybraná oblast zahrnuje. Můžete také aktualizovat hodnotu Koncové umístění a upravit vybranou oblast.
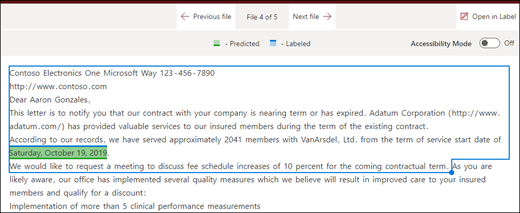
Konec souboru: Dokument se prohledá od konce do umístění fráze.
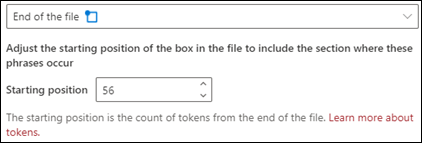
V prohlížeči můžete ručně upravit pole pro výběr tak, aby zahrnovalo umístění, ve kterém fáze probíhá. Hodnota Počáteční pozice se aktualizuje tak, aby zobrazovala počet tokenů, které vaše vybraná oblast zahrnuje. Můžete také aktualizovat hodnotu Počáteční pozice a upravit tak vybranou oblast.

Vlastní rozsah: V dokumentu se hledá umístění fráze v zadaném rozsahu.
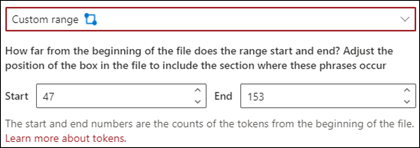
V prohlížeči můžete ručně upravit pole pro výběr tak, aby zahrnovalo umístění, ve kterém fáze probíhá. Pro toto nastavení musíte vybrat pozici Start a End . Tyto hodnoty představují počet tokenů od začátku dokumentu. I když můžete tyto hodnoty zadat ručně, je jednodušší ručně upravit pole pro výběr v prohlížeči.
Důležité informace o konfiguraci vysvětlení
Při trénování klasifikátoru je potřeba mít na paměti několik věcí, které zajistí předvídatelnější výsledky:
Čím více dokumentů trénujete, tím přesnější bude klasifikátor. Pokud je to možné, použijte více než pět dobrých dokumentů a použijte více než jeden špatný dokument. Pokud knihovny, se kterými pracujete, obsahují několik různých typů dokumentů, vede několik z nich k předvídatelnějším výsledkům.
Popisování dokumentu hraje v procesu trénování důležitou roli. Používají se společně s vysvětlením k trénování modelu. Při trénování klasifikátoru s dokumenty, které nemají velký obsah, se můžou zobrazit určité anomálie. Vysvětlení nemusí odpovídat ničemu v dokumentu, ale vzhledem k tomu, že byl označen jako "dobrý" dokument, může se jednat o shodu během trénování.
Při vytváření vysvětlení používá logiku OR v kombinaci s popiskem k určení, jestli se jedná o shodu. Regulární výraz, který používá logiku AND, může být předvídatelnější. Tady je ukázkový regulární výraz, který se použije ve skutečných dokumentech jako trénování. Všimněte si, že červeně zvýrazněný text je fráze nebo fráze, které byste hledali.
(?=.*network provider)(?=.*participating providers).*
Popisky a vysvětlení fungují společně a používají se při trénování modelu. Nejedná se o řadu pravidel, u nichž je možné zrušit spřaženost a u každé nakonfigurované proměnné použít přesné váhy nebo predikce. Čím větší varianta dokumentů použitých při trénování zajistí větší přesnost v modelu.