Automatické agregace
Automatické agregace používají nejmodernější strojové učení (ML) k průběžné optimalizaci sémantických modelů DirectQuery pro maximální výkon dotazů sestavy. Automatické agregace jsou založené na stávající uživatelsky definované infrastruktuře agregací , která byla poprvé zavedena ve složených modelech pro Power BI. Na rozdíl od uživatelem definovaných agregací nevyžadují automatické agregace rozsáhlé modelování dat a dovednosti optimalizace dotazů ke konfiguraci a údržbě. Automatické agregace jsou samoobslužné trénování i samoobslužná optimalizace. Umožňují vlastníkům modelů jakékoli úrovně dovedností zlepšit výkon dotazů a poskytují rychlejší vizualizace sestav pro velké modely.
S automatickými agregacemi:
- Vizualizace sestav jsou rychlejší – optimální procento dotazů sestavy vrací automaticky udržovaná mezipaměť agregací v paměti místo systémů back-endových zdrojů dat. Odlehlé dotazy, které nevrací mezipaměť v paměti, se předávají přímo zdroji dat pomocí DirectQuery.
- Vyvážená architektura – ve srovnání s čistým režimem DirectQuery vrací většina výsledků dotazů dotazovací modul Power BI a mezipaměť agregací v paměti. Zatížení zpracování dotazů na systémy zdrojů dat ve špičce je možné výrazně snížit, což znamená vyšší škálovatelnost back-endu zdroje dat.
- Snadné nastavení – Vlastníci modelů můžou povolit automatické trénování agregací a naplánovat jednu nebo více aktualizací modelu. Při prvním trénování a aktualizaci začnou automatické agregace vytvářet architekturu agregací a optimální agregace. Systém se v průběhu času automaticky naladí.
- Jemné ladění – Pomocí jednoduchého a intuitivního uživatelského rozhraní v nastavení modelu můžete odhadnout zvýšení výkonu pro jiné procento dotazů vrácených z mezipaměti agregací v paměti a provést úpravy pro ještě větší zisky. Jeden ovládací prvek panelu snímků vám pomůže snadno vyladit prostředí.
Požadavky
Podporované plány
Automatické agregace jsou podporované pro Power BI Premium na kapacitu, Premium na uživatele a modely Power BI Embedded.
Podporované zdroje dat
Automatické agregace jsou podporovány pro následující zdroje dat:
- Azure SQL Database
- Vyhrazený fond SQL služby Azure Synapse
- SQL Server 2019 nebo novější
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Podporované režimy
Modely režimu DirectQuery podporují automatické agregace. Podporují se složené modely modelu s importem i připojení DirectQuery. Automatické agregace se podporují jenom pro připojení DirectQuery.
Oprávnění
Pokud chcete povolit a nakonfigurovat automatické agregace, musíte být vlastníkem modelu. Správci pracovního prostoru můžou převzít roli vlastníka a nakonfigurovat nastavení automatických agregací.
Konfigurace automatických agregací
Automatické agregace se konfigurují v modelu Nastavení. Konfigurace je jednoduchá – povolte automatické trénování agregací a naplánujte jednu nebo více aktualizací. Než nakonfigurujete automatické agregace pro model, nezapomeňte si tento článek zcela přečíst. Poskytuje dobrý přehled o tom, jak automatické agregace fungují, a může vám pomoct rozhodnout se, jestli jsou pro vaše prostředí správné automatické agregace. Až budete připraveni na podrobné pokyny, jak povolit automatické trénování agregací, nakonfigurovat plán aktualizace a doladit pro vaše prostředí, přečtěte si téma Konfigurace automatických agregací.
Zaměstnanecké výhody
S DirectQuery se pokaždé, když uživatel modelu otevře sestavu nebo pracuje s vizualizací sestavy, předají se dotazy DAX (Data Analysis Expressions) do dotazovacího modulu a pak do back-endového zdroje dat jako dotazy SQL. Zdroj dat musí vypočítat a vrátit výsledky pro každý dotaz. V porovnání s modely režimu importu uloženými v paměti může být doba odezvy zdroje dat DirectQuery náročná na čas i zpracování, což často způsobuje pomalé doby odezvy dotazů ve vizualizacích sestav.
Pokud je pro model DirectQuery povolená funkce DirectQuery, mohou automatické agregace zvýšit výkon dotazů na sestavy tím, že se vyhnete odezvám dotazů na zdroje dat. Předem agregované výsledky dotazu se automaticky vrátí agregací v paměti, nikoli odesíláním a vrácením zdroje dat. Množství předem agregovaných dat v mezipaměti agregací v paměti je malý zlomek množství dat uchováných ve skutečnosti a podrobných tabulkách ve zdroji dat. Výsledkem je nejen lepší výkon dotazů na sestavy, ale také snížení zatížení systémů back-endových zdrojů dat. U automatických agregací se do back-endového zdroje dat předávají do back-endového zdroje dat jenom malá část sestav a ad hoc dotazů, které vyžadují agregace, které nejsou zahrnuté v mezipaměti v paměti, stejně jako u režimu DirectQuery.
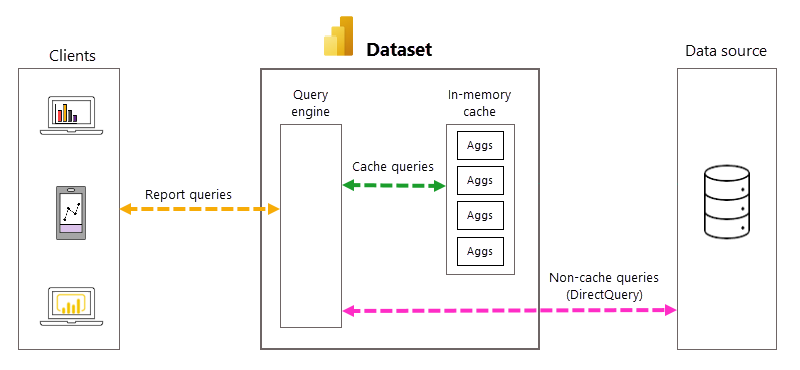
Automatická správa dotazů a agregací
I když automatické agregace eliminují potřebu vytvářet uživatelsky definované agregační tabulky a výrazně zjednodušit implementaci předem agregovaného datového řešení, hlubší znalost základních procesů a závislostí je užitečná při pochopení fungování automatických agregací. Power BI při vytváření a správě automatických agregací spoléhá na následující skutečnosti.
Protokol dotazů
Power BI sleduje dotazy modelu a sestav uživatelů v protokolu dotazů. Power BI pro každý model udržuje sedm dnů dat protokolu dotazů. Data protokolu dotazů se každý den zahrnou dopředu. Protokol dotazů je zabezpečený a není viditelný pro uživatele nebo prostřednictvím koncového bodu XMLA.
Trénovací operace
V rámci první plánované operace aktualizace modelu pro vybranou frekvenci (den nebo týden) power BI nejprve zahájí trénovací operaci, která vyhodnocuje protokol dotazů, aby se agregace v mezipaměti agregací v paměti přizpůsobily změnám vzorců dotazů. Tabulky agregace v paměti se vytvářejí, aktualizují nebo zahodí a do zdroje dat se odesílají speciální dotazy, aby bylo možné určit agregace, které se mají zahrnout do mezipaměti. Počítaná agregace se ale během trénování nenačtou do mezipaměti v paměti – načtou se během následné operace aktualizace.
Pokud například zvolíte frekvenci dne a naplánujete aktualizace v 4:00, 9:00, 2:00 a 17:00, každý den bude obsahovat pouze aktualizaci 4:00 DOM. Následující naplánované aktualizace 9:00, 2:00 a 17:00 pro tento den jsou operacemi, které aktualizují existující agregace v mezipaměti.
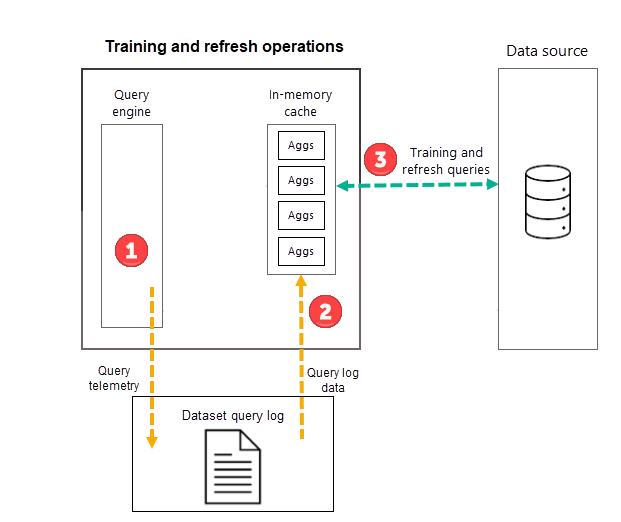
Zatímco trénovací operace vyhodnocují minulé dotazy z protokolu dotazů, výsledky jsou dostatečně přesné, aby se zajistilo, že se probírá budoucí dotazy. Není však zaručeno, že budoucí dotazy budou vráceny mezipamětí agregací v paměti, protože tyto nové dotazy se můžou lišit od dotazů odvozených z protokolu dotazů. Tyto dotazy, které nevrací mezipaměť agregací v paměti, se předávají do zdroje dat pomocí DirectQuery. V závislosti na frekvenci a řazení těchto nových dotazů mohou být agregace zahrnuté do mezipaměti agregací v paměti s další operací trénování.
Operace trénování má 60minutový časový limit. Pokud trénování nemůže zpracovat celý protokol dotazů v rámci časového limitu, zaprotokoluje se oznámení v historii aktualizace modelu a trénování se obnoví při příštím spuštění. Trénovací cyklus se dokončí a nahradí stávající automatické agregace při zpracování celého protokolu dotazů.
Operace aktualizace
Jak jsme popsali dříve, po dokončení trénovací operace jako součást první plánované aktualizace pro vybranou frekvenci provede Power BI operaci aktualizace, která se dotazuje a načte nová a aktualizovaná agregace do mezipaměti agregací v paměti, a odebere všechny agregace, které už nejsou dostatečně vysoké (jak určuje trénovací algoritmus). Všechny následné aktualizace pro zvolenou frekvenci dnů nebo týdnů jsou operace, které se dotazují na zdroj dat, aby aktualizovaly existující agregace dat v mezipaměti. V našem předchozím příkladu jsou naplánované aktualizace pro tento den pouze operace 9:00, 2:00 a 7:00.
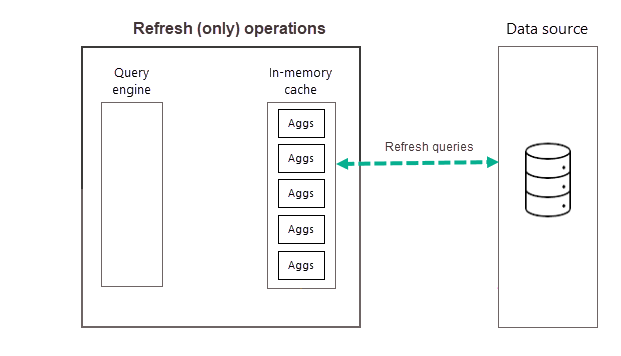
Pravidelné naplánované aktualizace v průběhu dne (nebo týdne) zajišťují, aby agregace dat v mezipaměti byly aktuální s daty v back-endovém zdroji dat. Prostřednictvím modelu Nastavení můžete naplánovat až 48 aktualizací za den, abyste zajistili, že dotazy sestavy vrácené mezipamětí agregací získávají výsledky na základě nejnovějších aktualizačních dat z back-endového zdroje dat.
Upozornění
Operace trénování a aktualizace jsou náročné na procesy a prostředky pro služba Power BI i systémy zdrojů dat. Zvýšení procenta dotazů, které používají agregace, znamená, že během trénování a aktualizace se musí dotazovat a počítat z zdrojů dat, což zvyšuje pravděpodobnost nadměrného využití systémových prostředků a potenciálně způsobuje vypršení časových limitů. Další informace najdete v tématu Jemné ladění.
Školení na vyžádání
Jak už bylo zmíněno dříve, cyklus trénování se nemusí dokončit v časových limitech jednoho cyklu aktualizace dat. Pokud nechcete čekat na další naplánovaný cyklus aktualizace, který zahrnuje trénování, můžete také aktivovat automatické trénování agregací na vyžádání výběrem možnosti Trénovat a aktualizovat hned v modelu Nastavení. Pomocí trénování a aktualizace teď aktivujete jak operaci trénování, tak operaci aktualizace. Zkontrolujte historii aktualizace modelu a v případě potřeby zkontrolujte, jestli je aktuální operace dokončená před spuštěním jiné operace trénování a aktualizace na vyžádání.
Historie aktualizace
Každá operace aktualizace se zaznamenává v historii aktualizace modelu. Zobrazí se důležité informace o každé aktualizaci, včetně počtu agregací paměti v mezipaměti, které spotřebovávají nakonfigurované procento dotazů. Pokud chcete zobrazit historii aktualizace, vyberte na stránce Nastavení modelu historii aktualizace. Pokud chcete přejít k podrobnostem o něco dál, vyberte Zobrazit podrobnosti.
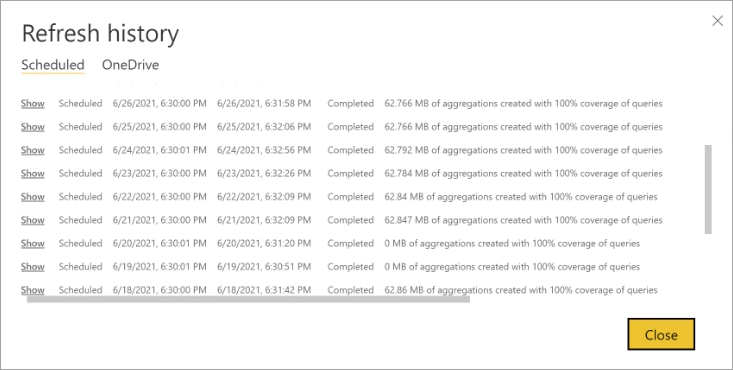
Pravidelným kontrolou historie aktualizací můžete zajistit dokončení plánovaných operací aktualizace v přijatelném období. Před zahájením další plánované aktualizace se ujistěte, že se operace aktualizace úspěšně dokončily.
Selhání trénování a aktualizace
Zatímco Power BI provádí operace trénování a aktualizace jako součást první naplánované aktualizace pro zvolený den nebo týden, tyto operace se implementují jako samostatné transakce. Pokud operace trénování nemůže plně zpracovat protokol dotazů v rámci časových limitů, Power BI bude pokračovat v aktualizaci existujících agregací (a běžných tabulek ve složeném modelu) pomocí předchozího stavu trénování. V tomto případě bude historie aktualizace značit, že aktualizace proběhla úspěšně a trénování bude pokračovat ve zpracování protokolu dotazů při příštím spuštění trénování. Výkon dotazů může být méně optimalizovaný, pokud se změnily vzory dotazů sestav klienta a agregace se ještě neupravily, ale dosažená úroveň výkonu by měla být mnohem lepší než čistý model DirectQuery bez agregací.
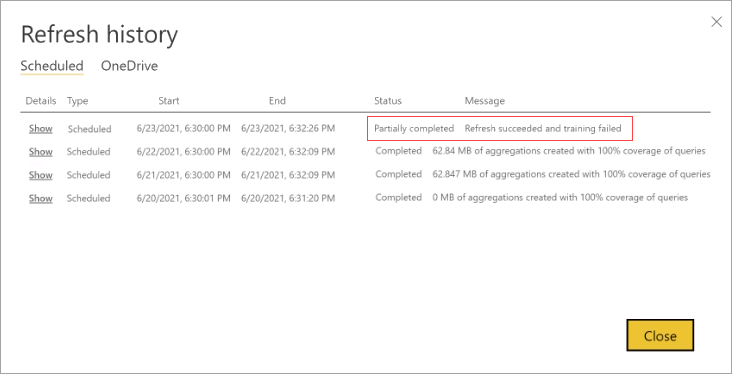
Pokud trénovací operace vyžaduje k dokončení zpracování protokolu dotazů příliš mnoho cyklů, zvažte snížení procenta dotazů, které používají mezipaměť agregací v paměti v modelu Nastavení. Tím se sníží počet agregací vytvořených v mezipaměti, ale umožníte dokončení operací trénování a aktualizace více času. Další informace najdete v tématu Jemné ladění.
Pokud trénování proběhne úspěšně, ale aktualizace selže, celá aktualizace se označí jako neúspěšná, protože výsledkem je nedostupná mezipaměť agregací v paměti.
Při plánování aktualizace můžete zadat e-mailová oznámení, pokud dojde k selhání aktualizace.
Uživatelem definované a automatické agregace
Uživatelem definované agregace v Power BI je možné ručně nakonfigurovat na základě skrytých agregovaných tabulek v modelu. Konfigurace uživatelsky definovaných agregací je často složitá a vyžaduje větší úroveň dovedností modelování dat a optimalizace dotazů. Automatické agregace na druhou stranu eliminují tuto složitost jako součást systému řízeného AI. Na rozdíl od uživatelem definovaných agregací, které zůstávají statické, Power BI nepřetržitě udržuje protokoly dotazů a z těchto protokolů určuje vzory dotazů na základě algoritmů prediktivního modelování strojového učení (ML). Předem agregovaná data se počítají a ukládají v paměti na základě analýzy vzorů dotazů. S automatickými agregacemi jsou modely samoobslužné trénování i samoobslužné optimalizace. Při změně vzorů dotazů na sestavu klienta se automatické agregace upravují, upřednostňují a ukládají tyto agregace do mezipaměti, které se nejčastěji používají.
Vzhledem k tomu, že automatické agregace jsou založené na stávající uživatelsky definované infrastruktuře agregací, je možné použít uživatelsky definované i automatické agregace společně ve stejném modelu. Zkušení modelátoři dat můžou definovat agregace pro tabulky pomocí DirectQuery, Importu (s přírůstkovou aktualizací nebo bez) nebo duálního úložiště, přičemž současně mají výhody více automatických agregací pro dotazy přes připojení DirectQuery, která nenarazí na uživatelsky definované agregační tabulky. Tato flexibilita umožňuje vyvážené architektury, které můžou snížit zatížení dotazů a vyhnout se kritickým bodům.
Agregace vytvořené v mezipaměti v paměti pomocí algoritmu automatického trénování agregací jsou identifikovány jako System agregace. Trénovací algoritmus vytváří a odstraňuje pouze ty System agregace, protože dotazy pro vytváření sestav se analyzují a provádějí úpravy, aby se zachovaly optimální agregace modelu. Uživatelsky definované i automatické agregace se aktualizují aktualizací. Automatické zpracování agregací zahrnuje pouze ty agregace vytvořené automatickými agregacemi, které jsou označené jako systémem generované agregace.
Ukládání dotazů do mezipaměti a automatické agregace
Power BI Premium také podporuje ukládání dotazů do mezipaměti v Power BI Premium/Embedded , aby se zachovaly výsledky dotazů. Ukládání dotazů do mezipaměti je jiná funkce než automatické agregace. S ukládáním dotazů do mezipaměti používá Power BI Premium k implementaci ukládání do mezipaměti místní službu ukládání do mezipaměti, zatímco automatické agregace se implementují na úrovni modelu. Při ukládání dotazů do mezipaměti služba ukládá dotazy pouze do mezipaměti pro počáteční načtení stránky sestavy, a proto se výkon dotazů nezlepší, když uživatelé pracují se sestavou. Naproti tomu automatické agregace optimalizují většinu dotazů sestav tím, že agregované výsledky dotazů předem ukládají do mezipaměti, včetně těchto dotazů generovaných při interakci uživatelů se sestavami. Ukládání dotazů do mezipaměti i automatické agregace je možné pro model povolit, ale pravděpodobně to není nutné.
Monitorování s využitím Azure Log Analytics
Azure Log Analytics (LA) je služba ve službě Azure Monitor, kterou může Power BI použít k ukládání protokolů aktivit. Pomocí sady Azure Monitor můžete shromažďovat, analyzovat a pracovat s telemetrickými daty z Azure a místních prostředí. Nabízí dlouhodobé úložiště, rozhraní ad hoc dotazů a přístup k rozhraní API, které umožňuje export a integraci dat s jinými systémy. Další informace najdete v tématu Použití Azure Log Analytics v Power BI.
Pokud je Power BI nakonfigurovaný s účtem Azure LA, jak je popsáno v konfiguraci Azure Log Analytics pro Power BI, můžete analyzovat úspěšnost automatických agregací. Mimo jiné můžete určit, jestli dotazy sestavy odpovídají z mezipaměti v paměti.
Pokud chcete tuto možnost použít, stáhněte si šablonu PBIT a připojte ji k účtu Log Analytics, jak je popsáno v tomto blogovém příspěvku Power BI. V sestavě můžete zobrazit data na třech různých úrovních: souhrnné zobrazení, zobrazení na úrovni dotazu DAX a zobrazení na úrovni dotazu SQL.
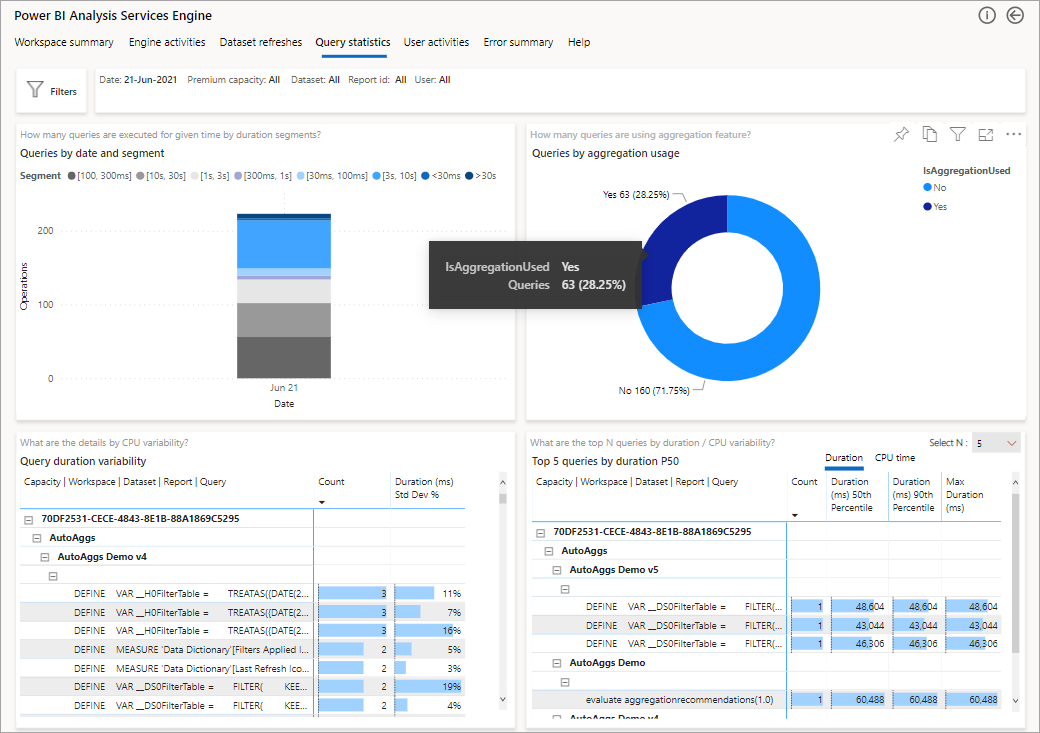
Následující obrázek ukazuje stránku souhrnu pro všechny dotazy. Jak vidíte, označený graf zobrazuje procento celkových dotazů, které byly splněny agregacemi a těmi, které musely zdroj dat využívat.
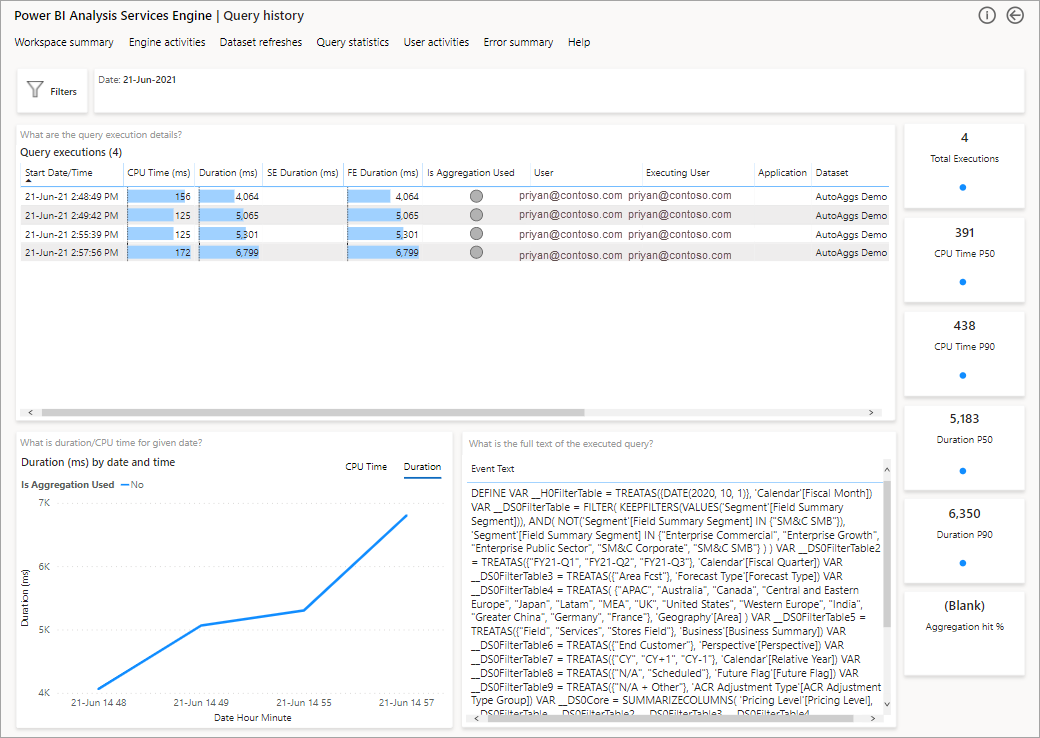
Dalším krokem k podrobnějšímu pohledu je podívat se na použití agregací na úrovni dotazu DAX. Klikněte pravým tlačítkem myši na dotaz DAX ze seznamu (vlevo dole) >Procházení historie> dotazů.
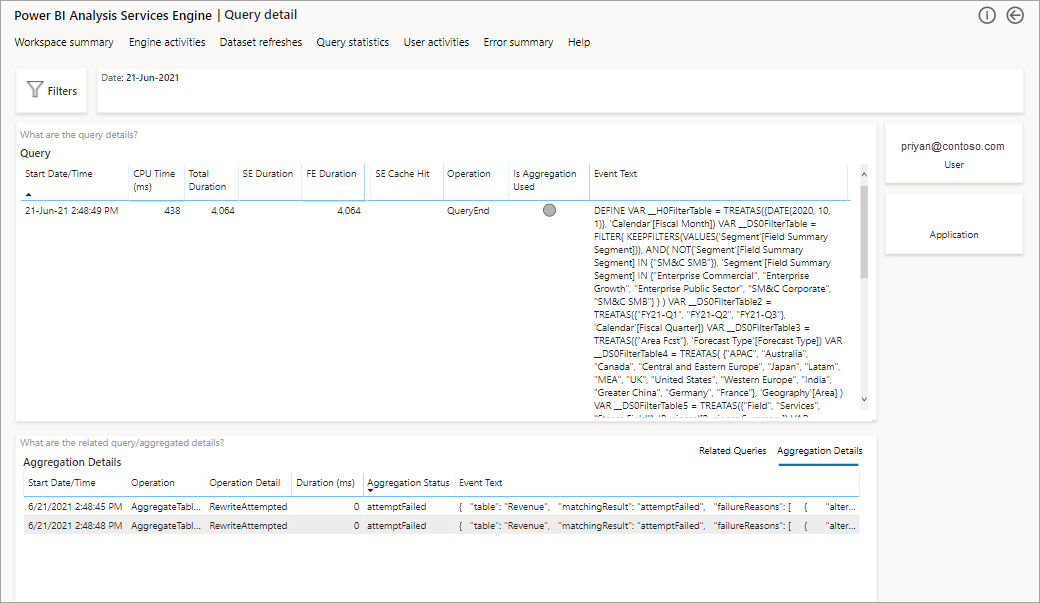
Zobrazí se seznam všech relevantních dotazů. Přechod k podrobnostem na další úrovni a zobrazení dalších podrobností agregace
Správa životního cyklu aplikací
Od vývoje až po testování a z testování do produkce mají modely s povolenými automatickými agregacemi zvláštní požadavky na řešení ALM.
Kanály nasazení
S kanály nasazení může Power BI zkopírovat modely s jejich konfigurací modelu z aktuální fáze do cílové fáze. Automatické agregace ale musí být v cílové fázi resetovány, protože nastavení nepřenesou z aktuální do cílové fáze. Obsah můžete také nasadit programově pomocí rozhraní REST API kanálů nasazení. Další informace o tomto procesu najdete v tématu Automatizace kanálu nasazení pomocí rozhraní API a DevOps.
Vlastní řešení ALM
Pokud používáte vlastní řešení ALM založené na koncových bodech XMLA, mějte na paměti, že vaše řešení může jako součást metadat modelu kopírovat tabulky agregace generované systémem a uživatelem vytvořené agregace. Musíte však povolit automatické agregace po každém kroku nasazení v cílové fázi ručně. Power BI zachová konfiguraci, pokud přepíšete existující model.
Poznámka:
Pokud model nahrajete nebo znovu publikujete jako součást souboru Power BI Desktopu (.pbix), systémem vytvořené agregační tabulky se ztratí, protože Power BI nahradí existující model všemi jeho metadaty a daty v cílovém pracovním prostoru.
Změna modelu
Po změně modelu s automatickými agregacemi povolenými prostřednictvím koncových bodů XMLA, jako je přidání nebo odebrání tabulek, Zachová Power BI všechny existující agregace, které už nejsou potřeba nebo nejsou relevantní. Výkon dotazů může být ovlivněn, dokud se neaktivuje další fáze trénování.
Prvky metadat
Modely s povolenými automatickými agregacemi obsahují jedinečné systémové tabulky agregací. Tabulky agregací nejsou uživatelům viditelné v nástrojích pro vytváření sestav. Jsou viditelné prostřednictvím koncového bodu XMLA pomocí nástrojů s klientskými knihovnami služby Analysis Services verze 19.22.5 a vyšší. Při práci s modely s povolenými automatickými agregacemi nezapomeňte upgradovat nástroje pro modelování a správu dat na nejnovější verzi klientských knihoven. Pro SQL Server Management Studio (SSMS) upgradujte na SSMS verze 18.9.2 nebo vyšší. Starší verze SSMS nemůžou tyto modely vyčíslit ani nevypsat.
Tabulky automatických agregací jsou identifikovány SystemManaged vlastností tabulky, která je novinkou tabulkového objektového modelu (TOM) v klientských knihovnách služby Analysis Services verze 19.22.5 a vyšší. Následující fragment kódu ukazuje vlastnost nastavenou SystemManaged true na automatické tabulky agregací a false pro běžné tabulky.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
Spuštěním tohoto fragmentu kódu se vypíše tabulky automatických agregací, které jsou aktuálně součástí modelu v konzole.
Mějte na paměti, že tabulky agregací se neustále mění, protože trénovací operace určují optimální agregace, které se mají zahrnout do mezipaměti agregací v paměti.
Důležité
Power BI plně spravuje automatické agregace systémem generované objekty tabulky. Tyto tabulky neodstraňujte ani neupravujte sami. To může způsobit snížení výkonu.
Power BI udržuje konfiguraci modelu mimo model. Přítomnost tabulky agregací spravovaných systémem v modelu nemusí nutně znamenat, že model je ve skutečnosti povolený pro automatické trénování agregací. Jinými slovy, pokud skriptujete úplnou definici modelu s povolenými automatickými agregacemi a vytvoříte novou kopii modelu (s jiným názvem, pracovním prostorem nebo kapacitou), nebude nový výsledný model povolený pro automatické trénování agregací. Stále potřebujete povolit automatické trénování agregací pro nový model v modelu Nastavení.
Úvahy a omezení
Při použití automatických agregací mějte na paměti následující skutečnosti:
- Agregace nepodporují dynamické parametry dotazu M.
- Dotazy SQL vygenerované během počáteční fáze trénování můžou generovat významné zatížení datového skladu. Pokud se trénování nedokončí a na straně datového skladu můžete ověřit, že u dotazů dochází k vypršení časového limitu, zvažte dočasné vertikální navýšení kapacity datového skladu tak, aby splňovalo poptávku po trénování.
- Agregace uložené v mezipaměti agregací v paměti nemusí být vypočítány na nejnovějších datech ve zdroji dat. Na rozdíl od čistě DirectQuery a podobně jako u běžných tabulek importu je latence mezi aktualizacemi ve zdroji dat a agregacemi dat uloženými v mezipaměti agregací v paměti. I když bude vždy nějaký stupeň latence, je možné ji zmírnit efektivním plánem aktualizace.
- Pokud chcete dále optimalizovat výkon, nastavte všechny tabulky dimenzí na duální režim a ponechte tabulky faktů v režimu DirectQuery.
- Automatické agregace nejsou dostupné v Power BI Pro, Azure Analysis Services ani v Služba Analysis Services serveru SQL.
- Power BI nepodporuje stahování modelů s povolenými automatickými agregacemi. Pokud jste do Power BI nahráli nebo publikovali soubor Power BI Desktopu (.pbix) a povolili jste automatické agregace, nebudete už moct stáhnout soubor PBIX. Ujistěte se, že kopii souboru PBIX uchováváte místně.
- Automatické agregace s externími tabulkami ve službě Azure Synapse Analytics se nepodporují. V Synapse můžete vytvořit výčet externích tabulek pomocí následujícího dotazu SQL:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Automatické agregace jsou k dispozici pouze pro modely používající rozšířená metadata. Pokud chcete povolit automatické agregace pro starší model, nejprve upgradujte model na rozšířená metadata. Další informace najdete v tématu Použití rozšířených metadat modelu.
- Nepovolujte automatické agregace, pokud je zdroj dat DirectQuery nakonfigurovaný pro jednotné přihlašování a používá dynamická zobrazení dat nebo ovládací prvky zabezpečení k omezení dat, ke které má uživatel povolený přístup. Automatické agregace o těchto ovládacích prvcích na úrovni zdroje dat si nejsou vědomy, což znemožňuje zajistit, aby se správná data poskytovala pro jednotlivé uživatele. Trénování zaznamená upozornění v historii aktualizace, že zjistil zdroj dat nakonfigurovaný pro jednotné přihlašování a přeskočil tabulky, které používají tento zdroj dat. Pokud je to možné, zakažte jednotné přihlašování pro tyto zdroje dat, abyste plně využili výhod automatických agregací výkonu optimalizovaných dotazů.
- Nepovolujte automatické agregace, pokud model obsahuje pouze hybridní tabulky, abyste se vyhnuli zbytečným režijním nákladům na zpracování. Hybridní tabulka používá oddíly importu i oddíl DirectQuery. Běžným scénářem je přírůstková aktualizace s daty v reálném čase, ve kterých oddíl DirectQuery načítá transakce ze zdroje dat, ke kterému došlo po poslední aktualizaci dat. Power BI ale během aktualizace importuje agregace. Automatické agregace nemohou zahrnovat transakce, ke kterým došlo po poslední aktualizaci dat. Trénování zaznamená upozornění v historii aktualizace, že zjistil a přeskočil hybridní tabulky.
- Počítané sloupce se nepovažují za automatické agregace. Pokud použijete počítaný sloupec v režimu DirectQuery, například pomocí
COMBINEVALUESfunkce DAX k vytvoření relace založené na více sloupcích ze dvou tabulek DirectQuery, odpovídající dotazy sestavy nenarazí do mezipaměti agregací v paměti. - Automatické agregace jsou k dispozici pouze v služba Power BI. Power BI Desktop nevytvoří systémem generované tabulky agregací.
- Pokud upravíte metadata modelu s povolenými automatickými agregacemi, výkon dotazů se může snížit, dokud se neaktivuje další proces trénování. Osvědčeným postupem je vypustit automatické agregace, provést změny a pak je znovu natrénovat.
- Neupravujte ani neodstraňovat tabulky systémem generovaných agregací, pokud nemáte zakázané automatické agregace a model vyčistit. Systém zodpovídá za správu těchto objektů.
Komunita
Power BI má živou komunitu, kde MVP, profesionálové a partneré sdílejí odborné znalosti v diskuzní skupině, videích, blogech a dalších. Při získávání informací o automatických agregacích se nezapomeňte podívat na tyto další zdroje informací: