Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek cílí na import modelů dat pracujících s Power BI Desktopem. Je to důležité téma návrhu modelu, které je nezbytné k poskytování intuitivních, přesných a optimálních modelů.
Podrobnější informace o optimálním návrhu modelu, včetně rolí a relací tabulek, najdete v tématu Vysvětlení hvězdicového schématu a důležitostiPower BI .
Účel vztahu
Relace modelu šíří filtry použité ve sloupci jedné tabulky modelu do jiné tabulky modelu. Filtry se rozšíří tak dlouho, dokud existuje cesta relace, která může zahrnovat šíření do více tabulek.
Cesty relací jsou deterministické, což znamená, že filtry se vždy šíří stejným způsobem a bez náhodné variace. Relace ale mohou být zakázány nebo mohou mít kontext filtru upraven výpočty modelu, které používají konkrétní funkce DAX. Pro podrobnosti si prostudujte téma Relevantní funkce jazyka DAX, které se nachází dále v tomto článku.
Důležité
Relace modelů nevynucují integritu dat. Další informace najdete v tématu Vyhodnocení relací dále v tomto článku, které vysvětluje, jak se relace modelu chovají, když jsou problémy s integritou dat.
Zde je ukázáno, jak vztahy šíří filtry pomocí animovaného příkladu.

V tomto příkladu se model skládá ze čtyř tabulek: Category, Product, Yeara Sales. Tabulka kategorie se vztahuje k tabulce Product a tabulka Product se vztahuje k tabulce Sales. Tabulka Year také souvisí s tabulkou Sales. Všechny relace jsou jedna k mnoha (podrobnosti, které jsou popsány dále v tomto článku).
Dotaz, pravděpodobně vygenerovaný vizuálem karty Power BI, požaduje celkové množství prodaného zboží na základě prodejních objednávek pro jednu kategorii, Cat-A, a jeden rok, CY2018. Proto můžete zobrazit filtry použité v tabulkách Category a Year. Filtr tabulky Category se rozšíří do tabulky Product a izoluje dva produkty přiřazené kategorii cat-A. Potom se filtry tabulky Product rozšíří do tabulky Sales a izolují pouze dva řádky prodeje pro tyto produkty. Tyto dva řádky prodeje představují prodej produktů přiřazených do kategorie Cat-A. Jejich kombinované množství je 14 jednotek. Současně se filtr tabulky Year rozšiřuje, aby dále filtroval tabulku Sales, což vede pouze k jednomu řádku prodeje pro produkty přiřazené k kategorii Cat-A a které byly objednány v roce CY2018. Hodnota množství vrácená dotazem je 11 jednotek. Všimněte si, že když se na tabulku použije více filtrů (například tabulka Sales v tomto příkladu), je to vždy operace AND, která vyžaduje, aby všechny podmínky byly pravdivé.
Použití principů návrhu hvězdicového schématu
Doporučujeme použít hvězdicové schéma principy návrhu k vytvoření modelu, který obsahuje tabulky dimenzí a faktů. Je běžné nastavit Power BI tak, aby vynucovalo pravidla, která filtrují tabulky dimenzí, což umožňuje efektivně přenášet tyto filtry do tabulek faktů.
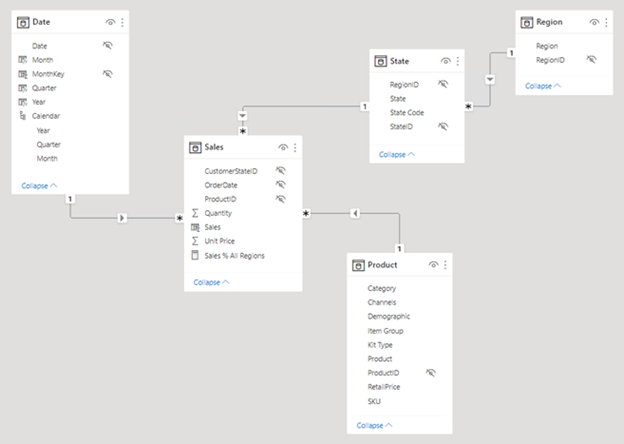
Následující obrázek je diagram modelu datového modelu analýzy prodeje společnosti Adventure Works. Zobrazuje návrh hvězdicového schématu, který obsahuje jednu tabulku faktů s názvem Sales. Další čtyři tabulky jsou tabulky dimenzí, které podporují analýzu měr prodeje podle data, stavu, oblasti a produktu. Všimněte si relací modelu, které propojují všechny tabulky. Tyto relace šíří filtry (přímo nebo nepřímo) do tabulky Sales.
Odpojené tabulky
Je neobvyklé, že tabulka modelu nesouvisí s jinou tabulkou modelu. Taková tabulka v platném návrhu modelu je popsána jako odpojená tabulka. Odpojená tabulka není určená k šíření filtrů do jiných tabulek modelu. Místo toho přijímá "uživatelský vstup" (třeba s vizuálem průřezu), což umožňuje výpočtům modelu smysluplně používat vstupní hodnotu. Představte si například odpojenou tabulku, která obsahuje rozsah kurzů měn. Pokud je filtr použit k filtrování podle hodnoty jedné sazby, výraz míry může tuto hodnotu použít k převodu hodnot prodeje.
Parametr co kdyby v Power BI Desktopu je funkce, která vytvoří odpojenou tabulku. Další informace najdete v tématu Vytvoření a použití parametru 'co kdyby' k vizualizaci proměnných v Power BI Desktopu.
Vlastnosti relace
Relace modelu spojuje jeden sloupec v tabulce s jedním sloupcem v jiné tabulce. (Existuje jeden specializovaný případ, kdy tento požadavek není pravdivý a vztahuje se pouze na relace s více sloupci v modelech DirectQuery. Další informace najdete v článku COMBINEVALUES funkce DAX.)
Poznámka:
Není možné spojit sloupec s jiným sloupcem ve stejné tabulce. Tento koncept se někdy zaměňuje se schopností definovat omezení cizího klíče relační databáze, na které odkazuje sama tabulka. Tento koncept relační databáze můžete použít k ukládání nadřazených a podřízených vztahů (například každý záznam zaměstnance souvisí s tím, komu zaměstnanec podléhá). Relace modelu ale nemůžete použít k vygenerování hierarchie modelu na základě tohoto typu relace. Pro vytvoření hierarchie nadřazený-podřízený si přečtěte funkce Nadřazený a Podřízený.
Datové typy sloupců
Datový typ pro sloupec "from" i "to" relace by měl být stejný. Práce s relacemi definovanými na sloupcích DateTime se nemusí chovat podle očekávání. Modul, který ukládá data Power BI, používá pouze DateTime datových typů; datové typy Datum, Čas a Datum/Čas/Časové pásmo jsou konstrukty formátování Power BI implementované nahoře. Všechny objekty závislé na modelu se v modulu budou stále zobrazovat jako DateTime (například relace, skupiny atd.). Pokud uživatel vybere Datum na kartě Modelování u těchto sloupců, stále nejsou rozpoznány jako stejné datum, protože časová část dat je stále brána v úvahu stroj. Přečtěte si další informace o způsobu zpracování typů data a času. Pokud chcete chování opravit, datové typy sloupců by se měly aktualizovat v Editoru Power Query, aby se z importovaných dat odebrala část Čas, takže když modul zpracovává data, hodnoty se zobrazí stejně.
Mohutnost
Každá relace modelu je definována typem kardinality. Existují čtyři možnosti typu kardinality, které představují charakteristiky dat souvisejících sloupců "from" a "to". Strana "jeden" znamená, že sloupec obsahuje jedinečné hodnoty; strana "mnoho" znamená, že sloupec může obsahovat duplicitní hodnoty.
Poznámka:
Pokud se operace aktualizace dat pokusí načíst duplicitní hodnoty do sloupce na „jedné“ straně, celá aktualizace dat selže.
Čtyři možnosti, společně s jejich zkratkami, jsou popsány v následujícím seznamu s odrážkami:
- Jedna k mnoha (1:*)
- Mnoho na jedno (*:1)
- Jeden na jednoho (1:1)
- Mnoho k mnoha (*:*)
Když v Power BI Desktopu vytvoříte relaci, návrhář automaticky rozpozná a nastaví typ kardinality. Power BI Desktop dotazuje model, aby věděl, které sloupce obsahují jedinečné hodnoty. Pro modely importu používá interní statistiku úložiště; pro modely DirectQuery odesílá dotazy profilace do zdroje dat. Někdy se ale Power BI Desktop může pokazit. Může se pokazit, když se tabulky ještě nenačtou s daty, nebo protože sloupce, u kterých očekáváte, že budou obsahovat duplicitní hodnoty, aktuálně obsahují jedinečné hodnoty. V obou případech můžete změnit typ kardinality, pokud jakýkoli sloupec na straně "jedna" obsahuje jedinečné hodnoty (nebo pokud je tabulka stále bez načtených řádků dat).
Kardinalita jedna k mnoha (a mnoho k jedné)
Možnosti kardinality jedna ku mnoha a mnoho ku jedné jsou v podstatě stejné a jsou také nejběžnějšími typy kardinality.
Při konfiguraci relace 1:N nebo N:1 zvolíte relaci, která odpovídá pořadí, ve kterém sloupce souvisejí. Zvažte, jak byste nakonfigurovali relaci z tabulky Product (Produkt ) s tabulkou Sales (Prodej ) pomocí sloupce ProductID nalezeného v každé tabulce. Typ kardinality by byl 1:N, protože sloupec ID produktu v tabulce Produkt obsahuje jedinečné hodnoty. Pokud byste propojili tabulky v opačném směru, Sales k Product, pak by kardinalita byla mnoho na jednu.
Kardinalita jedna ku jedné
Relace 1:1 znamená, že oba sloupce obsahují jedinečné hodnoty. Tento typ kardinality není běžný a pravděpodobně představuje neoptimální návrh modelu kvůli ukládání redundantních dat.
Další informace o použití tohoto typu kardinality najdete v pokynech k relaci typu 1:1.
Kardinalita M:N
Relace M:N znamená, že oba sloupce můžou obsahovat duplicitní hodnoty. Tento typ kardinality se používá zřídka. Obvykle je užitečné při návrhu složitých požadavků na model. Můžete ho použít ke spojení faktů M:N nebo k propojení faktů s vyšší úrovní podrobnosti. Například pokud jsou fakta cíle prodeje uložena na úrovni kategorie produktu a tabulka dimenzí produktu je uložena na úrovni produktu.
Pokyny k použití tohoto typu kardinality najdete v pokynech pro vztah M:N.
Poznámka:
Kardinalita typu mnohonásobný na mnohonásobný je podporována pro modely vyvinuté pro Power BI Report Server od ledna 2024 a novější.
Návod
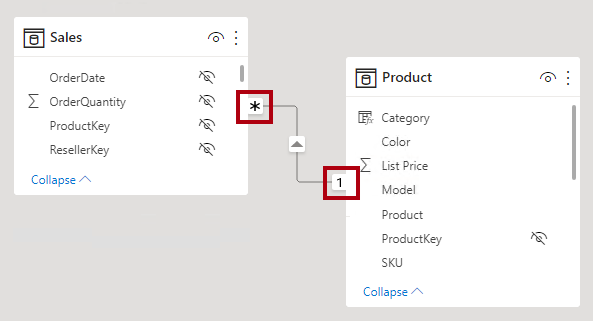
V zobrazení modelu Power BI Desktopu můžete typ kardinality relace interpretovat tak, že se podíváte na indikátory (1 nebo *) na obou stranách čáry relace. Pokud chcete určit, které sloupce souvisejí, budete muset vybrat nebo najet myší na řádek relace, aby se sloupce zvýraznily.
Směr křížového filtru
Každá relace modelu je definována směrem křížového filtru. Vaše nastavení určuje směry šíření filtrů. Možné možnosti křížového filtru jsou závislé na typu kardinality.
| Typ kardinality | Možnosti křížového filtru |
|---|---|
| 1:N (nebo M:1) | Jednotlivý Oba |
| Jeden na jednoho | Oba |
| mnoho-na-mnoho | Jedna (tabulka1 až tabulka2) Jednoduchý (Tabulka2 do Tabulky1) Oba |
Jednosměrný filtr znamená "pouze jeden směr" a oba znamená "oba směry". Relace, která filtruje v obou směrech, se běžně popisuje jako obousměrná.
U relací 1:N je směr křížového filtru vždy ze strany "jeden" a volitelně ze strany "N" (obousměrný). U relací 1:1 je směr křížového filtru vždy z obou tabulek. V případě relací M:N může být směr křížového filtru z jedné z tabulek nebo z obou tabulek. Všimněte si, že když typ kardinality obsahuje stranu "jedna", budou se filtry vždy šířit z této strany.
Pokud je směr křížového filtru nastaven na Obě, bude k dispozici další vlastnost. Když Power BI vynucuje pravidla zabezpečení na úrovni řádků (RLS), může použít obousměrné filtrování. Další informace o zabezpečení na úrovni řádků (RLS) najdete v tématu zabezpečení na úrovni řádků (RLS) v Power BI Desktopu.
Směr křížového filtru v rámci relace, včetně možnosti zakázání šíření filtru, můžete upravit pomocí modelového výpočtu. Toho dosáhnete pomocí funkce CROSSFILTER DAX.
Mějte na paměti, že obousměrné relace můžou mít negativní vliv na výkon. Pokus o konfiguraci obousměrné relace by navíc mohl vést k nejednoznačným cestám šíření filtru. V takovém případě se power BI Desktopu nemusí podařit potvrdit změnu relace a upozorní vás na chybovou zprávu. Power BI Desktop vám ale někdy umožní definovat nejednoznačné cesty relací mezi tabulkami. Řešení nejednoznačnosti cesty relace je popsáno dále v tomto článku.
Obousměrné filtrování doporučujeme používat jenom podle potřeby. Další informace najdete v tématu Pokyny k obousměrným relacím.
Návod
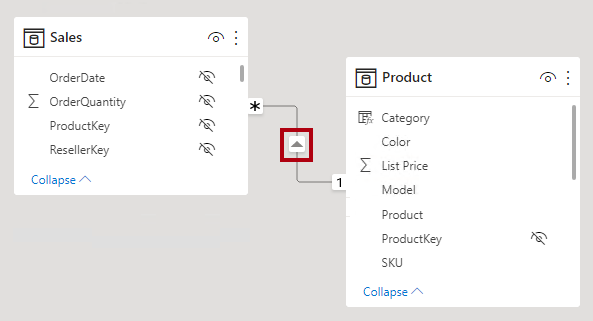
V zobrazení modelu Power BI Desktopu můžete vyložit směr křížového filtru relace všimnutím si šipkového zakončení podél linie relace. Jedna šipka představuje jednosměrný filtr ve směru šipky; Dvojitá šipka představuje obousměrnou relaci.
Aktivovat tuto relaci
Mezi dvěma tabulkami modelu může existovat pouze jedna aktivní cesta šíření filtru. Je však možné zavést další cesty relací, i když tyto relace musíte nastavit jako neaktivní. Neaktivní relace je možné aktivovat pouze během vyhodnocení výpočtu modelu. Toho dosáhnete pomocí funkce DAX USERELATIONSHIP.
Obecně doporučujeme definovat aktivní relace, kdykoli je to možné. Rozšiřují rozsah a potenciál, jak autoři sestav mohou váš model používat. Použití pouze aktivních relací znamená, že tabulky dimenzí rolí by měly být ve vašem modelu duplikovány.
Za určitých okolností však můžete definovat jednu nebo více neaktivních relací pro tabulku dimenzí rolí. Tento návrh můžete zvážit v těchto případech:
- Vizuály sestav není potřeba filtrovat podle různých rolí současně.
- Pomocí
USERELATIONSHIPfunkce DAX aktivujete konkrétní relaci pro relevantní výpočty modelu.
Další informace najdete v Pokynech pro aktivní a neaktivní relace.
Návod
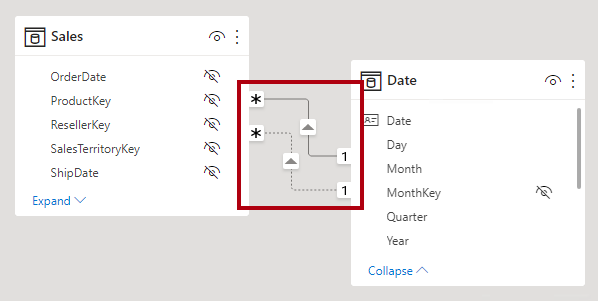
V zobrazení modelu Power BI Desktopu můžete interpretovat aktivní a neaktivní stav relace. Aktivní relace je reprezentována plnou čárou; Neaktivní relace je reprezentována přerušovanou čárou.
Předpokládat referenční integritu
Vlastnost Předpokládat referenční integritu je k dispozici pouze pro relace 1:N a 1:1 mezi dvěma tabulkami režimu úložiště DirectQuery, které patří do stejné zdrojové skupiny. Tuto vlastnost můžete povolit pouze v případě, že sloupec na straně N neobsahuje žádné NULL hodnoty.
Pokud je tato možnost povolená, nativní dotazy odeslané do zdroje dat spojí dvě tabulky dohromady pomocí metody INNER JOIN a nikoli .OUTER JOIN Obecně platí, že povolení této vlastnosti zlepšuje výkon dotazů, i když závisí na specifikách zdroje dat.
Tuto vlastnost vždy povolte, pokud mezi těmito dvěma tabulkami existuje omezení cizího klíče databáze. I když omezení cizího klíče neexistuje, zvažte povolení vlastnosti, pokud jste si jistí integritou dat.
Důležité
Pokud by se měla ohrozit integrita dat, vnitřní spojení eliminuje chybějící řádky mezi tabulkami. Představte si například tabulku Sales s hodnotou sloupce Idproduktu, která v související tabulce Product neexistuje. Šíření filtru z tabulky Product (Produkt) do tabulky Sales (Prodej) eliminuje řádky prodeje pro neznámé produkty. Výsledkem by bylo podhodnocené výsledky prodeje.
Další informace najdete v tématu Předpokládat nastavení referenční integrity v Power BI Desktopu.
Relevantní funkce jazyka DAX
Existuje několik funkcí DAX, které jsou relevantní pro relace modelu. Každá funkce je stručně popsána v následujícím seznamu s odrážkami:
- SOUVISEJÍCÍ: Načte hodnotu z "jedné" strany vztahu. Je užitečné při provádění výpočtů z různých tabulek, které se vyhodnocují v kontextu řádku .
- RELATEDTABLE: Načte tabulku řádků z mnohé strany relace.
- USERELATIONSHIP: Umožňuje výpočtu použít neaktivní relaci. (Tato funkce technicky upravuje váhu specifického neaktivního vztahu modelu a ovlivňuje tak jeho využití.) Je užitečná, pokud váš model zahrnuje tabulku rolového hraní dimenzí a rozhodnete se z ní vytvořit neaktivní relace. Tuto funkci můžete také použít k řešení nejednoznačnosti v cestách filtru.
- CROSSFILTER: Upraví směr křížového filtru relace (na jednu stranu nebo obě) nebo zakáže propagaci filtru (žádná). Je užitečné, když potřebujete změnit nebo ignorovat relace modelu během vyhodnocení konkrétního výpočtu.
- COMBINEVALUES: Spojí dva nebo více textových řetězců do jednoho textového řetězce. Účelem této funkce je podporovat relace s více sloupci v modelech DirectQuery, když tabulky patří do stejné zdrojové skupiny.
- TREATAS: Použije výsledek výrazu tabulky jako filtry na sloupce z nesouvisející tabulky. V pokročilých scénářích je užitečné, když chcete během vyhodnocení určitého výpočtu vytvořit virtuální vztah.
- Funkce rodič-potomek: Soubor souvisejících funkcí, které můžete použít k vytváření počítaných sloupců pro naturalizaci hierarchie rodič-potomek. Tyto sloupce pak můžete použít k vytvoření hierarchie s pevnou úrovní.
Vyhodnocení relace
Relace modelu jsou z hlediska vyhodnocení klasifikovány jako pravidelné nebo omezené. Nejedná se o konfigurovatelnou vlastnost relace. Ve skutečnosti je odvozena z typu kardinality a zdroje dat dvou souvisejících tabulek. Je důležité pochopit typ vyhodnocení, protože může dojít k výkonovým dopadům nebo důsledkům, pokud by došlo k narušení integrity dat. Tyto důsledky a důsledky integrity jsou popsány v tomto tématu.
Za prvé, některé teorie modelování je nutná k úplnému pochopení vyhodnocení vztahů.
Model importu nebo DirectQuery zjišťuje všechna data z mezipaměti Vertipaq nebo zdrojové databáze. V obou případech dokáže Power BI určit, že existuje jedna strana vztahu.
Složený model ale může obsahovat tabulky pomocí různých režimů úložiště (import, DirectQuery nebo duální) nebo více zdrojů DirectQuery. Každý zdroj, včetně mezipaměti Vertipaq importovaných dat, se považuje za zdrojovou skupinu. Relace modelu je pak možné klasifikovat jako uvnitř zdrojové skupiny nebo mezi zdrojovými skupinami. Relace uvnitř zdrojové skupiny spojuje dvě tabulky ve zdrojové skupině, zatímco relace mezi zdrojovými skupinami spojuje tabulky mezi dvěma zdrojovými skupinami. Mějte na paměti, že relace v modelech importu nebo DirectQuery jsou vždy uvnitř zdrojové skupiny.
Tady je příklad složeného modelu.
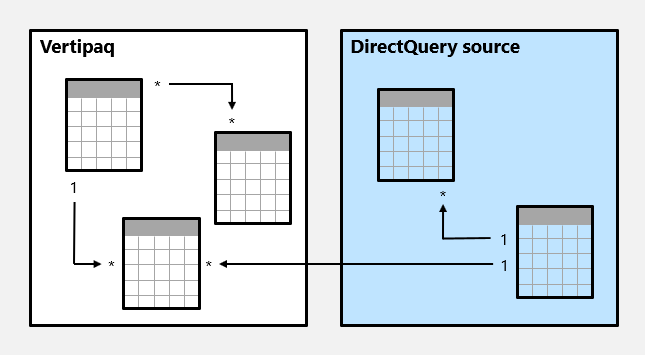
V tomto příkladu se složený model skládá ze dvou zdrojových skupin: zdrojové skupiny Vertipaq a zdrojové skupiny DirectQuery. Zdrojová skupina Vertipaq obsahuje tři tabulky a zdrojová skupina DirectQuery obsahuje dvě tabulky. Jedna relace mezi zdrojovými skupinami existuje k propojení tabulky ve zdrojové skupině Vertipaq s tabulkou ve zdrojové skupině DirectQuery.
Pravidelné relace
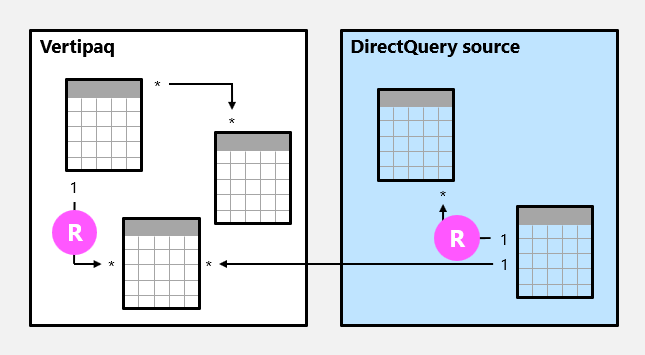
Relace modelu je standardní, když dotazovací mechanismus dokáže určit stranu relace jako "jedna". Potvrzuje se, že sloupec na straně "jeden" obsahuje jedinečné hodnoty. Všechny vztahy jedna ku mnoha uvnitř zdrojové skupiny jsou pravidelné vztahy.
V následujícím příkladu existují dvě běžné relace, obě jsou označené jako R. Relace zahrnují relaci 1:N obsaženou ve zdrojové skupině Vertipaq a relaci 1:N obsaženou ve zdroji DirectQuery.
Pro modely importu, kde jsou všechna data uložená v mezipaměti Vertipaq, vytvoří Power BI datovou strukturu pro každou běžnou relaci v době aktualizace dat. Datové struktury se skládají z indexovaných mapování všech hodnot sloupců na sloupec a jejich účelem je zrychlit spojování tabulek v době dotazu.
V době dotazu umožňují pravidelné relace rozšíření tabulky. Rozšíření tabulky vede k vytvoření virtuální tabulky zahrnutím nativních sloupců základní tabulky a následným rozbalením do souvisejících tabulek. Pro tabulky importu se rozšíření tabulky provádí v dotazovacím stroji; pro tabulky DirectQuery se provádí v nativním dotazu odeslaném do zdrojové databáze (pokud Předpokládat referenční integritu vlastnost není povolená). Dotazovací modul pak funguje s rozbalenou tabulkou a použije filtry a seskupování podle hodnot ve sloupcích rozbalené tabulky.
Poznámka:
Neaktivní relace jsou také rozšířeny, i v případě, že je relace nepoužívána ve výpočtu. Obousměrné relace nemají žádný vliv na rozšíření tabulky.
U relací 1:N se rozšíření tabulky provádí ze strany "mnoho" na stranu "jedna" pomocí LEFT OUTER JOIN sémantiky. Pokud neexistuje odpovídající hodnota z "mnoha" na stranu "jedna", přidá se do tabulky na straně "jedna" prázdný virtuální řádek. Toto chování platí jenom pro běžné relace, ne pro omezené relace.
K rozšíření tabulky dochází také u relací typu jeden na jednoho uvnitř zdrojové skupiny, ale s použitím FULL OUTER JOIN sémantiky. Tento typ spojení zajistí, že se prázdné virtuální řádky v případě potřeby přidají na obě strany.
Prázdné virtuální řádky jsou efektivně neznámých členů. Neznámí členové představují porušení referenční integrity, kdy na straně "mnoho" neexistuje odpovídající hodnota na straně "jedna". V ideálním případě by tyto prázdné hodnoty neměly existovat. Mohou být eliminovány čištěním nebo opravou zdrojových dat.
Tady je postup, jak rozšíření tabulky funguje s animovaným příkladem.

V tomto příkladu se model skládá ze tří tabulek: Category (Kategorie), Product (Produkt) a Sales (Prodej). Tabulka Category se vztahuje k tabulce Product s relací 1:N a tabulka Product se vztahuje k tabulce Sales s relací 1:N. Tabulka Category (Kategorie ) obsahuje dva řádky, tabulka Product (Produkt ) obsahuje tři řádky a tabulky Sales (Prodej ) obsahují pět řádků. Na obou stranách všech relací existují odpovídající hodnoty, což znamená, že neexistují žádná porušení referenční integrity. Zobrazí se tabulka rozšířená podle času dotazu. Tabulka se skládá ze sloupců ze všech tří tabulek. Jedná se o denormalizovaný pohled na data obsažená ve třech tabulkách. Nový řádek se přidá do tabulky Sales (Prodej ) a má hodnotu identifikátoru produkce (9), která nemá v tabulce Product žádnou odpovídající hodnotu. Jedná se o porušení referenční integrity. V rozšířené tabulce má nový řádek prázdné hodnoty pro sloupce Category a Product.
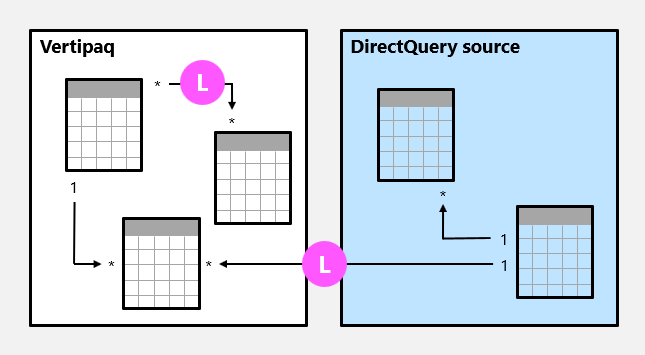
Omezené relace
Relace modelu je omezená, pokud neexistuje žádná zaručená "jedna" strana. K omezenému vztahu může dojít ze dvou důvodů:
- Relace používá typ kardinality M:N (i když jeden nebo oba sloupce obsahují jedinečné hodnoty).
- Relace je napříč zdrojovými skupinami, což může být případ pouze složených modelů.
V následujícím příkladu existují dvě omezené relace, obě jsou označené jako L. Tyto dvě relace zahrnují relaci M:N obsaženou ve zdrojové skupině Vertipaq a relaci 1:N mezi zdrojovými skupinami.
U modelů importu se datové struktury nikdy nevytvořily pro omezené relace. V takovém případě Power BI vyřeší spojení tabulek v době dotazu.
K rozšíření tabulky nikdy nedojde u omezených relací. Spojení tabulek se dosahuje pomocí sémantiky INNER JOIN a z tohoto důvodu se nepřidají prázdné virtuální řádky, které by kompenzovaly porušení referenční integrity.
Existují další omezení související s omezenými relacemi:
- Funkci
RELATEDDAX nelze použít k načtení hodnot sloupce na straně 1. - Vynucení RLS (zabezpečení na úrovni řádků) má omezení topologie.
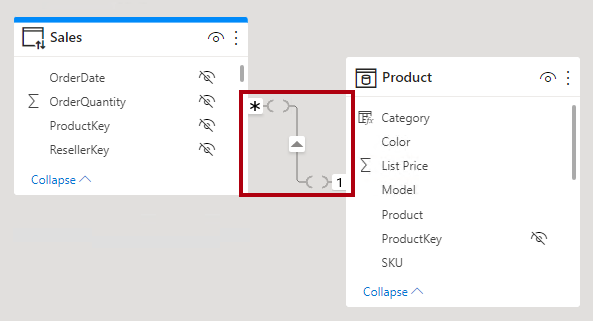
Návod
V zobrazení modelu Power BI Desktopu můžete interpretovat relaci jako omezenou. Omezený vztah je reprezentován závorkami () za indikátory kardinality.
Řešení nejednoznačnosti ve vztahové cestě
Obousměrné relace mohou představovat více cest šíření filtru, a tím i nejednoznačnost mezi tabulkami modelu. Při vyhodnocování nejednoznačnosti vybere Power BI cestu šíření filtru podle priority a váhy.
Priorita
Prioritní vrstvy definují posloupnost pravidel, která Power BI používá k řešení nejednoznačnosti cesty relace. Pravidlo, které se shoduje jako první, určuje cestu, kterou se Power BI vydá. Každé pravidlo níže popisuje, jak filtry přecházejí ze zdrojové tabulky do cílové tabulky.
- Cesta složená z vztahů jednoho k mnoha.
- Cesta skládající se z relací 1:N nebo M:N.
- Cesta skládající se z relací mnoho na jednoho.
- Cesta skládající se z relací 1:N ze zdrojové tabulky do zprostředkující tabulky, následovaná relacemi M:1 ze zprostředkující tabulky do cílové tabulky.
- Cesta skládající se z relací 1:N nebo M:N ze zdrojové tabulky do zprostředkující tabulky následovaná relacemi M:1 nebo N:N z zprostředkující tabulky do cílové tabulky.
- Jakákoli jiná cesta.
Pokud je relace zahrnutá do všech dostupných cest, je ze všech cest vyřazena z úvahy.
Hmotnost
Každá relace v cestě má váhu. Ve výchozím nastavení je každá váha relace rovna, pokud se nepoužije funkce USERELATIONSHIP. Váha cesty je maximum všech vah vztahů podél cesty. Power BI používá váhy cesty k vyřešení nejednoznačnosti mezi více cestami ve stejné vrstvě priority. Nevybere cestu s nižší prioritou, ale zvolí cestu s vyšší váhou. Počet relací v cestě nemá vliv na váhu.
Váhu relace můžete ovlivnit pomocí funkce USERELATIONSHIP. Váha je určena úrovní vnoření volání této funkce, přičemž nejvnitřnější volání má nejvyšší prioritu.
Podívejte se na následující příklad. Míra Product Sales přiřazuje vyšší váhu vztahu mezi Sales[ProductID] a Product[ProductID], následovaného vztahem mezi Inventory[ProductID] a Product[ProductID].
Product Sales =
CALCULATE(
CALCULATE(
SUM(Sales[SalesAmount]),
USERELATIONSHIP(Sales[ProductID], Product[ProductID])
),
USERELATIONSHIP(Inventory[ProductID], Product[ProductID])
)
Poznámka:
Pokud Power BI zjistí více tras, které mají stejnou prioritu a stejnou váhu, vrátí nejednoznačnou chybu cesty. V tomto případě musíte vyřešit nejednoznačnost ovlivněním váhy relace pomocí funkce USERELATIONSHIP nebo odebráním nebo úpravou relací modelu.
Předvolba výkonu
Následující seznam obsahuje pořadí výkonu šíření filtru od nejrychlejšího po nejpomalejší výkon:
- Interní relace typu 1:N v rámci zdrojové skupiny
- Relace modelu mnoho-na-mnoho dosažené pomocí zprostředkující tabulky, které zahrnují alespoň jednu obousměrnou relaci
- Vztahy s kardinalitou mnoho-ku-mnoha
- Vztahy mezi zdrojovými skupinami
Související obsah
Další informace o tomto článku najdete v následujících zdrojích informací:
- Pochopte hvězdicové schéma a jeho význam pro Power BI
- Pokyny pro relaci 1:1
- Pokyny k relacím M:N
- Pokyny k aktivní a neaktivní relaci
- Poradenství pro obousměrné vztahy
- Pokyny k řešení potíží ve vztazích
- Video: Co dělat a nedělat při práci s relacemi v Power BI
- Otázky? Zkuste se zeptat komunity Power BI
- Návrhy? Přispívání nápadů ke zlepšení Power BI