TripPin část 5 - Stránkování
Tento vícedílný kurz popisuje vytvoření nového rozšíření zdroje dat pro Power Query. Tento kurz se má provést postupně – každá lekce vychází z konektoru vytvořeného v předchozích lekcích a postupně přidává do konektoru nové funkce.
V této lekci:
- Přidání podpory stránkování do konektoru
Mnoho rozhraní REST API vrací data na "stránkách", což vyžaduje, aby klienti udělali více žádostí o spojení výsledků dohromady. I když existují některé běžné konvence pro stránkování (například RFC 5988), obecně se liší od rozhraní API až po rozhraní API. TripPin je služba OData a standard OData definuje způsob stránkování pomocí hodnot odata.nextLink vrácených v těle odpovědi.
Aby se zjednodušily předchozí iterace konektoru, TripPin.Feed funkce nevěděla o stránce. Jednoduše parsoval jakýkoli json, který se vrátil z požadavku, a naformátoval ho jako tabulku. Ti, kteří znají protokol OData, si možná všimli, že ve formátu odpovědi bylo provedeno mnoho nesprávných předpokladů (například za předpokladu, že existuje value pole obsahující pole záznamů).
V této lekci vylepšíte logiku zpracování odpovědí tím, že si ji uvědomíte o stránce. V budoucích kurzech je logika zpracování stránek robustnější a schopná zpracovat více formátů odpovědí (včetně chyb ze služby).
Poznámka:
Nemusíte implementovat vlastní logiku stránkování s konektory založenými na OData.Feed, protože zpracovává vše za vás automaticky.
Kontrolní seznam pro stránkování
Při implementaci podpory stránkování budete muset znát následující informace o rozhraní API:
- Jak si vyžádáte další stránku dat?
- Zahrnuje mechanismus stránkování výpočet hodnot nebo extrahujete adresu URL další stránky z odpovědi?
- Jak poznáte, kdy zastavit stránkování?
- Souvisí stránkování s parametry, o které byste měli vědět? (například "velikost stránky")
Odpověď na tyto otázky má vliv na způsob implementace logiky stránkování. I když existuje určité množství opětovného použití kódu napříč implementacemi stránkování (například použití Table.GenerateByPage, většina konektorů nakonec vyžaduje vlastní logiku.
Poznámka:
Tato lekce obsahuje logiku stránkování pro službu OData, která se řídí konkrétním formátem. Projděte si dokumentaci k rozhraní API a zjistěte změny, které budete muset v konektoru provést, aby podporovalo jeho stránkovací formát.
Přehled stránkování OData
Stránkování OData je řízeno poznámkami nextLink obsaženými v datové části odpovědi. Hodnota nextLink obsahuje adresu URL na další stránku dat. Zjistíte, jestli v odpovědi najdete další stránku dat, a to vyhledáním odata.nextLink pole v nejkrajnějším objektu. Pokud pole neexistuje odata.nextLink , přečetli jste si všechna data.
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
Některé služby OData umožňují klientům zadat maximální předvolbu velikosti stránky, ale záleží na službě, jestli ji má respektovat nebo ne. Power Query by měl být schopný zpracovat odpovědi libovolné velikosti, takže si nemusíte dělat starosti s určením předvolby velikosti stránky – můžete podporovat jakoukoli službu, která na vás vyvolá.
Další informace o stránkování řízené serverem najdete ve specifikaci OData.
Testování TripPinu
Před opravou implementace stránkování potvrďte aktuální chování rozšíření z předchozího kurzu. Následující testovací dotaz načte Lidé tabulku a přidá indexový sloupec, který zobrazí aktuální počet řádků.
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Zapněte Fiddler a spusťte dotaz v sadě Power Query SDK. Všimněte si, že dotaz vrátí tabulku s osmi řádky (index 0 až 7).
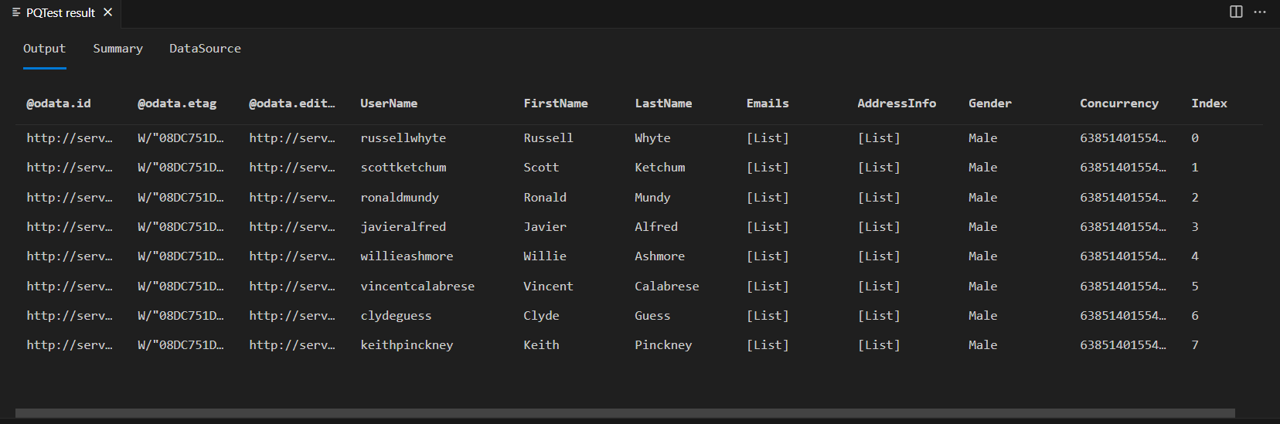
Pokud se podíváte na text odpovědi od fiddleru, uvidíte, že ve skutečnosti obsahuje @odata.nextLink pole, které označuje, že je k dispozici více stránek dat.
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
Implementace stránkování pro TripPin
Teď v rozšíření provedete následující změny:
- Import společné
Table.GenerateByPagefunkce - Přidání
GetAllPagesByNextLinkfunkce, která se používáTable.GenerateByPagek připevnění všech stránek GetPagePřidání funkce, která může číst jednu stránku datGetNextLinkPřidání funkce pro extrahování další adresy URL z odpovědi- Aktualizace
TripPin.Feedpro použití nových funkcí čtečky stránek
Poznámka:
Jak jsme uvedli dříve v tomto kurzu, logika stránkování se bude mezi zdroji dat lišit. Implementace se zde pokusí rozdělit logiku na funkce, které by měly být opakovaně použitelné pro zdroje, které používají další odkazy vrácené v odpovědi.
Table.GenerateByPage
Pokud chcete zkombinovat (potenciálně) více stránek vrácených zdrojem do jedné tabulky, použijeme Table.GenerateByPage. Tato funkce přebírá jako svůj argument getNextPage funkci, která by měla provést přesně to, co její název naznačuje: načíst další stránku dat. Table.GenerateByPage bude funkci opakovaně volat getNextPage , pokaždé, když jí předáte výsledky vytvořené při posledním volání, dokud se nevrátí k null signálu, že nejsou k dispozici žádné další stránky.
Vzhledem k tomu, že tato funkce není součástí standardní knihovny Power Query, budete muset zkopírovat zdrojový kód do souboru .pq.
Implementace GetAllPagesByNextLink
Tělo funkce GetAllPagesByNextLink implementuje getNextPage argument funkce pro Table.GenerateByPage. GetPage Zavolá funkci a načte adresu URL další stránky dat z NextLink pole záznamu meta z předchozího volání.
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
Implementace getpage
Funkce GetPage použije web.Contents k načtení jedné stránky dat ze služby TripPin a převod odpovědi na tabulku. Předá odpověď z Web.Contents funkci GetNextLink k extrahování adresy URL další stránky a nastaví ji na meta záznam vrácené tabulky (stránka dat).
Tato implementace je mírně upravená verze TripPin.Feed volání z předchozích kurzů.
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
Implementace GetNextLinku
Vaše GetNextLink funkce jednoduše zkontroluje text odpovědi pro @odata.nextLink pole a vrátí její hodnotu.
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
Spojení všech součástí dohromady
Posledním krokem implementace logiky stránkování je aktualizace TripPin.Feed pro použití nových funkcí. Prozatím jednoduše voláte , GetAllPagesByNextLinkale v dalších kurzech budete přidávat nové funkce (například vynucování schématu a logiku parametru dotazu).
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
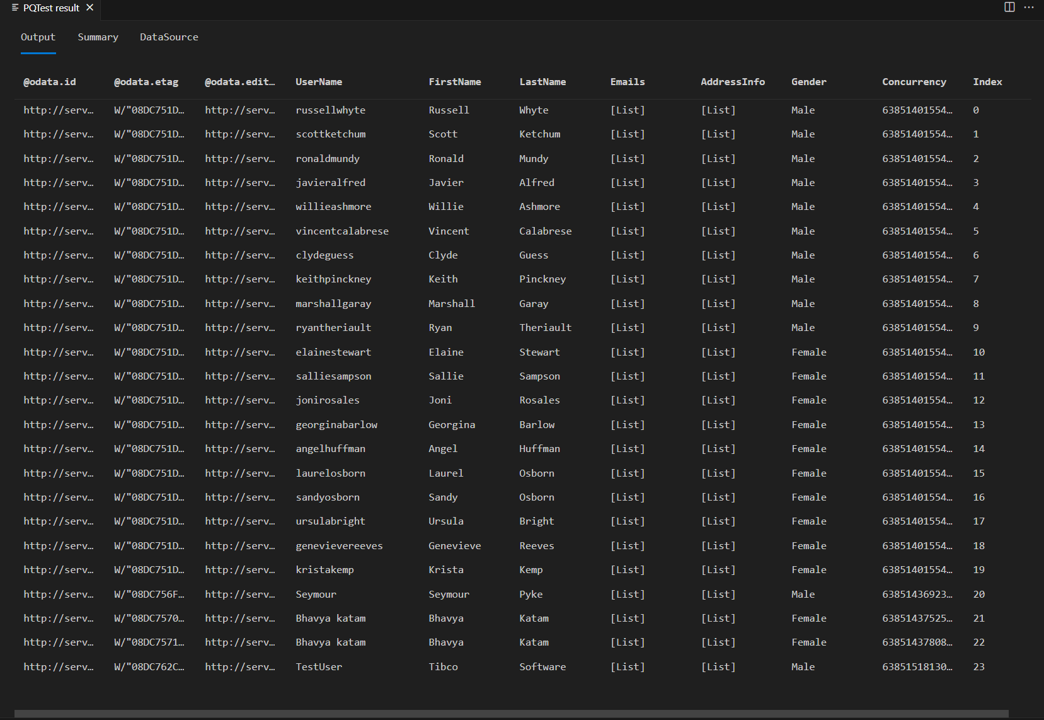
Pokud znovu spustíte stejný testovací dotaz z dřívějšího kurzu, měli byste teď vidět čtečku stránky v akci. Měli byste také vidět, že v odpovědi máte místo osmi řádků 24 řádků.
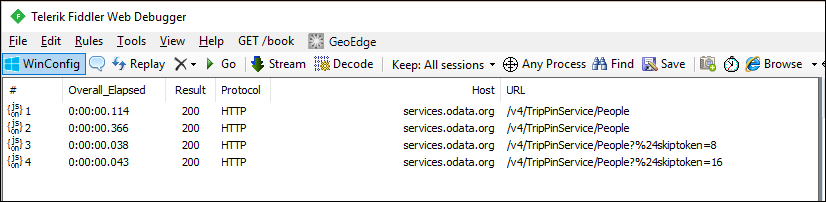
Pokud se podíváte na požadavky ve fiddleru, měli byste teď vidět samostatné požadavky na každou stránku dat.
Poznámka:
Všimnete si duplicitních požadavků na první stránku dat ze služby, což není ideální. Dodatečný požadavek je výsledkem chování kontroly schématu modulu M. Prozatím tento problém ignorujte a v dalším kurzu ho vyřešte, kde použijete explicitní schéma.
Závěr
Tato lekce vám ukázala, jak implementovat podporu stránkování pro rozhraní REST API. I když se logika bude pravděpodobně lišit mezi rozhraními API, model vytvořený zde by měl být opakovaně použitelný s menšími úpravami.
V další lekci se podíváme na to, jak použít explicitní schéma pro vaše data, a to nad rámec jednoduchých text a number datových typů, ze Json.Documentkteré získáte .