TripPin část 6 – schéma
Tento vícedílný kurz popisuje vytvoření nového rozšíření zdroje dat pro Power Query. Tento kurz se má provést postupně – každá lekce vychází z konektoru vytvořeného v předchozích lekcích a postupně přidává do konektoru nové funkce.
V této lekci:
- Definování pevného schématu pro rozhraní REST API
- Dynamické nastavení datových typů pro sloupce
- Vynucení struktury tabulky, aby nedocházelo k chybám transformace kvůli chybějícím sloupcům
- Skrytí sloupců ze sady výsledků
Jednou z velkých výhod služby OData oproti standardnímu rozhraní REST API je její $metadata definice. Dokument $metadata popisuje data nalezená v této službě, včetně schématu pro všechny entity (tabulky) a pole (sloupce). Funkce OData.Feed používá tuto definici schématu k automatickému nastavení informací o datovém typu, takže místo získání všech textových a číselných polí (jako byste od Json.Document) získali data, celá čísla, časy a tak dále, což poskytuje lepší celkové uživatelské prostředí.
Mnoho rozhraní REST API nemá způsob, jak programově určit jejich schéma. V těchto případech budete muset do konektoru zahrnout definice schématu. V této lekci definujete jednoduché pevně zakódované schéma pro každou z tabulek a vynutíte schéma u dat, která ze služby čtete.
Poznámka:
Zde popsaný přístup by měl fungovat pro mnoho služeb REST. Budoucí lekce budou vycházet z tohoto přístupu rekurzivně vynucováním schémat ve strukturovaných sloupcích (záznam, seznam, tabulka) a poskytují ukázkové implementace, které můžou programově generovat tabulku schématu z dokumentů schématu CSDL nebo JSON .
Vynucování schématu u dat vrácených konektorem má celkově několik výhod, například:
- Nastavení správných datových typů
- Odebrání sloupců, které se koncovým uživatelům nemusí zobrazovat (například interní ID nebo informace o stavu)
- Zajištění, aby každá stránka dat měla stejný obrazec přidáním všech sloupců, které můžou chybět v odpovědi (běžný způsob, jak rozhraní REST API označit pole, by mělo být null)
Zobrazení existujícího schématu pomocí Table.Schema
Konektor vytvořený v předchozí lekci zobrazí tři tabulky ze služby TripPin –AirlinesAirports a People. Spuštěním následujícího dotazu zobrazte Airlines tabulku:
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
data
Ve výsledcích se zobrazí čtyři vrácené sloupce:
- @odata.id
- @odata.editLink
- AirlineCode
- Název
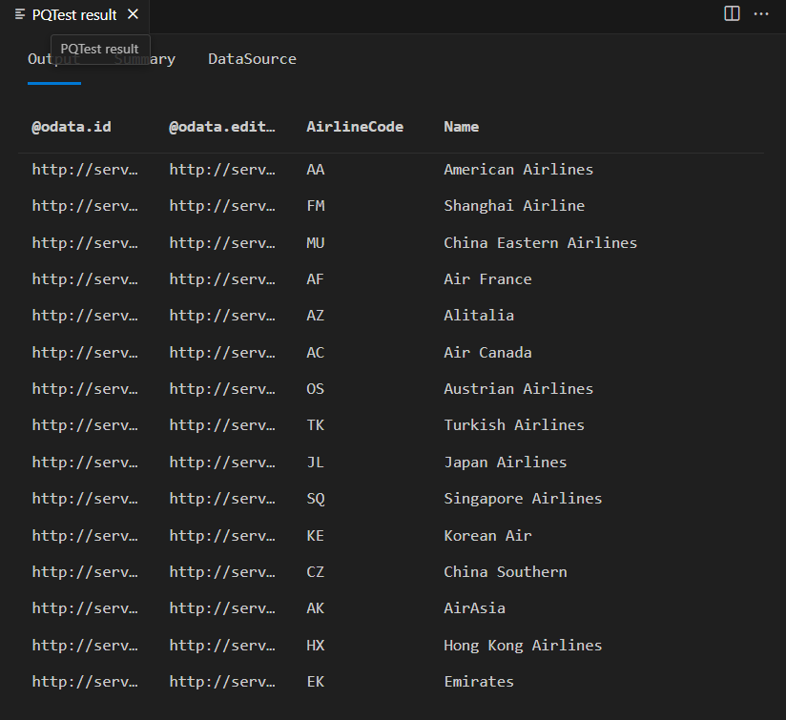
Sloupce "@odata.*" jsou součástí protokolu OData, a ne něco, co byste chtěli nebo potřebovali zobrazit koncovým uživatelům vašeho konektoru. AirlineCode a Name jsou to dva sloupce, které chcete zachovat. Pokud se podíváte na schéma tabulky (pomocí užitečné funkce Table.Schema ), můžete vidět, že všechny sloupce v tabulce mají datový typ Any.Type.
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
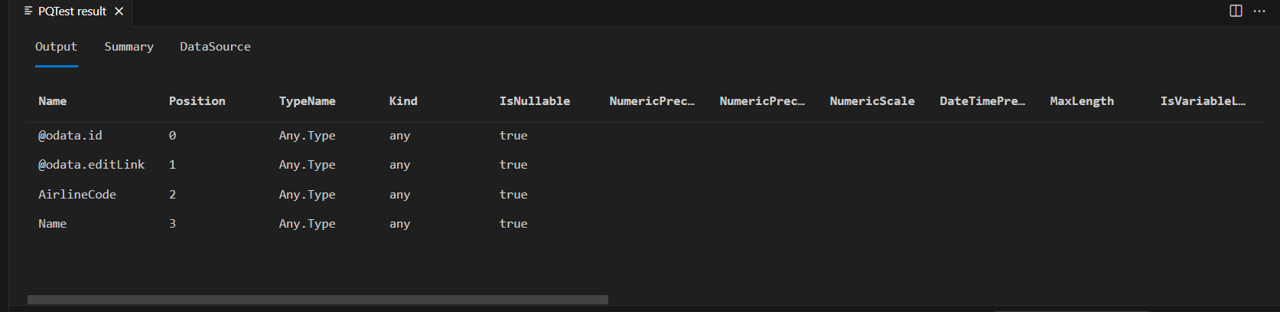
Table.Schema vrací mnoho metadat o sloupcích v tabulce, včetně názvů, pozic, informací o typu a mnoha pokročilých vlastností, jako je přesnost, měřítko a MaxLength.
Budoucí lekce budou poskytovat vzory návrhu pro nastavení těchto pokročilých vlastností, ale prozatím se potřebujete zabývat pouze přiřazeným typem (TypeName), primitivním typem (Kind) a to, jestli hodnota sloupce může mít hodnotu null (IsNullable).
Definování jednoduché tabulky schématu
Tabulka schématu se bude skládat ze dvou sloupců:
| Column | Detaily |
|---|---|
| Název | Název sloupce. Musí se shodovat s názvem ve výsledcích vrácených službou. |
| Typ | Datový typ M, který nastavíte. Může to být primitivní typ (text, number, datetimeatd.) nebo přiřazený typ (Int64.Typeatd Currency.Type.). |
Pevně zakódovaná tabulka schématu Airlines pro tabulku nastaví její AirlineCode a Name sloupce na text, a vypadá takto:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
});
Tabulka Airports obsahuje čtyři pole, která chcete zachovat (včetně jednoho typu record):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
});
People Nakonec tabulka obsahuje sedm polí, včetně seznamů (Emails, AddressInfo), sloupce s možnou hodnotou null (Gender) a sloupce s přiřazeným typem (Concurrency).
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
Pomocná funkce SchemaTransformTable
Pomocná SchemaTransformTable funkce popsaná níže se použije k vynucení schémat ve vašich datech. Přebírá následující parametry:
| Parametr | Typ | Popis |
|---|---|---|
| table | table | Tabulka dat, pro která chcete vynutit schéma |
| schema | table | Tabulka schématu pro čtení informací o sloupci z, s následujícím typem: type table [Name = text, Type = type]. |
| enforceSchema | Číslo | (volitelné) Výčet, který řídí chování funkce. Výchozí hodnota ( EnforceSchema.Strict = 1) zajišťuje, aby výstupní tabulka odpovídala tabulce schématu, kterou poskytla, přidáním chybějících sloupců a odebráním dalších sloupců. Možnost EnforceSchema.IgnoreExtraColumns = 2 lze použít k zachování dalších sloupců ve výsledku. Při EnforceSchema.IgnoreMissingColumns = 3 použití se budou ignorovat chybějící sloupce i nadbytečné sloupce. |
Logika pro tuto funkci vypadá přibližně takto:
- Zjistěte, jestli ve zdrojové tabulce chybí nějaké sloupce.
- Určete, jestli existují nějaké další sloupce.
- Ignorovat strukturované sloupce (typu
list,recordatable) a sloupce nastavené natype any. - K nastavení jednotlivých typů sloupců použijte Table.TransformColumnTypes .
- Změnit pořadí sloupců podle pořadí, ve kterém se zobrazují v tabulce schématu
- Nastavte typ v samotné tabulce pomocí Value.ReplaceType.
Poznámka:
Posledním krokem k nastavení typu tabulky bude potřeba, aby uživatelské rozhraní Power Query při prohlížení výsledků v editoru dotazů odvodily informace o typu. Tím se odebere problém s dvojitým požadavkem, který jste viděli na konci předchozího kurzu.
Do rozšíření můžete zkopírovat a vložit následující pomocný kód:
EnforceSchema.Strict = 1; // Add any missing columns, remove extra columns, set table type
EnforceSchema.IgnoreExtraColumns = 2; // Add missing columns, do not remove extra columns
EnforceSchema.IgnoreMissingColumns = 3; // Do not add or remove columns
SchemaTransformTable = (table as table, schema as table, optional enforceSchema as number) as table =>
let
// Default to EnforceSchema.Strict
_enforceSchema = if (enforceSchema <> null) then enforceSchema else EnforceSchema.Strict,
// Applies type transforms to a given table
EnforceTypes = (table as table, schema as table) as table =>
let
map = (t) => if Type.Is(t, type list) or Type.Is(t, type record) or t = type any then null else t,
mapped = Table.TransformColumns(schema, {"Type", map}),
omitted = Table.SelectRows(mapped, each [Type] <> null),
existingColumns = Table.ColumnNames(table),
removeMissing = Table.SelectRows(omitted, each List.Contains(existingColumns, [Name])),
primativeTransforms = Table.ToRows(removeMissing),
changedPrimatives = Table.TransformColumnTypes(table, primativeTransforms)
in
changedPrimatives,
// Returns the table type for a given schema
SchemaToTableType = (schema as table) as type =>
let
toList = List.Transform(schema[Type], (t) => [Type=t, Optional=false]),
toRecord = Record.FromList(toList, schema[Name]),
toType = Type.ForRecord(toRecord, false)
in
type table (toType),
// Determine if we have extra/missing columns.
// The enforceSchema parameter determines what we do about them.
schemaNames = schema[Name],
foundNames = Table.ColumnNames(table),
addNames = List.RemoveItems(schemaNames, foundNames),
extraNames = List.RemoveItems(foundNames, schemaNames),
tmp = Text.NewGuid(),
added = Table.AddColumn(table, tmp, each []),
expanded = Table.ExpandRecordColumn(added, tmp, addNames),
result = if List.IsEmpty(addNames) then table else expanded,
fullList =
if (_enforceSchema = EnforceSchema.Strict) then
schemaNames
else if (_enforceSchema = EnforceSchema.IgnoreMissingColumns) then
foundNames
else
schemaNames & extraNames,
// Select the final list of columns.
// These will be ordered according to the schema table.
reordered = Table.SelectColumns(result, fullList, MissingField.Ignore),
enforcedTypes = EnforceTypes(reordered, schema),
withType = if (_enforceSchema = EnforceSchema.Strict) then Value.ReplaceType(enforcedTypes, SchemaToTableType(schema)) else enforcedTypes
in
withType;
Aktualizace konektoru TripPin
Teď v konektoru provedete následující změny, které použijí nový kód vynucení schématu.
- Definujte tabulku hlavního schématu (
SchemaTable), která obsahuje všechny definice schématu. - Aktualizujte parametr
TripPin.FeedaGetPageGetAllPagesByNextLinkpřijměte hoschema. - Vynucujte schéma v
GetPagesouboru . - Aktualizujte kód navigační tabulky tak, aby všechny tabulky zabalily voláním nové funkce (
GetEntity). Díky tomu budete mít větší flexibilitu při práci s definicemi tabulek v budoucnu.
Tabulka hlavního schématu
Teď sloučit definice schématu do jedné tabulky a přidat pomocnou funkci (GetSchemaForEntity), která umožňuje vyhledat definici na základě názvu entity (například GetSchemaForEntity("Airlines")).
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})},
{"Airports", #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})},
{"People", #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})}
});
GetSchemaForEntity = (entity as text) as table => try SchemaTable{[Entity=entity]}[SchemaTable] otherwise error "Couldn't find entity: '" & entity &"'";
Přidání podpory schématu do datových funkcí
Teď do parametru TripPin.Feed, GetPagea GetAllPagesByNextLink funkcí přidáte volitelný schema parametr.
To vám umožní předat schéma (pokud chcete) stránkovacím funkcím, kde se použije na výsledky, které vrátíte ze služby.
TripPin.Feed = (url as text, optional schema as table) as table => ...
GetPage = (url as text, optional schema as table) as table => ...
GetAllPagesByNextLink = (url as text, optional schema as table) as table => ...
Také aktualizujete všechna volání těchto funkcí, abyste měli jistotu, že schéma předáváte správně.
Vynucení schématu
Ve vaší GetPage funkci se provede skutečné vynucení schématu.
GetPage = (url as text, optional schema as table) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value]),
// enforce the schema
withSchema = if (schema <> null) then SchemaTransformTable(data, schema) else data
in
withSchema meta [NextLink = nextLink];
Poznámka:
Tato GetPage implementace používá Table.FromRecords k převodu seznamu záznamů v odpovědi JSON na tabulku.
Hlavní nevýhodou použití Table.FromRecords je, že předpokládá, že všechny záznamy v seznamu mají stejnou sadu polí.
To funguje pro službu TripPin, protože záznamy OData jsou guarenteed obsahovat stejná pole, ale nemusí to být případ všech rozhraní REST API.
Robustnější implementace by používala kombinaci Table.FromList a Table.ExpandRecordColumn.
Pozdější kurzy změní implementaci tak, aby získala seznam sloupců z tabulky schématu a zajistila, že během překladu JSON do M nedojde ke ztrátě nebo chybějícím sloupcům.
Přidání funkce GetEntity
Funkce GetEntity zabalí vaše volání do TripPin.Feed.
Vyhledá definici schématu na základě názvu entity a vytvoří úplnou adresu URL požadavku.
GetEntity = (url as text, entity as text) as table =>
let
fullUrl = Uri.Combine(url, entity),
schemaTable = GetSchemaForEntity(entity),
result = TripPin.Feed(fullUrl, schemaTable)
in
result;
Potom funkci aktualizujete TripPinNavTable tak, aby volala místo toho, aby všechna GetEntityvolání byla vložená.
Hlavní výhodou je, že vám umožní pokračovat v úpravách kódu sestavení entity, aniž byste se museli dotýkat logiky navigační tabulky.
TripPinNavTable = (url as text) as table =>
let
entitiesAsTable = Table.FromList(RootEntities, Splitter.SplitByNothing()),
rename = Table.RenameColumns(entitiesAsTable, {{"Column1", "Name"}}),
// Add Data as a calculated column
withData = Table.AddColumn(rename, "Data", each GetEntity(url, [Name]), type table),
// Add ItemKind and ItemName as fixed text values
withItemKind = Table.AddColumn(withData, "ItemKind", each "Table", type text),
withItemName = Table.AddColumn(withItemKind, "ItemName", each "Table", type text),
// Indicate that the node should not be expandable
withIsLeaf = Table.AddColumn(withItemName, "IsLeaf", each true, type logical),
// Generate the nav table
navTable = Table.ToNavigationTable(withIsLeaf, {"Name"}, "Name", "Data", "ItemKind", "ItemName", "IsLeaf")
in
navTable;
Spojení všech součástí dohromady
Po provedení všech změn kódu zkompilujte a znovu spusťte testovací dotaz, který volá Table.Schema tabulku Airlines.
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
Teď vidíte, že tabulka Airlines obsahuje jenom dva sloupce, které jste definovali ve schématu:
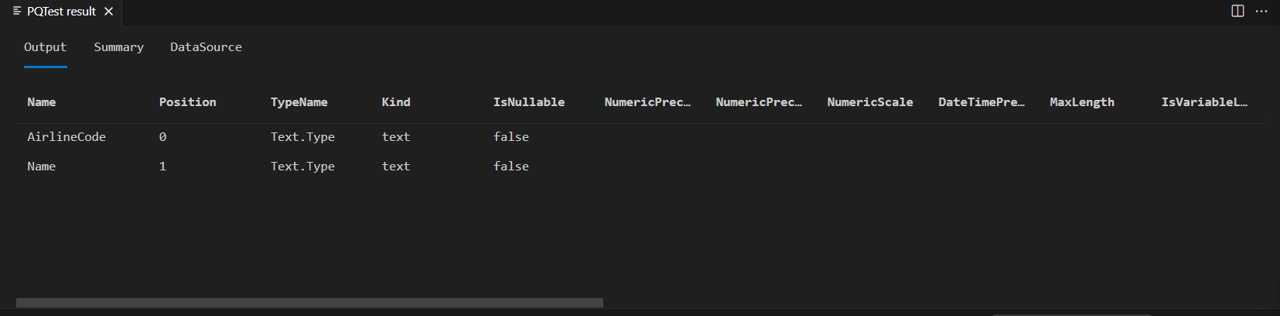
Pokud spustíte stejný kód proti Lidé tabulce...
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data]
in
Table.Schema(data)
Uvidíte, že přiřazený typ, který jste použili (Int64.Type), byl také správně nastavený.
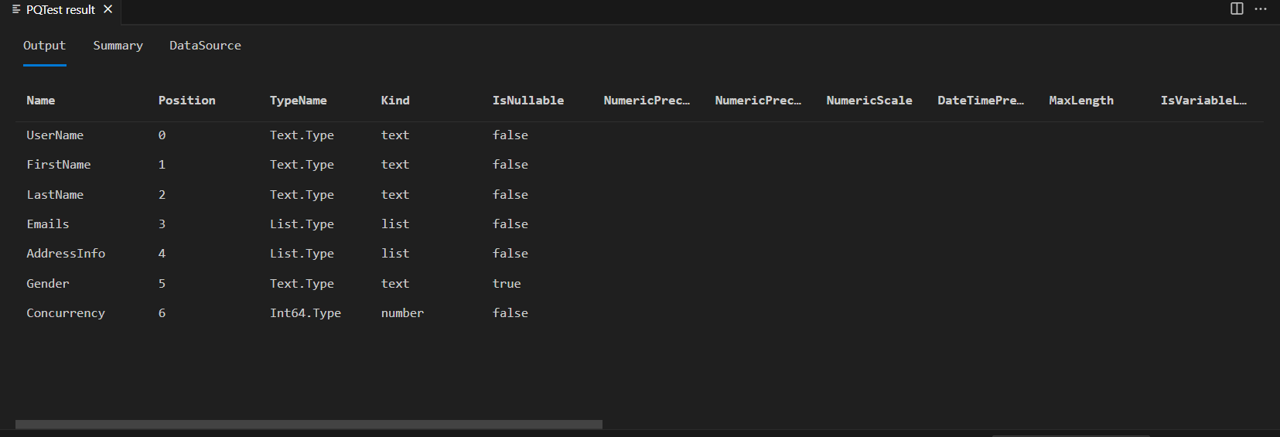
Důležité je uvědomit si, že tato implementace SchemaTransformTable nemění typy list a record sloupce, ale Emails sloupce jsou AddressInfo stále zadány jako list. Je to proto, že Json.Document správně mapuje pole JSON na seznamy M a objekty JSON na záznamy M. Pokud byste chtěli rozbalit sloupec seznamu nebo záznamu v Power Query, uvidíte, že všechny rozbalené sloupce budou mít libovolný typ. Budoucí kurzy zlepší implementaci, aby rekurzivně nastavila informace o typu pro vnořené komplexní typy.
Závěr
Tento kurz poskytl ukázkovou implementaci pro vynucování schématu u dat JSON vrácených ze služby REST. I když tato ukázka používá jednoduchý formát tabulky pevně zakódovaného schématu, je možné tento přístup rozšířit dynamickým vytvořením definice tabulky schématu z jiného zdroje, jako je soubor schématu JSON nebo služba metadat nebo koncový bod vystavený zdrojem dat.
Kromě úprav typů sloupců (a hodnot) kód také nastavuje správné informace o typu v samotné tabulce. Nastavení těchto informací o typu přináší výkon při spouštění v Power Query, protože uživatelské prostředí se vždy pokouší odvodit informace o typu, aby se zobrazily správné fronty uživatelského rozhraní koncovému uživateli, a volání odvozování můžou skončit aktivací dalších volání podkladových datových rozhraní API.
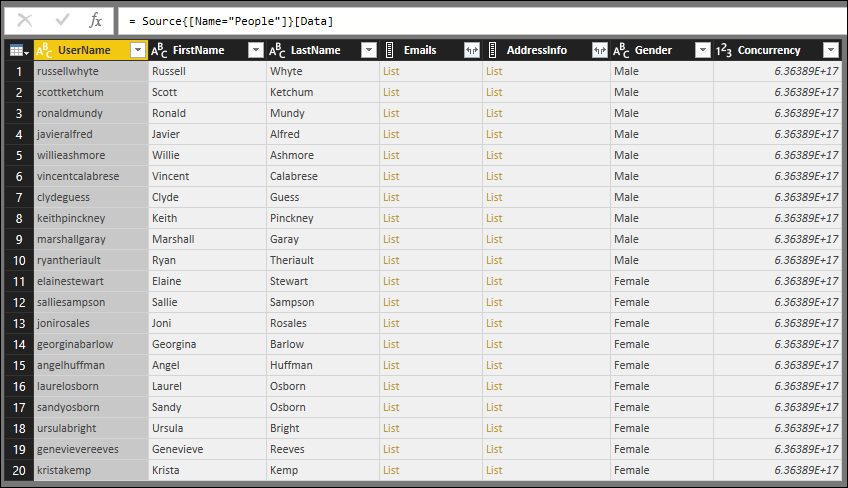
Pokud zobrazíte tabulku Lidé pomocí konektoru TripPin z předchozí lekce, uvidíte, že všechny sloupce mají ikonu typu libovolný (i sloupce, které obsahují seznamy):
Spuštění stejného dotazu s konektorem TripPin z této lekce uvidíte, že se informace o typu zobrazují správně.