Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
platí pro:![]() SQL Server
SQL Server
Pro vytvoření distribuované skupiny dostupnosti musíte vytvořit dvě skupiny dostupnosti, z nichž každá má svého vlastního posluchače. Tyto skupiny dostupnosti pak zkombinujete do distribuované skupiny dostupnosti. Následující kroky obsahují základní příklad jazyka Transact-SQL. Tento příklad nepokrývá všechny podrobnosti o vytváření skupin dostupnosti a posluchačů; místo toho se zaměřuje na zdůraznění klíčových požadavků.
Technický přehled distribuovaných skupin dostupnosti najdete v tématu Distribuované skupiny dostupnosti.
Požadavky
Pokud chcete nakonfigurovat distribuovanou skupinu dostupnosti, musíte mít následující:
- Podporovaná verze SQL Serveru.
Poznámka:
Pokud jste nakonfigurovali posluchač pro vaši skupinu dostupnosti na SQL Serveru na Azure VM pomocí názvu distribuované sítě (DNN), konfigurace distribuované skupiny dostupnosti nad vaší skupinou dostupnosti není podporována. Další informace najdete v tématu Interoperabilita funkcí SQL Serveru na virtuálním počítači Azure s naslouchacím procesem pro AG a DNN listener.
Povolení
Vyžaduje oprávnění CREATE AVAILABILITY GROUP na serveru k vytvoření skupiny dostupnosti a sysadmin k převzetí služeb při selhání distribuované skupiny dostupnosti.
Nastavte koncové body zrcadlení databáze tak, aby přijímaly všechny IP adresy.
Ujistěte se, že koncové body zrcadlení databáze mohou komunikovat mezi různými skupinami dostupnosti, které dohromady tvoří distribuovanou skupinu dostupnosti. Pokud je jedna skupina dostupnosti nastavená na konkrétní síť v koncovém bodu zrcadlení databáze, distribuovaná skupina dostupnosti nefunguje správně. Na každém serveru, který je hostitelem repliky v distribuované skupině dostupnosti, nastavte koncový bod zrcadlení databáze tak, aby naslouchal na všech IP adresách (LISTENER_IP = ALL).
Vytvořte koncový bod zrcadlení databáze, který bude naslouchat na všech IP adresách
Následující skript například vytvoří nový koncový bod zrcadlení databáze na portu TCP 5022, který naslouchá na všech IP adresách.
CREATE ENDPOINT [aodns-hadr]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATABASE_MIRRORING
(
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
Upravit existující koncový bod zrcadlení databáze, aby naslouchal na všech IP adresách
Následující skript například změní existující koncový bod zrcadlení databáze, aby naslouchal všem IP adresám.
ALTER ENDPOINT [aodns-hadr]
AS TCP
(
LISTENER_IP = ALL
);
GO
Vytvoření první skupiny dostupnosti
Vytvoření primární skupiny dostupnosti v prvním clusteru
Vytvořte skupinu dostupnosti na prvním Clusteru Windows Serveru pro převzetí služeb při selhání (WSFC). V tomto příkladu je skupina dostupnosti pojmenována ag1 pro databázi db1. Primární replika primární skupiny dostupnosti se označuje jako globální primární v distribuované skupině dostupnosti. Server1 je v tomto příkladu globálním primárním serverem.
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Poznámka:
Předchozí příklad používá automatické nasazení, kde SEEDING_MODE je nastaven na AUTOMATIC pro repliky i distribuovanou skupinu dostupnosti. Tato konfigurace nastaví sekundární repliky a sekundární skupinu dostupnosti tak, aby se automaticky naplnily bez nutnosti ručního zálohování a obnovení primární databáze.
Připojení sekundárních replik k primární skupině dostupnosti
Všechny sekundární repliky musí být připojené ke skupině dostupnosti pomocí ALTER AVAILABILITY GROUP s volbou JOIN. Vzhledem k tomu, že se v tomto příkladu používá automatické nasazení, musíte také použít ALTER AVAILABILITY GROUP s možností GRANT CREATE ANY DATABASE. Toto nastavení umožňuje skupině dostupnosti vytvořit databázi a začít ji automaticky sestavovat z primární repliky.
V tomto příkladu se pro připojení server2 ke skupině dostupnosti spustí následující příkazy na sekundární repliceag1. Skupina dostupnosti pak může vytvářet databáze na sekundárním serveru.
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
Poznámka:
Když skupina dostupnosti vytvoří databázi na sekundární replice, nastaví vlastníka databáze jako účet, který spustil ALTER AVAILABILITY GROUP příkaz k udělení oprávnění k vytvoření jakékoli databáze. Úplné informace najdete v tématu Udělení oprávnění k vytvoření databáze na sekundární replice skupině dostupnosti.
Vytvořte naslouchací komponentu pro primární skupinu dostupnosti
Dále přidejte naslouchací službu pro primární skupinu dostupnosti v první WSFC. V tomto příkladu je posluchač pojmenován ag1-listener. Podrobné pokyny k vytvoření naslouchacího procesu najdete v tématu Vytvoření nebo konfigurace naslouchacího procesu skupiny dostupnosti (SQL Server).
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
Vytvoření druhé skupiny dostupnosti
Pak ve druhé WSFC vytvořte druhou skupinu dostupnosti ag2. V tomto případě není databáze zadaná, protože je automaticky inicializována z primární dostupnostní skupiny. Primární replika sekundární skupiny dostupnosti se označuje jako předávač v distribuované skupině dostupnosti. V tomto příkladu je server3 předávačem.
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Poznámka:
- Sekundární skupina dostupnosti musí používat stejný koncový bod zrcadlení databáze (v tomto příkladu port 5022). Jinak se replikace zastaví po místním převzetí služeb při selhání systému.
- Základní skupiny dostupnosti by měly být ve stejném režimu dostupnosti – obě skupiny dostupnosti by měly být v synchronním režimu potvrzení nebo obě skupiny by měly být v asynchronním režimu potvrzení. Pokud si nejste jistí, který použít, nastavte oba na režim asynchronního potvrzování, dokud nebudete připraveni přepnout na záložní řešení.
Připojte sekundární repliky k sekundární skupině dostupnosti
V tomto příkladu se pro připojení server4 ke skupině dostupnosti spustí následující příkazy na sekundární repliceag2. Skupina dostupnosti pak může vytvářet databáze na sekundárním serveru, aby podporovala automatické seedování.
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
Vytvoření naslouchacího procesu pro sekundární skupinu dostupnosti
Dále přidejte naslouchací službu pro sekundární skupinu dostupnosti na druhém WSFC. V tomto příkladu je posluchač pojmenován ag2-listener. Podrobné pokyny k vytvoření naslouchacího procesu najdete v tématu Vytvoření nebo konfigurace naslouchacího procesu skupiny dostupnosti (SQL Server).
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
Vytvoření distribuované skupiny dostupnosti v prvním clusteru
Na první WSFC vytvořte distribuovanou skupinu dostupnosti (pojmenovanou distributedAG v tomto příkladu). Použijte příkaz CREATE AVAILABILITY GROUP s možností DISTRIBUOVANÉ . Parametr AVAILABILITY GROUP ON určuje skupiny ag1 dostupnosti členů a ag2.
Pokud chcete vytvořit distribuovanou skupinu dostupnosti pomocí automatického osazení, použijte následující Transact-SQL kód:
CREATE AVAILABILITY GROUP [distributedAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Poznámka:
LISTENER_URL určuje posluchače pro každou skupinu dostupnosti spolu s koncovým bodem zrcadlení databáze skupiny dostupnosti. V tomto příkladu se jedná o port 5022 (nikoli port 60173 použitý k vytvoření naslouchacího procesu). Pokud používáte nástroj pro vyrovnávání zatížení, například v Azure, přidejte pravidlo vyrovnávání zatížení pro port distribuované skupiny dostupnosti. Přidejte pravidlo pro naslouchací port, kromě portu instance SQL Serveru.
Zrušení automatického zasílání k předávači
Pokud je z jakéhokoli důvodu nutné zrušit inicializaci služby předávání před synchronizací dvou skupin dostupnosti, změňte distribuovanou skupinu dostupnosti nastavením parametru SEEDING_MODE služby předávání na MANUAL a okamžitě zrušte počáteční nastavení. Spusťte příkaz na globálním primárním serveru:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedAG]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
Připojte se ke skupině distribuované dostupnosti na druhém clusteru
Poté se připojte k distribuované skupině dostupnosti ve druhém WSFC.
Pokud se chcete připojit k distribuované skupině dostupnosti pomocí automatického osévání, použijte následující Transact-SQL kód:
ALTER AVAILABILITY GROUP [distributedAG]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Připojte se k databázi na sekundárním serveru druhé skupiny dostupnosti.
Pokud byla druhá skupina dostupnosti nastavená tak, aby používala automatické nasazení, přejděte ke kroku 2.
Pokud druhá skupina dostupnosti používá ruční počáteční nastavení, obnovte zálohu, kterou jste provedli v globální primární sekundární skupině dostupnosti:
RESTORE DATABASE [db1] FROM DISK = '<full backup location>' WITH NORECOVERY; RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY;Jakmile je databáze na sekundární replice druhé skupiny dostupnosti v režimu obnovení, musíte ji ručně připojit ke skupině dostupnosti.
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
Přechod na záložní řešení pro distribuovanou skupinu dostupnosti
Protože SQL Server 2022 (16.x) zavedl podporu pro distribuované skupiny dostupnosti nastavení REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, pokyny pro převod servisní zátěže v případě selhání se liší mezi SQL Serverem 2022 a novějšími verzemi, na rozdíl od SQL Serveru 2019 a starších verzí.
Pro distribuovanou skupinu dostupnosti je jediný podporovaný typ převzetí služeb při selhání ručně uživatelem iniciovaný FORCE_FAILOVER_ALLOW_DATA_LOSS. Abyste zabránili ztrátě dat, před převzetím služeb proveďte další kroky (popsané podrobně v této části) a zajistěte synchronizaci dat mezi oběma replikami.
V případě mimořádné situace, kdy je ztráta dat přijatelná, můžete zahájit přepnutí na záložní systém, aniž byste zajistili synchronizaci dat, spuštěním:
ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;
Stejný příkaz můžete použít pro přepnutí služeb na předávací server a také pro návrat k globálnímu primárnímu serveru.
Na SQL Serveru 2022 (16.x) a novějším můžete nakonfigurovat REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT nastavení pro distribuovanou skupinu dostupnosti, která je navržená tak, aby při převzetí služeb při selhání distribuované skupiny dostupnosti nebyla zaručena žádná ztráta dat. Pokud je toto nastavení nastaveno, postupujte podle kroků v této části, abyste převedli svou distribuovanou skupinu dostupnosti na záložní systém. Pokud nechcete toto nastavení používat REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT , postupujte podle pokynů k převzetí služeb při selhání distribuované skupiny dostupnosti v SQL Serveru 2019 a dřívějších verzích.
Poznámka:
Nastavení REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT na 1 znamená, že primární replika čeká na potvrzení transakcí na sekundární repliku, než se potvrdí na primární replice, což může snížit výkon. Při omezování nebo zastavování transakcí na globálním primárním serveru není nutné, aby se distribuovaná skupina dostupnosti synchronizovala v SQL Serveru 2022 (16.x), což může zlepšit výkon pro uživatelské transakce i distribuovanou synchronizaci skupin dostupnosti s nastavenou REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT hodnotou 1.
Postup, jak zajistit, aby nedošlo ke ztrátě dat
Pokud chcete zajistit, aby nedošlo ke ztrátě dat, musíte nejprve nakonfigurovat distribuovanou skupinu dostupnosti tak, aby podporovala žádnou ztrátu dat pomocí následujících kroků:
- Pokud se chcete připravit na převzetí služeb při selhání, ověřte, že globální primární a přesměrovávač jsou v
SYNCHRONOUS_COMMITrežimu. Pokud ne, nastavte je pomocí příkazuSYNCHRONOUS_COMMITna . - Nastavte distribuovanou skupinu dostupnosti na synchronní potvrzení pro globální primární i předávací modul.
- Počkejte, až se distribuovaná skupina dostupnosti synchronizuje.
- Na globálním primárním serveru nastavte nastavení distribuované skupiny
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITdostupnosti na hodnotu 1 pomocí funkce ALTER AVAILABILITY GROUP. - Ověřte, že všechny repliky v místních skupinách AG a distribuované skupině dostupnosti jsou v pořádku a distribuovaná skupina dostupnosti je SYNCHRONIZOVANÁ.
- Na globální primární replice nastavte roli distribuované skupiny dostupnosti na
SECONDARY, čímž se distribuovaná skupina dostupnosti stane nedostupnou. - Na předávacím serveru (zamýšleném novém primárním serveru) přepněte dostupnost distribuované skupiny při selhání pomocí ALTER AVAILABILITY GROUP s
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Na nové sekundární (předchozí globální primární replice) nastavte distribuovanou skupinu dostupnosti
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITna hodnotu 0. - Volitelné: Pokud jsou skupiny dostupnosti v zeměpisné vzdálenosti, která způsobuje latenci, změňte režim dostupnosti na
ASYNCHRONOUS_COMMIT. Tento krok vrátí změnu z prvního kroku, je-li to nutné.
Příklad T-SQL
Tato část obsahuje kroky v podrobném příkladu pro převzetí služeb při selhání distribuované skupiny dostupnosti pojmenované distributedAG pomocí jazyka Transact-SQL. Ukázkové prostředí má celkem 4 uzly pro distribuovanou skupinu dostupnosti. Primární globální skupina dostupnosti hostitelů N1 a N2ag1, zatímco skupina dostupnosti pro předávání hostitelů N3 a N4ag2. Distribuovaná skupina dostupnosti distributedAG provádí přesun změn z ag1 do ag2.
Dotaz na ověření
SYNCHRONOUS_COMMITna primarie místních skupin dostupnosti, které tvoří distribuovanou skupinu dostupnosti. Spusťte následující T-SQL přímo na předávacím serveru a globálním primárním serveru:SELECT DISTINCT ag.name AS [Availability Group], ar.replica_server_name AS [Replica], ar.availability_mode_desc AS [Availability Mode] FROM sys.availability_replicas AS ar INNER JOIN sys.availability_groups AS ag ON ar.group_id = ag.group_id INNER JOIN sys.dm_hadr_database_replica_states AS rs ON ar.group_id = rs.group_id AND ar.replica_id = rs.replica_id WHERE ag.name IN ('ag1', 'ag2') AND rs.is_primary_replica = 1 ORDER BY [Availability Group]; --if needed, to set a given replica to SYNCHRONOUS for node N1, default instance. If named, change from N1 to something like N1\SQL22 ALTER AVAILABILITY GROUP [testag] MODIFY REPLICA ON N'N1\SQL22' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Nastavte distribuovanou skupinu dostupnosti na synchronní potvrzení spuštěním následujícího kódu jak na globálním primárním, tak na přesměrovacím serveru:
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedAG] MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Poznámka:
V distribuované skupině dostupnosti závisí stav synchronizace mezi těmito dvěma skupinami dostupnosti na režimu dostupnosti obou replik. V případě synchronního režimu potvrzení musí mít jak aktuální primární skupina dostupnosti, tak i aktuální sekundární skupina dostupnosti režim dostupnosti
SYNCHRONOUS_COMMIT. Z tohoto důvodu musíte tento skript spustit na globální primární replice i na předávači.Počkejte, až se stav distribuované skupiny dostupnosti změní na
SYNCHRONIZED. Spusťte následující dotaz na globální primární server:-- Run this query on the Global Primary -- Check the results to see if synchronization_state_desc is SYNCHRONIZED SELECT ag.name, drs.database_id AS [Availability Group], db_name(drs.database_id) AS database_name, drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id WHERE ag.name = 'distributedAG' ORDER BY [Availability Group];Pokračujte po synchronization_state_desc
SYNCHRONIZEDskupiny dostupnosti .Pro SQL Server 2022 (16.x) a novější na globální primární sadě nastavte
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIThodnotu 1 pomocí následujícího jazyka T-SQL:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Ověřte, že jsou vaše skupiny dostupnosti na všech replikách v pořádku, a to dotazováním globálního primárního a předávacího procesu:
SELECT ag.name AS [AG Name], db_name(drs.database_id) AS database_name, ar.replica_server_name AS [replica], drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id INNER JOIN sys.availability_replicas AS ar ON drs.replica_id = ar.replica_id AND drs.replica_id = ar.replica_id WHERE ag.name IN ('ag1', 'ag2', 'distributedAG');Na globálním primárním serveru nastavte roli distribuované skupiny dostupnosti na
SECONDARY. V tomto okamžiku není distribuovaná skupina dostupnosti dostupná. Po dokončení tohoto kroku nemůžete vrátit zpět změny, dokud nebudou provedeny všechny zbývající kroky.ALTER AVAILABILITY GROUP distributedAG SET (ROLE = SECONDARY);Převzetí služeb při selhání z globálního primárního serveru provedete spuštěním následujícího dotazu na přepínači pro přepnutí skupin dostupnosti a znovu zprovoznění distribuované skupiny dostupnosti:
-- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;Po tomto kroku:
- Globální primární přechod z
N1doN3. - Předávání přechází z
N3doN1. - Distribuovaná skupina dostupnosti je nyní k dispozici.
- Globální primární přechod z
U nového forwarderu (předchozí globální primární,
N1) vymažte vlastnost distribuované skupiny dostupnosti tím, že ji nastavíte na 0:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);VOLITELNÉ: Pokud se skupiny dostupnosti nacházejí na geograficky vzdálených místech, což způsobuje latenci, zvažte změnu režimu dostupnosti zpět na
ASYNCHRONOUS_COMMITu globálního primárního i předávacího modulu. Pokud je to potřeba, vrátí se změna provedená v prvním kroku.-- If applicable: sets the distributed availability group to asynchronous commit: ALTER AVAILABILITY GROUP distributedAG MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT);
Odstraňte distribuovanou skupinu dostupnosti
Následující příkaz Transact-SQL odebere distribuovanou skupinu dostupnosti s názvem distributedAG:
DROP AVAILABILITY GROUP distributedAG;
Vytvoření distribuované skupiny dostupnosti na instancích clusteru s převzetím služeb při selhání
Distribuovanou skupinu dostupnosti můžete vytvořit pomocí skupiny dostupnosti v instanci clusteru s podporou převzetí služeb při selhání (FCI). V takovém případě nepotřebujete posluchač skupiny dostupnosti. Pro primární repliku instance FCI použijte název virtuální sítě (VNN). Následující příklad ukazuje distribuovanou skupinu dostupnosti s názvem SQLFCIDAG. Jeden dostupný cluster je SQLFCIAG. SQLFCIAG má dvě repliky FCI. Virtuální síť VNN pro primární repliku FCI je SQLFCIAG-1 a virtuální síť VNN pro sekundární repliku FCI je SQLFCIAG-2. Distribuovaná skupina dostupnosti také zahrnuje SQLAG-DR pro zotavení po havárii.
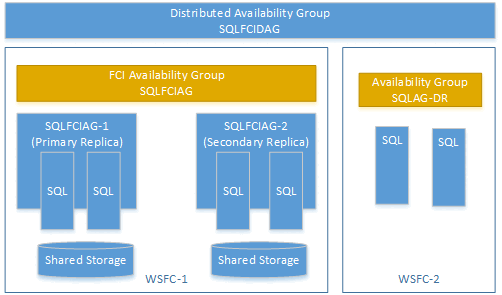
Následující DDL vytvoří tuto distribuovanou skupinu dostupnosti:
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
Adresa URL posluchače je VNN primární instance FCI.
Ruční přepnutí při selhání FCI v distribuované skupině dostupnosti
Pokud chcete skupinu dostupnosti FCI převzít ručně, aktualizujte distribuovanou skupinu dostupnosti tak, aby odrážela změnu adresy URL naslouchacího procesu. Například spusťte následující DDL na globálním primárním serveru distribuované AG a na přesměrovávači distribuované AG SQLFCIDAG:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)