Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
platí pro:![]() SQL Server
SQL Server
Distribuovaná skupina dostupnosti je speciální typ skupiny dostupnosti, která zahrnuje dvě samostatné skupiny dostupnosti. Distribuované skupiny dostupnosti jsou dostupné od SQL Serveru 2016.
Tento článek popisuje funkci distribuované skupiny dostupnosti. Pokud chcete nakonfigurovat distribuovanou skupinu dostupnosti, přečtěte si téma Konfigurace distribuovaných skupin dostupnosti.
Přehled
Distribuovaná skupina dostupnosti je speciální typ skupiny dostupnosti, která zahrnuje dvě samostatné skupiny dostupnosti. Skupiny dostupnosti, které se účastní distribuované skupiny dostupnosti, nemusí být ve stejném umístění. Mohou být fyzické, virtuální, místní, ve veřejném cloudu nebo kdekoli, kde je podporováno nasazení skupiny dostupnosti. To zahrnuje různé domény a dokonce i různé platformy – například mezi skupinou dostupnosti hostovanou v Linuxu a jinou hostovanou ve Windows. Pokud spolu můžou komunikovat dvě skupiny dostupnosti, můžete s nimi nakonfigurovat distribuovanou skupinu dostupnosti.
Tradiční skupina dostupnosti má prostředky nakonfigurované v clusteru s podporou převzetí služeb při selhání Windows Serveru (WSFC), nebo na Linuxu s Pacemakerem. Distribuovaná skupina dostupnosti nenakonfiguruje nic v podkladovém clusteru (WSFC nebo Pacemaker). Všechno o něm se udržuje v RÁMCI SQL Serveru. Informace o tom, jak zobrazit informace pro distribuovanou skupinu dostupnosti, najdete v tématu Zobrazení informací o distribuované skupině dostupnosti.
Distribuovaná skupina dostupnosti vyžaduje, aby základní skupiny dostupnosti měly posluchač. Místo zadání názvu základního serveru pro samostatnou instanci (nebo v případě instance clusteru s podporou převzetí služeb při selhání SQL Serveru [FCI], hodnota přidružená k prostředku názvu sítě) jako u tradiční skupiny dostupnosti zadáte nakonfigurovaný naslouchací proces pro distribuovanou skupinu dostupnosti s parametrem ENDPOINT_URL při jeho vytvoření. I když každá podkladová skupina dostupnosti v distribuované skupině dostupnosti má naslouchací službu, distribuovaná skupina dostupnosti nemá žádnou naslouchací službu.
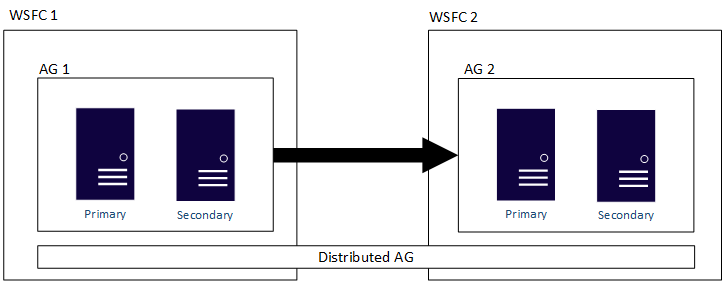
Následující obrázek znázorňuje základní zobrazení distribuované skupiny dostupnosti, která zahrnuje dvě skupiny dostupnosti (AG 1 a AG 2), které jsou nakonfigurované ve vlastní WSFC. Distribuovaná skupina dostupnosti má celkem čtyři repliky, přičemž dvě jsou v každé dostupnostní skupině. Každá skupina dostupnosti může podporovat až maximální počet replik, takže distribuovaná skupina dostupnosti může mít až 18 celkových replik.
Přesun dat v distribuovaných skupinách dostupnosti můžete nakonfigurovat jako synchronní nebo asynchronní. Přesun dat se ale v rámci distribuovaných skupin dostupnosti mírně liší v porovnání s tradiční skupinou dostupnosti. I když každá skupina dostupnosti má primární repliku, existuje pouze jedna kopie databází zapojených do distribuované skupiny dostupnosti, která může přijímat vložení, aktualizace a odstranění. Jak je znázorněno na následujícím obrázku, AG 1 je primární skupina dostupnosti. Jeho primární replika odesílá transakce do sekundárních replik AG 1 a primární repliky AG 2. Primární replika AG 2 se také označuje jako předávač. Přeposílatel je primární replikou v sekundární skupině dostupnosti v distribuované skupině dostupnosti. Služba předávání přijímá transakce z primární repliky v primární skupině dostupnosti a předává je sekundárním replikám ve vlastní skupině dostupnosti. Zprostředkovatel pak udržuje aktualizované sekundární repliky AG 2.
Jediným způsobem, jak zajistit, aby primární replika skupiny dostupnosti 2 přijímala vložení, aktualizace a odstranění, je ruční převzetí služeb při selhání distribuované skupiny dostupnosti z skupiny dostupnosti 1. Na předchozím obrázku, protože skupina dostupnosti 1 obsahuje zapisovatelnou kopii databáze, při převzetí služeb při selhání se skupina dostupnosti 2 stane tou skupinou, která dokáže zpracovat vložení, aktualizace a odstranění. Informace o tom, jak převzít při selhání jednu distribuovanou skupinu dostupnosti na jinou, najdete v tématu Převzetí při selhání na sekundární skupinu dostupnosti.
Poznámka:
- Distribuované skupiny dostupnosti v SQL Serveru 2016 podporují převzetí služeb při selhání pouze z jedné skupiny dostupnosti do druhé pomocí možnosti
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Při použití transakční replikace s distribuovanými skupinami dostupnosti nemůže být replika služby předávání nakonfigurovaná jako vydavatel.
Změny SQL Serveru 2025
SQL Server 2025 (17.x) zavádí následující změny:
Vylepšení synchronizace distribuované skupiny dostupnosti
SQL Server 2025 (17.x) zavádí změnu interního synchronizačního mechanismu distribuovaných skupin dostupnosti za účelem zlepšení výkonu synchronizace snížením sytosti sítě, když je předávací replika v režimu asynchronního potvrzení. Tato změna je ve výchozím nastavení povolená a nevyžaduje žádnou konfiguraci.
Poznámka:
Konfigurace distribuované skupiny dostupnosti s neshodou mezi režimy dostupnosti dvou základních skupin dostupnosti se nedoporučuje a může zavádět latenci synchronizace. Obě skupiny dostupnosti by měly být nakonfigurované se stejným režimem dostupnosti (synchronním nebo asynchronním), aby se zajistil optimální výkon a synchronizace.
Podpora izolované skupiny dostupnosti
SQL Server 2025 (17.x) zavádí podporu pro distribuovanou ohraničenou skupinu dostupnosti. Pokud chcete použít obsaženou skupinu dostupnosti jako předávací prvek v distribuované skupině dostupnosti, musíte vytvořit obsaženou skupinu dostupnosti pomocí klauzule AUTOSEEDING_SYSTEM_DATABASES pro možnost WITH | CONTAINED příkazu CREATE AVAILABILITY GROUP.
Požadavky na verzi a edici
Distribuované skupiny dostupnosti v SYSTÉMU SQL Server 2017 nebo novější můžou kombinovat hlavní verze SQL Serveru ve stejné distribuované skupině dostupnosti. Skupina dostupnosti obsahující primární čtení a zápis může být stejná nebo nižší než ostatní skupiny dostupnosti, které se účastní distribuované skupiny dostupnosti. Ostatní AG mohou být stejné verze nebo vyšší. Tento scénář se zaměřuje na scénáře upgradu a migrace. Například, pokud je skupina dostupnosti, která obsahuje primární repliku pro čtení a zápis, na SQL Serveru 2016 a chcete upgradovat nebo migrovat na SQL Server 2017 nebo novější, pak ostatní skupina dostupnosti účastnící se v distribuované skupině dostupnosti může být nakonfigurována s SQL Serverem 2017.
Vzhledem k tomu, že funkce distribuovaných skupin dostupnosti v SQL Serveru 2012 nebo 2014 neexistuje, skupiny dostupnosti vytvořené s těmito verzemi se nemůžou účastnit distribuovaných skupin dostupnosti.
Poznámka:
V závislosti na verzi SQL Serveru je možné při připojování ke službám Azure (například propojení spravované instance) nakonfigurovat distribuovanou skupinu dostupnosti s edicí Standard nebo kombinaci edicí Standard a Enterprise. Další informace najdete v KB5016729 .
Vzhledem k tomu, že existují dvě samostatné skupiny dostupnosti, proces instalace aktualizace Service Pack nebo kumulativní aktualizace na repliku, která se účastní distribuované skupiny dostupnosti, se mírně liší od tradiční skupiny dostupnosti:
Začněte aktualizací replik druhé skupiny dostupnosti v rámci distribuované skupiny dostupnosti.
Aktualizujte repliky primární skupiny dostupnosti v distribuované skupině dostupnosti.
Stejně jako u standardní skupiny dostupnosti převeďte primární skupinu dostupnosti na jednu ze svých vlastních replik (ne na primární skupinu dostupnosti) a opravte ji. Pokud není jiná replika než primární, bude potřeba ruční převzetí druhé skupiny dostupnosti.
Verze Windows Serveru a distribuované skupiny dostupnosti
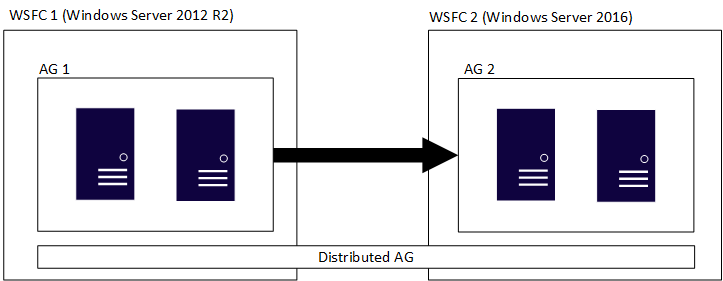
Distribuovaná skupina dostupnosti zahrnuje více skupin dostupnosti, z nichž každá má vlastní základní WSFC, a distribuovaná skupina dostupnosti je konstruktor jen pro SQL Server. To znamená, že wsFCs, které jsou součástí jednotlivých skupin dostupnosti, můžou mít různé hlavní verze Windows Serveru. Hlavní verze SQL Serveru musí být stejné, jak je popsáno v předchozí části. Podobně jako na počátečním obrázku ukazuje následující obrázek AG 1 a AG 2, které se účastní distribuované skupiny dostupnosti, ale každá z WSFC je jiná verze Windows Serveru.
Jednotlivé WSFC a jejich odpovídající skupiny dostupnosti se řídí tradičními pravidly. To znamená, že se dají připojit k doméně nebo nepřipojit k doméně (Windows Server 2016 nebo novější). Pokud se v jedné distribuované skupině dostupnosti zkombinují dvě různé skupiny dostupnosti, existují čtyři scénáře:
- Oba clusterové uzly WSFC jsou připojené ke stejné doméně.
- Každý WSFC je připojený k jiné doméně.
- Jedna WSFC je připojená k doméně a jedna WSFC není připojená k doméně.
- K doméně není připojeno žádné WSFC.
Pokud jsou oba řadiče WSFC připojené ke stejné doméně (ne důvěryhodné domény), nemusíte při vytváření distribuované skupiny dostupnosti dělat nic zvláštního. Pro skupiny dostupnosti a WSFCs, které nejsou připojené ke stejné doméně, použijte certifikáty k tomu, aby distribuovanou skupinu dostupnosti fungovala podobně jako, když vytváříte skupinu dostupnosti pro skupinu dostupnosti nezávislou na doméně. Pokud chcete zjistit, jak nakonfigurovat certifikáty pro distribuovanou skupinu dostupnosti, postupujte podle kroků 3 až 13 v části Vytvoření skupiny dostupnosti nezávislé na doméně.
U distribuované skupiny dostupnosti musí primární repliky v každé základní skupině dostupnosti mít certifikáty ostatních. Pokud už máte koncové body, které nepoužívají certifikáty, překonfigurujte je pomocí příkazu ALTER ENDPOINT tak, aby odrážely použití certifikátů.
Scénáře použití
Tady jsou tři hlavní scénáře použití distribuované skupiny dostupnosti:
- Zotavení po havárii a jednodušší konfigurace s více lokalitami
- Migrace na nový hardware nebo konfigurace, které můžou zahrnovat použití nového hardwaru nebo změnu základních operačních systémů
- Zvýšení počtu čitelných replik nad rámec osmi v jedné skupině dostupnosti prostřednictvím několika skupin dostupnosti
Scénáře zotavení po havárii a scénáře s více lokalitami
Tradiční skupina dostupnosti vyžaduje, aby všechny servery byly součástí stejné WSFC, což může vyžadovat náročné přecházení několika datových center. Následující obrázek ukazuje, jak vypadá tradiční architektura skupin dostupnosti s více lokalitami, včetně toku dat. Existuje jedna primární replika, která odesílá transakce do všech sekundárních replik. Tato konfigurace je v některých ohledech méně výkonná než distribuovaná skupina dostupnosti. Musíte například implementovat službu služba Active Directory (pokud je k dispozici) a svědka pro kvorum ve WSFC. Možná budete muset vzít v úvahu i další aspekty WSFC, jako je úprava hlasování uzlů.

Distribuované skupiny dostupnosti nabízejí flexibilnější scénář nasazení pro skupiny dostupnosti, které zahrnují více datových center. Můžete dokonce použít distribuované skupiny dostupnosti, ve kterých se funkce, jako je přesouvání protokolů , používaly v minulosti pro scénáře, jako je zotavení po havárii. Na rozdíl od přesouvání protokolů ale distribuované skupiny dostupnosti nemohou mít zpožděné použití transakcí. To znamená, že skupiny dostupnosti nebo distribuované skupiny dostupnosti nemůžou pomoct v případě lidské chyby, ve které se data nesprávně aktualizují nebo odstraní.
Distribuované skupiny dostupnosti jsou volně svázané, což v tomto případě znamená, že nevyžadují jedinou službu WSFC a udržují se SQL Serverem. Vzhledem k tomu, že jsou WSFCs udržovány jednotlivě a synchronizace je primárně asynchronní mezi těmito dvěma skupinami dostupnosti, je jednodušší nakonfigurovat získání dat po havárii v jiné lokalitě. Primární repliky v každé skupině dostupnosti synchronizují své vlastní sekundární repliky.
- Ruční převzetí služeb při selhání je podporováno pouze pro distribuovanou skupinu dostupnosti. V situaci při zotavení po havárii, kdy přepínáte datacentrum, byste neměli konfigurovat automatické převzetí služeb při selhání (s několika výjimkami).
- Pravděpodobně nebudete muset nastavit některé z tradičních položek nebo parametrů pro více lokalit nebo podsíť WSFCs, například CrossSubnetThreshold, ale přesto potřebujete zjistit latenci sítě v jiné vrstvě přenosu dat. Rozdíl je v tom, že každá WSFC udržuje svou vlastní dostupnost; cluster není jedna velká entita čtyř uzlů. Máte dva samostatné dvouuzlové WSFC, jak je znázorněno na předchozím obrázku.
- Doporučujeme asynchronní přesun dat, protože tento přístup by byl určený pro účely zotavení po havárii.
- Pokud nakonfigurujete synchronní přesun dat mezi primární replikou a alespoň jednou sekundární replikou druhé skupiny dostupnosti a nakonfigurujete synchronní přesun v distribuované skupině dostupnosti, distribuovaná skupina dostupnosti bude čekat, dokud všechny synchronní kopie nebudou potvrzeny, že data mají. Pokud je více distribuovaných skupin dostupnosti zřetězených (AG1 –> AG2 –> AG3) a jsou nastaveny na synchronní režim, distribuovaná skupina dostupnosti vyčká, dokud nebude aktualizována poslední replika poslední skupiny dostupnosti.
Migrovat
Vzhledem k tomu, že distribuované skupiny dostupnosti podporují dvě zcela různé konfigurace skupin dostupnosti, umožňují nejen snadnější zotavení po havárii a scénáře s více lokalitami, ale také scénáře migrace. Bez ohledu na to, jestli migrujete na nový hardware nebo virtuální počítače (místní nebo IaaS ve veřejném cloudu), konfigurace distribuované skupiny dostupnosti umožňuje migraci provést tam, kde v minulosti jste možná použili zálohování, kopírování a obnovení nebo přesouvání protokolů.
Možnost migrace je užitečná zejména ve scénářích, kdy měníte nebo upgradujete základní operační systém, zatímco zachováte stejnou verzi SQL Serveru. I když Windows Server 2016 umožňuje postupný upgrade z Windows Serveru 2012 R2 na stejném hardwaru, většina uživatelů se rozhodne nasadit nový hardware nebo virtuální počítače.
Pokud chcete dokončit migraci na novou konfiguraci, na konci procesu zastavte veškerý provoz dat do původní skupiny dostupnosti a změňte distribuovanou skupinu dostupnosti na synchronní přesun dat. Tato akce zajistí, že primární replika druhé skupiny dostupnosti bude plně synchronizovaná, takže nedojde ke ztrátě dat. Po ověření synchronizace přepněte distribuovanou skupinu dostupnosti na sekundární skupinu dostupnosti. Další informace najdete v tématu Převzetí služeb při selhání na sekundární skupinu dostupnosti.
Po migraci, kde je druhá skupina dostupnosti nyní novou primární skupinou dostupnosti, možná budete muset provést některý z následujících kroků:
- Přejmenujte naslouchací proces v sekundární skupině dostupnosti (a případně odstraňte nebo přejmenujte starý v původní primární skupině dostupnosti) nebo ho znovu vytvořte pomocí naslouchacího procesu z původní primární skupiny dostupnosti, aby aplikace a uživatelé mohli získat přístup k nové konfiguraci.
- Pokud přejmenování nebo opětovné vytvoření není možné, nasměrujte aplikace a uživatele na posluchač v sekundární skupině dostupnosti.
Migrace na vyšší verze SQL Serveru
Během scénáře migrace je možné nakonfigurovat distribuovanou AG pro migraci databází na cílový SQL Server, který má vyšší verzi než zdroj, avšak existuje několik omezení.
Pokud konfigurujete distribuovanou skupinu dostupnosti s cílem migrace SQL Serveru, který má vyšší verzi než zdroj, automatické vkládání se nepodporuje, takže režim vkládání musí být nastavený na MANUAL. Pokud nezakážete funkci AUTO-SEEDING, migrace selže a zobrazí se chyba 946 Nejde otevřít databázi DistributionAG verze xxx. V protokolu chyb je zaznamenána chyba: aktualizovat databázi na nejnovější verzi. Režim počátečního nastavení je nutné nastavit na RUČNÍ a ručně provést úplnou zálohu transakčního protokolu zdrojové databáze z primární skupiny dostupnosti. Potom ho ručně obnovte spolu s transakčním protokolem do sekundární skupiny dostupnosti. Další informace najdete v ručních krocích počátečního nastavení konfigurace distribuované skupiny dostupnosti a skriptů pro zálohování a obnovení databáze z primární skupiny dostupnosti do sekundární skupiny dostupnosti.
Za předpokladu, že sekundární skupina dostupnosti (AG2) je cílem migrace a je vyšší než primární skupina dostupnosti (AG1), zvažte následující omezení:
- Nebudete mít přístup pro čtení k žádné databázi replik v sekundární skupině dostupnosti, pokud je primární skupina dostupnosti v nižší verzi.
- Během této doby budou aktualizace pokračovat v toku z primární skupiny dostupnosti (AG1) do sekundární skupiny dostupnosti (AG2), ale stav sekundární skupiny dostupnosti se zobrazí jako Částečně v pořádku a databáze na sekundárních replikách sekundární skupiny dostupnosti (AG2) se zobrazí jako Synchronizace/In Recovery (i když je skupina dostupnosti v potvrzení synchronizace).
- Po převzetí služeb při selhání distribuované skupiny dostupnosti na vyšší verzi (AG2) by se skupina dostupnosti 2 měla stát v pořádku.
- Během této doby nebude možné vrátit stav na AG1, protože je v nižší verzi.
- Vzhledem k tomu, že skupina dostupnosti 1 je v nižší verzi, aktualizace z ag2 po převzetí služeb při selhání do skupiny dostupnosti 2 se nebudou replikovat do skupiny dostupnosti 1.
- Tady zvolte, jestli chcete původní (primární) skupiny dostupnosti vyřadit z provozu, nebo pokud chcete upgradovat ag1 a udržovat distribuovanou agátku.
- Pokud se rozhodnete vyřadit ag1 z provozu, odeberte původní primární skupiny dostupnosti z distribuované skupiny dostupnosti a proces se dokončí.
- Pokud se rozhodnete udržovat distribuovanou skupiny dostupnosti, upgradujte verzi SQL Serveru pro ag1 tak, aby odpovídala skupině dostupnosti 2. Po upgradu skupiny dostupnosti AG1 se skupina dostupnosti 1 stane v pořádku, distribuovaná skupina dostupnosti se stane v pořádku, repliky se zachytí, aby se synchronizovaly a navrácení služeb po obnovení bude možné.
Horizontální navýšení kapacity čitelných replik
Jedna distribuovaná skupina dostupnosti může mít podle potřeby až 16 sekundárních replik. Může tedy mít až 18 kopií pro čtení, včetně dvou primárních replik různých skupin dostupnosti. Tento přístup znamená, že více než jedno místo může mít přístup téměř v reálném čase pro hlášení různým aplikacím.
Distribuované skupiny dostupnosti vám můžou pomoct škálovat farmu určenou jen pro čtení, než můžete použít pouze u jedné skupiny dostupnosti. Distribuovaná skupina dostupnosti může škálovat repliky s možností čtení dvěma způsoby:
- Primární repliku druhé z dostupných skupin v distribuované skupině dostupnosti můžete použít k vytvoření jiné distribuované skupiny dostupnosti, i když databáze není v režimu obnovy.
- Primární repliku první skupiny dostupnosti můžete použít také k vytvoření jiné distribuované skupiny dostupnosti.
Jinými slovy, primární replika se může účastnit různých distribuovaných skupin dostupnosti. Následující obrázek ukazuje skupinu dostupnosti 1 i skupinu dostupnosti 2, které se účastní distribuované skupiny dostupnosti 1, přičemž skupina dostupnosti 2 a skupina dostupnosti 3 se účastní distribuované skupiny dostupnosti 2. Primární replika (nebo předávač) skupiny dostupnosti AG 2 je zároveň sekundární replika pro distribuovanou skupinu dostupnosti AG 1 a primární replika pro distribuovanou skupinu dostupnosti AG 2.
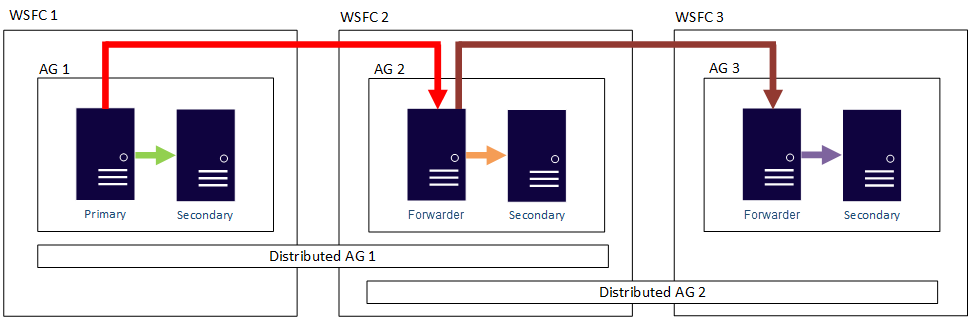
Následující obrázek znázorňuje skupinu dostupnosti 1 jako primární repliku pro dvě různé distribuované skupiny dostupnosti: Distribuovaná skupina dostupnosti 1 (složená z skupiny dostupnosti 1 a skupiny dostupnosti 2) a Distribuovaná skupina dostupnosti 2 (složená z skupiny dostupnosti 1 a skupiny dostupnosti 3).
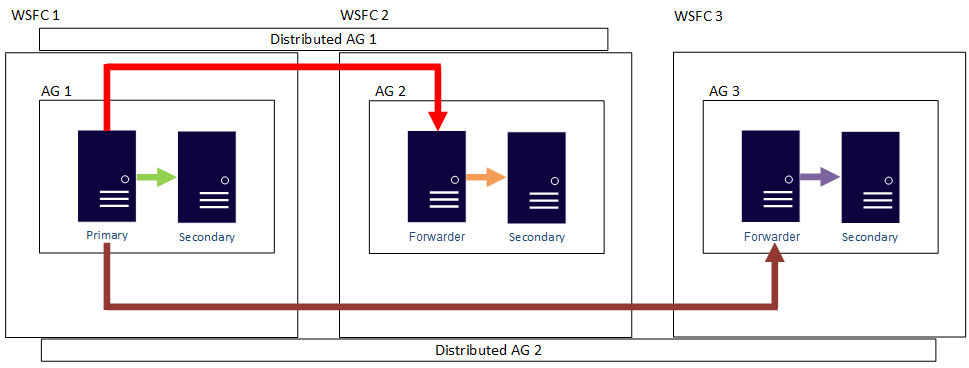
V obou předchozích příkladech může existovat až 27 celkových replik ve třech skupinách dostupnosti, z nichž všechny se dají použít pro dotazy jen pro čtení.
Směrování jen pro čtení nefunguje s distribuovanými skupinami dostupnosti. Konkrétněji,
- Read-Only Směrování lze nakonfigurovat a bude fungovat pro hlavní skupinu dostupnosti v rámci distribuované skupiny dostupnosti.
- Read-Only Směrování lze nakonfigurovat, ale nebude fungovat pro sekundární skupinu dostupnosti v rámci distribuované skupiny dostupnosti. Všechny dotazy, které používají naslouchací proces pro připojení k sekundární skupině dostupnosti, jsou nasměrovány na primární repliku této sekundární skupiny dostupnosti. Jinak je potřeba nakonfigurovat každou repliku tak, aby umožňovala všechna připojení jako sekundární repliku a přistupovat k nim přímo. Směrování pouze pro čtení však bude fungovat, pokud se sekundární skupina dostupnosti stane primární po převzetí při selhání. Toto chování se může změnit v aktualizaci na SQL Server 2016 nebo v budoucí verzi SQL Serveru.
Inicializace sekundárních skupin dostupnosti
Distribuované skupiny dostupnosti byly navrženy s automatickým nasazením jako hlavní metodou pro inicializaci primární repliky ve druhé skupině dostupnosti. Úplné obnovení databáze na primární replice druhé skupiny dostupnosti je možné, pokud provedete následující kroky:
- Obnovte zálohu databáze POMOCÍ NORECOVERY.
- V případě potřeby obnovte správné zálohy transakčních protokolů POMOCÍ NORECOVERY.
- Vytvořte druhou skupinu dostupnosti bez zadání názvu databáze a s SEEDING_MODE nastavenou na HODNOTU AUTOMATIC.
- Vytvořte distribuovanou skupinu dostupnosti pomocí automatického nasazení.
Když do distribuované skupiny dostupnosti přidáte primární repliku druhé skupiny dostupnosti, replika se zkontroluje u primárních databází první skupiny dostupnosti a automatické nasazení synchronizuje databázi se zdrojem. Existuje několik upozornění:
Výstup zobrazený v
sys.dm_hadr_automatic_seedingna primární replice druhé skupiny dostupnosti se zobrazí jakocurrent_stateFAILED s důvodem "Vypršení časového limitu kontrolní zprávy osévání."Aktuální protokol chyb SQL Serveru na primární replice druhé skupiny dostupnosti bude ukazovat, že automatické seedování fungovalo a že byly synchronizovány sítě LSN .
Výstup zobrazený na
sys.dm_hadr_automatic_seedingprimární replice první skupiny dostupnosti zobrazí stav current_state jako DOKONČENO.Automatické seedování má také jiné chování s distribuovanými skupinami dostupnosti. Aby automatické spuštění začalo na druhé replice, musíte spustit příkaz
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEna replice. I když je tato podmínka stále pravdivá pro všechny sekundární repliky, které se účastní základní skupiny dostupnosti, primární replika druhé skupiny dostupnosti už má správná oprávnění k tomu, aby se automatické počáteční spuštění povolilo po přidání do distribuované skupiny dostupnosti.
Poznámka:
- Sekundární skupina dostupnosti musí používat stejný koncový bod zrcadlení databáze. Jinak se replikace zastaví po místním převzetí služeb při selhání.
- Základní skupiny dostupnosti by měly být ve stejném režimu dostupnosti – obě skupiny dostupnosti by měly být v synchronním režimu potvrzení nebo obě skupiny by měly být v asynchronním režimu potvrzení. Pokud si nejste jistí, který použít, nastavte oba na režim asynchronního potvrzování, dokud nebudete připraveni přepnout na záložní řešení.
Monitorování stavu
Distribuovaná skupina dostupnosti je konstruktor jen pro SQL Server a v podkladové WSFC se nezobrazuje. Následující ukázka kódu ukazuje dva různé wsFCs (CLUSTER_A a CLUSTER_B), z nichž každá má vlastní skupiny dostupnosti. Zde jsou popsány pouze AG1 v CLUSTER_A a AG2 v CLUSTER_B.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
Všechny podrobné informace o distribuované skupině dostupnosti jsou v SQL Serveru, konkrétně v zobrazení dynamické správy skupiny dostupnosti. V současné době jsou jediné informace, které jsou zobrazeny v aplikaci SQL Server Management Studio pro distribuovanou skupinu dostupnosti, dostupné na primární replice skupin dostupnosti. Jak je znázorněno na následujícím obrázku, ve složce Skupiny dostupnosti sql Server Management Studio ukazuje, že existuje distribuovaná skupina dostupnosti. Obrázek znázorňuje AG1 jako primární repliku pro jednotlivou skupinu dostupnosti, která je místní pro danou instanci, nikoli pro distribuovanou skupinu dostupnosti.
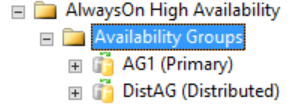
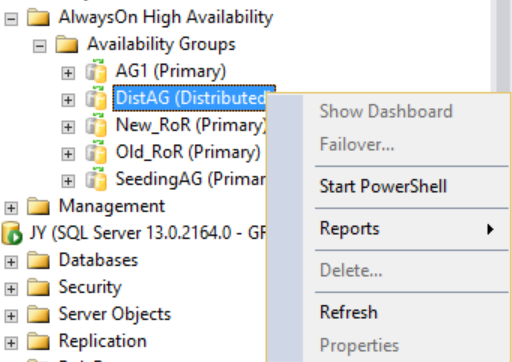
Pokud ale kliknete pravým tlačítkem myši na distribuovanou skupinu dostupnosti, nejsou dostupné žádné možnosti (viz následující obrázek) a složka Databáze dostupnosti, nástroje pro naslouchání skupiny dostupnosti a složka Repliky dostupnosti jsou prázdné. SQL Server Management Studio 16 zobrazí tento výsledek, ale může se změnit v budoucí verzi aplikace SQL Server Management Studio.
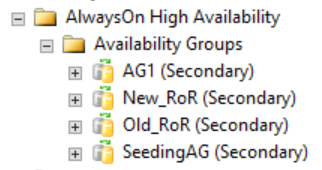
Jak je znázorněno na následujícím obrázku, sekundární repliky neukazují nic v SQL Server Management Studio, co by souviselo s distribuovanou skupinou dostupnosti. Tyto názvy skupin dostupnosti se mapují na role uvedené na předchozím obrázku WSFC CLUSTER_A.
Zobrazení dynamické správy pro výpis všech názvů replik dostupnosti
Stejné koncepty platí, když používáte zobrazení dynamické správy. Pomocí následujícího dotazu můžete zobrazit všechny skupiny dostupnosti (běžné a distribuované) a uzly, které se jich účastní. Tento výsledek se zobrazí pouze v případě, že se dotazujete na primární repliku v jednom ze serverů WSFC, které se účastní distribuované skupiny dostupnosti. V zobrazení sys.availability_groups dynamické správy je nový sloupec s názvem is_distributed1, pokud je skupina dostupnosti distribuovanou skupinou dostupnosti. Chcete-li zobrazit tento sloupec:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
Příklad výstupu druhé WSFC, která se účastní distribuované skupiny dostupnosti, je znázorněn na následujícím obrázku. SPAG1 se skládá ze dvou replik: DENNIS a JY. Distribuovaná skupina dostupnosti s názvem SPDistAG má však názvy dvou zúčastněných skupin dostupnosti (SPAG1 a SPAG2) místo názvů instancí, stejně jako u tradiční skupiny dostupnosti.
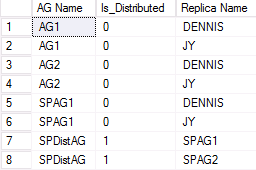
DMV pro zobrazení stavu zdraví distribuovaných skupin dostupnosti
V aplikaci SQL Server Management Studio jsou všechny stavy zobrazené na řídicím panelu a dalších oblastech určené pouze pro místní synchronizaci v rámci této skupiny dostupnosti. Pokud chcete zobrazit stav distribuované skupiny dostupnosti, zadejte dotaz na zobrazení dynamické správy. Následující příklad dotazu rozšiřuje a upřesňuje předchozí dotaz:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

Zobrazení dynamické správy pro zobrazení základního výkonu
Pokud chcete předchozí dotaz dále rozšířit, můžete také zobrazit základní výkon prostřednictvím zobrazení dynamické správy tím, že přidáte sys.dm_hadr_database_replicas_states. Zobrazení dynamické správy aktuálně ukládá informace o druhé skupině dostupnosti. Následující příklad dotazu, spuštění v primární skupině dostupnosti, vytvoří ukázkový výstup zobrazený níže:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

Zobrazení čítačů výkonu pro distribuovanou ag
Následující dotaz zobrazí čítače výkonu přidružené ke konkrétní distribuované skupině dostupnosti.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
Snímek obrazovky DMV zobrazující čítače výkonu operačního systému pro DAG.
Poznámka:
Filtr LIKE by měl mít název distribuované skupiny dostupnosti. V tomto příkladu je název distribuované skupiny dostupnosti "distributedag". Změňte modifikátor tak LIKE , aby odrážel název vaší distribuované skupiny dostupnosti.
Zobrazení stavu dynamické správy pro zobrazení stavu skupiny dostupnosti i distribuované skupiny dostupnosti
Následující dotaz zobrazí řadu informací o stavu skupiny dostupnosti i distribuované skupině dostupnosti. (Reprodukováno s oprávněním od Tracy Boggiano.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

Zobrazení dynamické správy pro zobrazení metadat distribuované skupiny dostupnosti
Následující dotazy zobrazí informace o adresách URL koncových bodů používaných skupinami dostupnosti, včetně distribuované skupiny dostupnosti. (Reprodukováno s oprávněním Od Davida Barbarina.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV pro zobrazení aktuálního stavu setí
Následující dotaz zobrazí informace o aktuálním stavu seedování. To je užitečné při řešení chyb synchronizace mezi replikami. (Reprodukováno s oprávněním Od Davida Barbarina.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
