Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro:![]() SQL Server 2017 (14.x) a novější verze
SQL Server 2017 (14.x) a novější verze ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Ve třetí části této čtyřdílné série kurzů vytvoříte v Pythonu model K-Means, který provede clustering. V další části této série nasadíte tento model do databáze se službou SQL Server Machine Learning Services nebo v clusterech s velkými objemy dat.
Ve třetí části této čtyřdílné série kurzů vytvoříte v Pythonu model K-Means, který provede clustering. V další části této série nasadíte tento model do databáze se službou SQL Server Machine Learning Services.
Ve třetí části této čtyřdílné série kurzů vytvoříte v Pythonu model K-Means, který provede clustering. V další části této série nasadíte tento model do databáze se službou Azure SQL Managed Instance Machine Learning Services.
V tomto článku se naučíte:
- Definování počtu clusterů pro algoritmu K-Means
- Proveď klastrovaní
- Analýza výsledků
V první části jste nainstalovali požadavky a obnovili ukázkovou databázi.
V druhé části jste zjistili, jak připravit data z databáze na clustering.
Ve čtvrté části se dozvíte, jak vytvořit uloženou proceduru v databázi, která může provádět clustering v Pythonu na základě nových dat.
Požadavky
- Třetí část tohoto kurzu předpokládá, že jste splnili požadavky první části a dokončili kroky v druhé části.
Definování počtu clusterů
Ke clusterování zákaznických dat použijete algoritmus clusteringu K-Means , jeden z nejjednodušších a nejznámějších způsobů seskupování dat. Další informace o K-Means najdete v úplném průvodci algoritmem clusteringu K-Means.
Algoritmus přijímá dva vstupy: samotná data a předdefinované číslo "k" představující počet clusterů, které se mají vygenerovat. Výstupem jsou clustery k se vstupními daty rozdělenými mezi clustery.
Cílem K-means je seskupit položky do clusterů k tak, aby všechny položky ve stejném clusteru byly podobné sobě a co nejvíce odlišné od položek v jiných clusterech.
Pokud chcete určit počet shluků, které má algoritmus použít, použijte graf součtu čtverců v rámci skupin podle počtu získaných shluků. Vhodný počet klastrů, které se mají použít, je v místě zalomení nebo "loktu" grafu.
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
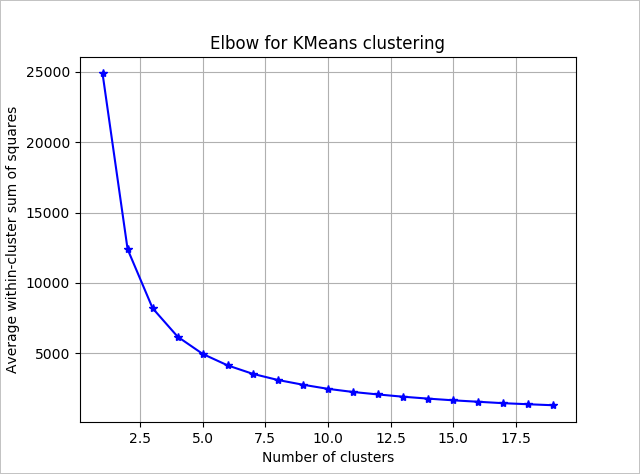
Na základě grafu to vypadá, že k = 4 by bylo dobrou hodnotou vyzkoušet. Tato hodnota k seskupí zákazníky do čtyř clusterů.
Proveď klastrovaní
V následujícím skriptu Pythonu použijete funkci KMeans z balíčku sklearn.
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
Analýza výsledků
Teď, když jste provedli clustering pomocí K-Means, je dalším krokem analýza výsledku a zjištění, jestli najdete nějaké užitečné informace.
Podívejte se na střední hodnoty clusteringu a velikosti clusterů vytištěné z předchozího skriptu.
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
Čtyři prostředky clusteru jsou dány pomocí proměnných definovaných v první části:
- orderRatio = poměr vrácených objednávek (celkový počet objednávek částečně nebo zcela vrácených oproti celkovému počtu objednávek)
- itemsRatio = poměr vrácených položek (celkový počet vrácených položek oproti počtu zakoupených položek)
- monetaryRatio = poměr výnosové částky (celková peněžní částka vrácených položek a zakoupená částka)
- frequency = návratová frekvence
Dolování dat pomocí K-Means často vyžaduje další analýzu výsledků a další kroky k lepšímu pochopení každého clusteru, ale může poskytnout některé dobré zájemce. Tady je několik způsobů, jak byste mohli tyto výsledky interpretovat:
- Zdá se, že cluster 0 je skupina zákazníků, kteří nejsou aktivní (všechny hodnoty jsou nula).
- Zdá se, že cluster 3 je skupina, která vynikne z hlediska chování při návratu.
Cluster 0 je sada zákazníků, kteří nejsou jasně aktivní. Možná můžete cílit na marketingové úsilí v této skupině, aby aktivovalo zájem o nákupy. V dalším kroku se do databáze dotazujete na e-mailové adresy zákazníků v clusteru 0, abyste jim mohli poslat marketingový e-mail.
Vyčistěte zdroje
Pokud nebudete pokračovat v tomto kurzu, odstraňte tpcxbb_1gb databázi.
Další kroky
Ve třetí části této série kurzů jste dokončili tyto kroky:
- Definování počtu clusterů pro algoritmu K-Means
- Proveď klastrovaní
- Analýza výsledků
Pokud chcete nasadit model strojového učení, který jste vytvořili, postupujte podle části 4 této série kurzů: