Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro:![]() SQL Server 2017 (14.x) a novější verze
SQL Server 2017 (14.x) a novější verze
Tento článek popisuje rozšíření Pythonu pro spouštění externích skriptů Pythonu se službou SQL Server Machine Learning Services. Rozšíření přidá:
- Spouštěcí prostředí Pythonu
- Distribuce Anaconda s modulem runtime Python 3.5 a interpretem
- Standardní knihovny a nástroje
- Balíčky Microsoft Pythonu:
- revoscalepy pro analýzy ve velkém měřítku.
- microsoftml pro algoritmy strojového učení.
Instalace modulu runtime Python 3.5 a interpret zajišťuje téměř úplnou kompatibilitu se standardními řešeními Pythonu. Python běží v samostatném procesu od SQL Serveru, aby se zajistilo, že databázové operace nebudou ohroženy.
Komponenty Pythonu
SQL Server obsahuje opensourcové i proprietární balíčky. Modul runtime Pythonu nainstalovaný instalačním programem je Anaconda 4.2 s Pythonem 3.5. Běhové prostředí Pythonu se instaluje nezávisle na nástrojích SQL a je prováděno mimo jádrové procesy, v rámci rozšiřitelného rozhraní. V rámci instalace služby Machine Learning Services s Pythonem musíte souhlasit s podmínkami gnu Public License.
SQL Server neupravuje spustitelné soubory Pythonu, ale musíte použít verzi Pythonu nainstalovanou instalačním programem, protože tato verze je ta, na které jsou sestavené a otestované vlastní balíčky. Seznam balíčků podporovaných distribucí Anaconda najdete v analytickém webu Continuum: Seznam balíčků Anaconda.
Distribuci Anaconda přidruženou ke konkrétní instanci databázového stroje najdete ve složce přidružené k instanci. Pokud jste například nainstalovali databázový stroj SQL Server 2017 se službou Machine Learning Services a Pythonem ve výchozí instanci, podívejte se do části C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Balíčky Pythonu přidané Microsoftem pro paralelní a distribuované úlohy zahrnují následující knihovny.
| Knihovna | Description |
|---|---|
| revoscalepy | Podporuje objekty zdroje dat a zkoumání dat, manipulaci, transformaci a vizualizaci. Podporuje vytváření vzdálených výpočetních kontextů a také různé škálovatelné modely strojového učení, jako je rxLinMod. Další informace najdete v modulu revoscalepy s SQL Serverem. |
| microsoftml | Obsahuje algoritmy strojového učení optimalizované pro rychlost a přesnost a také integrované transformace pro práci s textem a obrázky. Další informace najdete v modulu Microsoftml s SQL Serverem. |
Microsoftml a revoscalepy jsou úzce svázané; zdroje dat používané v microsoftml jsou definovány jako objekty revoscalepy. Omezení výpočetního kontextu při přenosu revoscalepy do microsoftml. Konkrétně všechny funkce jsou k dispozici pro místní operace, ale přepnutí na vzdálený výpočetní kontext vyžaduje RxInSqlServer.
Použití Pythonu na SQL Serveru
Modul revoscalepy naimportujete do kódu Pythonu a potom zavoláte funkce z modulu, stejně jako všechny ostatní funkce Pythonu.
Mezi podporované zdroje dat patří databáze ODBC, SQL Server a formát souborů XDF pro výměnu dat s jinými zdroji nebo s řešeními R. Vstupní data pro Python musí být tabulková. Všechny výsledky Pythonu musí být vráceny ve formě datového rámce pandas .
Mezi podporované výpočetní kontexty patří místní nebo vzdálený výpočetní kontext SQL Serveru. Vzdálený výpočetní kontext odkazuje na spuštění kódu, které se spouští na jednom počítači, jako je pracovní stanice, ale pak přepne spuštění skriptu na vzdálený počítač. Přepnutí výpočetního kontextu vyžaduje, aby oba systémy měly stejnou knihovnu revoscalepy.
Místní výpočetní kontext, jak můžete očekávat, zahrnuje spuštění kódu Pythonu na stejném serveru jako instance databázového stroje s kódem uvnitř T-SQL nebo vloženým do uložené procedury. Kód můžete spustit také z místního integrovaného vývojového prostředí Pythonu a nechat skript spustit na počítači s SQL Serverem tak, že definujete vzdálený výpočetní kontext.
Architektura spouštění
Následující diagramy znázorňují interakci komponent SQL Serveru s modulem runtime Pythonu v jednotlivých podporovaných scénářích: spouštění skriptů v databázi a vzdálené spouštění z terminálu Pythonu pomocí výpočetního kontextu SQL Serveru.
Skripty Pythonu spuštěné v databázi
Když spustíte Python "uvnitř" SQL Serveru, musíte skript Pythonu zapouzdřit do speciální uložené procedury sp_execute_external_script.
Po vložení skriptu do uložené procedury může každá aplikace, která může provést volání uložené procedury, zahájit spuštění kódu Pythonu. Následně SQL Server spravuje provádění kódu, jak je shrnuto v následujícím diagramu.
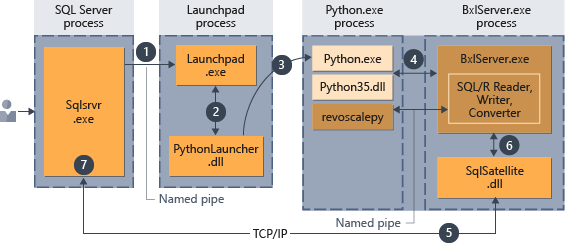
- Požadavek na modul runtime Pythonu je označen parametrem
@language='Python'předaný uložené proceduře. SQL Server odešle tento požadavek do služby launchpad. SQL v Linuxu používá službu launchpadd ke komunikaci se samostatným procesem launchpadu pro každého uživatele. Podrobnosti najdete v diagramu architektury rozšiřitelnosti . - Služba launchpad spustí příslušný spouštěč; v tomto případě PythonLauncher.
- PythonLauncher spustí externí proces Python35.
- BxlServer koordinuje modul runtime Pythonu ke správě výměn dat a ukládání pracovních výsledků.
- Sql Satellite spravuje komunikaci o souvisejících úkolech a procesech s SQL Serverem.
- BxlServer používá funkci SQL Satellite ke komunikaci stavu a výsledků s SQL Serverem.
- SQL Server získá výsledky a zavře související úlohy a procesy.
Skripty Pythonu spouštěné ze vzdáleného klienta
Skripty Pythonu můžete spustit ze vzdáleného počítače, jako je přenosný počítač, a nechat je spustit v kontextu počítače s SQL Serverem, pokud jsou splněny tyto podmínky:
- Skripty navrhnete odpovídajícím způsobem.
- Vzdálený počítač nainstaloval knihovny rozšiřitelnosti, které používají služby Machine Learning Services. K použití vzdálených výpočetních kontextů se vyžaduje balíček revoscalepy .
Následující diagram shrnuje celkový pracovní postup při odesílání skriptů ze vzdáleného počítače.
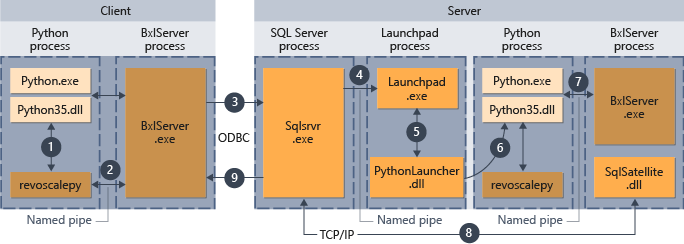
- Pro funkce podporované v revoscalepy volá modul runtime Python odkazovací funkci, která pak volá BxlServer.
- BxlServer je součástí služby Machine Learning Services (In-Database) a běží v samostatném procesu od modulu runtime Pythonu.
- BxlServer určuje cíl připojení a zahájí připojení pomocí rozhraní ODBC a předá přihlašovací údaje zadané jako součást připojovacího řetězce ve skriptu Pythonu.
- BxlServer otevře připojení k instanci SQL Serveru.
- Při zavolání modulu runtime externího skriptu je vyvolána služba launchpad, která následně spustí příslušný spouštěč: v tomto případě PythonLauncher.dll. Následně se zpracování kódu Pythonu zpracovává v pracovním postupu podobném tomu, když se kód Pythonu vyvolá z uložené procedury v T-SQL.
- PythonLauncher volá instanci Pythonu, která je nainstalovaná na počítači s SQL Serverem.
- Výsledky se vrátí do BxlServeru.
- Služba SQL Satellite spravuje komunikaci s SQL Serverem a vyčištění souvisejících objektů úloh.
- SQL Server předává výsledky zpět klientovi.