Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí na:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytický platformový systém (PDW)
Analytický platformový systém (PDW)![]() SQL databáze v Microsoft Fabric
SQL databáze v Microsoft Fabric
SQL Server používá spojení k načtení dat z více tabulek na základě logických relací mezi nimi. Spojení jsou zásadní pro operace relační databáze a umožňují kombinovat data ze dvou nebo více tabulek do jedné sady výsledků.
SQL Server implementuje operace logického spojení (definované syntaxí Transact-SQL) i fyzické operace spojení (skutečné algoritmy používané ke spuštění spojení). Pochopení obou aspektů vám pomůže při psaní efektivních dotazů a optimalizaci výkonu databáze.
Mezi operace logického spojení patří:
- Vnitřní spojení
- Levé, pravé a úplné vnější spojení
- Křížové spojení
Mezi operace fyzického spojení patří:
- Spojení vnořených smyček
- Sloučení spojení
- Spojení hash
- Adaptivní spojení (platí pro: SQL Server 2017 (14.x) a novější verze)
Tento článek vysvětluje, jak spojení fungují, kdy použít různé typy spojení a jak Optimalizátor dotazů vybere nejúčinnější algoritmus spojení na základě faktorů, jako je velikost tabulky, dostupné indexy a distribuce dat.
Note
Další informace o syntaxi spojení naleznete v tématu KLAUZULE FROM plus JOIN, APPLY, PIVOT.
Spojení základních principů
Pomocí spojení můžete načíst data ze dvou nebo více tabulek na základě logických relací mezi tabulkami. Spojení označují, jak má SQL Server používat data z jedné tabulky k výběru řádků v jiné tabulce.
Podmínka spojení definuje způsob, jakým dvě tabulky souvisejí v dotazu:
- Zadejte sloupec z každé tabulky, který se má použít pro spojení. Typická podmínka spojení určuje cizí klíč z jedné tabulky a jeho přidružený klíč v druhé tabulce.
- Určení logického operátoru (například = nebo <>,), který se má použít při porovnávání hodnot ze sloupců.
Spojení se vyjadřují logicky pomocí následující syntaxe Transact-SQL:
[ INNER ] JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
Vnitřní spojení lze specifikovat buď v FROM nebo WHERE klauzuli.
Vnější spojení a křížová spojení lze zadat pouze v klauzuli FROM . Podmínky spojení jsou kombinovány s WHERE podmínkami HAVING hledání a řídí řádky vybrané ze základních tabulek odkazovaných v FROM klauzuli.
Určení podmínek spojení v FROM klauzuli pomáhá oddělit je od ostatních podmínek hledání, které mohou být zadány v WHERE klauzuli, a je doporučenou metodou pro určení spojení. Zjednodušená syntaxe spojení klauzule ISO FROM je:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- Join_type určuje, jaký druh spojení se provádí: vnitřní, vnější nebo křížové spojení. Vysvětlení různých typů spojení najdete v klauzuli FROM.
- Join_condition definuje predikát, který se má vyhodnotit pro každou dvojici spojených řádků.
Následující kód je příkladem specifikace spojovací klauzule FROM.
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
Následující kód je jednoduchý SELECT příkaz, který používá toto spojení:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
Prohlášení SELECT vrátí informace o produktu a dodavateli pro libovolnou kombinaci dílů poskytovaných společností, pro kterou název společnosti začíná písmenem F a cena produktu je vyšší než 10 USD.
Pokud je v jednom dotazu odkazováno více tabulek, musí být všechny odkazy na sloupce jednoznačné. V předchozím příkladu mají obě tabulky ProductVendor a Vendor sloupec s názvem BusinessEntityID. Libovolný název sloupce, který je duplikován mezi dvěma nebo více tabulkami odkazovanými v dotazu, musí být kvalifikovaný s názvem tabulky. Všechny odkazy na Vendor sloupce v příkladu jsou kvalifikované.
Pokud název sloupce není duplikován ve dvou nebo více tabulkách použitých v dotazu, odkazy na něj nemusí být kvalifikované s názvem tabulky. To je znázorněno v předchozím příkladu.
SELECT Taková klauzule je někdy obtížně pochopitelné, protože neexistuje nic k označení tabulky, která poskytla každý sloupec. Čitelnost dotazu se zlepší, pokud jsou všechny sloupce kvalifikované s názvy tabulek. Čitelnost je dále vylepšena, pokud se používají aliasy tabulek, zejména pokud názvy samotných tabulek musí být kvalifikované s názvy databáze a vlastníka. Následující kód je ten samý příklad, jen aliasy tabulek byly přiřazeny a sloupce byly kvalifikovány aliasy tabulek, aby se zlepšila čitelnost.
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
Předchozí příklady určily podmínky spojení v FROM klauzuli, což je upřednostňovaná metoda. Následující dotaz obsahuje stejnou podmínku spojení zadanou WHERE v klauzuli:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
Seznam SELECT spojení může odkazovat na všechny sloupce ve spojených tabulkách nebo na libovolnou podmnožinu sloupců. Seznam SELECT nemusí obsahovat sloupce z každé tabulky ve spojení. Například ve spojení tří tabulek lze k přemostění z jedné z ostatních tabulek do třetí tabulky použít pouze jednu tabulku a žádný sloupec z prostřední tabulky nemusí být uveden v seznamu výběrů. Tomu se také říká anti semijoin.
I když podmínky spojení mají obvykle porovnání rovnosti (=), lze zadat jiné relační operátory, stejně jako jiné predikáty. Další informace naleznete v tématu Relační operátory a WHERE.
Když SQL Server zpracovává spojení, optimalizátor dotazů vybere nejúčinnější metodu (z několika možných) pro zpracování spojení. To zahrnuje výběr nejúčinnějšího typu fyzického spojení, pořadí spojení tabulek a dokonce použití typů operací logického spojení, které nelze přímo vyjádřit pomocí Transact-SQL syntaxe, jako jsou středníky a antimi spojení. Fyzické spouštění různých spojení může používat mnoho různých optimalizací, a proto není možné spolehlivě předpovědět. Další informace o polotech spojeních a protimětových spojeních naleznete v tématu Odkaz na logické a fyzické operátory showplan.
Sloupce použité v podmínce spojení nemusí mít stejný název ani stejný datový typ. Pokud ale datové typy nejsou identické, musí být kompatibilní nebo typy, které SQL Server může implicitně převést. Pokud datové typy nelze implicitně převést, musí podmínka spojení explicitně převést datový typ pomocí CAST funkce. Další informace o implicitních a explicitních převodech najdete v tématu Převod datového typu (databázový stroj).
Většina dotazů používajících spojení se dá přepsat pomocí poddotazu (dotaz vnořený do jiného dotazu) a většina poddotazů se dá přepsat jako spojení. Další informace o poddotazech najdete v tématu Poddotazy (SQL Server).
Note
Tabulky nelze spojit přímo se sloupci typu ntext, text nebo obrázek. Tabulky lze však nepřímo spojit na ntextových, textových nebo obrazových sloupcích pomocí SUBSTRING.
Například SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) provede vnitřní spojení se dvěma tabulkami na prvních 20 znaků každého textového sloupce v tabulkách t1 a t2.
Další možností porovnání ntextových nebo textových sloupců ze dvou tabulek je navíc porovnání délky sloupců s WHERE klauzulí, například: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Vysvětlení spojení vnořených smyček
Pokud je jeden vstup spojení malý (méně než 10 řádků) a druhý vstup spojení je poměrně velký a indexovaný na svých sloupcích spojení, spojení vnořených smyček pomocí indexů je nejrychlejší způsob spojení, protože vyžadují nejméně operací I/O a nejméně porovnání.
Vnořené smyčky spojení, označované také jako vnořené iterace, používá jeden vstup spojení jako vnější vstupní tabulku (zobrazenou jako horní vstup v plánu grafického provádění) a jeden jako vnitřní (dolní) vstupní tabulku. Vnější smyčka spotřebovává řádek vnější vstupní tabulky po řádku. Vnitřní smyčka spuštěná pro každý vnější řádek vyhledá odpovídající řádky ve vnitřní vstupní tabulce.
V nejjednodušším případě prohledá hledání celou tabulku nebo index; to se nazývá naivní vnořené smyčky spojení. Pokud vyhledávání zneužije index, označuje se jako spojení vnořených smyček indexu. Pokud je index vytvořen jako součást plánu dotazu (a zničen po dokončení dotazu), označuje se jako dočasné spojení vnořených smyček indexu. Všechny tyto varianty považuje optimalizátor dotazů.
Spojení vnořených smyček je zvláště účinné, pokud je vnější vstup malý a vnitřní vstup je předindexován a velký. V mnoha malých transakcích, jako jsou například ty, které ovlivňují pouze malou sadu řádků, jsou spojení vnořených smyček indexu vynikající pro sloučení spojení i spojení hash. Ve velkých dotazech ale spojení vnořených smyček často není optimální volbou.
Pokud je atribut OPTIMIZED operátoru spojení vnořených smyček nastaven na Hodnotu True, znamená to, že optimalizované vnořené smyčky (nebo dávkové řazení) se používají k minimalizaci vstupně-výstupních operací, pokud je vnitřní boční tabulka velká, bez ohledu na to, jestli je paralelizovaná nebo ne. Přítomnost této optimalizace v daném plánu nemusí být při analýze plánu provádění velmi jasná, vzhledem k tomu, že samotné řazení je skrytou operací. Když ale hledáte v plánu XML atribut OPTIMIZED, ukazuje to, že spojení vnořených smyček se může pokusit změnit pořadí vstupních řádků, aby se zlepšil výkon I/O operací.
Sloučení spojení
Pokud dva vstupy spojení nejsou malé, ale jsou seřazené ve sloupci spojení (například pokud byly získány prohledáváním seřazených indexů), je sloučení spojení nejrychlejší operací spojení. Pokud jsou oba vstupy spojení velké a mají podobnou velikost, slučovací spojení s předchozím řazením a spojení pomocí hashe nabízí podobný výkon. Operace spojení hash jsou ale často mnohem rychlejší, pokud se tyto dvě velikosti vstupu výrazně liší od sebe.
Sloučení spojení vyžaduje, aby oba vstupy byly seřazeny ve sloupcích sloučení, které jsou definovány klauzulí rovnosti (ON) predikátu spojení. Optimalizátor dotazů obvykle prohledá index, pokud existuje ve správné sadě sloupců nebo umístí operátor řazení pod slučovací spojení. Ve výjimečných případech může existovat více klauzulí rovnosti, ale slučovací sloupce jsou převzaty pouze z některých dostupných klauzulí rovnosti.
Vzhledem k tomu, že každý vstup je seřazený, operátor merge join získá řádek z každého vstupu a porovná je. Například pro operace vnitřního spojení se řádky vrátí, pokud jsou stejné. Pokud nejsou stejné, řádek s nižší hodnotou se zahodí a z daného vstupu se získá další řádek. Tento proces se opakuje, dokud nebudou zpracovány všechny řádky.
Operace "merge join" je buď běžná, nebo operace M:N. Spojení sloučení M:N používá k ukládání řádků dočasnou tabulku. Pokud jsou z každého vstupu duplicitní hodnoty, jeden ze vstupů se musí převinout zpět na začátek duplicit, protože každý duplikát z druhého vstupu se zpracuje.
Pokud je k dispozici reziduální predikát, vyhodnotí se všechny řádky, které vyhovují predikátu sloučení, a vrátí se pouze ty řádky, které vyhovují.
Merge join je velmi rychlé, ale může být nákladná volba, pokud jsou potřeba operace řazení. Pokud je ale objem dat velký a požadovaná data je možné získat předem seřazená z existujících B-stromových indexů, algoritmus merge join je často nejrychlejší dostupný algoritmus spojení.
Spojení hash
Spojení hash mohou efektivně zpracovávat velké, neseřazené a neindexované vstupy. Jsou užitečné pro přechodné výsledky v složitých dotazech, protože:
- Průběžné výsledky se neindexují (pokud nejsou explicitně uloženy na disk a pak indexovány) a často nejsou vhodné pro další operaci v plánu dotazu.
- Optimalizátory dotazů odhadují pouze velikosti průběžných výsledků. Vzhledem k tomu, že odhady mohou být velmi nepřesné pro složité dotazy, musí být algoritmy pro zpracování průběžných výsledků nejen efektivní, ale také musí být elegantně degradované, pokud se ukáže, že průběžný výsledek je mnohem větší, než se čekalo.
Hashové spojení umožňuje omezit použití denormalizace. Denormalizace se obvykle používá k dosažení lepšího výkonu snížením operací spojení, a to i přes nebezpečí redundance, jako jsou nekonzistentní aktualizace. Spojení hash snižují potřebu denormalizovat. Spojení hash umožňují vertikální dělení (představující skupiny sloupců z jedné tabulky v samostatných souborech nebo indexech), aby se stala proveditelnou možností pro návrh fyzické databáze.
Hashové spojení má dva vstupy: vstup sestavení a vstup sondy. Optimalizátor dotazů přiřadí tyto role tak, aby menší ze dvou vstupů byl vstup pro sestavení.
Spojení hash se používají pro mnoho typů operací párování množin: vnitřní spojení; levé, pravé a úplné vnější spojení; levé a pravé semispojení; průnik; sjednocení; a rozdíl. Kromě toho může varianta spojení hash provádět duplicitní odebrání a seskupování, například SUM(salary) GROUP BY department. Tyto úpravy používají pouze jeden vstup jak pro role sestavení, tak i pro role sondy.
Následující části popisují různé typy spojení hash: spojení hash v paměti, Grace hash spojení a rekurzivní spojení hash.
Spojení hash v operační paměti
Hash spojení nejprve prohledá nebo vypočítá celý vstup pro sestavení a poté vytvoří hashovou tabulku v paměti. Každý řádek se vloží do kontejneru hash v závislosti na hodnotě hash vypočítané pro klíč hash. Pokud je celý vstup sestavení menší než dostupná paměť, lze všechny řádky vložit do tabulky hash. Po této fázi sestavení následuje fáze sondování. Celý vstup sondy je skenován nebo vypočítáván po jednom řádku, a pro každý řádek sondy se vypočítá hodnota hash klíče, prohledá se odpovídající hash kbelík a vytvoří se shody.
Grace hash join (Grace hash spojení)
Pokud se vstup sestavení nevejde do paměti, spojení hash pokračuje v několika krocích. To se označuje jako hash spojení typu odložené zpracování. Každý krok má fázi sestavení a fázi sondy. Zpočátku se celý vstup sestavení a sondy zpracovává a rozděluje (pomocí hashovací funkce na hash klíčích) do více souborů. Použití hashovací funkce na hash klíčích zaručuje, že jakékoli dva spárované záznamy musí být ve stejné dvojici souborů. Proto se úloha spojení dvou velkých vstupů snížila na více, ale menší instance stejných úloh. Spojení hash se pak použije pro každou dvojici dělených souborů.
Rekurzivní hashové spojení
Pokud je vstup sestavení tak velký, aby vstupy pro standardní externí sloučení vyžadovaly více úrovní sloučení, vyžaduje se několik kroků dělení a více úrovní dělení. Pokud jsou velké jenom některé oddíly, použijí se další postupy dělení jenom pro konkrétní oddíly. Aby bylo možné co nejrychleji provést všechny kroky dělení na oddíly, používají se velké asynchronní vstupně-výstupní operace, aby jedno vlákno mohlo udržovat více diskových jednotek zaneprázdněných.
Note
Pokud je vstup sestavení pouze o něco větší než dostupná paměť, zkombinují se prvky spojení hash v paměti a grace hash spojení v jednom kroku, čímž vznikne hybridní hash spojení.
Během optimalizace není vždy možné určit, které spojení hash se používá. SQL Server proto začíná použitím in-memory hash spojení a postupně přechází na Grace hash spojení a rekurzivní hash spojení, v závislosti na velikosti vstupních dat sestavení.
Pokud optimalizátor dotazů nesprávně předpokládá, který ze dvou vstupů je menší, a proto by měl být vstupem pro sestavení, role pro sestavení a vstupu pro sondování jsou dynamicky zaměněny. Algoritmus hash join zajišťuje, že jako vstup pro sestavení používá přetečený soubor menších rozměrů. Tato technika se nazývá vrácení role zpět. K vrácení role dojde uvnitř spojení hash po alespoň jednom přelití na disk.
Note
Převrácení role probíhá nezávisle na jakýchkoli nápovědách nebo struktuře dotazů. Vrácení role se v plánu dotazu nezobrazuje. pokud k tomu dojde, je pro uživatele transparentní.
Sanace hash
Termín "hash bailout" se někdy používá k popisu grace hash spojení a/nebo rekurzivní hash spojení.
Note
Rekurzivní spojení hash nebo sanace hash způsobují snížení výkonu na vašem serveru. Pokud v trasování vidíte mnoho upozornění na události hash, aktualizujte statistiky sloupců, které jsou spojeny.
Další informace o záchraně hash naleznete v tématu Hash Warning Event Class.
Adaptivní spojení
Režim dávkového zpracování Adaptivní spojení umožňuje odložení výběru metody hash spojení nebo spojení vnořených smyček až po dokončení skenování prvního vstupu. Operátor adaptivního spojení definuje prahovou hodnotu, která se používá k rozhodnutí o přechodu na plán vnořených smyček. Plán dotazů se proto může dynamicky přepnout na lepší strategii spojení během provádění, aniž by bylo nutné překompilovat.
Tip
Úlohy s častými oscilacemi mezi malými a velkými vstupními kontrolami spojení budou z této funkce těžit nejvíce.
Rozhodnutí o modulu runtime je založené na následujících krocích:
- Pokud je počet řádků vstupu spojení sestavení tak malý, že by spojení vnořených smyček bylo optimálnější než spojení pomocí hash, plán se přepne na algoritmus vnořených smyček.
- Pokud vstup spojení sestavení překročí určitou prahovou hodnotu počtu řádků, k žádnému přepnutí nedojde a váš plán bude pokračovat s hash spojením.
Následující dotaz se používá k ilustraci příkladu adaptivního spojení:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
Dotaz vrátí 336 řádků. Při povolení statistiky živého dotazu se zobrazí následující plán:

V plánu si všimněte těchto věcí:
- Kontrola indexu columnstore sloužící k poskytnutí řádků pro fázi sestavení spojení hash.
- Nový operátor adaptivní spojení. Tento operátor definuje prahovou hodnotu, která se používá k rozhodnutí o přechodu na plán vnořených smyček. V tomto příkladu je prahová hodnota 78 řádků. Cokoli s >= 78 řádků použije spojení hash. Pokud je nižší než prahová hodnota, použije se spojení vnořených smyček.
- Vzhledem k tomu, že dotaz vrátí 336 řádků, tato hodnota překročila prahovou hodnotu, a proto druhá větev představuje sondovací fázi standardní operace hash spojení. Live Query Statistics zobrazuje řádky, které procházejí operátory – v tomto případě „672 z 672“.
- Poslední větev je vyhledávání v clusterovaném indexu pro použití spojení vnořenými smyčkami, pokud by nebyla překročena prahová hodnota. Zobrazuje se "0 z 336" řádků (větev se nepoužívá).
Nyní porovnejte plán se stejným dotazem, ale pokud Quantity má hodnota v tabulce pouze jeden řádek:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
Dotaz vrátí jeden řádek. Při povolení statistiky živého dotazu se zobrazí následující plán:

V plánu si všimněte těchto věcí:
- Když se vrátí jeden řádek, clusterované hledání indexů teď obsahuje řádky, kterými prochází.
- A vzhledem k tomu, že fáze sestavení hash join nepokračovala, neprotéká přes druhou větev žádné řádky.
Poznámky k adaptivnímu spojení
Adaptivní spojení představují vyšší požadavek na paměť než plán ekvivalentní k indexovaným spojům s vnořenými smyčkami. Další paměť je požadována, jako by vnořené smyčky byly spojení hash. Pro fázi sestavení je také režijní náklady na operaci zastavení a přechodu oproti připojení ekvivalentu streamování vnořených smyček. Díky tomuto dodatečnému nákladu získáte flexibilitu pro scénáře, kdy počet řádků ve vstupu sestavení kolísá.
Adaptivní spojení v dávkovém režimu fungují pro počáteční spuštění příkazu a po kompilaci zůstanou následující spuštění adaptivní na základě zkompilované prahové hodnoty adaptivního spojení a běhových řádků, které procházejí fází sestavení vnějšího vstupu.
Pokud se Adaptive Join přepne na operaci vnořené smyčky, použije řádky, které již byly přečteny během sestavení operace hash join. Operátor znovu nepřečte vnější odkazové řádky.
Sledovat aktivitu adaptivního spojení
Operátor adaptivního spojení má následující atributy operačního plánu:
| Atribut Plánu | Description |
|---|---|
| AdaptiveThresholdRows | Zobrazuje prahovou hodnotu, která se používá k přepnutí z spojení hash na vnořené spojení smyčky. |
| EstimatedJoinType | Jaký typ spojení pravděpodobně bude. |
| ActualJoinType | Ve skutečném plánu ukazuje, jaký algoritmus spojení byl nakonec zvolen na základě prahové hodnoty. |
Odhadovaný plán zobrazuje obrazec plánu Adaptivní spojení spolu s definovanou prahovou hodnotou adaptivního spojení a odhadovaným typem spojení.
Tip
Úložiště dotazů zaznamenává a dokáže vynutit plán adaptivního připojení v dávkovém režimu.
Příkazy způsobilé pro adaptivní spojení
Několik podmínek činí logické spojení způsobilé pro adaptivní připojení v dávkovém režimu:
- Úroveň kompatibility databáze je 140 nebo vyšší.
- Dotaz je
SELECTpříkaz (příkazy pro úpravu dat jsou momentálně nezpůsobilé). - Spojení je možné provést jak prostřednictvím indexovaného spojení vnořených smyček, tak fyzického algoritmu hash spojení.
- Spojení hash používá režim Batch, který je povolený prostřednictvím přítomnosti indexu columnstore v dotazu celkově, indexované tabulky columnstore odkazované přímo spojením nebo pomocí režimu Batch v úložišti řádků.
- Alternativní řešení vygenerovaná pro vnořené smyčky spojení a hash spojení by měla mít stejné první dítě (vnější reference).
Adaptivní prahové řádky
Následující graf ukazuje příklad srovnání mezi náklady na Hash join a náklady na alternativu Nested Loops join. V tomto bodě průsečíku je prahová hodnota stanovena, která následně určuje použitý algoritmus pro spojovací operaci.
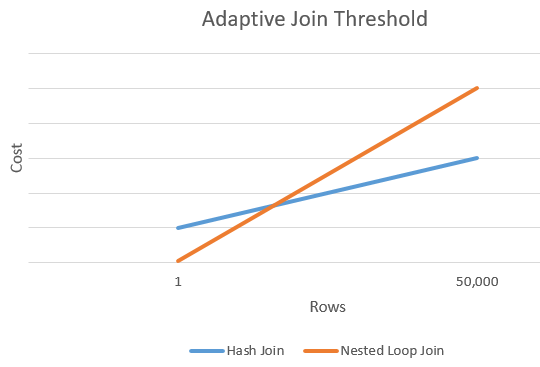
Zákaz adaptivních spojení beze změny úrovně kompatibility
Adaptivní spojení je možné zakázat v oboru databáze nebo příkazu a přitom zachovat úroveň kompatibility databáze 140 a vyšší.
Pokud chcete zakázat adaptivní spojení pro všechna spuštění dotazů pocházející z databáze, spusťte v kontextu příslušné databáze následující příkaz:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Pokud je toto nastavení povolené, zobrazí se v sys.database_scoped_configurations jako povolené.
Pokud chcete znovu povolit adaptivní spojení pro všechna spuštění dotazů pocházející z databáze, spusťte v kontextu příslušné databáze následující příkaz:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
Adaptivní spojení je také možné pro konkrétní dotaz zakázat tak, že se označí DISABLE_BATCH_MODE_ADAPTIVE_JOINS jako nápověda k dotazu USE HINT. Například:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
USE HINT Tip dotazu má přednost před nastavením příznaku trasování nebo konfigurace v oboru databáze.
Hodnoty null a spojení
Pokud jsou ve sloupcích tabulek spojené hodnoty null, hodnoty null se navzájem neshodují. Přítomnost hodnot null ve sloupci z jedné z spojených tabulek může být vrácena pouze pomocí vnějšího spojení (pokud WHERE klauzule nezahrnuje hodnoty null).
Tady jsou dvě tabulky, které mají NULL ve svém sloupci, který se bude účastnit propojení:
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Spojení, které porovnává hodnoty ve sloupci a se sloupcem c , se neshoduje se sloupci, které mají hodnoty NULL:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Vrátí se pouze jeden řádek s hodnotou 4 ve sloupcích ac:
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Hodnoty null vrácené ze základní tabulky jsou také obtížné odlišit od hodnot null vrácených z vnějšího spojení. Například následující SELECT příkaz provede levé vnější spojení těchto dvou tabulek:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Tady je soubor výsledků.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
Výsledky neusnadní rozlišení NULL dat od NULL data, která představují selhání spojení. Pokud NULL jsou hodnoty přítomny ve spojení dat, je obvykle vhodnější je vynechat z výsledků pomocí běžného spojení.