Použití Sparku ve službě Azure Synapse Analytics
Ve Sparku můžete spustit mnoho různých druhů aplikací, včetně kódu ve skriptech Pythonu nebo Scala, kódu Java zkompilovaného jako Java Archive (JAR) a dalších. Spark se běžně používá ve dvou typech úloh:
- Úlohy dávkového zpracování nebo zpracování datových proudů za účelem ingestování, čištění a transformace dat – často běží jako součást automatizovaného kanálu.
- Interaktivní analytické relace pro zkoumání, analýzu a vizualizaci dat
Spouštění kódu Sparku v poznámkových blocích
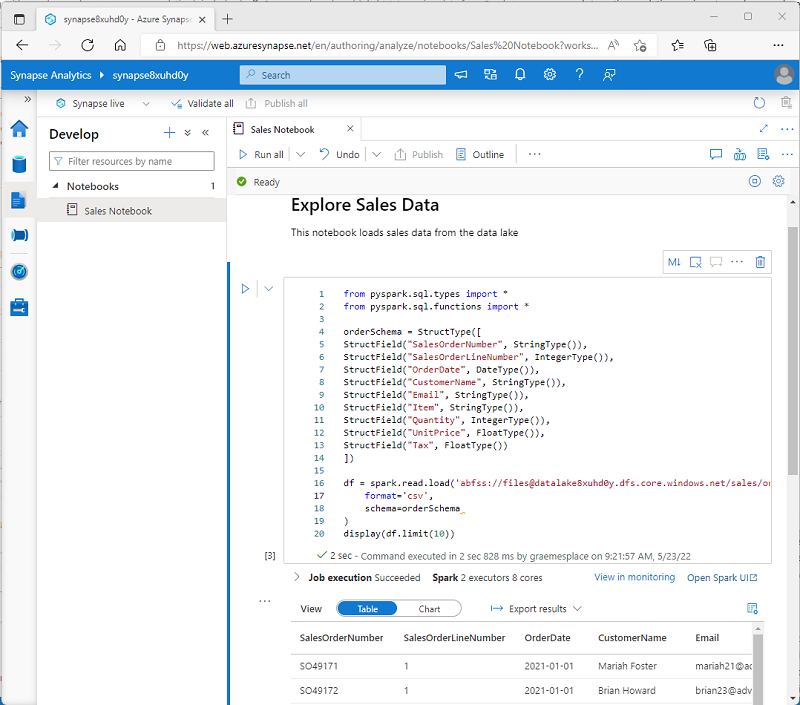
Azure Synapse Studio obsahuje integrované rozhraní poznámkového bloku pro práci se Sparkem. Poznámkové bloky poskytují intuitivní způsob kombinování kódu s poznámkami Markdownu, které běžně používají datoví vědci a datoví analytici. Vzhled integrovaného prostředí poznámkového bloku v nástroji Azure Synapse Studio je podobný prostředí jupyter notebooků – oblíbené opensourcové platformě poznámkových bloků.
Poznámka:
I když se poznámkové bloky obvykle používají interaktivně, dají se zahrnout do automatizovaných kanálů a spouštět jako bezobslužný skript.
Poznámkové bloky se skládají z jedné nebo více buněk, z nichž každá obsahuje buď kód, nebo text formátovaný jako markdown. Buňky kódu v poznámkových blocích mají některé funkce, které vám můžou pomoct zvýšit produktivitu, včetně těchto:
- Podpora zvýrazňování syntaxe a chyb
- Automatické dokončování kódu
- Interaktivní vizualizace dat
- Možnost exportu výsledků
Návod
Další informace o práci s poznámkovými bloky v Azure Synapse Analytics najdete v článku Vytváření, vývoj a údržba poznámkových bloků Synapse v Azure Synapse Analytics v dokumentaci k Azure Synapse Analytics.
Přístup k datům z fondu Synapse Spark
Spark ve službě Azure Synapse Analytics můžete použít k práci s daty z různých zdrojů, mezi které patří:
- Datové jezero založené na primárním účtu úložiště pro pracovní prostor Azure Synapse Analytics.
- Datové jezero založené na úložišti, které je definováno jako propojená služba v pracovním prostoru.
- Vyhrazený nebo bezserverový fond SQL v pracovním prostoru.
- Databáze Azure SQL nebo SQL Serveru (pomocí konektoru Spark pro SQL Server)
- Analytická databáze Azure Cosmos DB definovaná jako propojená služba a nakonfigurovaná pomocí Azure Synapse Link pro Cosmos DB.
- Databáze Kusto Azure Data Exploreru definovaná jako propojená služba v pracovním prostoru.
- Externí metastor Hive definovaný jako propojená služba v pracovním prostoru.
Jedním z nejběžnějších použití Sparku je práce s daty v datovém jezeře, kde můžete číst a zapisovat soubory v několika běžně používaných formátech, včetně textu s oddělovači, Parquet, Avro a dalších.