Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Poznámkový blok ve službě Azure Synapse Analytics (poznámkový blok Synapse) je webové rozhraní pro vytváření souborů, které obsahují živý kód, vizualizace a popisný text. Poznámkové bloky jsou vhodným místem pro ověřování nápadů a rychlé experimenty, které vám pomohou získat poznatky z dat. Poznámkové bloky se také běžně používají při přípravě dat, vizualizaci dat, strojovém učení a dalších scénářích pro velké objemy dat.
S poznámkovým blokem Synapse můžete:
- Začněte bez jakéhokoliv úsilí na nastavení.
- Pomáhá zajistit zabezpečení dat pomocí integrovaných podnikových funkcí zabezpečení.
- Analyzujte data v nezpracovaných formátech (například CSV, TXT a JSON), zpracovaných formátech souborů (například Parquet, Delta Lake a ORC) a tabulkových datových souborů SQL pro Spark a SQL.
- Buďte produktivní díky vylepšeným možnostem vytváření a integrované vizualizaci dat.
Tento článek popisuje, jak používat poznámkové bloky v nástroji Synapse Studio.
Vytvořte poznámkový blok
Můžete vytvořit nový poznámkový blok nebo importovat existující poznámkový blok do pracovního prostoru Synapse z Průzkumník objektů. Vyberte nabídku Vývoj. + Vyberte tlačítko a vyberte Poznámkový blok nebo klikněte pravým tlačítkem na Poznámkové bloky a pak vyberte Nový poznámkový blok nebo Importovat. Poznámkové bloky Synapse rozpoznávají standardní soubory poznámkového bloku Jupyter ve formátu IPYNB.
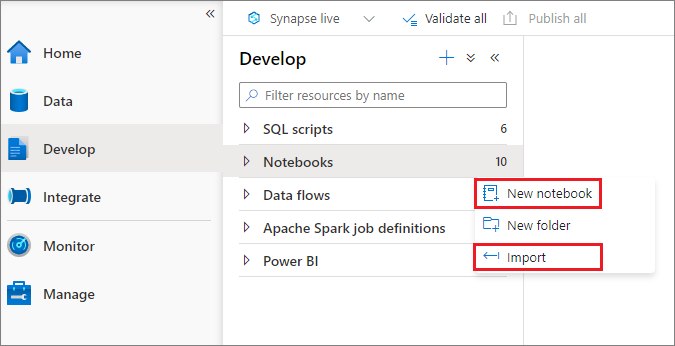
Vývoj poznámkových bloků
Poznámkové bloky se skládají z buněk, které jsou jednotlivé bloky kódu nebo textu, které můžete spouštět nezávisle nebo jako skupinu.
Následující části popisují operace vývoje poznámkových bloků:
- Přidání buňky
- Nastavení primárního jazyka
- Použití více jazyků
- Použití dočasných tabulek k odkazování na data napříč jazyky
- Použití technologie IntelliSense ve stylu integrovaného vývojového prostředí
- Používání fragmentů kódu
- Formátování textových buněk pomocí tlačítek panelu nástrojů
- Vrácení nebo opětovné provedení operace buňky
- Komentář k buňce kódu
- Přesunutí buňky
- Zkopírování buňky
- Odstranění buňky
- Sbalit vstup do buňky
- Sbal výstup buňky
- Použijte osnovu poznámkového bloku
Poznámka:
V poznámkových blocích je pro vás automaticky vytvořena instance SparkSession a uloží se do proměnné s názvem spark. Existuje také proměnná pro SparkContext nazvaná sc. Uživatelé mají k těmto proměnným přístup přímo, ale neměli by měnit hodnoty těchto proměnných.
Přidání buňky
Do poznámkového bloku můžete přidat novou buňku několika způsoby:
Najeďte myší na mezeru mezi dvěma buňkami a vyberte Kód nebo Markdown.
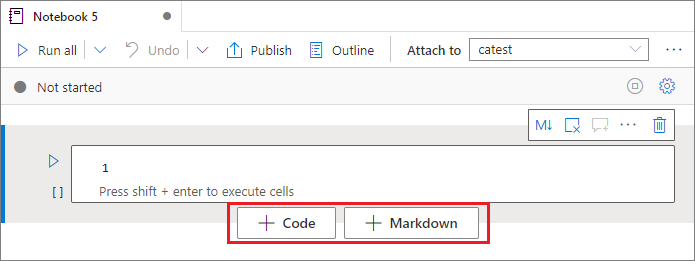
Používejte klávesové zkratky v režimu příkazů. Výběrem klávesy A vložte buňku nad aktuální buňku. Výběrem klávesy B vložte buňku pod aktuální buňku.
Nastavení primárního jazyka
Poznámkové bloky Synapse podporují pět jazyků Apache Spark:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
Primární jazyk pro nově přidané buňky můžete nastavit z rozevíracího seznamu Jazyk na horním panelu příkazů.
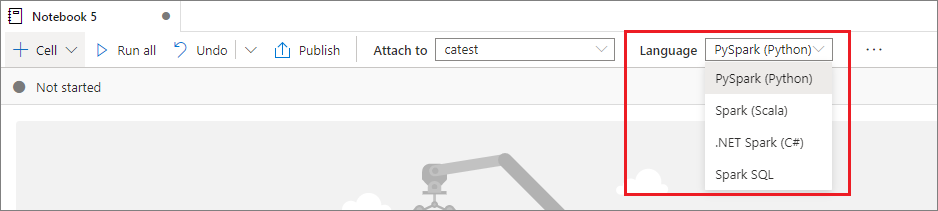
Použití více jazyků
V jednom poznámkovém bloku můžete použít více jazyků zadáním správného magického příkazu na začátku buňky. Následující tabulka uvádí magické příkazy pro přepínání jazyků buněk.
| Magický příkaz | Jazyk | Popis |
|---|---|---|
%%pyspark |
Python | Spusťte dotaz Pythonu proti SparkContext. |
%%spark |
Scala | Spusťte dotaz Scala proti SparkContext. |
%%sql |
Spark SQL | Spusťte dotaz Spark SQL na SparkContext. |
%%csharp |
.NET pro Spark C# | Spusťte dotaz .NET pro Spark C# pro SparkContext. |
%%sparkr |
R | Spusťte dotaz R proti SparkContext. |
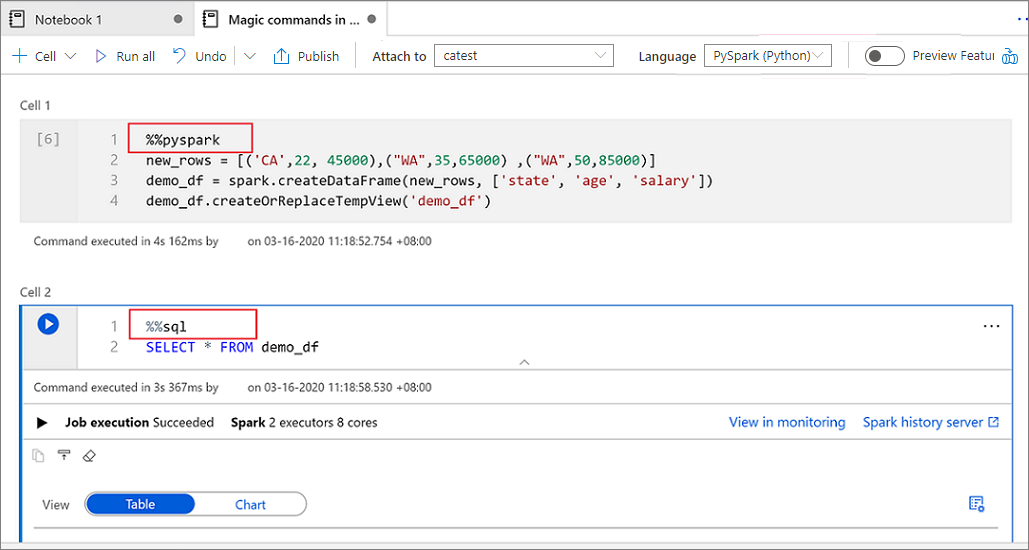
Následující obrázek ukazuje příklad, jak můžete psát dotaz PySpark pomocí %%pyspark příkazu magic nebo dotazu Spark SQL pomocí %%sql příkazu magic v poznámkovém bloku Spark (Scala). Primární jazyk poznámkového bloku je nastavený na PySpark.
Použití dočasných tabulek k odkazování na data napříč jazyky
V poznámkovém bloku Synapse nemůžete odkazovat na data ani proměnné přímo v různých jazycích. Ve Sparku můžete odkazovat na dočasnou tabulku napříč jazyky. Tady je příklad, jak číst datový rámec Scala v PySpark a Spark SQL pomocí dočasné tabulky Spark jako alternativní řešení:
V buňce 1 načtěte DataFrame z konektoru fondu SQL pomocí Scaly a vytvořte dočasnou tabulku.
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )V buňce 2 zadejte dotaz na data pomocí Spark SQL:
%%sql SELECT * FROM mydataframetableV buňce 3 použijte data v PySparku:
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
Použití technologie IntelliSense ve stylu integrovaného vývojového prostředí
Poznámkové bloky Synapse jsou integrované s editorem Monaku, aby se do editoru buněk přenesla technologie IntelliSense ve stylu IDE. Funkce zvýrazňování syntaxe, značky chyb a automatického dokončování kódu pomáhají psát kód a identifikovat problémy rychleji.
Funkce IntelliSense jsou na různých úrovních vyspělosti pro různé jazyky. V následující tabulce se dozvíte, co je podporované.
| Jazyky | Zvýraznění syntaxe | Značka chyby syntaxe | Dokončování kódu syntaxe | Automatické dokončování kódu pro proměnné | Dokončování kódu systémové funkce | Dokončování kódu funkce uživatele | Inteligentní odsazení | Skrytí kódu |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Ano | Ano | Ano | Ano | Ano | Ano | Ano | Ano |
| Spark (Scala) | Ano | Ano | Ano | Ano | Ano | Ano | Ne | Ano |
| Spark SQL | Ano | Ano | Ano | Ano | Ano | Ne | Ne | Ne |
| .NET pro Spark (C#) | Ano | Ano | Ano | Ano | Ano | Ano | Ano | Ano |
Aktivní relace Sparku je nutná k využití dokončování kódu proměnných, dokončování kódu systémových funkcí a dokončování kódu uživatelských funkcí pro .NET pro Spark (C#).
Použití fragmentů kódu
Poznámkové bloky Synapse poskytují fragmenty kódu, které usnadňují zadávání běžně používaných vzorů kódu. Mezi tyto vzory patří konfigurace relace Sparku, čtení dat jako datového rámce Sparku a vytváření grafů pomocí knihovny Matplotlib.
Fragmenty kódu se zobrazují v klávesových zkratkách IntelliSense v IDE stylu smíchané s jinými návrhy. Obsah úryvků kódu odpovídá jazyku buňky kódu. Dostupné fragmenty kódu můžete zobrazit zadáním fragmentu kódu nebo libovolných klíčových slov, která se zobrazí v názvu fragmentu kódu v editoru buněk kódu. Zadáním příkazu read můžete například zobrazit seznam fragmentů kódu pro čtení dat z různých zdrojů dat.

Formátování textových buněk pomocí tlačítek panelu nástrojů
Pomocí tlačítek formátu na panelu nástrojů textové buňky můžete provádět běžné akce Markdownu. Mezi tyto akce patří vytváření textu tučně, kurzíva textu, vytváření odstavců a nadpisů prostřednictvím rozevírací nabídky, vložení kódu, vložení neuspořádaného seznamu, vložení uspořádaného seznamu, vložení hypertextového odkazu a vložení obrázku z adresy URL.
Vrácení nebo opětovné provedení operace v buňce
Pokud chcete odvolat nejnovější operace buněk, vyberte tlačítko Zpět nebo Znovu nebo stiskněte klávesu Z nebo Shift+Z. Nyní můžete vrátit zpět nebo znovu provést až 10 historických operací v buňkách.

Mezi podporované operace buněk patří:
- Vložte nebo odstraňte buňku Operace odstranění můžete odvolat výběrem možnosti Zpět. Tato akce zachová textový obsah společně s buňkou.
- Změnit pořadí buněk
- Zapněte nebo vypněte buňku parametru.
- Převod mezi buňkou kódu a buňkou Markdownu
Poznámka:
Nelze vrátit zpět operace s textem ani operace s komentáři v buňce.
Komentář k buňce kódu
Výběrem tlačítka Komentáře na panelu nástrojů poznámkového bloku otevřete podokno Komentáře.
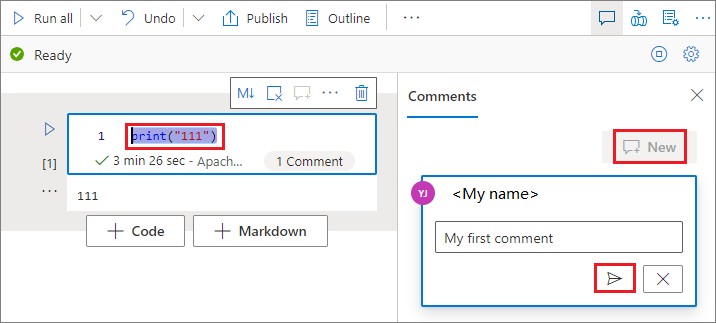
Vyberte kód v buňce kódu, v podokně Komentáře vyberte Nový, přidejte komentáře a pak vyberte tlačítko Publikovat komentář.
V případě potřeby můžete provést akce Upravit komentář, Vyřešit vlákno a Odstranit vlákno výběrem ikony Další (tři tečky ...) vedle svého komentáře.
Přesunutí buňky
Pokud chcete buňku přesunout, vyberte levou stranu buňky a přetáhněte ji na požadovanou pozici.
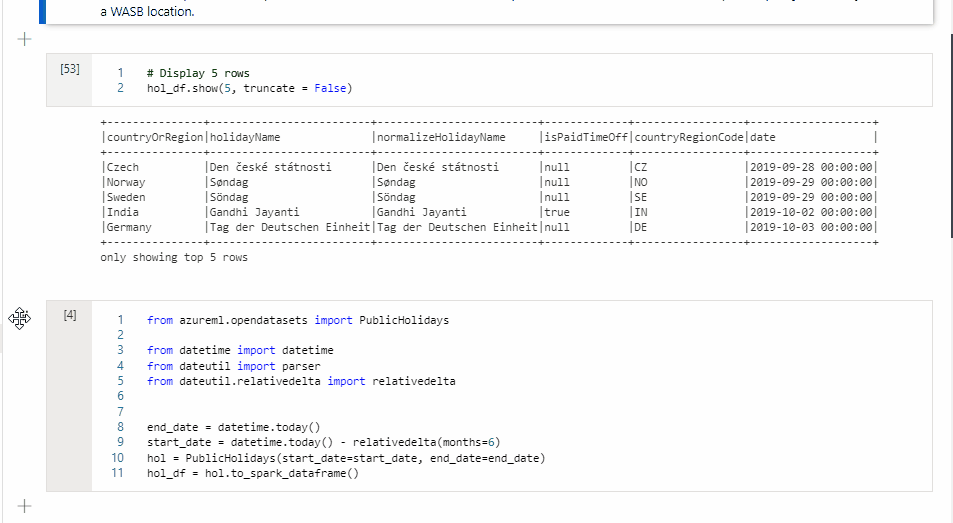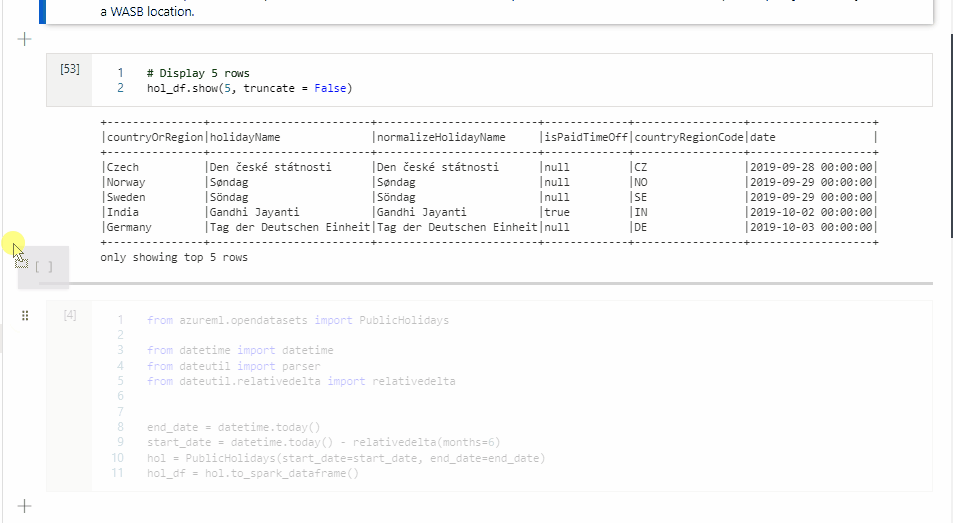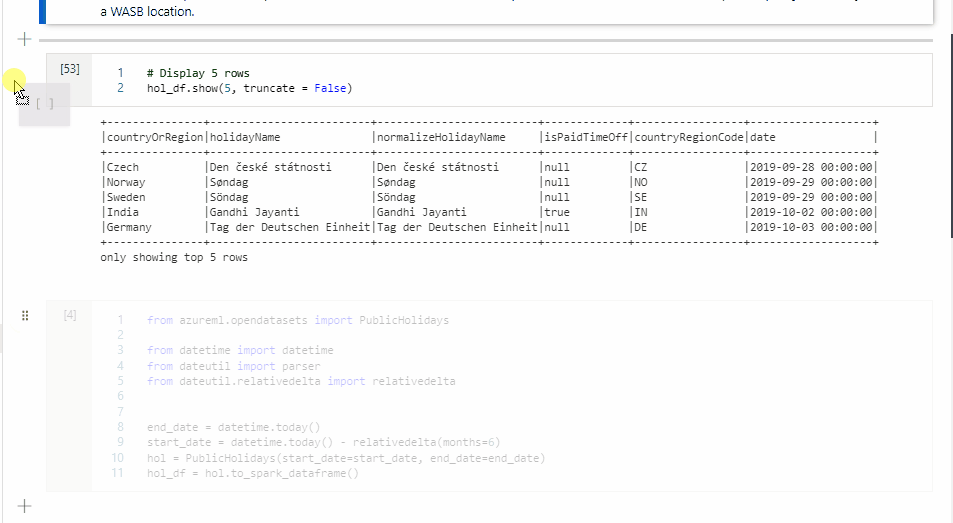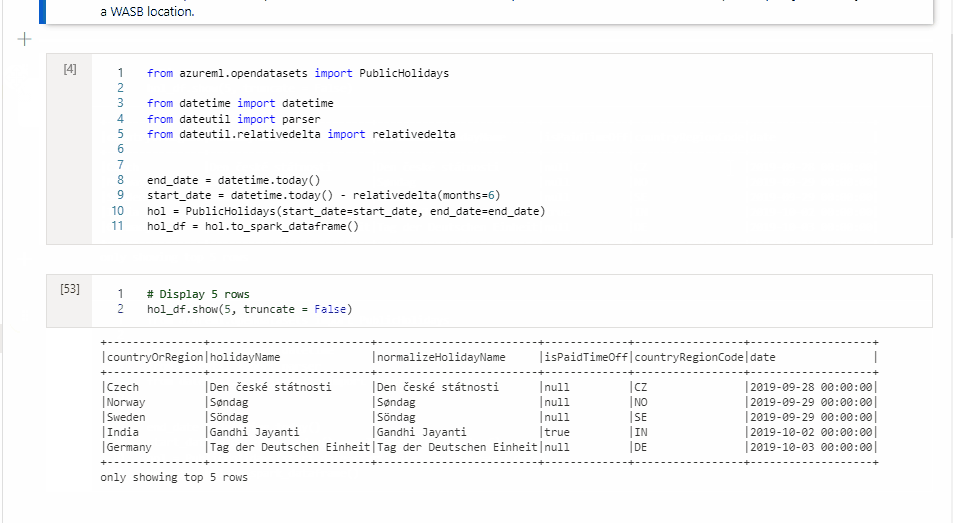
Zkopírování buňky
Pokud chcete zkopírovat buňku, nejprve vytvořte novou buňku a pak vyberte veškerý text v původní buňce, zkopírujte text a vložte ho do nové buňky. Pokud je buňka v režimu úprav, tradiční klávesové zkratky pro výběr veškerého textu jsou omezené na buňku.
Tip
Poznámkové bloky Synapse také poskytují úryvky běžně používaných vzorů kódu.
Odstranění buňky
Pokud chcete odstranit buňku, vyberte tlačítko Odstranit napravo od buňky.
Můžete také použít klávesové zkratky v režimu příkazů. Pokud chcete aktuální buňku odstranit, vyberte Shift+D.
Skrýt vstup buňky
Pokud chcete sbalit vstup aktuální buňky, vyberte ikonu Další příkazy (...) na panelu nástrojů buňky a pak vyberte Skrýt vstup. Pokud chcete vstup rozbalit, vyberte Zobrazit vstup, když je buňka zavřená.
Sbalit výstup buňky
Pokud chcete sbalit výstup aktuální buňky, vyberte více příkazů (...) na panelu nástrojů buňky a potom vyberte Skrýt výstup. Pokud chcete výstup rozbalit, vyberte Zobrazit výstup , zatímco výstup buňky je skrytý.
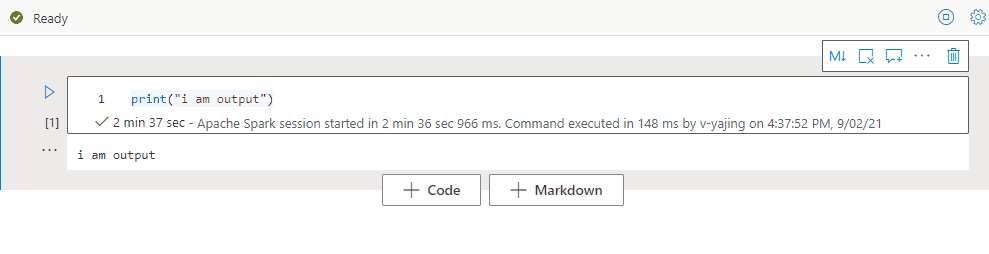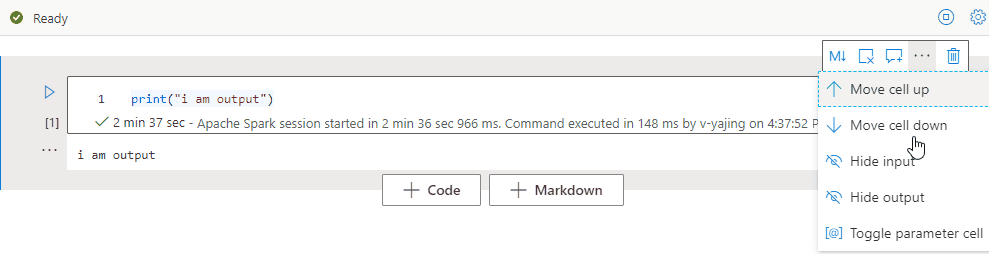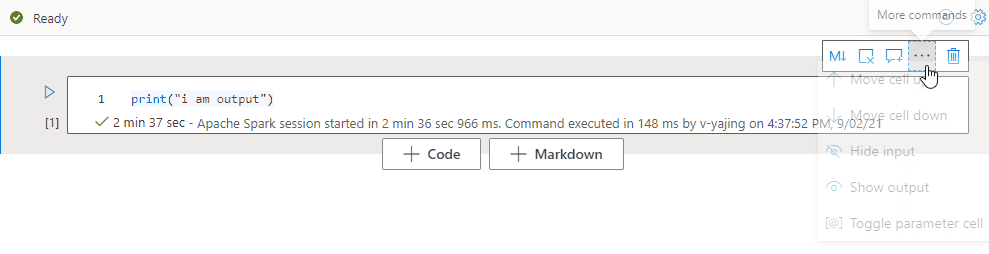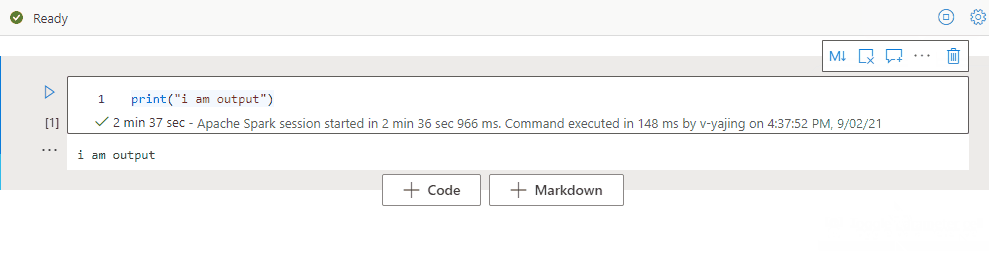
Použijte osnovu poznámkového bloku
Osnova (obsah) zobrazuje první nadpis jakékoliv Markdownové buňky v bočním panelu okna pro rychlou navigaci. Boční panel osnovy se dá přizpůsobit a sbalit tak, aby se na obrazovku vešel co nejlépe. Boční panel otevřete nebo skryjete tak, že na panelu příkazů poznámkového bloku vyberete tlačítko Osnova .
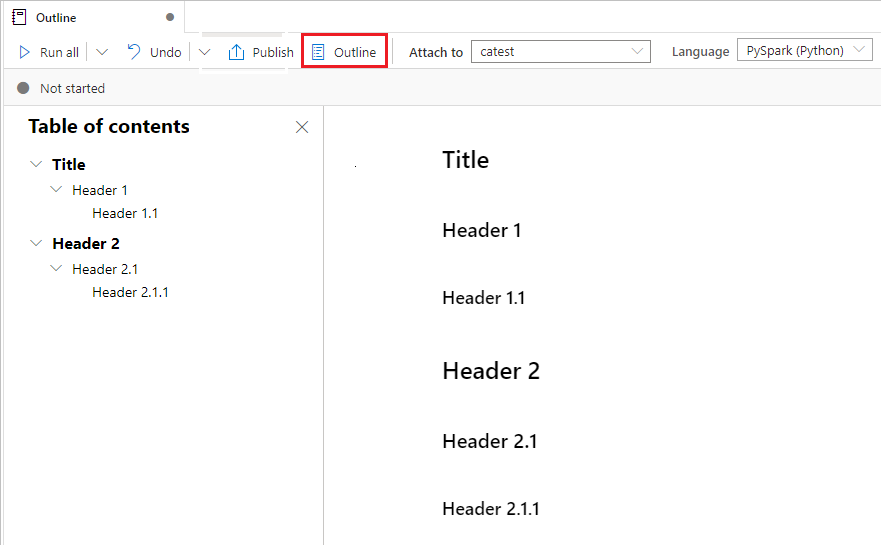
Spusťte poznámkový blok
Buňky kódu můžete v poznámkovém bloku spouštět jednotlivě nebo najednou. Stav a průběh jednotlivých buněk se zobrazí v poznámkovém bloku.
Poznámka:
Odstranění poznámkového bloku automaticky nezruší žádné úlohy, které jsou aktuálně spuštěné. Pokud potřebujete zrušit úlohu, přejděte do centra monitorování a zrušte ji ručně.
Spustit buňku
Kód v buňce můžete spustit několika způsoby:
Najeďte myší na buňku, kterou chcete spustit, a pak vyberte tlačítko Spustit buňku nebo stiskněte Ctrl+Enter.

Používejte klávesové zkratky v režimu příkazů. Stisknutím kombinace kláves Shift+Enter spusťte aktuální buňku a vyberte buňku pod ní. Stisknutím kombinace kláves Alt+Enter spusťte aktuální buňku a vložte pod ni novou buňku.
Spustit všechny buňky
Pokud chcete spustit všechny buňky v aktuálním poznámkovém bloku v posloupnosti, vyberte tlačítko Spustit vše .

Spustit všechny buňky nad nebo pod
Pokud chcete spustit všechny buňky nad aktuální buňkou v posloupnosti, rozbalte rozevírací seznam tlačítka Spustit vše a pak vyberte Spustit buňky nad. Výběrem možnosti Spustit buňky níže spustíte všechny buňky pod aktuálním pořadím.
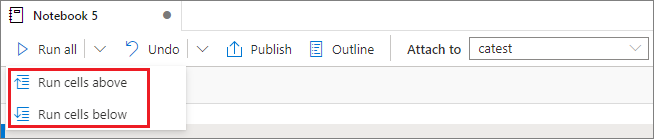
Zrušení všech spuštěných buněk
Pokud chcete zrušit spuštěné buňky nebo buňky čekající ve frontě, vyberte tlačítko Zrušit vše.

Odkaz na poznámkový blok
Pokud chcete odkazovat na jiný poznámkový blok v kontextu aktuálního poznámkového bloku, použijte %run <notebook path> příkaz magic. Všechny proměnné definované v referenčním poznámkovém bloku jsou dostupné v aktuálním poznámkovém bloku.
Tady je příklad:
%run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
Odkaz na notebook funguje v interaktivním režimu i v pipeline.
Příkaz %run magic má tato omezení:
- Příkaz podporuje vnořené volání, ale ne rekurzivní volání.
- Příkaz podporuje předání absolutní cesty nebo názvu poznámkového bloku pouze jako parametr. Nepodporuje relativní cesty.
- Příkaz aktuálně podporuje pouze čtyři typy hodnot parametrů:
int,float,boolastring. Nepodporuje operace nahrazení proměnných. - Odkazované poznámkové bloky musí být publikované. Musíte publikovat poznámkové bloky, abyste na ně mohli odkazovat, pokud nevyberete možnost povolení nepublikovaného odkazu na poznámkový blok. Synapse Studio nerozpozná nepublikované poznámkové bloky z úložiště Git.
- Odkazované poznámkové bloky nepodporují hloubku příkazů větší než pět úrovní.
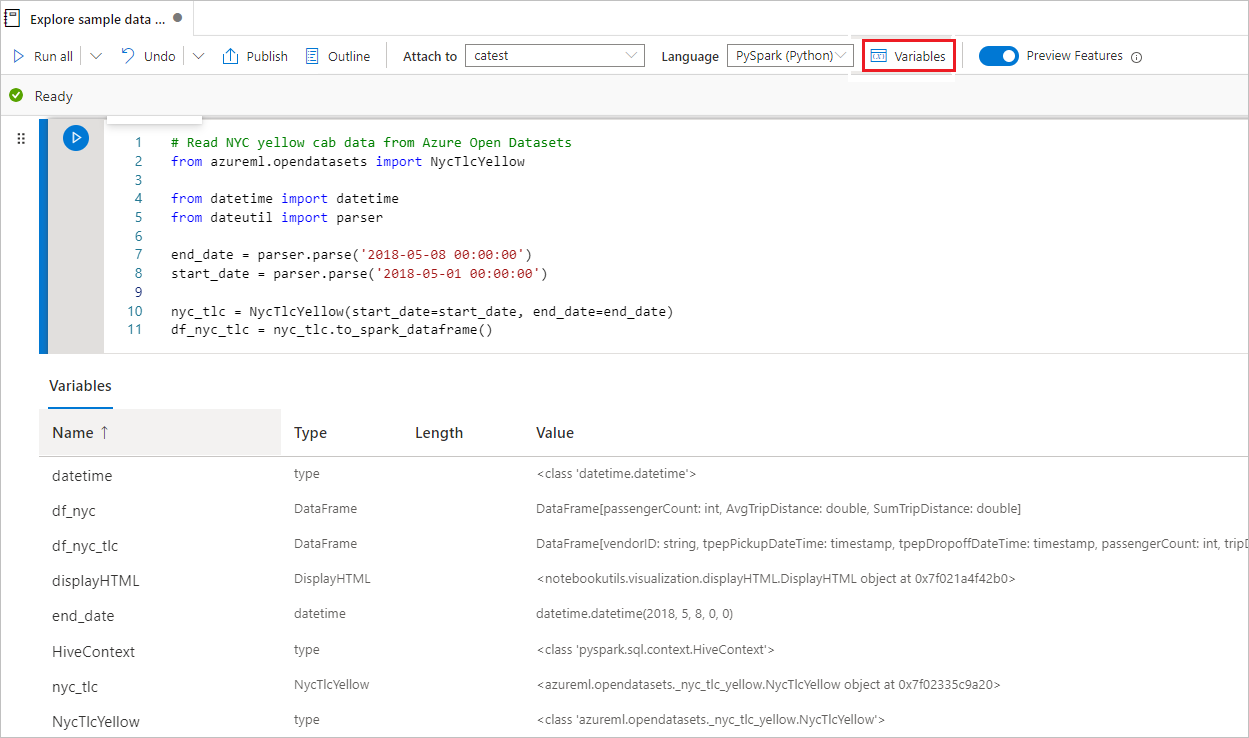
Použijte Průzkumníka proměnných
Notebook Synapse poskytuje integrovaný průzkumník proměnných ve formě tabulky, která uvádí proměnné v aktuální Sparkové relaci pro buňky PySpark (Python). Tabulka obsahuje sloupce pro název proměnné, typ, délku a hodnotu. Při definování v buňkách kódu se automaticky zobrazí více proměnných. Výběr záhlaví jednotlivých sloupců seřadí proměnné v tabulce.
Průzkumníka proměnných otevřete nebo skryjete tak, že na panelu příkazů poznámkového bloku vyberete tlačítko Proměnné .
Poznámka:
Průzkumník proměnných podporuje pouze Python.
Použití indikátoru stavu buňky
Pod buňkou se zobrazí postupný stav běhu buňky, abyste mohl(a) vidět její aktuální průběh. Po dokončení běhu buňky se zobrazí souhrn s celkovou dobou trvání a koncovým časem a zůstane tam pro budoucí referenci.

Použijte indikátor průběhu Spark.
Poznámkový blok Synapse je čistě založený na Sparku. Buňky kódu běží na bezserverovém fondu Apache Spark vzdáleně. Indikátor průběhu úlohy Sparku s reálným grafem postupu vám pomůže pochopit stav úlohy.
Počet úkolů pro každou úlohu nebo fázi vám pomůže identifikovat paralelní úroveň úlohy Sparku. Pokud chcete přejít k podrobnostem v uživatelském rozhraní Sparku konkrétní úlohy (nebo dílčí fáze), vyberte odkaz na název úlohy (nebo fáze).
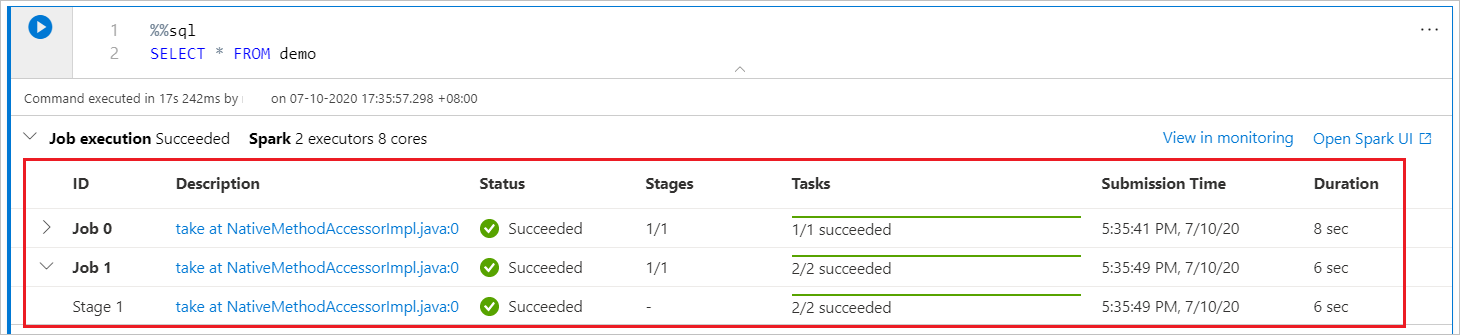
Nakonfigurujte relaci Spark
V podokně Konfigurovat relaci, které najdete výběrem ikony ozubeného kola v horní části poznámkového bloku, můžete určit dobu časového limitu, počet exekutorů a velikost exekutorů, které se mají předat aktuální relaci Sparku. Restartujte relaci Sparku, aby se projevily změny konfigurace. Všechny proměnné poznámkového bloku v mezipaměti jsou vymazány.
Můžete také vytvořit konfiguraci z konfigurace Apache Sparku nebo vybrat existující konfiguraci. Podrobnosti najdete v tématu Správa konfigurace Apache Sparku.
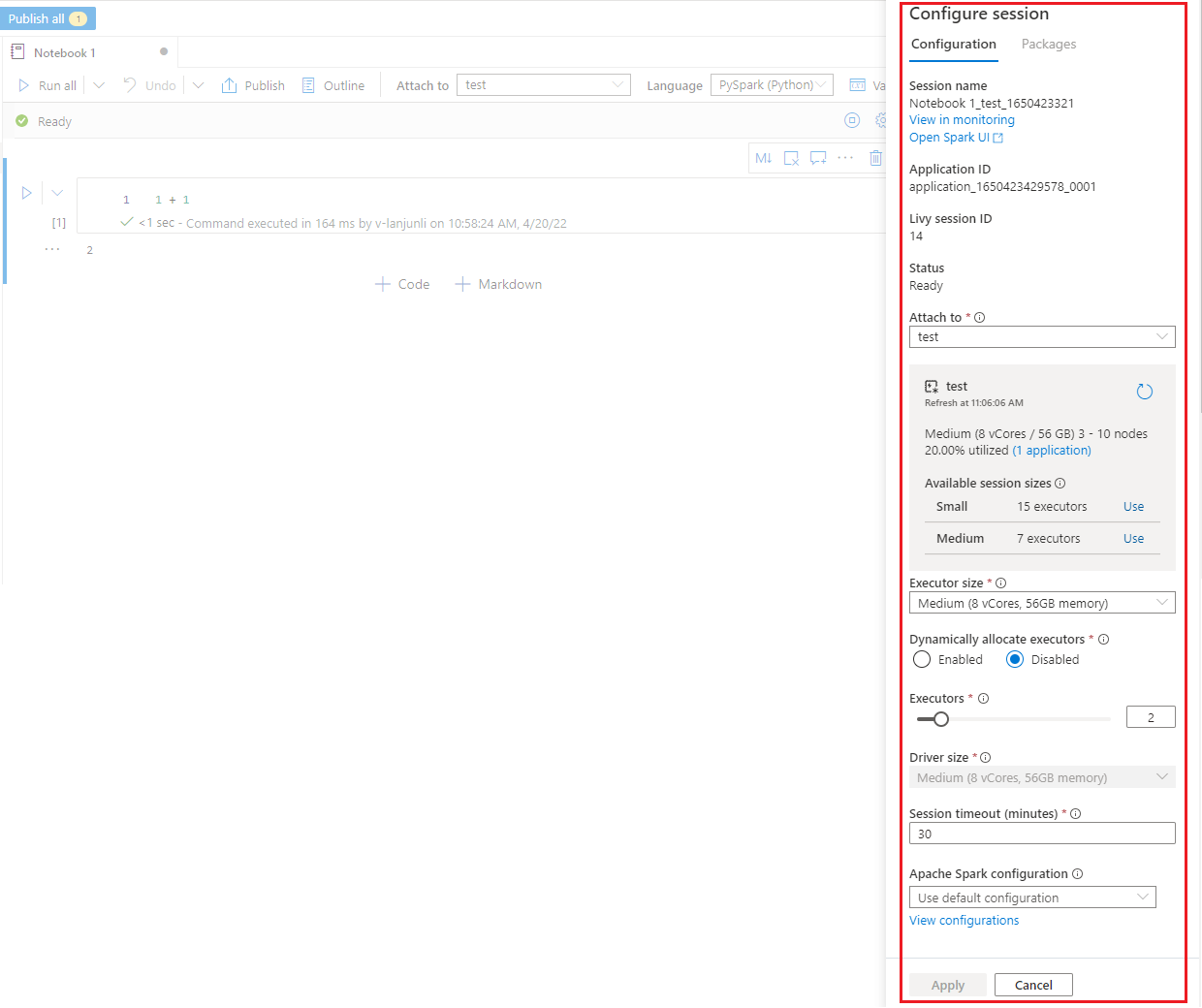
Příkaz Magic pro konfiguraci relace Sparku
Nastavení relace Sparku můžete také zadat pomocí magického příkazu %%configure. Aby se nastavení projevilo, restartujte relaci Sparku.
Doporučujeme spustit %%configure na začátku poznámkového bloku. Tady je ukázka. Úplný seznam platných parametrů najdete v informacích o Livy na GitHubu.
%%configure
{
//You can get a list of valid parameters to configure the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of a standard Spark property. To find more available properties, go to https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of a customized property. You can specify the count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Zde jsou některé úvahy o příkazu %%configure magic:
- Doporučujeme použít stejnou hodnotu pro
driverMemoryaexecutorMemoryv%%configure. Doporučujeme také, abydriverCoresmělaexecutorCoresstejnou hodnotu. - V kanálech Synapse můžete použít
%%configure, ale pokud ho nenastavíte v první buňce kódu, spuštění kanálu selže, protože relaci nejde restartovat. - Příkaz
%%configurepoužitý vmssparkutils.notebook.runse ignoruje, ale příkaz použitý v%run <notebook>se spustí. - V těle musíte použít standardní vlastnosti konfigurace Sparku
"conf". U vlastností konfigurace Spark nepodporujeme reference na první úrovni. - Některé speciální vlastnosti Sparku se neprojeví v
"conf"těle, včetně"spark.driver.cores","spark.executor.cores","spark.driver.memory","spark.executor.memory"a"spark.executor.instances".
Parametrizovaná konfigurace relace z pipeline
Pomocí parametrizované konfigurace relace můžete nahradit hodnoty v magickém příkazu %%configure parametry spuštění kanálu, které souvisejí s aktivitou poznámkového bloku. Při přípravě %%configure buňky kódu můžete výchozí hodnoty přepsat pomocí objektu, jako je tento:
{
"activityParameterName": "parameterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParameterFromPipelineNotebookActivity"
}
Následující příklad ukazuje výchozí hodnoty 4 a "2000", které jsou také konfigurovatelné:
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
Poznámkový blok používá výchozí hodnotu, pokud poznámkový blok spouštíte přímo v interaktivním režimu nebo pokud aktivita poznámkového bloku kanálu neposkytuje parametr, který odpovídá "activityParameterName".
Během režimu spuštění kanálu můžete pomocí karty Nastavení nakonfigurovat nastavení pro aktivitu poznámkového bloku kanálu.
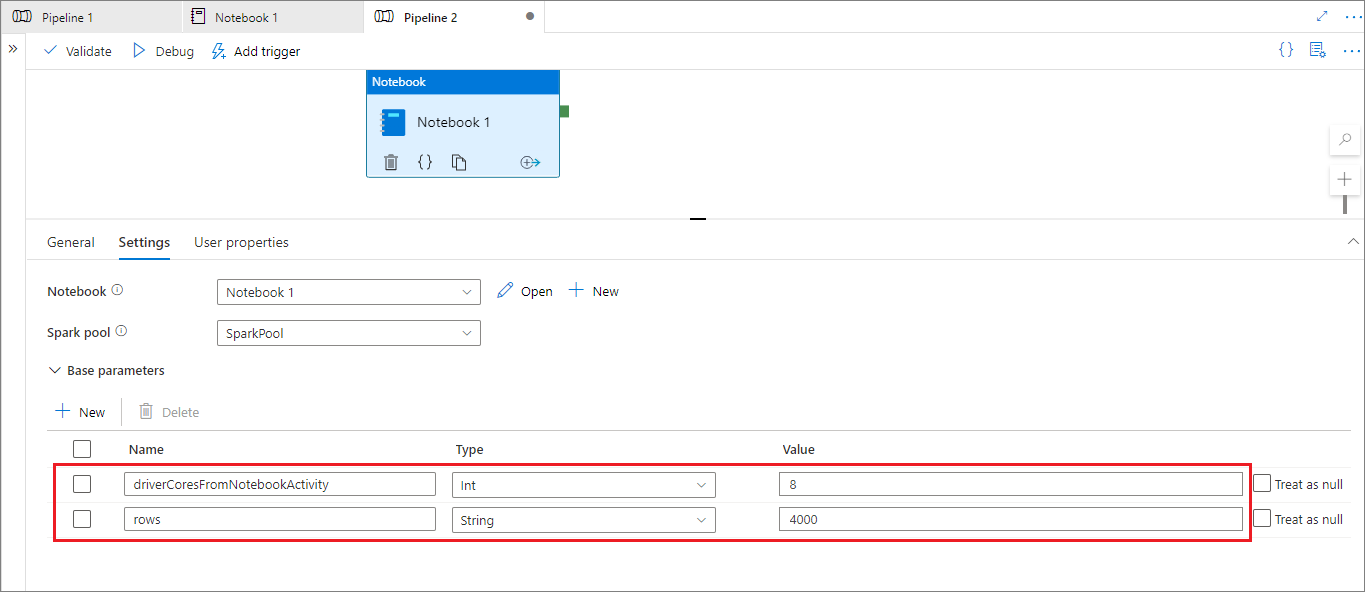
Pokud chcete změnit konfiguraci relace, název parametru aktivity poznámkového bloku datového kanálu by měl být stejný jako activityParameterName v poznámkovém bloku. V tomto příkladu během spuštění potrubí 8 nahradí driverCores v %%configure, a 4000 nahradí livy.rsc.sql.num-rows.
Pokud se spuštění kanálu po použití %%configure příkazu magic nezdaří, můžete získat další informace o chybách spuštěním %%configure buňky magic v interaktivním režimu poznámkového bloku.
Přenesení dat do poznámkového bloku
Můžete načíst data z Azure Data Lake Storage Gen2, Azure Blob Storage a fondů SQL, jak je znázorněno v následujících ukázkách kódu.
Čtení souboru CSV z Azure Data Lake Storage Gen2 jako datového rámce Spark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Čtení souboru CSV ze služby Azure Blob Storage jako datového rámce Spark
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow Spark to access from Azure Blob Storage remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Číst data z primárního úložiště
K datům v primárním účtu úložiště můžete přistupovat přímo. Tajné klíče nemusíte zadávat. V Průzkumníku dat klikněte pravým tlačítkem na soubor a vyberte Nový poznámkový blok, aby se zobrazil nový poznámkový blok s automaticky vygenerovaným extraktorem dat.
Použití widgetů IPython
Widgety jsou objekty Pythonu, které mají reprezentaci v prohlížeči, často jako ovládací prvek, jako je posuvník nebo textové pole. Widgety IPython fungují jenom v prostředích Pythonu. Aktuálně nejsou podporované v jiných jazycích (například Scala, SQL nebo C#).
Postup použití widgetů IPython
Importujte
ipywidgetsmodul pro použití architektury Jupyter Widgets:import ipywidgets as widgetsPomocí funkce nejvyšší úrovně
displaymůžete vykreslit widget nebo nechat výraz typuwidgetna posledním řádku buňky kódu:slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderSpusťte buňku. Widget se zobrazí ve výstupní oblasti.
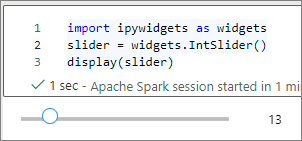
K vícenásobnému vykreslení stejné instance widgetu můžete použít více display() volání, ale vzájemně se synchronizují:
slider = widgets.IntSlider()
display(slider)
display(slider)
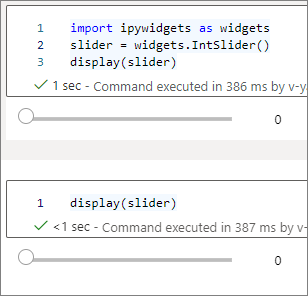
Pokud chcete vykreslit dva widgety, které jsou navzájem nezávislé, vytvořte dvě instance widgetu:
slider1 = widgets.IntSlider()
slider2 = widgets.IntSlider()
display(slider1)
display(slider2)
Podporované widgety
| Typ widgetu | Pomůcky |
|---|---|
| Numerický |
IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Logická hodnota |
ToggleButton, Checkbox, Valid |
| Výběr |
Dropdown, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, , ToggleButtonsSelectMultiple |
| Řetězec |
Text, Text area, Combobox, Password, Label, HTML, HTML Math, Image, Button |
| Přehrát (animace) |
Date picker, Color picker, Controller |
| Kontejner nebo rozložení |
Box, HBox, VBox, GridBox, Accordion, , TabsStacked |
Známá omezení
Následující tabulka uvádí widgety, které nejsou aktuálně podporované, spolu s alternativními řešeními:
Funkce Alternativní řešení OutputwidgetMísto toho můžete funkci použít k zápisu print()textu dostdout.widgets.jslink()Pomocí funkce můžete widgets.link()propojit dva podobné widgety.FileUploadwidgetNení k dispozici. Globální
displayfunkce, kterou Azure Synapse Analytics poskytuje, nepodporuje zobrazování více widgetů v jednom volání (tjdisplay(a, b). ). Toto chování se liší od funkce IPythondisplay.Pokud zavřete poznámkový blok, který obsahuje widget IPython, nemůžete widget zobrazit ani s ním pracovat, dokud znovu nespustíte odpovídající buňku.
Ukládání poznámkových bloků
Do pracovního prostoru můžete uložit jeden poznámkový blok nebo všechny poznámkové bloky:
Pokud chcete uložit změny provedené v jednom poznámkovém bloku, vyberte tlačítko Publikovat na panelu příkazů poznámkového bloku.

Pokud chcete uložit všechny poznámkové bloky v pracovním prostoru, vyberte na panelu příkazů pracovního prostoru tlačítko Publikovat vše .

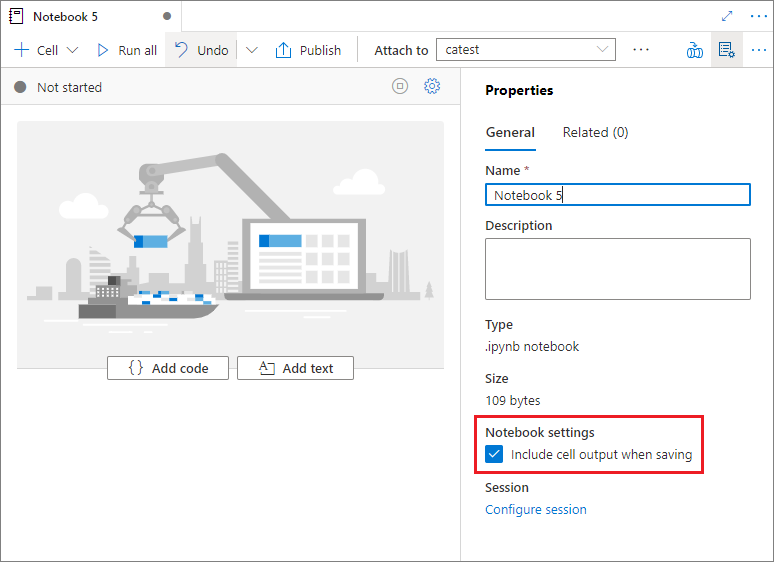
V podokně Vlastnosti poznámkového bloku můžete nakonfigurovat, jestli se má při ukládání zahrnout výstup buňky.
Použijte příkazy magic
Magické příkazy Jupyter můžete použít v poznámkových blocích Synapse. Projděte si následující seznamy aktuálně dostupných příkazů magic. Řekněte nám , jak na GitHubu používáte případy použití, abychom mohli dál vytvářet další magické příkazy, které vyhovují vašim potřebám.
Poznámka:
V pipelinách Synapse jsou podporovány pouze následující magic příkazy: %%pyspark, %%spark, %%csharp, %%sql.
Dostupné "magic" příkazy pro řádky:
%lsmagic, %time, %timeit, %history, , %run%load
Dostupné příkazy magic pro buňky:
%%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Odkaz na nepublikovaný poznámkový blok
Odkazování na nepublikovaný poznámkový blok je užitečné, když chcete ladit místně. Když tuto funkci povolíte, poznámkový blok načte aktuální obsah z webové mezipaměti. Pokud spustíte buňku, která obsahuje příkaz referenčního poznámkového bloku, budete odkazovat na prezentující poznámkové bloky v aktuálním prohlížeči poznámkového bloku místo uložené verze v clusteru. Ostatní poznámkové bloky můžou odkazovat na změny v editoru poznámkových bloků, aniž byste museli změny publikovat (dynamický režim) nebo potvrdit (režim Git). Pomocí tohoto přístupu můžete zabránit znečištění běžných knihoven během vývoje nebo ladění procesu.
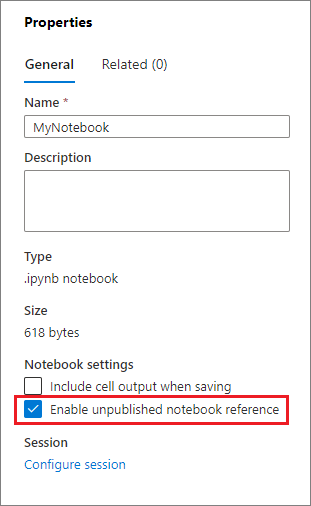
Odkazování na nepublikovaný poznámkový blok můžete povolit zaškrtnutím příslušného políčka v podokně Vlastnosti .
Následující tabulka porovnává případy. I když %run a mssparkutils.notebook.run mají stejné chování, tabulka používá %run jako příklad.
| Případ | Zakázat | Povolit |
|---|---|---|
| Živý režim | ||
Nb1 (publikováno) %run Nb1 |
Spustit publikovanou verzi Nb1 | Spustit publikovanou verzi Nb1 |
Nb1 (nový) %run Nb1 |
Chyba | Spuštění nového Nb1 |
Nb1 (dříve publikováno, upraveno) %run Nb1 |
Spustit publikovanou verzi Nb1 | Spustit upravenou verzi Nb1 |
| Režim Git | ||
Nb1 (publikováno) %run Nb1 |
Spustit publikovanou verzi Nb1 | Spustit publikovanou verzi Nb1 |
Nb1 (nový) %run Nb1 |
Chyba | spuštění nového Nb1 |
Nb1 (není publikováno, zavázáno) %run Nb1 |
Chyba | Spuštění potvrzené Nb1 |
Nb1 (dříve publikováno, potvrzeno) %run Nb1 |
Spustit publikovanou verzi Nb1 | Spuštění potvrzené verze Nb1 |
Nb1 (dříve publikováno, nové v této větvi) %run Nb1 |
Spustit publikovanou verzi Nb1 | Spusť nový Nb1 |
Nb1 (nepublikováno, dříve potvrzeno, upraveno) %run Nb1 |
Chyba | Spustit upravenou verzi Nb1 |
Nb1 (dříve publikováno a potvrzeno, upraveno) %run Nb1 |
Spustit publikovanou verzi Nb1 | Spustit upravenou verzi Nb1 |
Souhrnně:
- Pokud zakážete odkazování na nepublikovaný poznámkový blok, vždy spusťte publikovanou verzi.
- Pokud povolíte odkazování na nepublikovaný poznámkový blok, referenční spuštění vždy přijme aktuální verzi poznámkového bloku, která se zobrazí v uživatelském rozhraní poznámkového bloku.
Správa aktivních relací
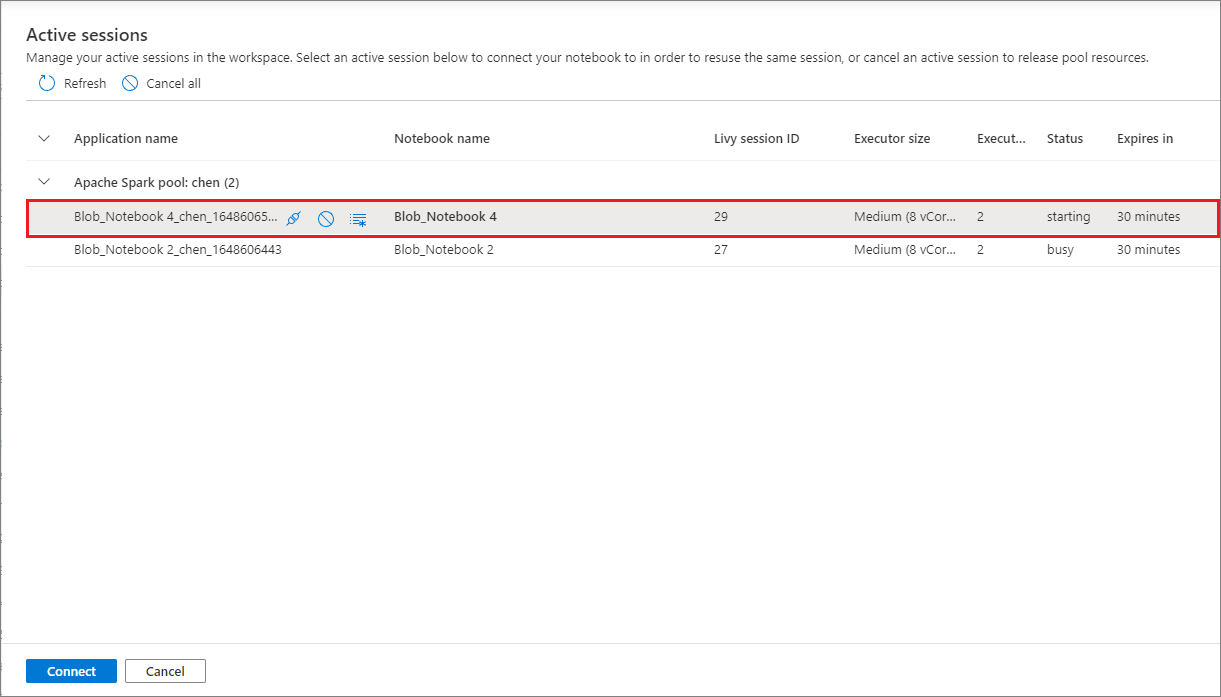
Relace poznámkového bloku můžete opakovaně používat, aniž byste museli spouštět nové relace. V poznámkových blocích Synapse můžete aktivní relace spravovat v jednom seznamu. Seznam otevřete tak, že vyberete tři tečky (...) a pak vyberete Spravovat relace.
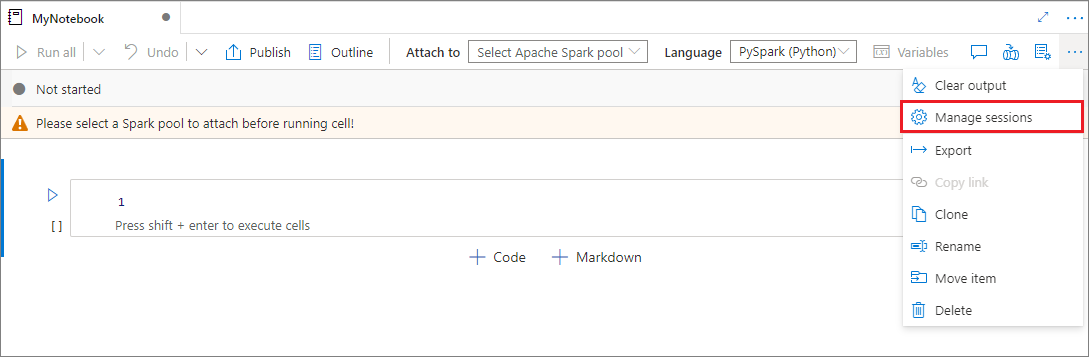
Podokno Aktivní relace obsahuje seznam všech relací v aktuálním pracovním prostoru, který jste začali z poznámkového bloku. V seznamu se zobrazí informace o relaci a odpovídající poznámkové bloky. Tady jsou k dispozici akce Odpojení s poznámkovým blokem, Zastavit relaci a Zobrazit v monitorování. Můžete také připojit vybraný poznámkový blok k aktivní relaci, která začala z jiného poznámkového bloku. Sezení se pak odpojí od předchozího poznámkového bloku (pokud není nečinné) a připojí se k aktuálnímu poznámkovému bloku.
Použití protokolů Pythonu v poznámkovém bloku
Protokoly Pythonu a nastavení různých úrovní protokolů a formátů můžete najít pomocí následujícího ukázkového kódu:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize the log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# Logger that uses the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# Logger that uses the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Zobrazení historie vstupních příkazů
Poznámkové bloky Synapse podporují magický příkaz %history k tisku historie příkazů pro aktuální relaci. Příkaz %history magic je podobný standardnímu příkazu IPyter IPython a funguje pro více kontextů jazyka v poznámkovém bloku.
%history [-n] [range [range ...]]
V předchozím kódu -n je číslo spuštění tisku. Hodnota range může být:
-
N: Vytiskněte kódNthspuštěné buňky. -
M-N: Vytiskněte kód z buňkyMthdo buňkyNth, která byla vykonána.
Chcete-li například vytisknout historii vstupu z první do druhé spuštěné buňky, použijte %history -n 1-2.
Integrace poznámkového bloku
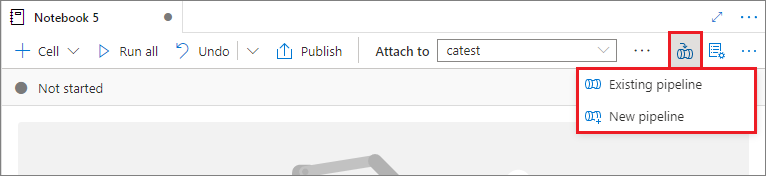
Přidání poznámkového bloku do kanálu
Pokud chcete přidat poznámkový blok do existujícího kanálu nebo vytvořit nový kanál, vyberte tlačítko Přidat do kanálu v pravém horním rohu.
Určení buňky parametru
Pokud chcete parametrizovat poznámkový blok, vyberte tři tečky (...) a získejte přístup k dalším příkazům na panelu nástrojů buňky. Potom vyberte Přepnout buňku parametru a označte ji jako buňku parametru.
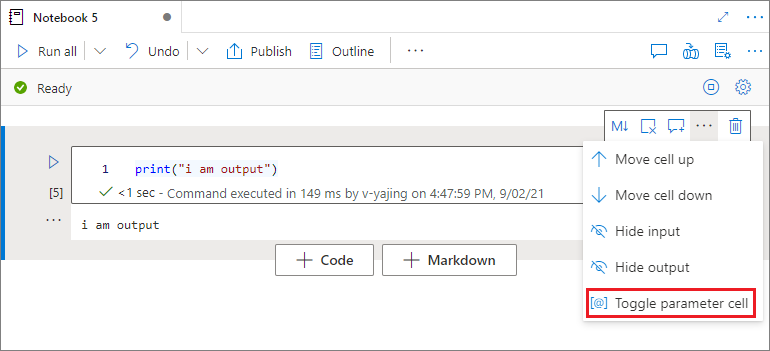
Azure Data Factory vyhledá buňku parametru a považuje tuto buňku za výchozí pro parametry předávané v době provádění. Prováděcí modul přidá novou buňku pod buňku parametru se vstupními parametry pro přepsání výchozích hodnot.
Přiřazení hodnot parametrů z kanálu
Po vytvoření poznámkového bloku s parametry ho můžete spustit pomocí aktivity poznámkového bloku Synapse v rámci datového pipeline. Po přidání aktivity na plátno potrubí můžete v části Základní parametry na kartě Nastavení nastavit hodnoty parametrů.
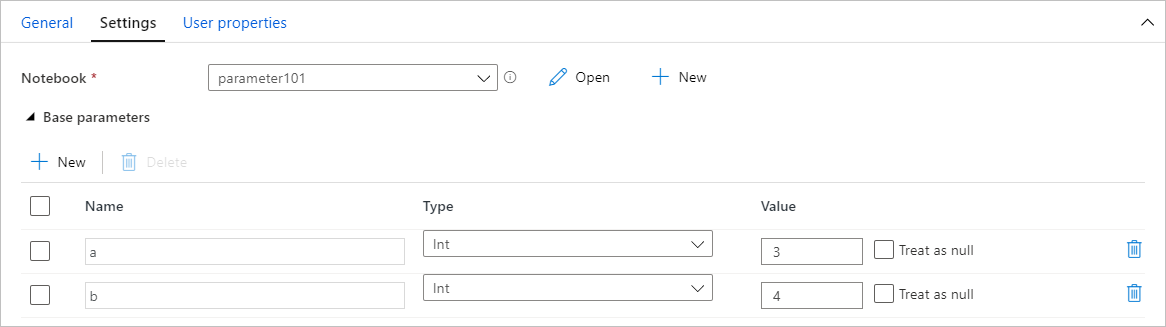
Při přiřazování hodnot parametrů můžete použít jazyk výrazu kanálu nebo systémové proměnné.
Použití klávesových zkratek
Podobně jako notebooky Jupyter mají notebooky Synapse modální uživatelské rozhraní. Klávesnice provádí různé věci v závislosti na tom, ve kterém režimu je buňka poznámkového bloku. Poznámkové bloky Synapse podporují následující dva režimy buňky kódu:
Příkazový režim: Buňka je v příkazovém režimu, když není zobrazen kurzor textu vyzývající k psaní. Pokud je buňka v režimu příkazů, můžete poznámkový blok upravit jako celek, ale ne psát do jednotlivých buněk. Stisknutím klávesy Esc nebo pomocí myši vyberte mimo oblast editoru buňky režim příkazu.

Režim úprav: Když je buňka v režimu úprav, kurzor vás vyzývá k psaní do buňky. Pro vstup do režimu úprav stiskněte klávesu Enter nebo použijte myš k výběru oblasti editoru buňky.

Klávesové zkratky v režimu příkazů
| Akce | Zástupce poznámkového bloku Synapse |
|---|---|
| Spusťte aktuální buňku a poté vyberte níže. | Shift + Enter |
| Spusťte aktuální buňku a vložte novou buňku níže. | Alt+Enter |
| Spuštění aktuální buňky | Ctrl+Enter |
| Vyberte buňku nad | Nahoru |
| Vyberte buňku níže. | Dolů |
| Výběr předchozí buňky | K |
| Vybrat další buňku | J |
| Vložit buňku nad | A |
| Vložit buňku pod | B |
| Odstranění vybraných buněk | Shift+D |
| Přepnout do režimu úprav | Vstoupit |
Klávesové zkratky v režimu úprav
| Akce | Zástupce poznámkového bloku Synapse |
|---|---|
| Přesunutí kurzoru nahoru | Nahoru |
| Přesunutí kurzoru dolů | Dolů |
| Zpět | CTRL+Z |
| Opakovat | Ctrl+Y |
| Komentář/zrušení komentáře | Ctrl+/ |
| Odstranit slovo před | Ctrl+Backspace |
| Odstranit slovo po | Ctrl+Delete |
| Přechod na začátek buňky | CTRL+HOME |
| Přejít na konec buňky | CTRL+END |
| Přejít o jedno slovo doleva | Ctrl+Vlevo |
| Přejít o jedno slovo doprava | Ctrl+šipka vpravo |
| Vybrat vše | CTRL+A |
| Odsazení | CTRL+] |
| Dedent | CTRL+[ |
| Přepnout do režimu příkazů | Esc |
Související obsah
- Ukázkové poznámkové bloky Synapse
- Rychlý start: Vytvoření fondu Apache Spark ve službě Azure Synapse Analytics pomocí webových nástrojů
- Co je Apache Spark ve službě Azure Synapse Analytics?
- Použití .NET pro Apache Spark se službou Azure Synapse Analytics
- Dokumentace k .NET pro Apache Spark
- Dokumentace Azure Synapse Analytics