Serverless compute tier for Azure SQL Database
Applies to: ![]() Azure SQL Database
Azure SQL Database
Serverless is a compute tier for single databases in Azure SQL Database that automatically scales compute based on workload demand and bills for the amount of compute used per second. The serverless compute tier also automatically pauses databases during inactive periods when only storage is billed and automatically resumes databases when activity returns. The serverless compute tier is available in the General Purpose service tier and the Hyperscale service tier.
Note
Auto-pausing and auto-resuming is currently only supported in the General Purpose service tier.
Overview
A compute autoscaling range and an auto-pause delay are important parameters for the serverless compute tier. The configuration of these parameters shapes the database performance experience and compute cost.
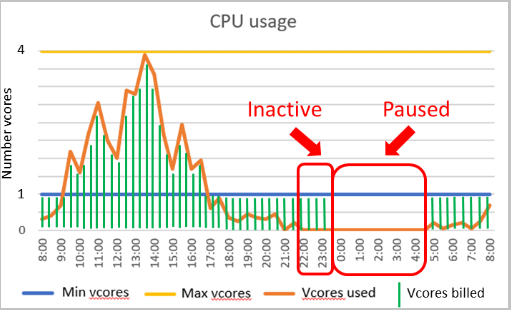
Performance configuration
- The minimum vCores and maximum vCores are configurable parameters that define the range of compute capacity available for the database. Memory and IO limits are proportional to the vCore range specified.
- The auto-pause delay is a configurable parameter that defines the period of time the database must be inactive before it is automatically paused. The database is automatically resumed when the next sign in or other activity occurs. Alternatively, automatic pausing can be disabled.
Cost
- The cost for a serverless database is the summation of the compute cost and storage cost.
- When compute usage is between the minimum and maximum limits configured, the compute cost is based on vCore and memory used.
- When compute usage is below the minimum limits configured, the compute cost is based on the minimum vCores and minimum memory configured.
- When the database is paused, the compute cost is zero and only storage costs are incurred.
- The storage cost is determined in the same way as in the provisioned compute tier.
For more cost details, see Billing.
Scenarios
Serverless is price-performance optimized for single databases with intermittent, unpredictable usage patterns that can afford some delay in compute warm-up after idle usage periods. In contrast, the provisioned compute tier is price-performance optimized for single databases or multiple databases in elastic pools with higher average usage that cannot afford any delay in compute warm-up.
Scenarios well suited for serverless compute
- Single databases with intermittent, unpredictable usage patterns interspersed with periods of inactivity, and lower average compute utilization over time.
- Single databases in the provisioned compute tier that are frequently rescaled and customers who prefer to delegate compute rescaling to the service.
- New single databases without usage history where compute sizing is difficult or not possible to estimate before deployment in an Azure SQL Database.
Scenarios well suited for provisioned compute
- Single databases with more regular, predictable usage patterns and higher average compute utilization over time.
- Databases that cannot tolerate performance trade-offs resulting from more frequent memory trimming or delays in resuming from a paused state.
- Multiple databases with intermittent, unpredictable usage patterns that can be consolidated into elastic pools for better price-performance optimization.
Compare compute tiers
The following table summarizes distinctions between the serverless compute tier and the provisioned compute tier:
| Serverless compute | Provisioned compute | |
|---|---|---|
| Database usage pattern | Intermittent, unpredictable usage with lower average compute utilization over time. | More regular usage patterns with higher average compute utilization over time, or multiple databases using elastic pools. |
| Performance management effort | Lower | Higher |
| Compute scaling | Automatic | Manual |
| Compute responsiveness | Lower after inactive periods | Immediate |
| Billing granularity | Per second | Per hour |
Purchasing model and service tier
The following table describes serverless support based on purchasing model, service tiers, and hardware:
| Category | Supported | Not supported |
|---|---|---|
| Purchasing model | vCore | DTU |
| Service tier | General Purpose Hyperscale |
Business Critical |
| Hardware | Standard-series (Gen5) | All other hardware |
Autoscaling
Scaling responsiveness
Serverless databases are run on a machine with sufficient capacity to satisfy resource demand without interruption for any amount of compute requested, within limits set by the maximum vCores value. Occasionally, load balancing automatically occurs if the machine is unable to satisfy resource demand within a few minutes. For example, if the resource demand is 4 vCores, but only 2 vCores are available, then it can take up to a few minutes to load balance before 4 vCores are provided. The database remains online during load balancing except for a brief period at the end of the operation when connections are dropped.
Memory management
In both the General Purpose and Hyperscale service tiers, memory for serverless databases is reclaimed more frequently than for provisioned compute databases. This behavior is important to control costs in serverless and can impact performance.
Cache reclamation
Unlike provisioned compute databases, memory from the SQL cache is reclaimed from a serverless database when CPU or active cache utilization is low.
- Active cache utilization is considered low when the total size of the most recently used cache entries falls below a threshold, for a period of time.
- When cache reclamation is triggered, the target cache size is reduced incrementally to a fraction of its previous size and reclaiming only continues if usage remains low.
- When cache reclamation occurs, the policy for selecting cache entries to evict is the same selection policy as for provisioned compute databases when memory pressure is high.
- The cache size is never reduced below the minimum memory limit as defined by minimum vCores.
In both serverless and provisioned compute databases, cache entries can be evicted if all available memory is used.
When CPU utilization is low, active cache utilization can remain high depending on the usage pattern and prevent memory reclamation. Also, there can be other delays after user activity stops before memory reclamation occurs due to periodic background processes responding to prior user activity. For example, delete operations and Query Store cleanup tasks generate ghost records that are marked for deletion, but are not physically deleted until the ghost cleanup process runs. Ghost cleanup might involve reading data pages into cache.
Cache hydration
The SQL memory cache grows as data is fetched from disk in the same way and with the same speed as for provisioned databases. When the database is busy, the cache is allowed to grow unconstrained while there is available memory.
Disk cache management
In the Hyperscale service tier for both serverless and provisioned compute tiers, each compute replica uses a Resilient Buffer Pool Extension (RBPEX) cache, which stores data pages on local SSD to improve IO performance. However, in the serverless compute tier for Hyperscale, the RBPEX cache for each compute replica automatically grows and shrinks in response to increasing and decreasing workload demand. The maximum size the RBPEX cache can grow to is three times the maximum memory configured for the database. For details on maximum memory and RBPEX auto-scaling limits in serverless, see serverless Hyperscale resource limits.
Auto-pause and auto-resume
Currently, serverless auto-pausing and auto-resuming are only supported in the General Purpose tier.
Auto-pause
Auto-pausing is triggered if all of the following conditions are true during the auto-pause delay:
- Number of sessions = 0
- CPU = 0 for user workload running in the user resource pool
An option is provided to disable auto-pausing if desired.
The following features do not support auto-pausing, but do support auto-scaling. If any of the following features are used, then auto-pausing must be disabled and the database remains online regardless of the duration of database inactivity:
- Geo-replication (active geo-replication and failover groups).
- Long-term backup retention (LTR).
- The sync database used in SQL Data Sync. Unlike sync databases, hub and member databases support auto-pausing.
- DNS alias created for the logical server containing a serverless database.
- Elastic Jobs, Auto-pause enabled serverless database is not supported as a Job Database. Serverless databases targeted by elastic jobs do support auto-pausing. Job connections will resume a database.
Auto-pausing is temporarily prevented during the deployment of some service updates, which require the database be online. In such cases, auto-pausing becomes allowed again once the service update completes.
Auto-pause troubleshooting
If auto-pausing is enabled and features that block auto-pausing are not used, but a database does not auto-pause after the delay period, then application or user sessions might be preventing auto-pausing.
To see if there are any application or user sessions currently connected to the database, connect to the database using any client tool, and execute the following query:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Tip
After running the query, make sure to disconnect from the database. Otherwise, the open session used by the query will prevent auto-pausing.
- If the result set is nonempty, it indicates that there are sessions currently preventing auto-pausing.
- If the result set is empty, it is still possible that sessions were open, possibly for a short time, at some point earlier during the auto-pause delay period. To check for activity during the delay period, you can use Auditing for Azure SQL Database and Azure Synapse Analytics and examine audit data for the relevant period.
Important
The presence of open sessions, with or without concurrent CPU utilization in the user resource pool, is the most common reason for a serverless database to not auto-pause as expected.
Auto-resume
Auto-resuming is triggered if any of the following conditions are true at any time:
| Feature | Auto-resume trigger |
|---|---|
| Authentication and authorization | Login |
| Threat detection | Enabling/disabling threat detection settings at the database or server level. Modifying threat detection settings at the database or server level. |
| Data discovery and classification | Adding, modifying, deleting, or viewing sensitivity labels |
| Auditing | Viewing auditing records. Updating or viewing auditing policy. |
| Data masking | Adding, modifying, deleting, or viewing data masking rules |
| Transparent data encryption | Viewing state or status of transparent data encryption |
| Vulnerability assessment | Ad hoc scans and periodic scans if enabled |
| Query (performance) data store | Modifying or viewing Query Store settings |
| Performance recommendations | Viewing or applying performance recommendations |
| Auto-tuning | Application and verification of auto-tuning recommendations such as auto-indexing |
| Database copying | Create database as copy. Export to a BACPAC file. |
| SQL data sync | Synchronization between hub and member databases that run on a configurable schedule or are performed manually |
| Modifying certain database metadata | Adding new database tags. Changing maximum vCores, minimum vCores, or auto-pause delay. |
| SQL Server Management Studio (SSMS) | When using SSMS versions earlier than 18.1 and opening a new query window for any database in the server, any auto-paused database in the same server is resumed. This behavior does not occur if using SSMS version 18.1 or later. |
Monitoring, management, or other solutions performing any of these operations trigger auto-resuming. Auto-resuming is also triggered during the deployment of some service updates that require the database be online.
Connectivity
If a serverless database is paused, the first connection attempt resumes the database and returns an error stating that the database is unavailable with error code 40613. Once the database is resumed, the login can be retried to establish connectivity. Database clients following connection retry logic recommendations should not need to be modified. For connection retry logic options and recommendations, see:
- Connection retry logic in SqlClient
- Connection retry logic in SQL Database using Entity Framework Core
- Connection retry logic in SQL Database using Entity Framework 6
- Connection retry logic in SQL Database using ADO.NET
Latency
The latency to auto-resume and auto-pause a serverless database is generally order of 1 minute to auto-resume and 1-10 minutes after the expiration of the delay period to auto-pause.
Customer managed transparent data encryption (BYOK)
Key deletion or revocation
If using customer managed transparent data encryption (BYOK) and the serverless database is auto-paused when key deletion or revocation occurs, then the database remains in the auto-paused state. In this case, after the database is next resumed, the database becomes inaccessible within approximately 10 minutes. Once the database becomes inaccessible, the recovery process is the same as for provisioned compute databases. If the serverless database is online when key deletion or revocation occurs, then the database also becomes inaccessible within approximately 10 minutes in the same way as with provisioned compute databases.
Key rotation
If using customer-managed transparent data encryption (BYOK), and serverless auto-pausing is enabled, the database is auto-resumed whenever keys are rotated. The database will then be auto-paused when auto-pausing conditions are satisfied.
Create a new serverless database
Creating a new database or moving an existing database into a serverless compute tier follows the same pattern as creating a new database in provisioned compute tier and involves the following two steps:
Specify the service objective. The service objective prescribes the service tier, hardware configuration, and maximum vCores. For service objective options, see serverless resource limits
Optionally, specify the minimum vCores and auto-pause delay to change their default values. The following table shows the available values for these parameters.
Parameter Value choices Default value Minimum vCores Depends on maximum vCores configured - see resource limits. 0.5 vCores Auto-pause delay Minimum: 15 minutes
Maximum: 10,080 minutes (seven days)
Increments: 1 minute
Disable auto-pause: -160 minutes
The following examples create a new database in the serverless compute tier.
Use Azure portal
See Quickstart: Create a single database in Azure SQL Database using the Azure portal.
Use PowerShell
Create a new serverless General Purpose database with the following PowerShell example:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Use Azure CLI
Create a new serverless General Purpose database with the following Azure CLI example:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Use Transact-SQL (T-SQL)
When using T-SQL to create a new serverless database, default values are applied for the minimum vCores and auto-pause delay. Their values can later be changed from the Azure portal or via API including PowerShell, Azure CLI, and REST.
For details, see CREATE DATABASE.
Create a new General Purpose serverless database with the following T-SQL example:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Move a database between compute tiers or service tiers
A database can be moved between the provisioned compute tier and serverless compute tier.
A serverless database can also be moved from the General Purpose service tier to the Hyperscale service tier. Review Manage Hyperscale databases to learn more.
When moving a database between compute tiers, specify the compute model parameter as either Serverless or Provisioned when using PowerShell or Azure CLI, or the SERVICE_OBJECTIVE when using T-SQL. Review resource limits to identify the appropriate service objective.
The following examples move an existing database from provisioned compute to serverless.
Use PowerShell
Move a provisioned compute General Purpose database to the serverless compute tier with the following PowerShell example:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Use Azure CLI
Move a provisioned compute General Purpose database to the serverless compute tier with the following Azure CLI example:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Use Transact-SQL (T-SQL)
When using T-SQL to move a database between compute tiers, default values are applied for the minimum vCores and auto-pause delay. Their values can subsequently be changed from the Azure portal or via API including PowerShell, Azure CLI, and REST. For more information, see ALTER DATABASE.
Move a provisioned compute General Purpose database to the serverless compute tier with the following T-SQL example:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Modify serverless configuration
Use PowerShell
Use Set-AzSqlDatabase to modify the maximum or minimum vCores, and auto-pause delay. Use the MaxVcore, MinVcore, and AutoPauseDelayInMinutes arguments. Serverless auto-pausing is not currently supported in the Hyperscale tier, so the auto-pause delay argument is only applicable to the General Purpose tier.
Use Azure CLI
Use az sql db update to modify the maximum or minimum vCores, and auto-pause delay. Use the capacity, min-capacity, and auto-pause-delay arguments. Serverless auto-pausing is not currently supported in the Hyperscale tier, so the auto-pause delay argument is only applicable to the General Purpose tier.
Monitor
Resources used and billed
The resources of a serverless database include the app package, SQL instance, and user resource pool entities.
App package
The app package is the outer most resource management boundary for a database, regardless of whether the database is in a serverless or provisioned compute tier. The app package contains the SQL instance and external services like Full-text Search that all together scope all user and system resources used by a database in SQL Database. The SQL instance generally dominates the overall resource utilization across the app package.
User resource pool
The user resource pool is an inner resource management boundary for a database, regardless of whether the database is in a serverless or provisioned compute tier. The user resource pool scopes CPU and IO for user workload generated by DDL (CREATE and ALTER) and DML (INSERT, UPDATE, DELETE, and MERGE, and SELECT) queries. These queries generally represent the most substantial proportion of utilization within the app package.
Metrics
The following table includes metrics for monitoring the resource usage of the app package and user resource pool of a serverless database, including any geo-replicas:
| Entity | Metric | Description | Units |
|---|---|---|---|
| App package | app_cpu_percent | Percentage of vCores used by the app relative to maximum vCores allowed for the app. For serverless Hyperscale, this metric is exposed for all primary replicas, named replicas, and geo-replicas. | Percentage |
| App package | app_cpu_billed | The amount of compute billed for the app during the reporting period. The amount paid during this period is the product of this metric and the vCore unit price. Values of this metric are determined by aggregating the maximum of CPU used and memory used each second. If the amount used is less than the minimum amount provisioned as set by the minimum vCores and minimum memory, then the minimum amount provisioned is billed. In order to compare CPU with memory for billing purposes, memory is normalized into units of vCores by rescaling the amount of memory in GB by 3 GB per vCore. For serverless Hyperscale, this metric is exposed for the primary replica and any named replicas. |
vCore seconds |
| App package | app_cpu_billed_HA_replicas | Only applicable to serverless Hyperscale. Sum of the compute billed across all apps for HA replicas during the reporting period. This sum is scoped either to the HA replicas belonging to the primary replica or the HA replicas belonging to a given named replica. Before calculating this sum across HA replicas, the amount of compute billed for an individual HA replica is determined in the same way as for the primary replica or a named replica. For serverless Hyperscale, this metric is exposed for all primary replicas, named replicas, and geo-replicas. The amount paid during the reporting period is the product of this metric and the vCore unit price. | vCore seconds |
| App package | app_memory_percent | Percentage of memory used by the app relative to maximum memory allowed for the app. For serverless Hyperscale, this metric is exposed for all primary replicas, named replicas, and geo-replicas. | Percentage |
| User resource pool | cpu_percent | Percentage of vCores used by user workload relative to maximum vCores allowed for user workload. | Percentage |
| User resource pool | data_IO_percent | Percentage of data IOPS used by user workload relative to maximum data IOPS allowed for user workload. | Percentage |
| User resource pool | log_IO_percent | Percentage of log MB/s used by user workload relative to maximum log MB/s allowed for user workload. | Percentage |
| User resource pool | workers_percent | Percentage of workers used by user workload relative to maximum workers allowed for user workload. | Percentage |
| User resource pool | sessions_percent | Percentage of sessions used by user workload relative to maximum sessions allowed for user workload. | Percentage |
Pause and resume status
In the case of a serverless database with auto-pausing enabled, the status it reports includes the following values:
| Status | Description |
|---|---|
| Online | The database is online. |
| Pausing | The database is transitioning from online to paused. |
| Paused | The database is paused. |
| Resuming | The database is transitioning from paused to online. |
Use Azure portal
In the Azure portal, the database status is displayed in the overview page of the database and in the overview page of its server. Also in the Azure portal, the history of pause and resume events of a serverless database can be viewed in the Activity log.
Use PowerShell
View the current database status using the following PowerShell example:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Use Azure CLI
View the current database status using the following Azure CLI example:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Resource limits
For resource limits, see serverless compute tier.
Billing
The amount of compute billed for a serverless database is the maximum of CPU used and memory used each second. If the amount of CPU and memory used is less than the minimum amount provisioned for each resource, then the provisioned amount is billed. In order to compare CPU with memory for billing purposes, memory is normalized into units of vCores by rescaling the number of GB by 3 GB per vCore.
- Resource billed: CPU and memory
- Amount billed: vCore unit price * maximum (minimum vCores, vCores used, minimum memory GB * 1/3, memory GB used * 1/3)
- Billing frequency: Per second
The vCore unit price is the cost per vCore per second.
Refer to the Azure SQL Database pricing page for specific unit prices in a given region.
The amount of compute billed in serverless for a General Purpose database, or a Hyperscale primary or named replica is exposed by the following metric:
- Metric: app_cpu_billed (vCore seconds)
- Definition: maximum (minimum vCores, vCores used, minimum memory GB * 1/3, memory GB used * 1/3)
- Reporting frequency: Per minute based on per second measurements aggregated over 1 minute.
The amount of compute billed in serverless for Hyperscale HA replicas belonging to the primary replica or any named replica is exposed by the following metric:
- Metric: app_cpu_billed_HA_replicas (vCore seconds)
- Definition: Sum of maximum (minimum vCores, vCores used, minimum memory GB * 1/3, memory GB used * 1/3) for any HA replicas belonging to their parent resource.
- Parent resource and metric endpoint: The primary replica and any named replica each separately expose this metric, which measures the compute billed for any associated HA replicas.
- Reporting frequency: Per minute based on per second measurements aggregated over 1 minute.
Minimum compute bill
If a serverless database is paused, then the compute bill is zero. If a serverless database is not paused, then the minimum compute bill is no less than the amount of vCores based on maximum (minimum vCores, minimum memory GB * 1/3).
Examples:
- Suppose a serverless database in the General Purpose tier is not paused and configured with 8 maximum vCores and 1 minimum vCore corresponding to 3.0 GB minimum memory. Then the minimum compute bill is based on maximum (1 vCore, 3.0 GB * 1 vCore / 3 GB) = 1 vCore.
- Suppose a serverless database in the General Purpose tier is not paused and configured with 4 maximum vCores and 0.5 minimum vCores corresponding to 2.1 GB minimum memory. Then the minimum compute bill is based on maximum (0.5 vCores, 2.1 GB * 1 vCore / 3 GB) = 0.7 vCores.
- Suppose a serverless database in the Hyperscale tier has a primary replica with one HA replica and one named replica with no HA replicas. Suppose each replica is configured with 8 maximum vCores and 1 minimum vCore corresponding to 3 GB minimum memory. Then the minimum compute bill for the primary replica, HA replica, and named replica are each based on maximum (1 vCore, 3 GB * 1 vCore / 3 GB) = 1 vCore.
The Azure SQL Database pricing calculator for serverless can be used to determine the minimum memory configurable based on the number of maximum and minimum vCores configured. As a rule, if the minimum vCores configured is greater than 0.5 vCores, then the minimum compute bill is independent of the minimum memory configured and based only on the number of minimum vCores configured.
Scenario examples
Consider a serverless database in the General Purpose tier configured with 1 minimum vCore and 4 maximum vCores. This configuration corresponds to around 3 GB minimum memory and 12 GB maximum memory. Suppose the auto-pause delay is set to 6 hours and the database workload is active during the first 2 hours of a 24-hour period and otherwise inactive.
In this case, the database is billed for compute and storage during the first 8 hours. Even though the database is inactive starting after the second hour, it is still billed for compute in the subsequent 6 hours based on the minimum compute provisioned while the database is online. Only storage is billed during the remainder of the 24-hour period while the database is paused.
More precisely, the compute bill in this example is calculated as follows:
| Time Interval | vCores used each second | GB used each second | Compute dimension billed | vCore seconds billed over time interval |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | vCores used | 4 vCores * 3,600 seconds = 14,400 vCore seconds |
| 1:00-2:00 | 1 | 12 | Memory used | 12 GB * 1/3 * 3,600 seconds = 14,400 vCore seconds |
| 2:00-8:00 | 0 | 0 | Minimum memory provisioned | 3 GB * 1/3 * 21,600 seconds = 21,600 vCore seconds |
| 8:00-24:00 | 0 | 0 | No compute billed while paused | 0 vCore seconds |
| Total vCore seconds billed over 24 hours | 50,400 vCore seconds |
Suppose the compute unit price is $0.000145/vCore/second. Then the compute billed for this 24-hour period is the product of the compute unit price and vCore seconds billed: $0.000145/vCore/second * 50,400 vCore seconds ~ $7.31.
Azure Hybrid Benefit and reserved capacity
Azure Hybrid Benefit (AHB) and reserved capacity discounts do not apply to the serverless compute tier.
Available regions
Serverless for General Purpose and Hyperscale tiers with support up to 40 maximum vCores is available worldwide except the following regions:
- China East
- China North
- Germany Central
- Germany Northeast
- US Gov Central (Iowa)
Regions supporting 80 maximum vCores without availability zones for General Purpose and Hyperscale
Currently, 80 maximum vCores in serverless for General Purpose and Hyperscale tiers is currently supported in the following regions:
- Australia Central 1
- Australia Central 2
- Australia East
- Australia Southeast
- Brazil South
- Brazil Southeast
- Canada Central
- Canada East
- Central US
- China East 2
- China East 3
- China North 2
- China North 3
- East Asia
- East US
- East US 2
- France Central
- France South
- Germany North
- Germany West Central
- India Central
- India South
- Israel Central
- Italy North
- Japan East
- Japan West
- Jio India Central
- Jio India West
- Korea Central
- Korea South
- Malaysia South
- Mexico Central
- North Central US
- North Europe
- Norway East
- Norway West
- Poland Central
- Qatar Central
- South Africa North
- South Africa West
- South Central US
- Southeast Asia
- Spain Central
- Sweden Central
- Sweden South
- Switzerland North
- Switzerland West
- Taiwan North
- Taiwan Northwest
- UAE Central
- UAE North
- UK South
- UK West
- US Gov East
- US Gov South central
- US Gov Southwest
- West Europe
- West Central US
- West US
- West US 2
- West US 3
Regions supporting 80 maximum vCores with availability zones for General Purpose and Hyperscale
Currently, 80 maximum vCores with availability zone support in serverless for the General Purpose and Hyperscale tiers is provided in the following regions with more regions planned:
- Australia East
- Brazil South
- Canada Central
- Central US
- East Asia
- East US
- East US 2
- France Central
- Germany West Central
- India Central
- Japan East
- Korea Central
- North Europe
- South Africa North
- South Central US
- Southeast Asia
- Sweden Central
- UAE North
- UK South
- US Gov East
- West Europe
- West US 2
- West US 3
Related content
- To get started, see Quickstart: Create a single database - Azure SQL Database.
- For serverless service tier choices, see General Purpose and Hyperscale.