Create an index in Azure AI Search
In this article, learn the steps for defining a schema for a search index and pushing it to a search service. Creating an index establishes the physical data structures on your search service. Once the index exists, load the index as a separate task.
Prerequisites
Write permissions as a Search Service Contributor or an admin API key for key-based authentication.
An understanding of the data you want to index. A search index is based on external content that you want to make searchable. Searchable content is stored as fields in an index. You should have a clear idea of which source fields you want to make searchable, retrievable, filterable, facetable, and sortable on Azure AI Search. See the schema checklist for guidance.
You must also have a unique field in source data that can be used as the document key (or ID) in the index.
A stable index location. Moving an existing index to a different search service isn't supported out-of-the-box. Revisit application requirements and make sure that your existing search service (capacity and region), are sufficient for your needs. If you're taking a dependency on Azure AI services or Azure OpenAI, choose a region that provides all of the necessary resources.
Finally, all service tiers have index limits on the number of objects that you can create. For example, if you're experimenting on the Free tier, you can only have three indexes at any given time. Within the index itself, there are limits on vectors and index limits on the number of simple and complex fields.
Document keys
Search index creation has two requirements: an index must have a unique name on the search service, and it must have a document key. The boolean key attribute on a field can be set to true to indicate which field provides the document key.
A document key is the unique identifier of a search document, and a search document is a collection of fields that completely describes something. For example, if you're indexing a movies data set, a search document contains the title, genre, and duration of a single movie. Movie names are unique in this dataset, so you might use the movie name as the document key.
In Azure AI Search, a document key is a string, and it must originate from unique values in the data source that's providing the content to be indexed. As a general rule, a search service doesn't generate key values, but in some scenarios (such as the Azure table indexer) it synthesizes existing values to create a unique key for the documents being indexed. Another scenario is one-to-many indexing for chunked or partitioned data, in which case document keys are generated for each chunk.
During incremental indexing, where new and updated content is indexed, incoming documents with new keys are added, while incoming documents with existing keys are either merged or overwritten, depending on whether index fields are null or populated.
Important points about document keys include:
- The maximum length of values in a key field is 1,024 characters.
- Exactly one top-level field in each index must be chosen as the key field and it must be of type
Edm.String. - The default of the
keyattribute is false for simple fields and null for complex fields.
Key fields can be used to look up documents directly and update or delete specific documents. The values of key fields are handled in a case-sensitive manner when looking up or indexing documents. See GET Document (REST) and Index Documents (REST) for details.
Schema checklist
Use this checklist to assist the design decisions for your search index.
Review naming conventions so that index and field names conform to the naming rules.
Review supported data types. The data type affects how the field is used. For example, numeric content is filterable but not full text searchable. The most common data type is
Edm.Stringfor searchable text, which is tokenized and queried using the full text search engine. The most common data type for a vector field isEdm.Singlebut you can use other types as well.Identify a document key. A document key is an index requirement. It's a single string field populated from a source data field that contains unique values. For example, if you're indexing from Blob Storage, the metadata storage path is often used as the document key because it uniquely identifies each blob in the container.
Identify the fields in your data source that contribute searchable content in the index.
Searchable nonvector content includes short or long strings that are queried using the full text search engine. If the content is verbose (small phrases or bigger chunks), experiment with different analyzers to see how the text is tokenized.
Searchable vector content can be images or text (in any language) that exists as a mathematical representation. You can use narrow data types or vector compression to make vector fields smaller.
Attributes set on fields, such as
retrievableorfilterable, determine both search behaviors and the physical representation of your index on the search service. Determining how fields should be attributed is an iterative process for many developers. To speed up iterations, start with sample data so that you can drop and rebuild easily.Identify which source fields can be used as filters. Numeric content and short text fields, particularly those with repeating values, are good choices. When working with filters, remember:
Filters can be used in vector and nonvector queries, but the filter itself is applied to alphanumeric (nonvector) fields in your index.
Filterable fields can optionally be used in faceted navigation.
Filterable fields are returned in arbitrary order and don't undergo relevance scoring, so consider making them sortable as well.
For vector fields, specify a vector search configuration and the algorithms used for creating navigation paths and filling the embedding space. For more information, see Add vector fields.
Vector fields have extra properties that nonvector fields don't have, such as which algorithms to use and vector compression.
Vector fields omit attributes that aren't useful on vector data, such as sorting, filtering, and faceting.
For nonvector fields, determine whether to use the default analyzer (
"analyzer": null) or a different analyzer. Analyzers are used to tokenize text fields during indexing and query execution.For multi-lingual strings, consider a language analyzer.
For hyphenated strings or special characters, consider specialized analyzers. One example is keyword that treats the entire contents of a field as a single token. This behavior is useful for data like zip codes, IDs, and some product names. For more information, see Partial term search and patterns with special characters.
Note
Full text search is conducted over terms that are tokenized during indexing. If your queries fail to return the results you expect, test for tokenization to verify the string you're searching for actually exists. You can try different analyzers on strings to see how tokens are produced for various analyzers.
Configure field definitions
The fields collection defines the structure of a search document. All fields have a name, data type, and attributes.
Setting a field as searchable, filterable, sortable, or facetable has an effect on index size and query performance. Don't set those attributes on fields that aren't meant to be referenced in query expressions.
If a field isn't set to be searchable, filterable, sortable, or facetable, the field can't be referenced in any query expression. This is desirable for fields that aren't used in queries, but are needed in search results.
The REST APIs have default attribution based on data types, which is also used by the Import wizards in the Azure portal. The Azure SDKs don't have defaults, but they have field subclasses that incorporate properties and behaviors, such as SearchableField for strings and SimpleField for primitives.
Default field attributions for the REST APIs are summarized in the following table.
| Data type | Searchable | Retrievable | Filterable | Facetable | Sortable | Stored |
|---|---|---|---|---|---|---|
Edm.String |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.String) |
✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
Edm.Boolean |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.Int32, Edm.Int64, Edm.Double |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.DateTimeOffset |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.GeographyPoint |
✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
Edm.ComplexType |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.Single) and all other vector field types |
✅ | ✅ or ❌ | ❌ | ❌ | ❌ | ✅ |
String fields can also be optionally associated with analyzers and synonym maps. Fields of type Edm.String that are filterable, sortable, or facetable can be at most 32 kilobytes in length. This is because values of such fields are treated as a single search term, and the maximum length of a term in Azure AI Search is 32 kilobytes. If you need to store more text than this in a single string field, you should explicitly set filterable, sortable, and facetable to false in your index definition.
Vector fields must be associated with dimensions and vector profiles. Retrievable default is true if you add the vector field using the Import and vectorize wizard in the portal, otherwise it's false if you use the REST API.
Field attributes are described in the following table.
| Attribute | Description |
|---|---|
| name | Required. Sets the name of the field, which must be unique within the fields collection of the index or parent field. |
| type | Required. Sets the data type for the field. Fields can be simple or complex. Simple fields are of primitive types, like Edm.String for text or Edm.Int32 for integers. Complex fields can have sub-fields that are themselves either simple or complex. This allows you to model objects and arrays of objects, which in turn enables you to upload most JSON object structures to your index. See Supported data types for the complete list of supported types. |
| key | Required. Set this attribute to true to designate that a field's values uniquely identify documents in the index. See Document keys in this article for details. |
| retrievable | Indicates whether the field can be returned in a search result. Set this attribute to false if you want to use a field as a filter, sorting, or scoring mechanism but don't want the field to be visible to the end user. This attribute must be true for key fields, and it must be null for complex fields. This attribute can be changed on existing fields. Setting retrievable to true doesn't cause any increase in index storage requirements. Default is true for simple fields and null for complex fields. |
| searchable | Indicates whether the field is full-text searchable and can be referenced in search queries. This means it undergoes lexical analysis such as word-breaking during indexing. If you set a searchable field to a value like "Sunny day", internally it's normalized into the individual tokens "sunny" and "day". This enables full-text searches for these terms. Fields of type Edm.String or Collection(Edm.String) are searchable by default. This attribute must be false for simple fields of other nonstring data types, and it must be null for complex fields. A searchable field consumes extra space in your index since Azure AI Search processes the contents of those fields and organize them in auxiliary data structures for performant searching. If you want to save space in your index and you don't need a field to be included in searches, set searchable to false. See How full-text search works in Azure AI Search for details. |
| filterable | Indicates whether to enable the field to be referenced in $filter queries. Filterable differs from searchable in how strings are handled. Fields of type Edm.String or Collection(Edm.String) that are filterable don't undergo lexical analysis, so comparisons are for exact matches only. For example, if you set such a field f to "Sunny day", $filter=f eq 'sunny' finds no matches, but $filter=f eq 'Sunny day' will. This attribute must be null for complex fields. Default is true for simple fields and null for complex fields. To reduce index size, set this attribute to false on fields that you won't be filtering on. |
| sortable | Indicates whether to enable the field to be referenced in $orderby expressions. By default Azure AI Search sorts results by score, but in many experiences users want to sort by fields in the documents. A simple field can be sortable only if it's single-valued (it has a single value in the scope of the parent document). Simple collection fields can't be sortable, since they're multi-valued. Simple subfields of complex collections are also multi-valued, and therefore can't be sortable. This is true whether it's an immediate parent field, or an ancestor field, that's the complex collection. Complex fields can't be sortable and the sortable attribute must be null for such fields. The default for sortable is true for single-valued simple fields, false for multi-valued simple fields, and null for complex fields. |
| facetable | Indicates whether to enable the field to be referenced in facet queries. Typically used in a presentation of search results that includes hit count by category (for example, search for digital cameras and see hits by brand, by megapixels, by price, and so on). This attribute must be null for complex fields. Fields of type Edm.GeographyPoint or Collection(Edm.GeographyPoint) can't be facetable. Default is true for all other simple fields. To reduce index size, set this attribute to false on fields that you won't be faceting on. |
| analyzer | Sets the lexical analyzer for tokenizing strings during indexing and query operations. Valid values for this property include language analyzers, built-in analyzers, and custom analyzers. The default is standard.lucene. This attribute can only be used with searchable string fields, and it can't be set together with either searchAnalyzer or indexAnalyzer. Once the analyzer is chosen and the field is created in the index, it can't be changed for the field. Must be null for complex fields. |
| searchAnalyzer | Set this property together with indexAnalyzer to specify different lexical analyzers for indexing and queries. If you use this property, set analyzer to null and make sure indexAnalyzer is set to an allowed value. Valid values for this property include built-in analyzers and custom analyzers. This attribute can be used only with searchable fields. The search analyzer can be updated on an existing field since it's only used at query-time. Must be null for complex fields]. |
| indexAnalyzer | Set this property together with searchAnalyzer to specify different lexical analyzers for indexing and queries. If you use this property, set analyzer to null and make sure searchAnalyzer is set to an allowed value. Valid values for this property include built-in analyzers and custom analyzers. This attribute can be used only with searchable fields. Once the index analyzer is chosen, it can't be changed for the field. Must be null for complex fields. |
| synonymMaps | A list of the names of synonym maps to associate with this field. This attribute can be used only with searchable fields. Currently only one synonym map per field is supported. Assigning a synonym map to a field ensures that query terms targeting that field are expanded at query-time using the rules in the synonym map. This attribute can be changed on existing fields. Must be null or an empty collection for complex fields. |
| fields | A list of subfields if this is a field of type Edm.ComplexType or Collection(Edm.ComplexType). Must be null or empty for simple fields. See How to model complex data types in Azure AI Search for more information on how and when to use subfields. |
Create an index
When you're ready to create the index, use a search client that can send the request. You can use the Azure portal or REST APIs for early development and proof-of-concept testing, otherwise it's common to use the Azure SDKs.
During development, plan on frequent rebuilds. Because physical structures are created in the service, dropping and re-creating indexes is necessary for many modifications. You might consider working with a subset of your data to make rebuilds go faster.
Index design through the portal enforces requirements and schema rules for specific data types, such as disallowing full text search capabilities on numeric fields.
Sign in to the Azure portal.
Check for space. Search services are subject to maximum number of indexes, varying by service tier. Make sure you have room for a second index.
In the search service Overview page, choose either option for creating a search index:
- Add index, an embedded editor for specifying an index schema
- Import wizards
The wizard is an end-to-end workflow that creates an indexer, a data source, and a finished index. It also loads the data. If this is more than what you want, use Add index instead.
The following screenshot highlights where Add index, Import data, and Import and vectorize data appear on the command bar.
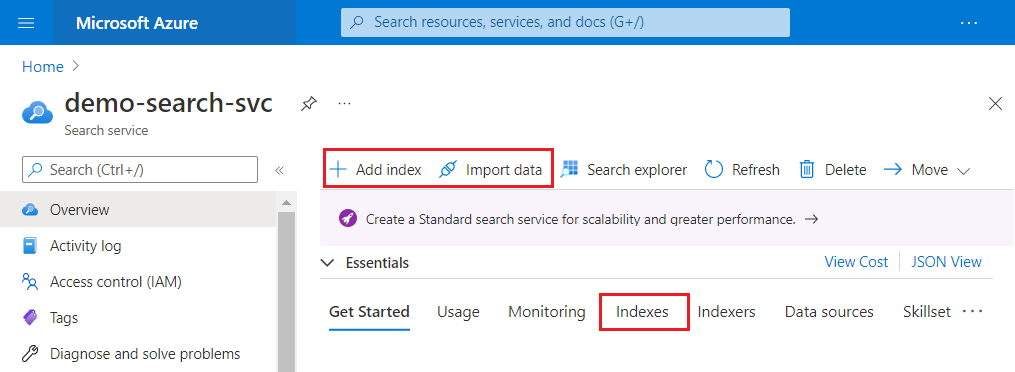
After an index is created, you can find it again on the Indexes page from the left navigation pane.
Tip
After creating an index in the portal, you can copy the JSON representation and add it to your application code.
Set corsOptions for cross-origin queries
Index schemas include a section for setting corsOptions. By default, client-side JavaScript can't call any APIs because browsers prevent all cross-origin requests. To allow cross-origin queries through to your index, enable CORS (Cross-Origin Resource Sharing) by setting the corsOptions attribute. For security reasons, only query APIs support CORS.
"corsOptions": {
"allowedOrigins": [
"*"
],
"maxAgeInSeconds": 300
The following properties can be set for CORS:
allowedOrigins (required): This is a list of origins that are allowed access to your index. JavaScript code served from these origins is allowed to query your index (assuming the caller provides a valid key or has permissions). Each origin is typically of the form
protocol://<fully-qualified-domain-name>:<port>although<port>is often omitted. For more information, see Cross-origin resource sharing (Wikipedia).If you want to allow access to all origins, include
*as a single item in the allowedOrigins array. This isn't a recommended practice for production search services but it's often useful for development and debugging.maxAgeInSeconds (optional): Browsers use this value to determine the duration (in seconds) to cache CORS preflight responses. This must be a non-negative integer. A longer cache period delivers better performance, but it extends the amount of time a CORS policy needs to take effect. If this value isn't set, a default duration of five minutes is used.
Allowed updates on existing indexes
Create Index creates the physical data structures (files and inverted indexes) on your search service. Once the index is created, your ability to effect changes using Create or Update Index is contingent upon whether your modifications invalidate those physical structures. Most field attributes can't be changed once the field is created in your index.
To minimize churn in application code, you can create an index alias that serves as a stable reference to the search index. Instead of updating your code with index names, you can update an index alias to point to newer index versions.
To minimize churn in the design process, the following table describes which elements are fixed and flexible in the schema. Changing a fixed element requires an index rebuild, whereas flexible elements can be changed at any time without impacting the physical implementation. For more information, see Update or rebuild an index.
| Element | Can be updated? |
|---|---|
| Name | No |
| Key | No |
| Field names and types | No |
| Field attributes (searchable, filterable, facetable, sortable) | No |
| Field attribute (retrievable) | Yes |
| Stored (applies to vectors) | No |
| Analyzer | You can add and modify custom analyzers in the index. Regarding analyzer assignments on string fields, you can only modify searchAnalyzer. All other assignments and modifications require a rebuild. |
| Scoring profiles | Yes |
| Suggesters | No |
| cross-origin resource sharing (CORS) | Yes |
| Encryption | Yes |
| Synonym maps | Yes |
| Semantic configuration | Yes |
Next steps
Use the following links to learn about specialized features that can be added to an index:
- Add vector fields and vector profiles
- Add scoring profiles
- Add semantic ranking
- Add suggesters
- Add synonym maps
- Add analyzers
- Add encryption
Use these links for loading or updating an index: