Opret forbindelse til en Common Data Model-tabeller i Azure Data Lake Storage
Bemærk
Azure Active Directory er nu Microsoft Entra ID. Få mere at vide
Indsæt data i Dynamics 365 Customer Insights - Data til at bruge din Azure Data Lake Storage-konto med Common Data Model-tabeller. Dataindtagelse kan være fuld eller trinvis.
Forudsætninger
Azure Data Lake Storage-firmaet skal have aktiveret hierarkisk navneområde. Dataene skal gemmes i et hierarkisk mappeformat, der definerer rodmappen og har undermapper til de enkelte tabeller. Undermapperne kan have komplette data eller trinvise datamapper.
Hvis du vil godkende med en Microsoft Entra-tjenestekonto, skal du sørge for, at den er konfigureret i din lejer. Du kan finde flere oplysninger i Oprette forbindelse til en Azure Data Lake Storage-konto vha. en Microsoft Entra-tjenesteprincipal.
Det Azure Data Lake Storage, du vil oprette forbindelse og indtage data fra, skal være i det samme Azure-område som Dynamics 365 Customer Insights-miljøet, og abonnementerne skal være i den samme lejer. Forbindelser til en Common Data Model-mappe fra en Data Lake i et andet Azure-område understøttes ikke. Hvis du vil vide mere om Azure-området i miljøet, skal du gå til Indstillinger>System>Om i Customer Insights - Data.
Data, der lagres i onlinetjenester, kan gemmes på en anden placering end det sted, hvor dataene behandles eller lagres. Ved at importere eller oprette forbindelse til data, der er gemt i onlinetjenester, accepterer du, at data kan overføres. Få mere at vide på Microsoft Sikkerhedscenter.
Customer Insights - Data-tjenestekonto skal være en af følgende roller for at få adgang til lagerkontoen. Du kan finde flere oplysninger i Tildele tilladelser til tjenesteprincipalen til at få adgang til lagerkontoen.
- Lager for Blob-datalæser
- Lager for Blob-dataejer
- Lager for Blob Data-bidragyder
Når du opretter forbindelse til dit Azure-datalager ved hjælp af Azure-abonnement-indstillingen, skal den bruger, der konfigurerer datakildeforbindelsen, mindst have tilladelserne Bidragyder til lagring af BLOB-data på lagerkontoen.
Når du opretter forbindelse til dit Azure-datalager ved hjælp af Azure-ressource-indstillingen, skal den bruger, der konfigurerer datakildeforbindelsen, mindst have tilladelsen til handlingen Microsoft.Storage/storageAccounts/read på lagerkontoen. En Azure-indbygget rolle, der inkluderer denne handling, er Læser-rollen. For at begrænse adgangen til kun den nødvendige handling skal du oprette en tilpasset Azure-rolle, der kun inkluderer denne handling.
Hvis du vil opnå en optimal ydeevne, skal størrelsen på en partition være på 1 GB eller mindre, og antallet af partitionsfiler i en mappe må ikke være større end 1000.
Data i dit Data Lake-lager skal følge standarden for Common Data Model for lagring af dine data og have et almindeligt datamodelmanifest, der repræsenterer skemaet for datafilerne (*.csv eller *.parquet). Manifestet skal indeholde oplysninger om tabellerne, f.eks. tabelkolonner og datatyper, samt placeringen og filtypen af datafilen. Du kan finde flere oplysninger i Common Data Model-manifest. Hvis manifestet ikke findes, kan admin-brugere med dataejeren Storage Blob eller Storage Blob Data-bidragyder definere skemaet, når dataene ændres.
Bemærk
Hvis nogen af felterne i .parquet-filerne har datatypen Int96, vises dataene muligvis ikke på siden Tabeller. Det anbefales, at du bruger standarddatatyper, f.eks. Unix-tidsstempelformatet (som repræsenterer tid som det antal sekunder, der er gået siden 1. januar 1970, ved midnat UTC).
Begrænsninger
- Customer Insights - Data understøtter ikke kolonner af decimaltype med mere præcision end 16.
Oprette forbindelse til Azure Data Lake Storage
Gå til Data>Datakilder.
Vælg Tilføj en datakilde.
Vælg Almindelige datamodeltabeller i Azure Data.

Angiv et Datakildenavn og en valgfri Beskrivelse. Navnet refereres til i downstreamprocesser og kan ikke ændres efter oprettelsen af datakilden.
Vælg en af følgende muligheder for at oprette forbindelse til lagerpladsen ved hjælp af. Du kan finde flere oplysninger i Oprette forbindelse til en Azure Data Lake Storage-konto vha. en Microsoft Entra-tjenesteprincipal.
- Azure-ressource: Angiv ressource-id'et. (private-link.md).
- Azure-abonnement: Vælg abonnementet, og vælg derefter ressourcegruppen og lagerkontoen.
Bemærk
Du skal bruge en af følgende roller for objektbeholderen for at kunne oprette datakilden:
- Læser af Blob Data-lager er tilstrækkelig, hvis du vil læse fra en lagerkonto og indtage dataene i Customer Insights - Data.
- Bidragyder til eller ejer af lagring af BLOB-data er påkrævet, hvis du vil redigere de manifestfiler direkte i Customer Insights - Data.
At have rollen på lagerkontoen vil give den samme rolle på alle dens objektbeholdere.
Hvis du vil aktivere data fra en lagerkonto via et Azure Private Link, skal du vælge Aktivér privat link. Du kan finde flere oplysninger under Private Link.
Vælg navnet på den beholder, der indeholder de data og skemaer (model.json- eller manifest.json-filen), der skal importeres data fra, og vælg Næste.
Bemærk
Alle model.json- eller manifest.json-filer, der er knyttet til andre datakilder i miljøet, vises ikke på listen. Men den samme model.json- eller manifest.json-fil kan bruges til datakilder i flere miljøer.
Hvis du vil oprette et nyt skema, skal du gå til Opret en ny skemafil.
Hvis du vil bruge et eksisterende skema, skal du navigere til den mappe, der indeholder filen model.json eller manifest.cdm.json. Du kan søge efter filen i en mappe.
Vælg json-filen, og vælg derefter Næste. En liste over tilgængelige tabeller vises.
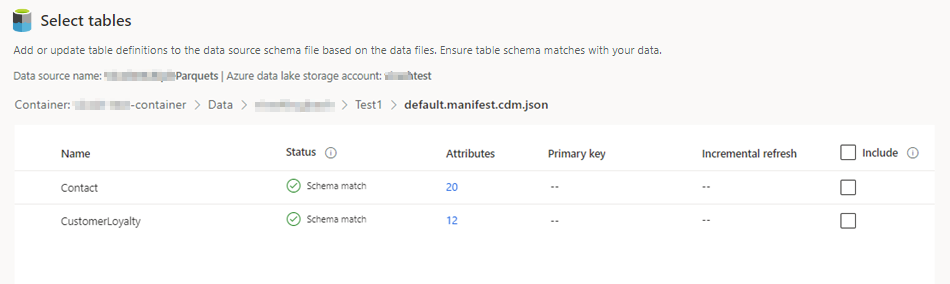
Vælg de tabeller, du vil medtage.
Tip
Hvis du vil redigere en tabel i en JSON-redigeringsgrænseflade, skal du vælge tabellen og derefter Rediger skemafil. Foretag dine ændringer, og Gem.
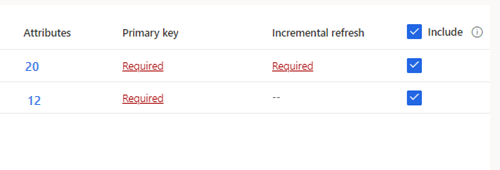
For de valgte tabeller, der kræver trinvis indtag, vises Påkrævet under Trinvis opdatering. For hver af disse tabeller skal du se Konfigurere en trinvis opdatering for Azure Data Lake-datakilder.
I forbindelse med valgte tabeller, hvor der ikke er defineret en primær nøgle, vises Obligatorisk under Primær nøgle. For hver af disse tabeller:
- Vælg Obligatorisk. Panelet Rediger tabel vises.
- Vælg den primære nøgle. Den primære nøgle er en attribut, der er entydig for tabellen. Hvis en attribut skal være en gyldig primær nøgle, må den ikke indeholde dubletværdier, manglende værdier eller null-værdier. Strengattributter, heltalsattributter og GUID-datatypeattributter understøttes som primære nøgler.
- Du kan også ændre partitionsmønsteret.
- Vælg Luk for at gemme og lukke panelet.
Vælg antallet af Kolonner for hver inkluderede tabel. Siden Administrer attributter vises.
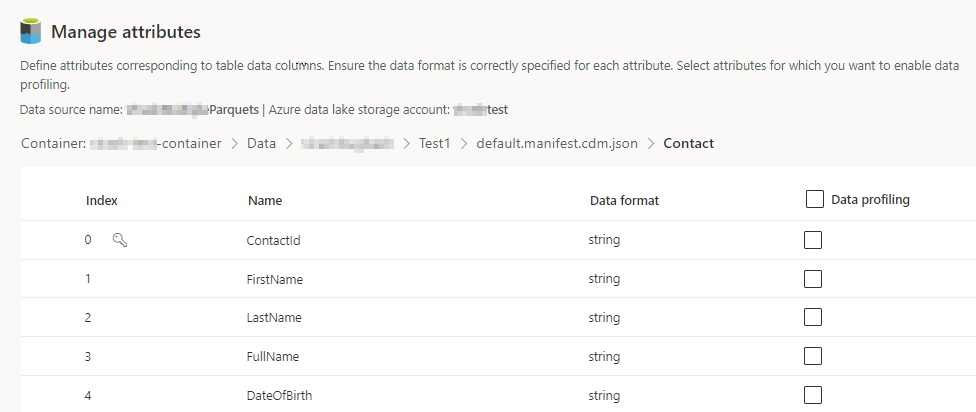
- Opret nye kolonner, rediger eller slet eksisterende kolonner. Du kan ændre navn, dataformat eller tilføje en semantisk type.
- Hvis du vil aktivere analyser og andre funktioner, skal du vælge Dataprofilering for hele tabellen eller for bestemte kolonner. Som standard er ingen tabel aktiveret for dataprofilering.
- Vælg Udført.
Vælg Gem. Siden Datakilder åbnes, der viser de nye datakilde status for Opdatering.
Tip
Der findes status for opgaver og processer. De fleste processer afhænger af andre upstream-processer, f.eks. datakilder og opdatering af dataprofiler.
Vælg status for at åbne ruden Statusdetaljer og få vist status for opgaverne. Hvis du vil annullere jobbet, skal du vælge Annuller job nederst i ruden.
Under hver opgave kan du vælge Se detaljer for at få flere statusoplysninger, f.eks. behandlingstid, den sidste behandlingsdato og eventuelle relevante fejl og advarsler, der er knyttet til opgaven eller processen. Vælg Visning af systemstatus nederst i panelet for at se andre processer i systemet.

Det kan tage tid at indlæse data. Når opdateringen er gennemført, kan de indtagne data gennemses fra siden Tabeller.
Opret en ny skemafil
Vælg Opret skemafil.
Skriv navnet på filen, og vælg Gem.
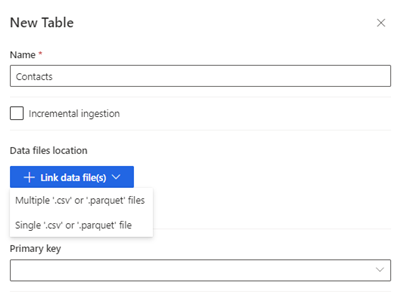
Vælg Ny tabel. Panelet Ny tabel vises.
Angiv tabelnavnet, og vælg placeringen af datafiler.
- Flere .csv- eller .parquet-filer: Søg efter rodmappen, vælg mønstertypen, og angiv udtrykket.
- Enkelte .csv- eller .parquet-filer: Gå til .csv- eller .parquet-filen, og markér den.
Vælg Gem.
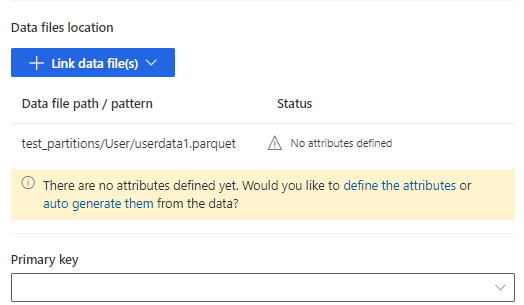
Vælg at definere attributterne for at tilføje attributterne manuelt, eller vælg automatisk at oprette dem. Hvis du vil definere attributterne, skal du angive et navn, vælge dataformatet og den valgfrie semantiske type. Autogenerede attributter:
Når attributterne er genereret automatisk, skal du vælge Gennemse attributter. Siden Administrer attributter vises.
Kontroller, at dataformatet er korrekt for hver attribut.
Hvis du vil aktivere analyser og andre funktioner, skal du vælge Dataprofilering for hele tabellen eller for bestemte kolonner. Som standard er ingen tabel aktiveret for dataprofilering.
Vælg Udført. Siden Vælg tabeller vises.
Fortsæt med at tilføje tabeller og kolonner, hvis de er relevante.
Når alle tabeller er tilføjet, skal du vælge Medtag for at inkludere tabellerne i datakildeindtag.
For de valgte tabeller, der kræver trinvis indtag, vises Påkrævet under Trinvis opdatering. For hver af disse tabeller skal du se Konfigurere en trinvis opdatering for Azure Data Lake-datakilder.
I forbindelse med valgte tabeller, hvor der ikke er defineret en primær nøgle, vises Obligatorisk under Primær nøgle. For hver af disse tabeller:
- Vælg Obligatorisk. Panelet Rediger tabel vises.
- Vælg den primære nøgle. Den primære nøgle er en attribut, der er entydig for tabellen. Hvis en attribut skal være en gyldig primær nøgle, må den ikke indeholde dubletværdier, manglende værdier eller null-værdier. Strengattributter, heltalsattributter og GUID-datatypeattributter understøttes som primære nøgler.
- Du kan også ændre partitionsmønsteret.
- Vælg Luk for at gemme og lukke panelet.
Vælg Gem. Siden Datakilder åbnes, der viser de nye datakilde status for Opdatering.
Tip
Der findes status for opgaver og processer. De fleste processer afhænger af andre upstream-processer, f.eks. datakilder og opdatering af dataprofiler.
Vælg status for at åbne ruden Statusdetaljer og få vist status for opgaverne. Hvis du vil annullere jobbet, skal du vælge Annuller job nederst i ruden.
Under hver opgave kan du vælge Se detaljer for at få flere statusoplysninger, f.eks. behandlingstid, den sidste behandlingsdato og eventuelle relevante fejl og advarsler, der er knyttet til opgaven eller processen. Vælg Visning af systemstatus nederst i panelet for at se andre processer i systemet.
Det kan tage tid at indlæse data. Når opdateringen er gennemført, kan de indtagne data gennemses fra siden Data>Tabeller.
Rediger Azure Data Lake Storage-datakilde
Du kan opdatere Kontoen Opret forbindelse til lager ved hjælp af-indstillingen. Du kan finde flere oplysninger i Oprette forbindelse til en Azure Data Lake Storage-konto vha. en Microsoft Entra-tjenesteprincipal. Hvis du vil oprette forbindelse til en anden objektbeholder fra lagerkontoen eller ændre kontonavnet, skal du oprette en ny datakildeforbindelse.
Gå til Data>Datakilder. Ud for den datakilde, du vil opdatere, og vælg Rediger.
Opdater følgende oplysninger:
Beskrivelse
Opret forbindelse til lagerpladsen ved hjælp af og forbindelsesoplysninger. Du kan ikke ændre objektbeholder-oplysninger, når du opdaterer forbindelsen.
Bemærk
En af følgende roller skal tildeles lagerkontoen eller -beholderen:
- Lager for Blob-datalæser
- Lager for Blob-dataejer
- Lager for Blob Data-bidragyder
Bruge administrerede identiteter til Azure med Azure Data Lake Storage ???
Aktiver privat link hvis du vil indtage data fra en lagerkonto via et Azure Private Link. Du kan finde flere oplysninger under Private Link.
Vælg Næste.
Opdater følgende:
Naviger til en anden model.json- eller manifest.json-fil med et andet sæt tabeller end beholderen.
Hvis du vil føje flere tabeller til indtag, skal du vælge Ny tabel.
Hvis du vil fjerne tabeller, der allerede er markeret, og hvis der ikke er nogen afhængigheder, skal du markere tabellen og vælge Slet.
Vigtigt
Hvis der er afhængigheder i den eksisterende model.json- eller manifest.json-fil og i sættet af tabeller, vises der en fejlmeddelelse, og du kan ikke vælge en anden model.json- eller manifest.json-fil. Fjern disse afhængigheder, før du ændrer filen model.json eller manifest.json eller opretter en ny datakilde med den model.json- eller manifest.json-fil, du vil bruge for at undgå at fjerne afhængighederne.
Vælg Rediger for at ændre placeringen af datafilen eller den primære nøgle.
Hvis du vil ændre trinvise indtagelsesdata, skal du se Konfigurere en trinvis opdatering af Azure Data Lake-datakilder.
Du skal kun ændre tabelnavnet, så det stemmer overens med tabelnavnet i .json-filen.
Bemærk
Du skal altid bevare tabelnavnet på samme måde som tabelnavnet i filen model.json eller manifest.json efter indtagelse. Customer Insights - Data validerer alle tabelnavne med model.json eller manifest.json under alle systemopdateringer. Hvis et tabelnavn ændres, opstår der en fejl, fordi Customer Insights - Data ikke kan finde det nye tabelnavn i .json-filen. Hvis et utilsigtet tabelnavn blev ændret ved et uheld, skal du redigere tabelnavnet, så det stemmer overens med navnet i .json-filen.
Vælg Kolonner for at tilføje eller ændre dem, eller hvis du vil aktivere dataprofilering. Vælg derefter Udført.
Vælg Gem for at anvende ændringerne og vende tilbage til siden Datakilder.
Tip
Der findes status for opgaver og processer. De fleste processer afhænger af andre upstream-processer, f.eks. datakilder og opdatering af dataprofiler.
Vælg status for at åbne ruden Statusdetaljer og få vist status for opgaverne. Hvis du vil annullere jobbet, skal du vælge Annuller job nederst i ruden.
Under hver opgave kan du vælge Se detaljer for at få flere statusoplysninger, f.eks. behandlingstid, den sidste behandlingsdato og eventuelle relevante fejl og advarsler, der er knyttet til opgaven eller processen. Vælg Visning af systemstatus nederst i panelet for at se andre processer i systemet.