Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Microsoft Fabrics API til GraphQL tilbyder en effektiv måde at forespørge på data effektivt, men optimering af ydeevne er nøglen til at sikre en jævn og skalerbar ydeevne. Uanset om du håndterer komplekse forespørgsler eller optimerer svartider, hjælper følgende bedste praksis dig med at få den bedste ydeevne ud af din GraphQL-implementering og maksimere din API-effektivitet i Fabric.
Hvem har brug for performanceoptimering
Ydelsesoptimering er afgørende for:
- Applikationsudviklere , der bygger applikationer med høj trafik, som forespørger Fabric lakehouses og lagre
- Dataingeniører , der optimerer Fabric-dataadgangsmønstre til storskala analyseapplikationer og ETL-processer
- Fabric workspace-administratorer styrer kapacitetsforbrug og sikrer effektiv ressourceudnyttelse
- BI-udviklere forbedrer responstider for brugerdefinerede analyseapplikationer bygget på Fabric-data
- DevOps-teams , der fejlsøger latensproblemer i produktionsapplikationer, der bruger Fabric API'er
Brug disse bedste praksisser, når dit GraphQL API skal håndtere produktionsarbejdsbelastninger effektivt, eller når du oplever ydelsesproblemer.
Regionsfordeling
Tværregionale API-kald er en almindelig årsag til høj latenstid. For optimal ydeevne skal du sikre, at dine klientapplikationer, Fabric-lejer, kapacitet og datakilder alle er i samme Azure-region.
Tjek din lejerregion
For at finde din Fabric-lejers region:
- Log ind på Microsoft Fabric-portalen med en administratorkonto
- Vælg Hjælp-ikonet (?) øverst til højre
- Nederst i Hjælp-panelet vælger du Om Stof
- Bemærk regionen, der vises i lejerdetaljerne
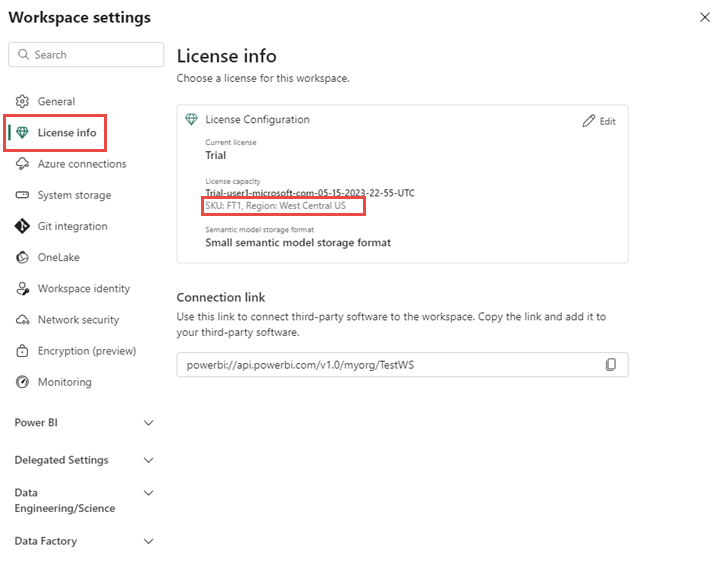
Tjek din kapacitetsregion
Dit API til GraphQL kører inden for en bestemt kapacitet. For at finde kapacitetsområdet:
Åbn arbejdsområdet, der hoster dit API for GraphQL
Gå til Workspace-indstillinger>Workspace-type
Find regionen under licenskapacitet

Tjek din datakilderegion
Placeringen af dine datakilder påvirker også ydeevnen:
- Fabric-datakilder (Lakehouse, Data Warehouse, SQL Database): Disse bruger samme region som arbejdsområdets kapacitet
- Eksterne datakilder (Azure SQL Database osv.): Tjek ressourceplaceringen i Azure-portalen
Best practice: Udrul klientapplikationer i samme område som din Fabric-kapacitet og datakilder for at minimere netværkslatens.
Best practices for performancetestning
Når du vurderer din API's ydeevne, skal du følge disse retningslinjer for pålidelige og konsistente resultater.
Brug realistiske testværktøjer
Test med værktøjer, der matcher dit produktionsmiljø tæt:
- Scripts eller applikationer: Brug Python-, Node.js- eller .NET-scripts, der simulerer faktisk klientadfærd
- HTTP-forbindelsespooling: Genanvendelse af HTTP-forbindelser for at reducere latenstid, hvilket især er vigtigt i scenarier på tværs af regioner
- Sessionsstyring: Oprethold sessioner på tværs af anmodninger for nøjagtigt at afspejle brugen i den virkelige verden
Eksempler på ressourcer:
- Eksempel på performance-testscript (Python notebook)
- HTTP-sessionsobjekter i Python
- HttpClient-retningslinjer for .NET
Indsaml meningsfulde målinger
For nøjagtig præstationsvurdering:
- Automatiser testning: Brug scripts eller performancetestværktøjer til at køre tests konsekvent over en defineret periode
- Varm API'et op: Udfør flere testforespørgsler, før du måler ydeevnen (se Opvarmningskrav)
- Analyser fordelinger: Brug percentilbaserede målinger (P50, P95, P99) i stedet for blot gennemsnit til at forstå latensmønstre
- Test under belastning: Mål ydeevne med realistiske samtidige anmodningsvolumener
- Dokumentbetingelser: Registrer tidspunkt på dagen, kapacitetsudnyttelse og eventuelle samtidige arbejdsbelastninger under testning
Almindelige ydelsesproblemer
At forstå disse almindelige problemer hjælper dig med effektivt at diagnosticere og løse præstationsproblemer.
Opvarmningskrav
Problem: Den første API-anmodning tager betydeligt længere tid end efterfølgende anmodninger.
Hvorfor dette sker:
- API-initialisering: Når API-miljøet er inaktivt, skal det initialisere under det første kald, hvilket tilføjer et par sekunders latenstid
- Opvarmning af datakilder: Mange datakilder (især SQL Analytics Endpoints og data warehouses) gennemgår en opvarmningsfase, når de tilgås efter at have været inaktive
- Kombineret initialisering: Hvis både API'en og datakilden er inaktive, ophobes initialiseringstiderne
Løsning:
- Udfør 2-3 testforespørgsler, før du måler ydeevnen
- For produktionsapplikationer skal du implementere sundhedskontrolendepunkter, der holder API'et varmt
- Overvej at bruge planlagte forespørgsler eller overvågningsværktøjer til at opretholde en aktiv tilstand i åbningstiden
Regional fejljustering
Problem: Konsekvent høj latenstid på alle forespørgsler.
Hvorfor dette sker: Netværkskald på tværs af regioner tilføjer betydelig latenstid, især når klient, API og datakilder er placeret i forskellige Azure-regioner.
Løsning:
- Kontroller at din klientapplikation, Fabric-kapacitet og datakilder er i samme region
- Hvis adgang på tværs af regioner er uundgåelig, skal du implementere aggressive caching-strategier
- Overvej at implementere regionale API-replikaer til globale applikationer
Datakildeydelse
Problem: API-forespørgsler er langsomme, selv når API'et er opvarmet og regionerne er justeret.
Hvorfor dette sker: API'et for GraphQL fungerer som et forespørgselsinterface over dine datakilder. Hvis den underliggende datakilde har performanceproblemer – såsom manglende indekser, komplekse forespørgsler eller ressourcebegrænsninger – arver API'et disse begrænsninger.
Løsning:
- Test direkte: Forespørg datakilden direkte (ved hjælp af SQL eller andre native værktøjer) for at etablere en baseline-ydelse
-
Optimer datakilden:
- Tilføj relevante indekser for ofte forespurgtes kolonner
- Overvej det rette datalager til dit brugsscenarie: Fabric beslutningsguide – vælg et datalager
- Gennemgå forespørgselsudførelsesplaner for optimeringsmuligheder
- Kapacitet i den rette størrelse: Sørg for, at din Fabric-kapacitets-SKU leverer tilstrækkelige beregningsressourcer. Se Microsoft Fabric-koncepter for vejledning i valg af passende kapacitet.
Forespørgselsdesign
Problem: Nogle forespørgsler fungerer godt, mens andre er langsomme.
Hvorfor dette sker:
- Over-fetching: At anmode om flere felter end nødvendigt øger behandlingstiden
- Dyb indlejring: Forespørgsler med mange niveauer af indlejrede relationer kræver flere resolver-udførelser
- Manglende filtre: Forespørgsler uden passende filtre kan returnere for meget data
Løsning:
- Anmod kun om de felter, du har brug for i din GraphQL-forespørgsel
- Begræns dybden af indlejrede relationer, hvor det er muligt
- Brug passende filtre og paginering i dine forespørgsler
- Overvej at opdele komplekse forespørgsler i flere enklere forespørgsler, når det er passende