Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Brug brugerdefinerede Spark-pools til at tilpasse compute til dine arbejdsbelastninger i Fabric. Du kan vælge nodestørrelse, konfigurere autoskaleringsadfærd og aktivere dynamisk eksekvertillokering.
Brugerdefinerede pools hjælper dig med at balancere ydeevne og omkostninger ved at lade dig sætte skaleringsgrænser, der matcher arbejdsbelastningens efterspørgsel.
Bemærkning
Custom Spark-pools kan opnå cirka 5-sekunders sessionsstart, når de konfigureres som en custom live pool med et miljø, der bruger Full mode til bibliotekspublicering. Uden en live pool-konfiguration tager custom Spark pools cirka tre minutter at starte.
Hvis du allerede bruger starterpools, er custom pools en supplerende mulighed, når du har brug for mere kontrol over størrelses- og skaleringsadfærd for specifikke arbejdsbelastninger. Brug startpools til hurtig opstart og standardindstillinger, og skift til brugerdefinerede pools, når du har brug for workload-specifik compute-tuning. For at lære mere om starterpuljer, se Konfigurér startpuljer i Fabric.
Forudsætninger
For at oprette en brugerdefineret Spark-pool:
- Du skal have admin-rollen i arbejdsområdet.
- En kapacitetsadministrator skal aktivere tilpassede arbejdsområdepuljer i Spark Compute-indstillingerne for kapaciteten.
For mere information, se Konfigurér og administrer data engineering- og data science-indstillinger for Fabric-kapaciteter.
Opret brugerdefinerede Spark-puljer
Sådan opretter eller administrerer du den Spark-gruppe, der er knyttet til dit arbejdsområde:
Gå til dit arbejdsområde og vælg Arbejdsområdeindstillinger.

Vælg indstillingen
Data Engineering/Science for at udvide menuen, og vælg derefter Spark-indstillinger .
Vælg Ny Pool fra Default pool for workspace dropdown-menuen for at oprette en ny brugerdefineret Spark pool. Du kan oprette flere brugerdefinerede pools og vælge en af dem som standardpool for dit workspace.
På siden Opret ny pool indtast et poolnavn. Vælg en nodefamilie (såsom hukommelsesoptimeret) og nodestørrelse baseret på arbejdsbelastningens krav. For mere information om nodestørrelser, se afsnittet om nodestørrelsesmuligheder nedenfor.
Tips
Nodestørrelsen bestemmes af Capacity Units (CU), som repræsenterer den beregningskapacitet, der er tildelt hver node.
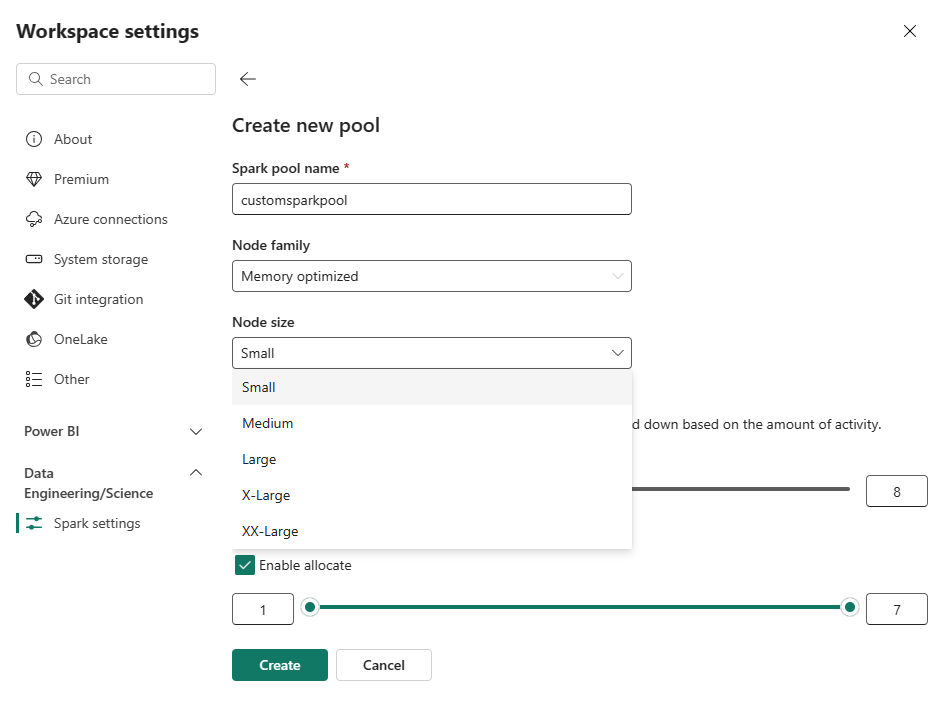
I redigeringsvisningen konfigurerer du Autoscale og tilloker eksekutorer dynamisk.
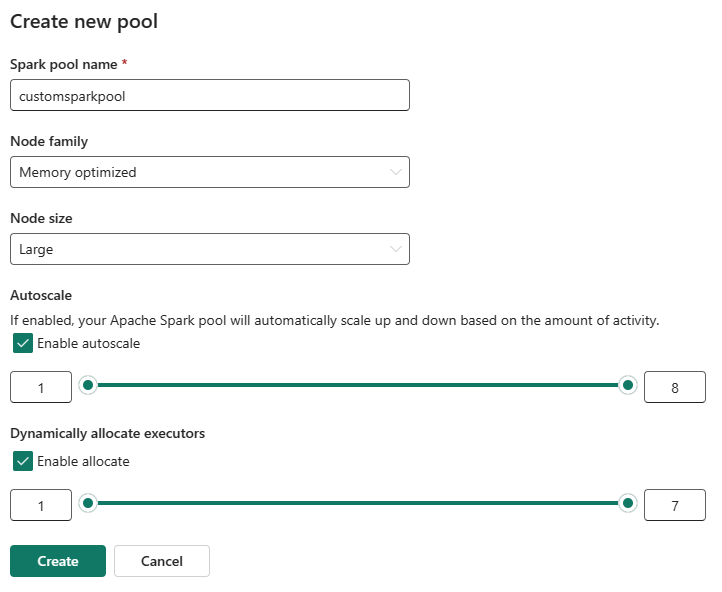
Brug skyderne til at øge eller mindske hver indstilling baseret på dine arbejdsbyrdebehov.
Hvis Autoscale er aktiveret, skalerer puljen mellem de konfigurerede minimums- og maksimumsnodeværdier baseret på aktivitet.
Hvis Dynamisk allokering af eksekutører er aktiveret, justerer Fabric eksekvertillokering baseret på arbejdsbelastningens behov inden for de konfigurerede grænser.
Vælg Opret.




Tips
Efter du har oprettet en brugerdefineret Spark-pool, afhænger bibliotekets udrulningstidspunkt af publiceringstilstanden i det tilknyttede miljø. Quick mode publiceres på cirka 5 sekunder og installerer biblioteker ved sessionsstart. Full mode tager 3 til 6 minutter at publicere og deployerer biblioteker som en del af sessionsopstart (1 til 3 minutter). For den hurtigste oplevelse kan du konfigurere poolen som en brugerdefineret live pool med Full mode, så sessioner starter cirka 5 sekunder.
Brugerdefinerede pools har en standard autopause-varighed på 2 minutter efter inaktivitet. Når autopause opnås, udløber sessionen, og klyngen frigør. Fakturering gælder kun, mens beregningen er aktivt. Brugerdefinerede Spark-pools i Microsoft Fabric understøtter i øjeblikket en maksimal nodegrænse på 200, så sørg for, at dine minimums- og maksimale autoskaleringsværdier forbliver inden for denne grænse.
Indstillinger for nodestørrelse
Når du konfigurerer en brugerdefineret Spark-pulje, skal du vælge mellem følgende nodestørrelser:
| Nodestørrelse | vCores | Hukommelse (GB) | Beskrivelse |
|---|---|---|---|
| Lille | 4 | 32 | Til lette udviklings- og testopgaver. |
| Mellem | 8 | 64 | Til generelle arbejdsbelastninger og typiske operationer. |
| Stor | 16 | 128 | Til hukommelseskrævende opgaver eller store databehandlingsjob. |
| X-stor | 32 | 256 | Til de mest krævende Spark-arbejdsbelastninger, der kræver betydelige ressourcer. |
| XX-stor | 64 | 512 | For de største Spark-arbejdsbelastninger, der kræver den højeste compute og hukommelse pr. node. |
Relateret indhold
- Få mere at vide i den offentlige dokumentation til Apache Spark.
- Kom i gang med Spark workspace-administrationsindstillinger i Microsoft Fabric.
- Administrer biblioteker i Fabric-miljøer