Git-integration og udrulningspipeline for miljø
I denne artikel beskrives det, hvordan du bruger Git-integrations- og udrulningspipelines til miljøet i Microsoft Fabric.
Git-integration til Microsoft Fabric-miljø
Microsoft Fabric understøtter Git-integration, så udviklere kan sikkerhedskopiere, styre versioner, vende tilbage til tidligere faser og samarbejde om deres arbejde ved hjælp af Git-forgreninger.
Vigtigt
Denne funktion er en prøveversion.
Bemærk
- Git understøtter i øjeblikket kun biblioteker og Spark-beregning, herunder Spark-kørsel.
- Git-integrationen administrerer miljøets midlertidige tilstand. Hvis du vil anvende ændringer, der er foretaget i Git, på miljøet, skal de publiceres. Det anbefales at publicere efter opdatering af miljøet fra Git for at sikre konfigurationens effektivitet. Du kan bruge publicerings-API'en for miljøet til at publicere ændringer via REST-API'en , hvis du foretrækker den første kodeoplevelse.
- Den tilknyttede brugerdefinerede gruppe bevares i et miljø, når du synkroniserer fra lager til et Fabric-arbejdsområde. Gruppedefinitionen findes i arbejdsområdeindstillingen, og referencen på tværs af arbejdsområder understøttes ikke. Du skal manuelt opdatere instance_pool_id til en eksisterende brugerdefineret gruppe i destinationsarbejdsområdet eller vende tilbage til startgruppen ved at fjerne denne egenskab. Du kan se brugerdefinerede puljer – Liste over brugerdefinerede puljer for at få den komplette liste over tilgængelige puljer i destinationsarbejdsområdet efter REST-API eller se Brugerdefinerede puljer – Opret brugerdefineret gruppe for arbejdsområdet for at oprette en ny brugerdefineret pulje.
- Hver bekræftelse har en øvre grænse på 150 MB. Brugerdefinerede biblioteker, der er større end 150 MB, understøttes i øjeblikket ikke via Git.
Opret forbindelse mellem Fabric-arbejdsområdet og et Azure DevOps-lager
Hvis du er administrator af et arbejdsområde, skal du gå til indstillingerne for arbejdsområdet og konfigurere forbindelsen i afsnittet Kildekontrol . Du kan få mere at vide under Administrer et arbejdsområde med Git.
Når du har oprettet forbindelse, kan du finde elementer, herunder de miljøer, der synkroniseres med lageret.
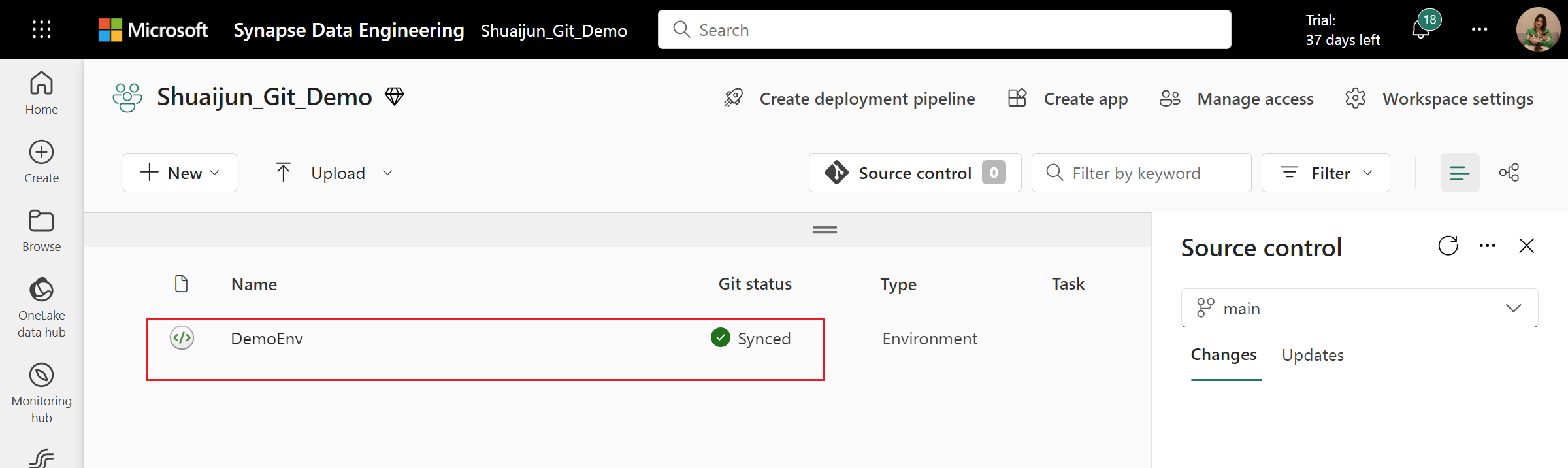
Lokal repræsentation af et miljø i Git
I elementrodmappen er miljøer organiseret med en biblioteksmappe , der indeholder undermapperne PublicLibraries og CustomLibraries sammen med mappen Setting .
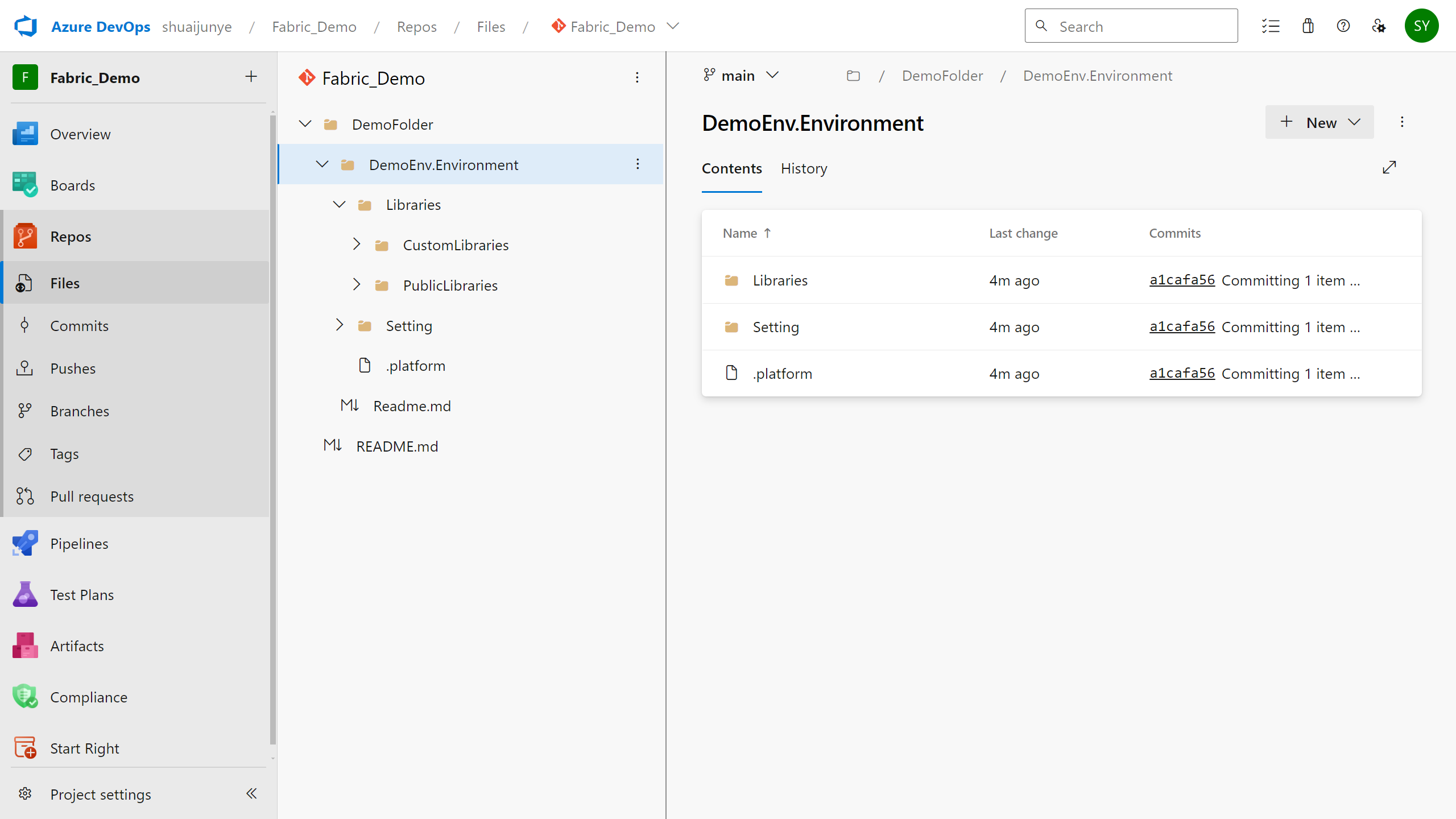
Biblioteker
Når du forpligter et miljø til Git, omdannes sektionen for det offentlige bibliotek til dens YAML-repræsentation. Desuden bekræftes det brugerdefinerede bibliotek sammen med kildefilen.
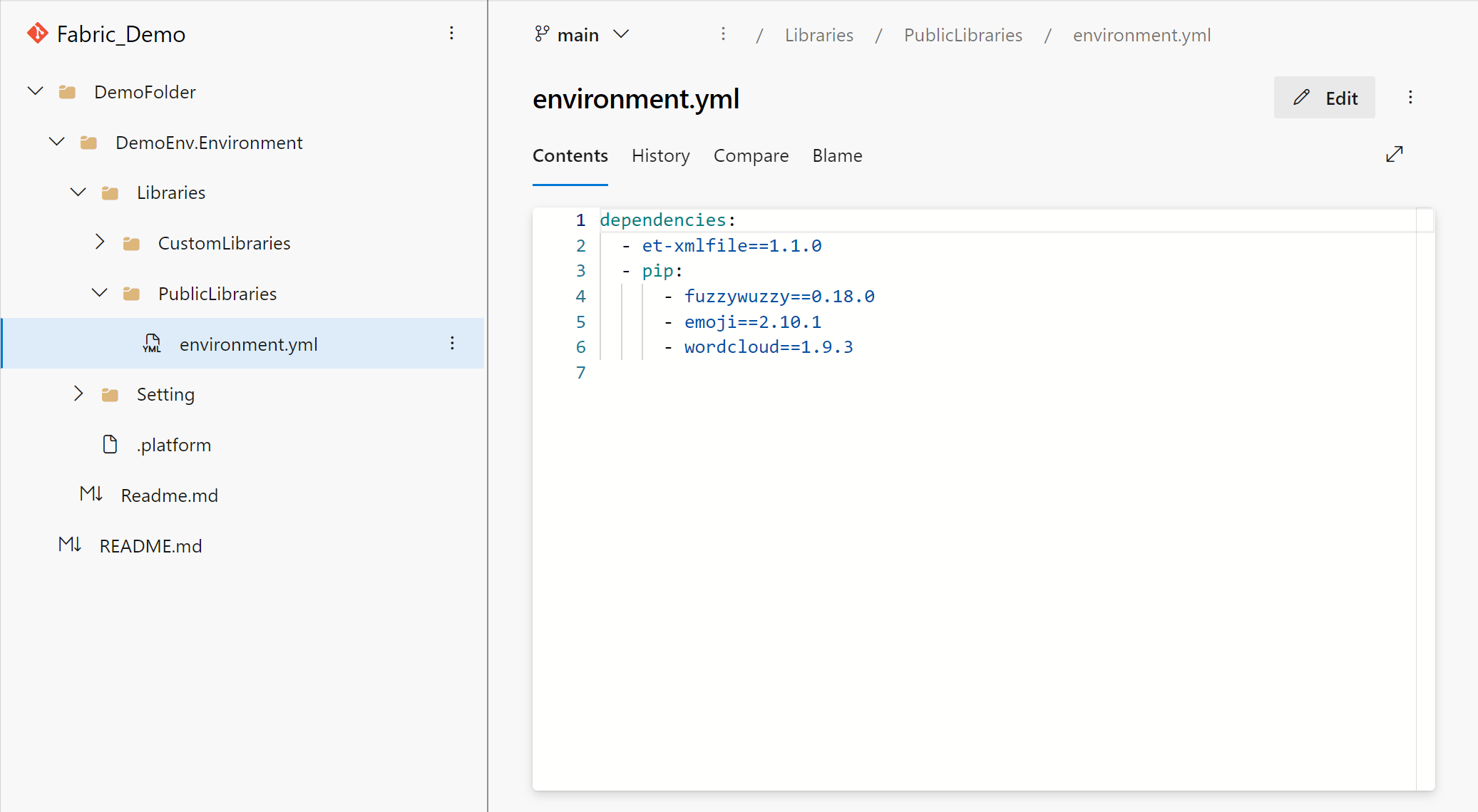
Du kan opdatere det offentlige bibliotek ved at redigere YAML-repræsentationen. På samme måde som med portaloplevelsen kan du angive et bibliotek fra PyPI og conda. Du kan angive biblioteket med den forventede version, et versionsområde eller uden version. Systemet kan hjælpe dig med at bestemme en version, der er kompatibel med andre afhængigheder i dit miljø. Hvis du vil rydde alle eksisterende offentlige biblioteker, skal du slette YAML-filen.
Du kan opdatere det brugerdefinerede bibliotek ved at tilføje nye filer eller slette eksisterende filer direkte.
Bemærk
Du kan medbringe din egen YAML-fil for at administrere det offentlige bibliotek. Filnavnet skal environment.yml for at kunne genkendes korrekt af systemet.
Spark-beregning
Spark-beregningsafsnittet transformeres også til YAML-repræsentationen. I denne YAML-fil kan du skifte den vedhæftede gruppe, finjustere beregningskonfigurationer, administrere Spark-egenskaber og vælge den ønskede Spark-kørsel.
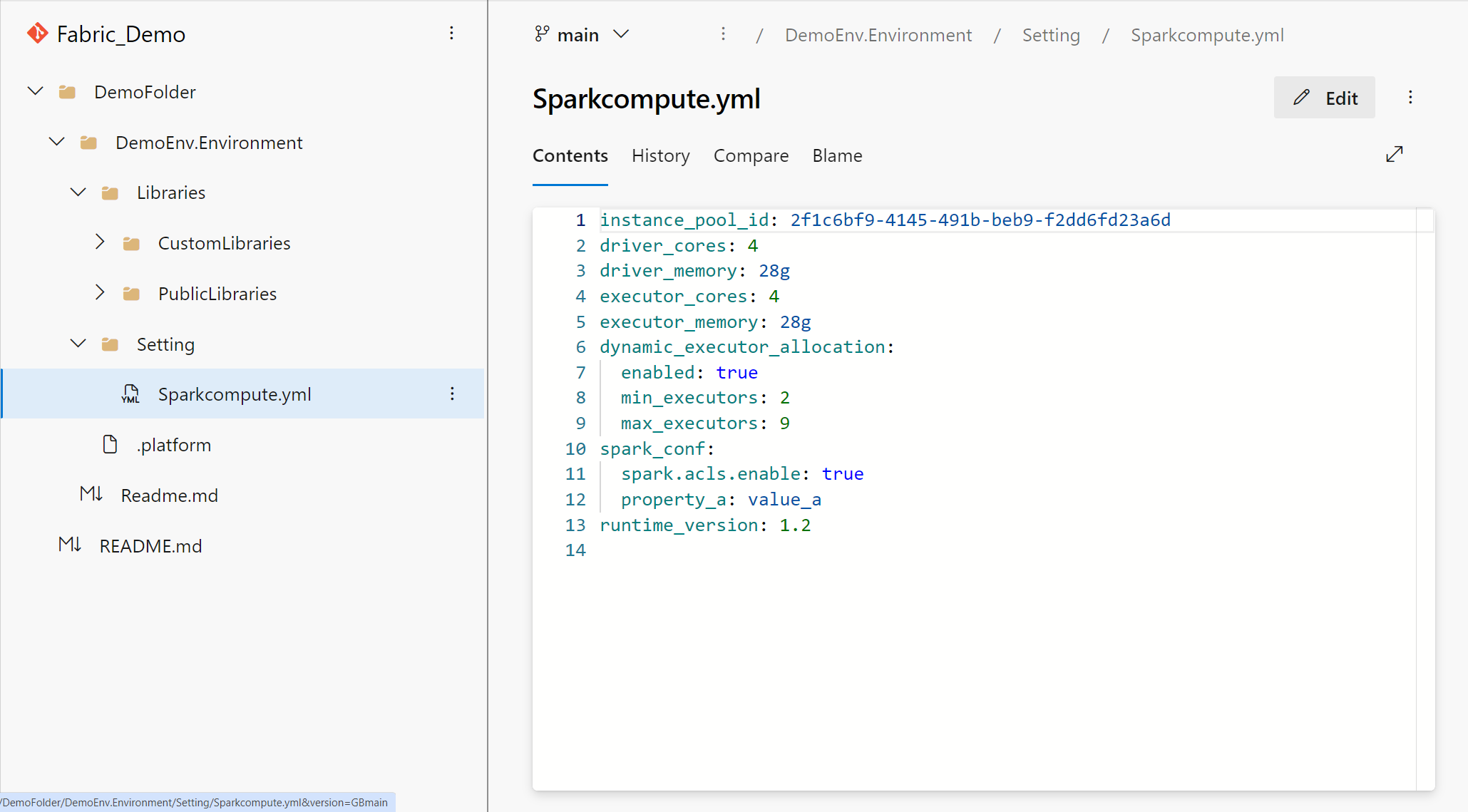
Udrulningspipeline til miljø
Vigtigt
Denne funktion er en prøveversion.
Fabric's udrulningspipelines forenkler processen med at levere ændret indhold på tværs af forskellige faser, f.eks. at gå fra udvikling til test. Den automatiske pipeline kan omfatte miljøelementerne for at streame genoprettelsesprocessen.
Du kan konfigurere en udrulningspipeline ved at tildele arbejdsområderne med forskellige faser. Få mere at vide om Kom i gang med udrulningspipelines.
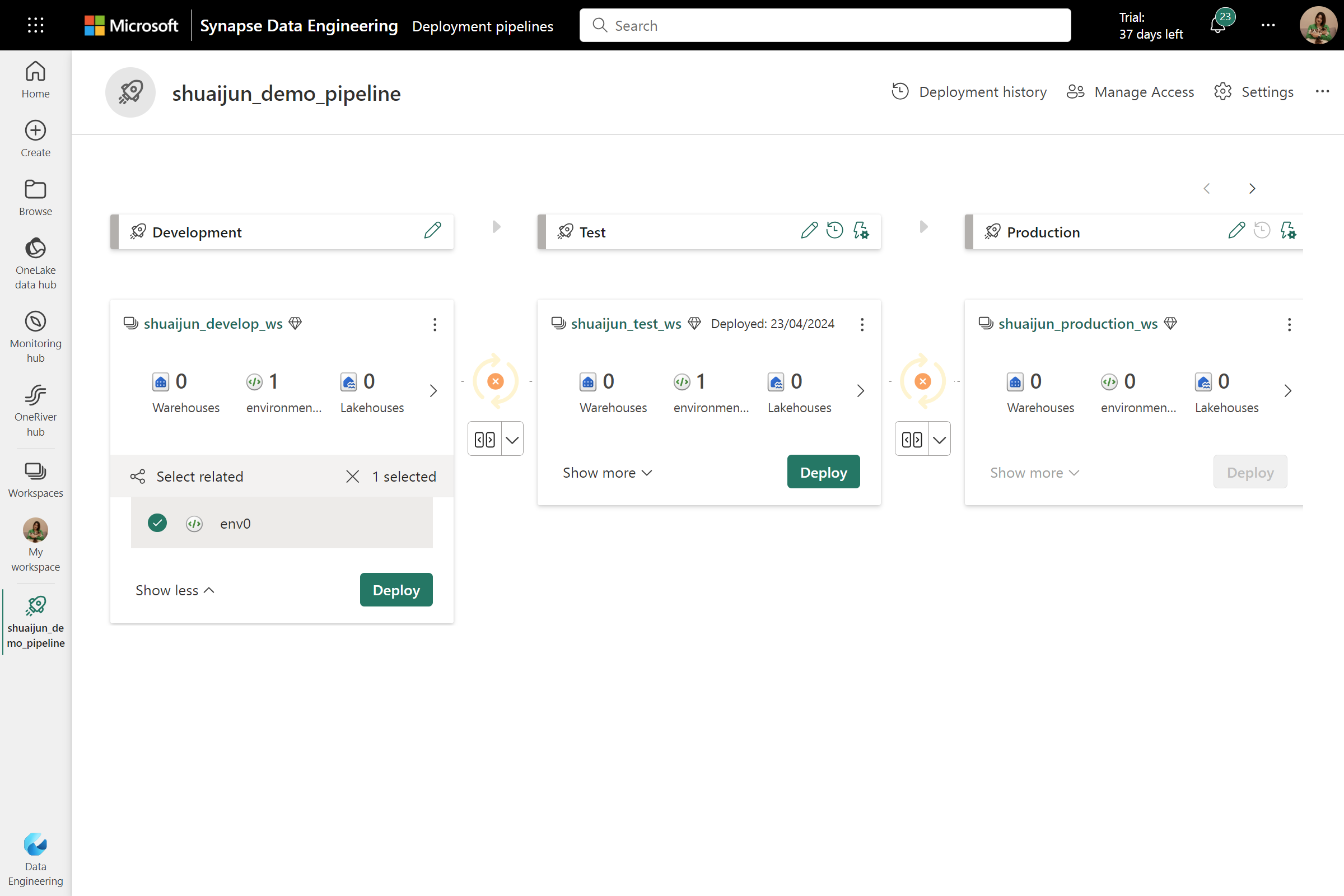
Du kan finde installationsstatussen, når pipelinen er konfigureret. Når du har klikket på knappen Installer med miljøet valgt, installeres alt indhold i miljøet i destinationsarbejdsområder. Status for det oprindelige miljø bevares i denne proces, hvilket betyder, at de publicerede konfigurationer forbliver i publiceret tilstand og ikke kræver ekstra publicering.
Vigtigt
- Den brugerdefinerede gruppe understøttes i øjeblikket ikke i udrulningspipeline. Hvis miljøet vælger den brugerdefinerede pulje, angives konfigurationerne af afsnittet Compute i destinationsmiljøet med standardværdier. I dette tilfælde bliver miljøerne ved med at vise diff i udrulningspipelinen, selv udrulningen udføres korrekt.
- Brug af udrulningsregler til at angive forskellige grupper i det nye arbejdsområde medtages i den kommende version.