Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Vigtigt
Denne funktion er i prøveversion.
Fabric Runtime leverer problemfri integration i Microsoft Fabric-økosystemet og tilbyder et robust miljø for data engineering og data science-projekter drevet af Apache Spark.
Denne artikel introducerer Fabric Runtime 2.0 Public Preview, den nyeste runtime designet til big data-beregninger i Microsoft Fabric. Den fremhæver de vigtigste funktioner og komponenter, der gør denne udgivelse til et betydeligt skridt fremad for skalerbar analyse og avancerede arbejdsbelastninger.
Fabric Runtime 2.0 indeholder følgende komponenter og opgraderinger, der er designet til at forbedre dine databehandlingsmuligheder:
- Apache Spark 4.1
- Operativsystem: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4,1
- R: 4.5.2
Vigtigt
Fabric Runtime 2.0 er blevet opdateret til Spark 4.1, Delta Lake 4.1 og Python 3.13. Fabric Runtime-versionen, der vises i portalen (Workspace-indstillinger og Runtime-indstilling i Environment UX), ændrer sig ikke.
| Komponent | Tidligere version | Aktuelle version |
|---|---|---|
| Spark | 4.0 | 4.1 |
| Delta-søen | 4.0 | 4.1 |
| Pyton | 3.12 | 3.13 |

Breaking change: Python-opgraderingen kræver, at du genudgiver alle miljøer, der har biblioteker. Indtil du genudgiver, vises fanerne Public libraries og Custom libraries tomme, og Spark-jobs, der målretter det berørte miljø, fejler med fejlene "No module found" eller "Class not found".
Påkrævede handlinger
- Optag eller eksporter din biblioteksliste fra hvert miljø.
- Tilføj bibliotekerne igen og vælg Publicer for at genopbygge dem mod Spark 4.1.
Tips
Fabric Runtime 2.0 inkluderer understøttelse af Native Execution Engine, som kan forbedre ydeevnen betydeligt uden yderligere omkostninger. Du kan aktivere den native eksekveringsmotor på miljøniveau, så alle jobs og notebooks automatisk arver de forbedrede ydeevnemuligheder.
Aktiver Runtime 2.0
Du kan aktivere Runtime 2.0 enten på arbejdsområdeniveau eller miljøobjektniveau. Brug arbejdsområde-indstillingen til at anvende Runtime 2.0 som standard for alle Spark-arbejdsbelastninger i dit arbejdsområde. Alternativt kan du oprette et miljøelement med Runtime 2.0, som kan bruges med specifikke notebooks eller Spark-jobdefinitioner, som tilsidesætter arbejdsområdets standard.
Aktiver Runtime 2.0 i Workspace-indstillingerne
For at sætte Runtime 2.0 som standard for hele dit arbejdsområde:
Gå til siden for arbejdsområdeindstillinger i dit Fabric-arbejdsområde.
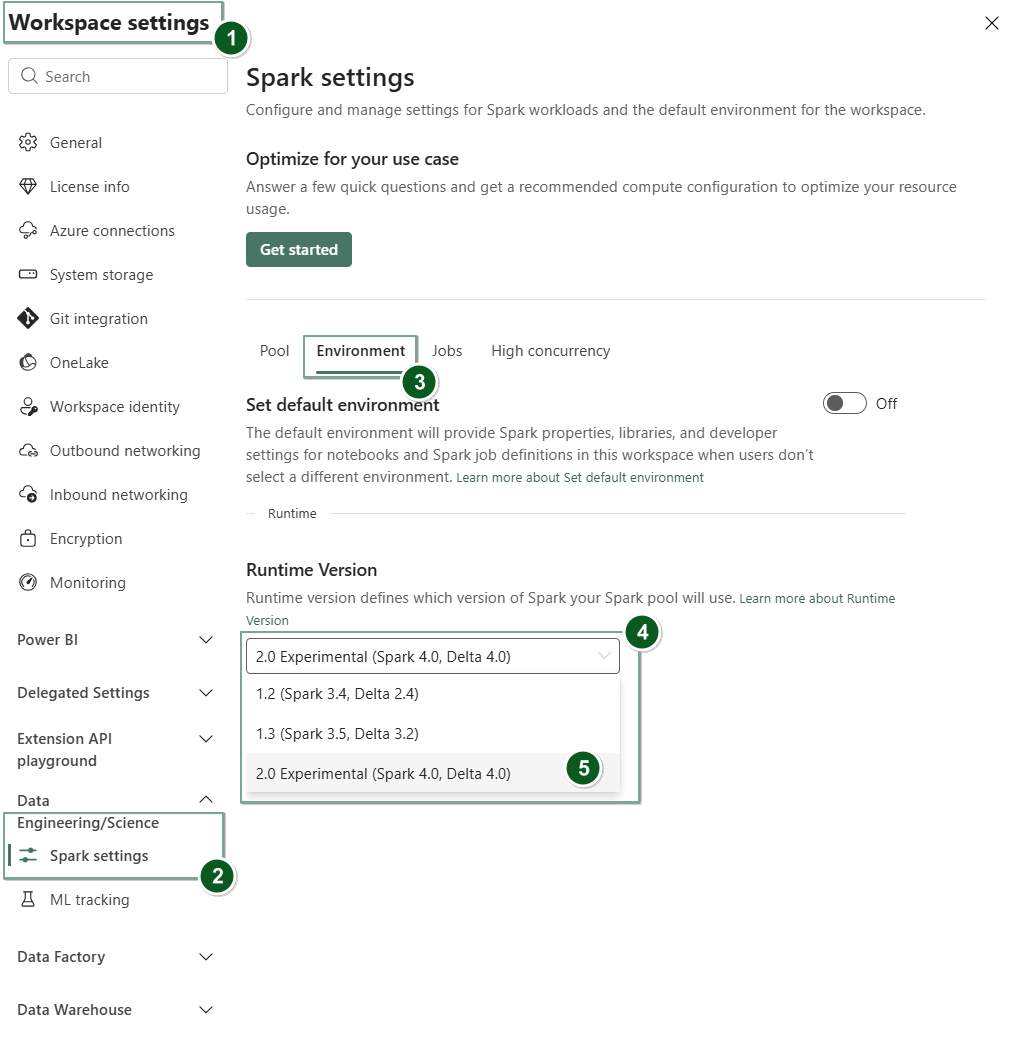
Vælg fanen Data Engineering/Science og vælg derefter Spark-indstillinger.
Vælg fanen Miljø .
Under rullemenuen for runtime-versionen vælger du 2.0 Public Preview (Spark 4.1, Delta 4.1) og gemmer dine ændringer.
Runtime 2.0 er sat som standardruntime for dit arbejdsområde.

Aktivér Runtime 2.0 i et miljøelement
For at bruge Runtime 2.0 med specifikke notebooks eller Spark-jobdefinitioner:
Opret et nyt miljøelement eller åbn et eksisterende.
Under rullemenuen Runtime vælger du 2.0 Public Preview (Spark 4.1, Delta 4.1),gemmer og udgiver dine ændringer.
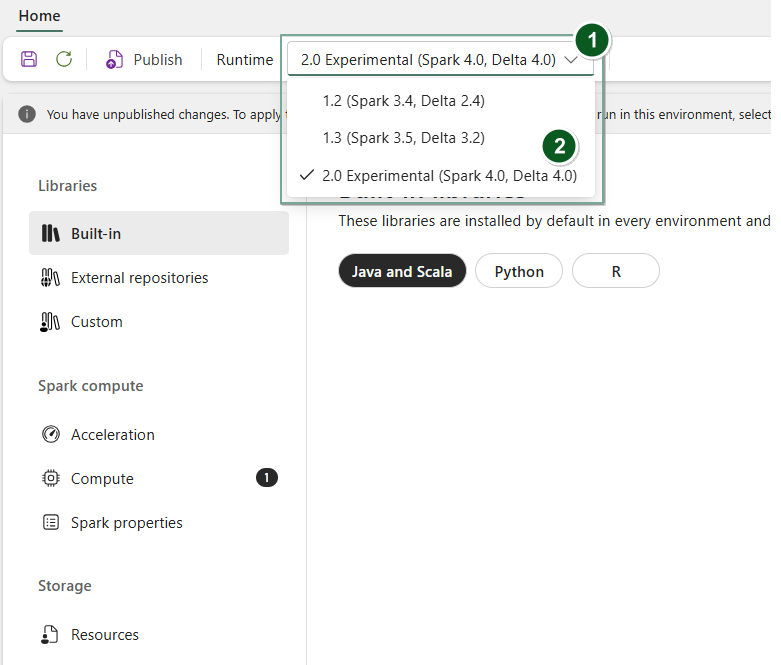
Dernæst kan du bruge dette Miljø-element med din Notebook - eller Spark-jobdefinition.

Du kan nu begynde at eksperimentere med de nyeste forbedringer og funktioner, der er introduceret i Fabric Runtime 2.0 (Spark 4.1 og Delta Lake 4.1).
Notat
WASB-protokollen for General Purpose v2 (GPv2) Azure Storage-konti er forældet. Du bør bruge den nyeste ABFS-protokol i stedet til at læse fra og skrive til GPv2-lagringskonti.
Offentlig prøveversion
Fabric Runtime 2.0 offentlige preview-fasen giver dig adgang til nye funktioner og API'er fra både Spark 4.1 og Delta Lake 4.1. Forhåndsvisningen lader dig bruge de nyeste Spark- og Delta-baserede forbedringer med det samme, samtidig med at den sikrer en glidende parathed og overgang til forbedrede og forbedrede ændringer som de nyere Java-, Scala- og Python-versioner.
Tips
Hvis du vil have opdaterede oplysninger, en detaljeret liste over ændringer og specifikke produktbemærkninger til Fabric-kørsel, skal du kontrollere og abonnere på Spark Runtimes-udgivelser og -opdateringer.
Centrale punkter
Forbedringer af ydeevne og eksekveringsmotor
Fabric Runtime 2.0 inkluderer Native Execution Engine, som giver betydelige ydelsesforbedringer i forhold til open source Spark. Motoren bruger vektoriseret behandling til at accelerere Spark-forespørgsler på lakehouse-infrastruktur uden at kræve kodeændringer.
Nøglefunktioner i Runtime 2.0:
- Op til seks gange hurtigere: Benchmarks viser op til seks gange hurtigere ydeevne sammenlignet med open source Spark på TPC-DS arbejdsbelastninger.
- Vektoriseret CSV-parsing: Den native eksekveringsmotor inkluderer en vektoriseret CSV-parser, der accelererer CSV-indlæsning og forespørgselsarbejdsbelastninger. Vectorized JSON-parsing og Spark Structured Streaming-understøttelse er planlagt til fremtidige opdateringer.
For at aktivere den native eksekveringsmotor, se Native eksekveringsmotor for Fabric Data Engineering.
Apache Spark 4.1
Apache Spark 4.0 markerede en vigtig milepæl som den første udgivelse i 4.x-serien, der indkapsler den fælles indsats fra det levende open source-fællesskab. Fabric Runtime 2.0 kører nu på Apache Spark 4.1, som bygger videre på det fundament med yderligere forbedringer.
I denne version er Spark SQL betydeligt beriget med kraftfulde nye funktioner, der skal øge udtryksfuldhed og alsidighed for SQL-arbejdsbelastninger, såsom understøttelse af VARIANT-datatyper, brugerdefinerede SQL-funktioner, sessionsvariabler, pipesyntaks og streng-kollation. PySpark ser en kontinuerlig dedikation til både sin funktionelle bredde og den samlede udvikleroplevelse, idet det bringer en native plotting API, en ny Python Data Source API, understøttelse af Python UDTF'er og samlet profilering af PySpark UDF'er, sammen med adskillige andre forbedringer. Structured Streaming udvikler sig med nøgletilføjelser, der giver større kontrol og nem fejlfinding, især introduktionen af Arbitrary State API v2 for mere fleksibel tilstandsstyring og State Data Source for nemmere fejlfinding.
Du kan se den fulde liste og detaljerede ændringer her:
Notat
I Spark 4.x er SparkR forældet og kan blive fjernet i en fremtidig version.
Delta Lake 4.1
Delta Lake 4.1 bygger videre på milepælsudgivelsen fra Delta Lake 4.0 og fortsætter engagementet i at gøre Delta Lake interoperabelt på tværs af formater, lettere at arbejde med og mere ydmygende. Den indeholder kraftfulde nye funktioner, ydeevneoptimeringer og grundlæggende forbedringer for fremtiden for åbne data-lakehouses.
Du kan se den fulde liste og detaljerede ændringer, der blev introduceret med Delta Lake 3.3, 4.0 og 4.1 her:
Datalayout og optimering
Runtime 2.0 understøtter datalayout- og optimeringsfunktioner for Delta-tabeller:
- Z-orden: Organiser data i Delta-tabelfiler efter specificerede kolonner for at forbedre forespørgselsydelsen for filtrerede forespørgsler.
- Liquid Clustering: En fleksibel klyngemetode, der automatisk optimerer datalayoutet uden manuel vedligeholdelse.
- Parallel Delta snapshot-indlæsning: Den native eksekveringsmotor indlæser Delta-tabelsnapshots parallelt, hvilket reducerer opstartstiden for forespørgsler for store tabeller.
Vigtigt
Delta Lake 4.1-specifikke funktioner er eksperimentelle og fungerer kun på Spark-oplevelser, såsom Notebooks og Spark Job Definitions. Hvis du skal bruge de samme Delta Lake-tabeller på tværs af flere Microsoft Fabric-arbejdsbelastninger, skal du ikke aktivere de funktioner. For at lære mere om, hvilke protokolversioner og funktioner der er kompatible på tværs af alle Microsoft Fabric-oplevelser, læs Delta Lake table format interoperability.
Beregningsstyring i Runtime 2.0
Runtime 2.0 understøtter følgende beregningsstyringsfunktioner:
- Ressourceprofiler: Konfigurer foruddefinerede ressourceallokeringer til Spark-sessioner for at matche arbejdsbelastningens krav og kontrollere omkostningerne.
- Brugerdefinerede live pools (forhåndsvisning): Opret dedikerede, forudopvarmede Spark-pools, der reducerer opstartstiden for sessioner. Brugerdefinerede live pools er tilgængelige i forhåndsvisning for Runtime 2.0-arbejdsbelastninger.
Begrænsninger og noter
- Delta Lake 4.x-specifikke funktioner er eksperimentelle og fungerer kun på Spark-oplevelser, såsom notebooks og Spark-jobdefinitioner. Hvis du skal bruge de samme Delta Lake-tabeller på tværs af flere Fabric-arbejdsbelastninger, skal du ikke aktivere de funktioner. For mere information, se Delta Lake tabelformat-interoperabilitet.
- Runtime 2.0 er i offentlig forhåndsvisning. Nogle funktioner og API'er kan ændre sig før generel tilgængelighed.
- VS Code-udvidelsen til Fabric Spark understøtter Runtime 2.0 til udvikling af notebook og Spark-jobdefinition.
Relateret indhold
- Apache Spark runtimes i Fabric - Oversigt, versionering og understøttelse af flere runtimes
- Spark Core-migreringsvejledning
- Vejledninger til migrering af SQL, Datasæt og DataFrame
- Vejledning til struktureret overførsel af streaming
- Overflytningsvejledning til MLlib (Machine Learning)
- Migreringsvejledning til PySpark (Python on Spark)
- SparkR-migreringsvejledning (R on Spark)