Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Kernebegreber, der understøtter dimensionering, optimering og fejlfinding. Læs dette først, hvis du er ny bruger af Spark in Fabric.
Generelle dos and don'ts
Scenarie: Du er ny bruger af Spark. Hvad er hvad du må og ikke må gøre
| Brugsscenarie | Bedste praksis |
|---|---|
| Brug optimerede serialiserede formater | Du bør: Foretræk formater som Avro, Parquet eller Optimized Row Column (ORC), fordi de integrerer skema, er kompakte og optimerer lagring og behandling. I stof skal du bruge Delta-format til atomicitet, konsistens, isolering, holdbarhed (ACID) garantier og ydeevnefordele |
| Vær forsigtig med XML/JSON | Stol ikke på skemainferens for store JavaScript Object Notation (JSON) eller XML-filer (Extensible Markup Language), da Spark læser hele datasættet for at udlede skemaet, hvilket gør behandlingen langsommere og bruger hukommelse intensivt. Angiv et statisk primært skema, når du læser JSON/XML, eller brug .option("samplingRatio", 0.1) det til at fremskynde læsninger, men vær opmærksom på, at hvis eksemplet ikke repræsenterer hele datasættet, kan læsninger mislykkes. En sikrere tilgang udleder skema fra et repræsentativt eksempel og bevarer det ved alle læsninger.Undgå at analysere store XML-filer. XML-parsing kører i sagens natur langsommere på grund af tagbehandling og typecasting. |
| Optimer joinforbindelser og filtrering | Du bør: Anvend kolonnebeskæring og filtrering på rækkeniveau før joinforbindelser for at reducere blanding og hukommelsesforbrug. Catalyst Optimizer håndterer automatisk predikat-pushdown, når du bruger DataFrame-API'er. Undgå RDD-API'er (Resilient Distributed Dataset), fordi de omgår Catalyst-optimeringer. |
| Foretræk DataFrames frem for RDD'er | Du bør: Brug DataFrames i stedet for RDD'er til de fleste handlinger. DataFrames bruger Catalyst Optimizer og Tungsten Execution Engine til effektiv udførelse. |
| Aktivér adaptiv udførelse af forespørgsler (AQE) | Du bør: Slå AQE til for dynamisk at optimere blandede partitioner og håndtere skæve data automatisk. |
Administration af eksekutorhukommelse
Scenarie: Du vil gerne forstå eksekutorens hukommelsesstyring til justering af ydeevnen.
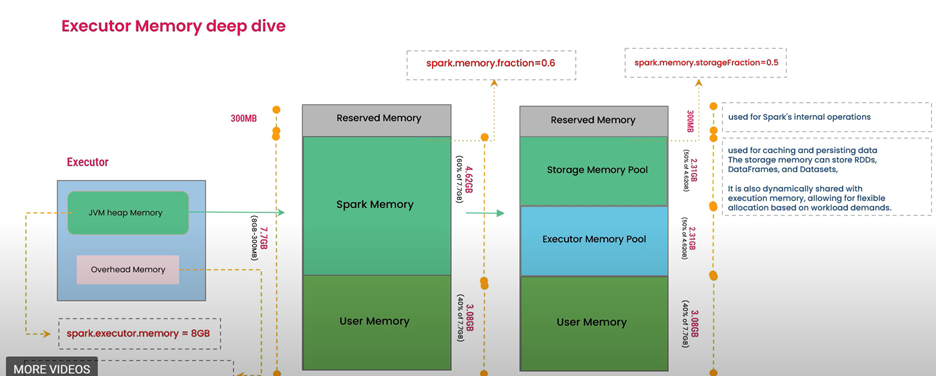
Selvom en eksekutor er konfigureret med 56 GB hukommelse, tillader Spark ikke, at det hele bruges direkte til brugerdata. Spark Core opdeler og administrerer eksekutorhukommelse:
Reserveret hukommelse: En fast del, der er reserveret til interne system- og Spark-omkostninger (f.eks. Java Virtual Machine (JVM), internals).
Brugerens hukommelse: Gemmer brugerdefinerede funktioner (UDF'er), lokale variabler, datastrukturer (lister, kort, ordbøger) og objekter, der er oprettet under beregningen.
Lagerhukommelse: Indeholder cachelagrede/persisterede data, udsendelsesvariabler og blandede data, der kan cachelagres.
Udførelse hukommelse: Bruges til mellemliggende beregninger (blandinger, joinforbindelser, sorteringer, sammenlægninger).
Dynamisk hukommelsesdeling: Grænsen mellem lager- og udførelseshukommelse kan flyttes. Spark kan låne hukommelse fra den ene region til den anden, hvilket giver mulighed for fleksibel hukommelsesbrug.
Spilde: Opstår, når enten lager- eller udførelseshukommelsesbehovet overstiger den tilgængelige hukommelse efter lån. Dette tvinger data til disk, hvilket kan påvirke ydeevnen.

Fejl ved manglende hukommelse (OOM)
Scenarie: Spark-job mislykkes med OOM-fejl (Out of Memory).
Driver OOM:
OOM-fejl for drivere opstår, når Spark-driveren overskrider den tildelte hukommelse.
Almindelig årsag: drivertunge handlinger som f.eks collect(). , countByKey()eller store toPandas() opkald, der trækker for mange data ind i driverhukommelsen.
Afbødning: Undgå førertunge operationer, når det er muligt. Hvis det er uundgåeligt, skal du øge driverstørrelsen og benchmark for at finde den optimale konfiguration.
Eksekutor tør for hukommelse (OOM):
OOM-fejl i eksekutoren opstår, når en Spark-eksekutor overskrider den allokerede hukommelse.
Almindelig årsag: Hukommelses- og beregningsintensive transformationer på store datasæt (f.eks. brede joinforbindelser, sammenlægninger, blandinger) eller cachelagrede/fastholdte datasæt, der overskrider eksekutorens tilgængelige hukommelse (udførelse + lagerområder).
Afhjælpning: Forøg eksekutorhukommelsen, hvis det er nødvendigt, juster Spark-hukommelsesfraktionerne (spark.memory.fraction, spark.memory.storageFraction) og bevar selektivt. Sørg for, at cachelagrede data passer ind i den tilgængelige hukommelse.
Data skævheder
Symptomer på skævhed:
- Nogle få opgaver tager længere tid end andre i Spark-brugergrænsefladen (sceneopgaver viser tung hale).
- Stor forskel mellem median og maks. opgavetid i fasemålinger.
- Faser med store shuffle-læse- eller skrivestørrelser for nogle få partitioner.
Almindelige årsager:
- Ujævn datafordeling for join-/gruppetasterne (genvejstaster).
- Forkert partitionering eller for få partitioner til datavolumen.
- Upstream-datauregelmæssigheder, der producerer store poster eller mange null/tomme nøgler.
Afbødning:
- Omfordeling eller sammenlægning for at øge partitionsparallelitet og balancere størrelser.
- Anvend nøglesaltning eller brugerdefineret partitionering for at sprede genvejstaster på tværs af partitioner.
- Brug AQE (Adaptive Query Execution) til at samle partitioner efter blanding og aktivere skæv-join-optimeringer.
- Brug rundsendelsesjoinforbindelser til små opslagstabeller for helt at undgå blandelser.
- Bevar afbalancerede mellemliggende datasæt før dyre faser, og kør jobbet igen.
UDF bedste praksis
Scenarie: Du skal anvende brugerdefineret logik, der ikke kan udtrykkes via indbyggede DataFrame-funktioner.
Brug Spark DataFrame-API'er, når det er muligt. Catalyst optimizer indbyggede funktioner og kører dem indbygget på JVM'en, så de leverer den bedste ydeevne.
Hvis du skal bruge en UDF (User Defined Function), skal du undgå almindelige PySpark Python UDF'er. Overvej i stedet følgende alternativer:
Pandas UDF'er (også kendt som vektoriserede UDF'er): Brug Apache Arrow til effektiv dataoverførsel mellem JVM og Python. Pandas UDF'er tillader vektoriserede operationer, hvilket forbedrer ydeevnen betydeligt sammenlignet med række-for-række Python UDF'er.
Scala/Java UDF'er: Kør direkte på JVM'en, og undgå Python-serialiseringsomkostninger. Scala/Java UDF'er overgår typisk Python UDF'er.
Vær forsigtig med Python UDF'er. Hver eksekutor starter en separat Python-proces, der kræver serialisering og deserialisering af data mellem JVM og Python. Dette skaber en flaskehals for ydeevnen, især i stor skala.
Logføring af fejl
Scenarie: Bedste fremgangsmåder for logføring af fejl i Fabric Spark
Brug
log4ji stedet forprint()som belaster føreren tungt. Medlog4jkan du få adgang til logfiler i driverlogfiler og søge i dem (ved hjælp af loggernavnet, f.eks.: PySparkLogger).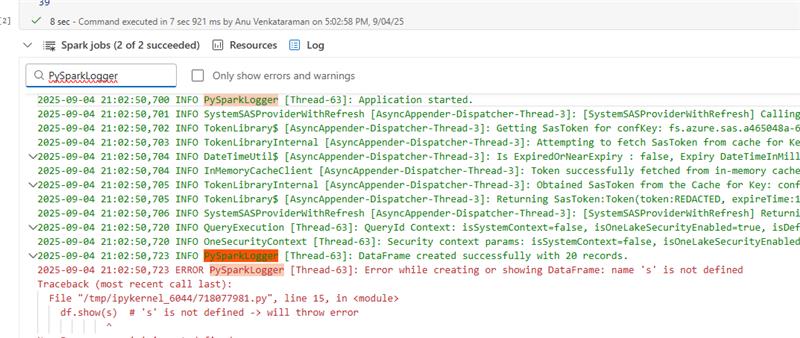
Ombryd læsninger, skrivninger og transformationer i try and excen-blokke. Bruges
logger.errortil undtagelser oglogger.infotil statusmeddelelser.Python-logning: Ideel til logføring af handlinger, statusopdateringer eller fejlfinding af oplysninger fra kode, der kun udføres på Spark-driveren. Pythons logføringsmodul overføres ikke til eksekutorlogfiler. Se dokumentationen til udvikling, udførelse og administration af notesbøger.
Spark log4j: Standarden for robust logføring af programmer på produktionsniveau i Spark, da den integreres indbygget med Sparks driver-/eksekutorlogfiler.
Eksempel på log4j-brug i PySpark:
import traceback # Get log4j logger log4jLogger = spark._jvm.org.apache.log4j logger = log4jLogger.LogManager.getLogger("PySparkLogger") logger.info("Application started.") try: # Create DataFrame with 20 records data = [(f"Name{i}", i) for i in range(1, 21)] # 20 records df = spark.createDataFrame(data, ["name", "age"]) logger.info("DataFrame created successfully with 20 records.") df.show(s) # 's' is not defined -> will throw error but the application will not fail except Exception as e: logger.error(f"Error while creating or showing DataFrame: {str(e)}\n{traceback.format_exc()}")Centraliser fejlovervågning:
Brug udvidelsen til diagnosticeringssender (Overvåg Apache Spark-programmer med Azure Log Analytics) i miljøet, og tilknyt dem til de notesbøger, der kører Spark-programmer. Senderen kan sende hændelseslogge, brugerdefinerede logge (f.eks. log4j) og målepunkter til Azure Log Analytics/Azure Storage/Azure Event Hubs. Giv log4j-navnet til ejendommen:
spark.synapse.diagnostic.emitter.\<destination\>.filter.loggerName.match.Derudover kan du til fejlfinding også indsamle mislykkede rækker/poster til Lakehouse-tabeller (LH) til registrering af dårlige data på postniveau.
