Sådan kommer du fra Azure Data Factory til Data Factory i Microsoft Fabric
Data Factory i Microsoft Fabric er den næste generation af Azure Data Factory, der leverer dataflytnings- og datatransformationstjenester i skyen, der giver dig mulighed for at løse de mest komplekse ETL-scenarier. Det er beregnet til at gøre din oplevelse nem at bruge, effektiv og virkelig professionel. I denne artikel sammenlignes forskellene mellem Azure Data Factory og Data Factory i Microsoft Fabric.
Funktionstilknytning
I den moderne oplevelse af Data Factory i Fabric er der nogle forskellige funktionskoncepter sammenlignet med Azure Data Factory. Tilknytning af detaljefunktioner vises som tabellen nedenfor.
| Azure Data Factory | Datafabrik i Fabric | Beskrivelse |
|---|---|---|
| Pipeline | Datapipeline | Datapipeline i Fabric er bedre integreret med den samlede dataplatform, herunder Lakehouse, Datawarehouse og meget mere. |
| Tilknytning af dataflow | Dataflow Gen2 | Dataflow Gen2 gør det nemmere at bygge transformation. Vi er i gang med at lade flere funktioner i tilknytning af dataflow understøttes i Dataflow Gen2 |
| Aktiviteter | Aktiviteter | Vi er i gang med at foretage flere aktiviteter for ADF, der understøttes i Data Factory i Fabric. Data Factory i Fabric har også nogle nyligt tiltrukket aktiviteter som Office 365 Outlook-aktivitet. Detaljer findes i aktivitetsoversigten. |
| Datasæt | Ikke tilgængelig | Data Factory i Fabric har ikke datasætbegreber. Forbind ion bruges til at oprette forbindelse mellem hver datakilde og pulldata. |
| Sammenkædet tjeneste | Forbindelser | Forbind ions har samme funktionalitet som linkede tjenester, men forbindelser i Fabric har en mere intuitiv måde at oprette på. |
| Udløsere | Tidsplaner (andre udløsere er i gang) | Fabric kan bruge tidsplanen til automatisk at køre pipelinen. Vi tilføjer flere udløsere, der understøttes af ADF i Microsoft Fabric. |
| Publicer | Gem, kør | I forbindelse med pipeline i Fabric behøver du ikke at publicere for at gemme indholdet. Du kan i stedet bruge knappen Gem til at gemme indholdet direkte. Når du klikker på knappen Kør, gemmes indholdet, før pipelinen køres. |
| Kørsel af Autoresolve og Azure Integration | Ikke tilgængelig | I Fabric har vi ikke begrebet Integration runtime. |
| Kørsel af integration via selvvært | Datagateway i det lokale miljø (i design) | Kapaciteten i Fabric er stadig i gang med design. |
| Kørsel af Azure-SSIS-integration | Skal bestemmes | Funktionen i Fabric har ikke bekræftet køreplanen og designet. |
| MVNet og privat slutpunkt | Skal bestemmes | Funktionen i Fabric har ikke bekræftet køreplanen og designet. |
| Udtrykssprog | Udtrykssprog | Udtrykssproget er det samme i ADF og Fabric. |
| Godkendelsestype i sammenkædet tjeneste | Godkendelsestype i forbindelse | Godkendelsestyper i Fabric-pipelinen understøttes allerede populære godkendelsestyper i ADF, og der tilføjes flere godkendelsestyper. |
| CI/CD | CI/CD | CI/CD-funktionalitet i Fabric Data Factory kommer snart. |
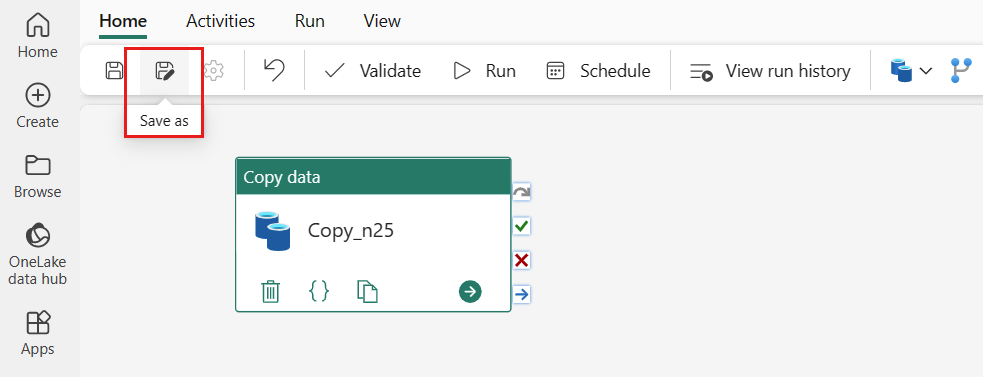
| Eksportér og importér ARM | Save as | Gem som er tilgængelig i Fabric-pipelinen for at duplikere en pipeline. |
| Overvågning | Overvågning, kørselsoversigt | Overvågningshubben i Fabric har mere avancerede funktioner og moderne oplevelse som overvågning på tværs af forskellige arbejdsområder for at få bedre indsigt. |
Datapipeline på datafabrikken i Microsoft Fabric
Der er mange spændende funktioner i datapipeline i Data Factory of Microsoft Fabric. Hvis du udnytter disse funktioner, kan du mærke styrken ved pipelinen i Fabric.
Integration af Lakehouse/Datawarehouse
Lakehouse og Data Warehouse er tilgængelige som kilde og destination i Pipeline of Fabric, så det er ekstremt praktisk for dig at bygge dine egne projekter integreret med Lakehouse og Datawarehouse.

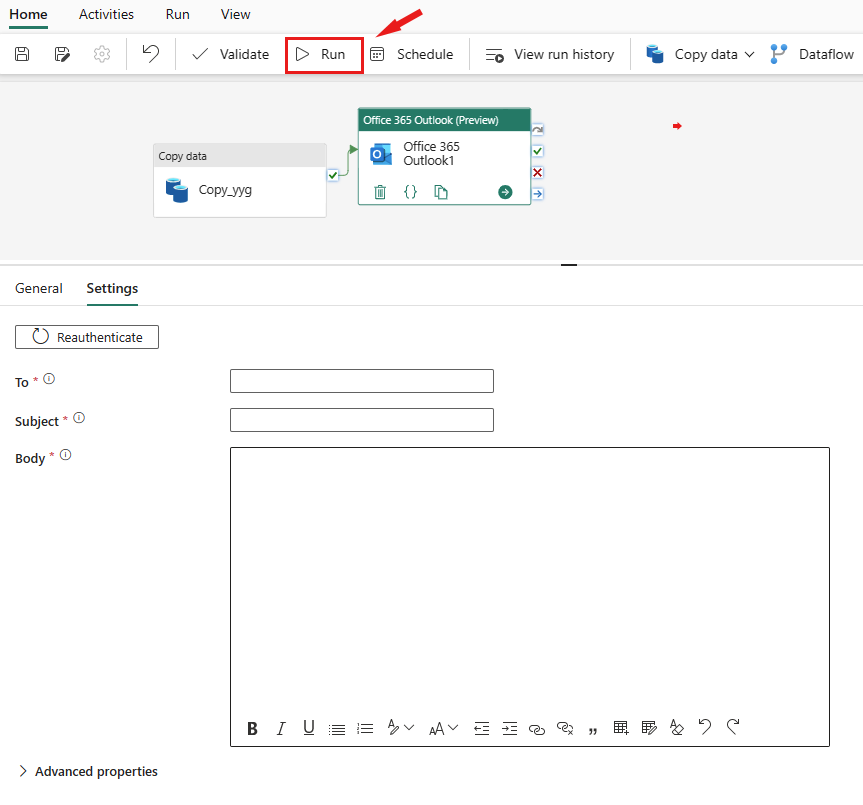
Outlook-aktivitet i Office 365
Office 365 Outlook-aktivitet er en intuitiv og enkel måde at sende tilpasset mailmeddelelse om oplysninger om pipeline og aktivitet og output af pipeline ved nem konfiguration.
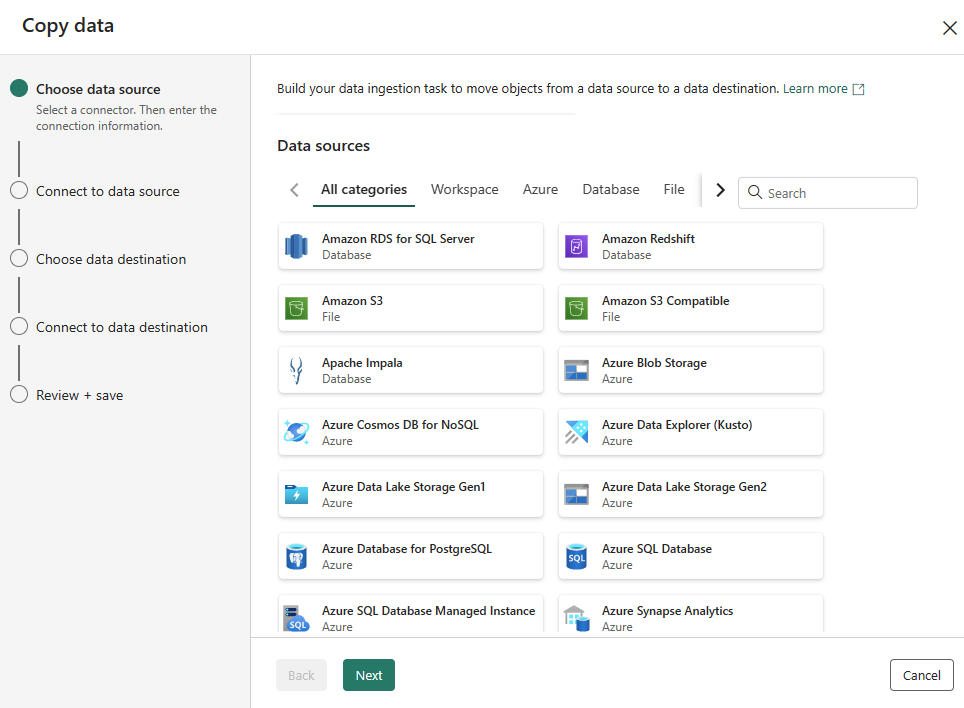
Få dataoplevelse
En moderne og nem Hent data-oplevelse leveres i Data Factory i Fabric, så det er superhurtigt for dig at konfigurere din kopipipeline og oprette en ny forbindelse.

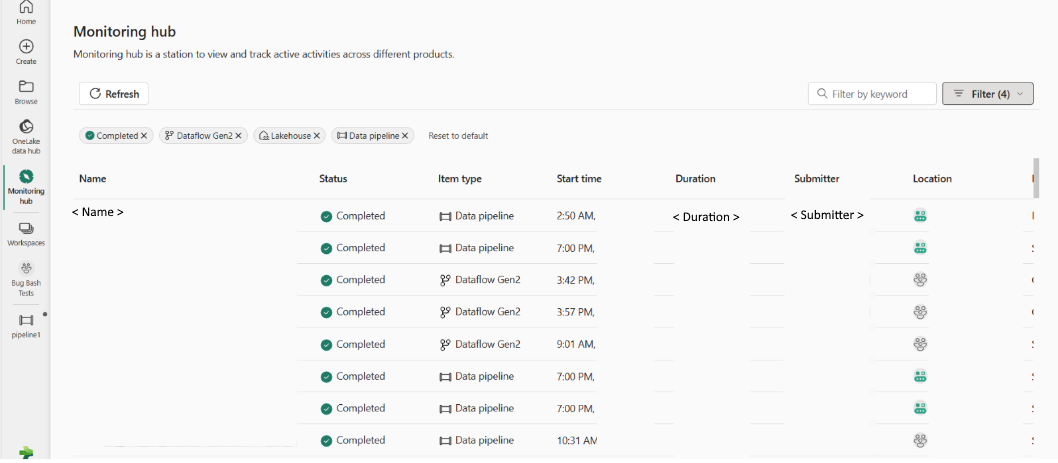
Moderne overvågningsoplevelse
Med de kombinerede funktioner i overvågningshubben og elementerne i Data Factory, f.eks. dataflows og datapipelines, kan vi få et fuldt overblik over alle arbejdsbelastninger og analysere alle aktiviteter i en datafabriks oplevelse. Det er også praktisk for dig at udføre analysen på tværs af arbejdsområder via overvågningshubben.
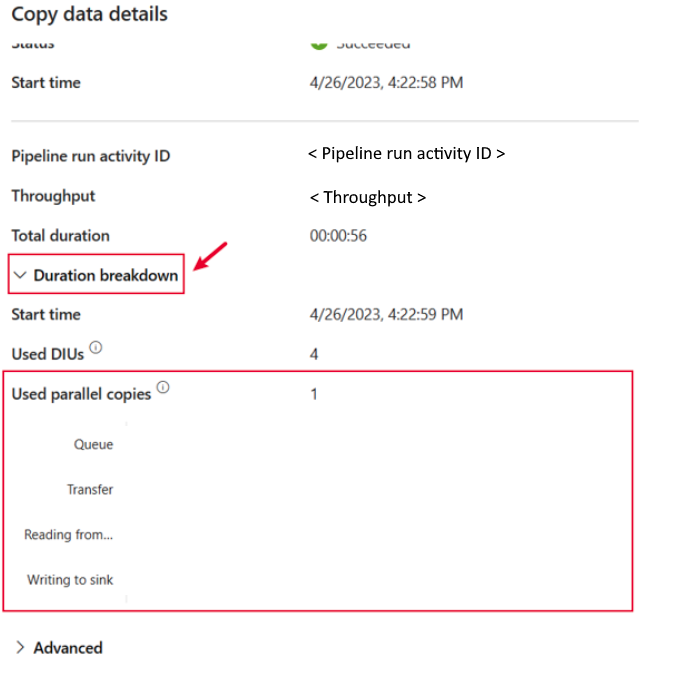
Overvågningsresultaterne for pipelinekopi indeholder detaljerede oplysninger om kopiaktivitet. Ved at vælge knappen med kørselsoplysninger (med ikonet briller fremhævet) for at få vist kørselsdetaljerne. Udvid opdelingen Varighed. Du kan kende varigheden af hver fase i kopiaktiviteten.

Save as
Gem som i Fabric-pipelinen gør det nemt for dig at duplikere en eksisterende pipeline til andre udviklingsformål.
Relateret indhold
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om