Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
I en pipeline kan du bruge aktiviteten Kopiér til at kopiere data mellem datalagre i skyen. Når du har kopieret dataene, kan du bruge andre aktiviteter i din pipeline til at transformere og analysere dem.
Aktiviteten Kopiér opretter forbindelse til dine datakilder og destinationer og flytter derefter data effektivt mellem dem. Sådan håndterer tjenesten kopiprocessen:
- Opretter forbindelse til din kilde: Opretter en sikker forbindelse for at læse data fra dit kildedatalager.
- Behandler dataene: Håndterer serialisering/deserialisering, komprimering/dekomprimering, kolonnetilknytning og konverteringer af datatyper baseret på din konfiguration.
- Skriver til destination: Overfører de behandlede data til dit destinationsdatalager.
- Giver overvågning: Sporer kopieringshandlingen og giver detaljerede logfiler og målepunkter til fejlfinding og optimering.
Tip
Hvis du kun har brug for at kopiere dine data og ikke har brug for transformationer, kan et kopijob være en bedre mulighed for dig. Kopieringsjob giver en forenklet oplevelse for scenarier for dataflytning, der ikke kræver oprettelse af en fuld pipeline. Se: Oversigt over kopiering af job , eller brug vores beslutningstabel til at sammenligne Kopiér aktivitet og Kopiér job.
Prerequisites
For at komme i gang skal du fuldføre disse forudsætninger:
- En Microsoft Fabric-lejerkonto med et aktivt abonnement. Opret en konto gratis.
- Et Microsoft Fabric-aktiveret arbejdsområde.
Tilføj en kopiaktivitet ved hjælp af kopiassistenten
Følg disse trin for at konfigurere din kopiaktivitet ved hjælp af kopiassistenten.
Start med kopiassistent
Åbn en eksisterende pipeline, eller opret en ny pipeline.
Vælg Kopiér data på lærredet for at åbne værktøjet Kopieringsassistent for at komme i gang. Eller vælg Brug kopiassistent på rullelisten Kopiér data under fanen Aktiviteter på båndet.


Konfigurer din kilde
Vælg en datakildetype i kategorien. Du skal bruge Azure Blob Storage som eksempel. Vælg Azure Blob Storage.
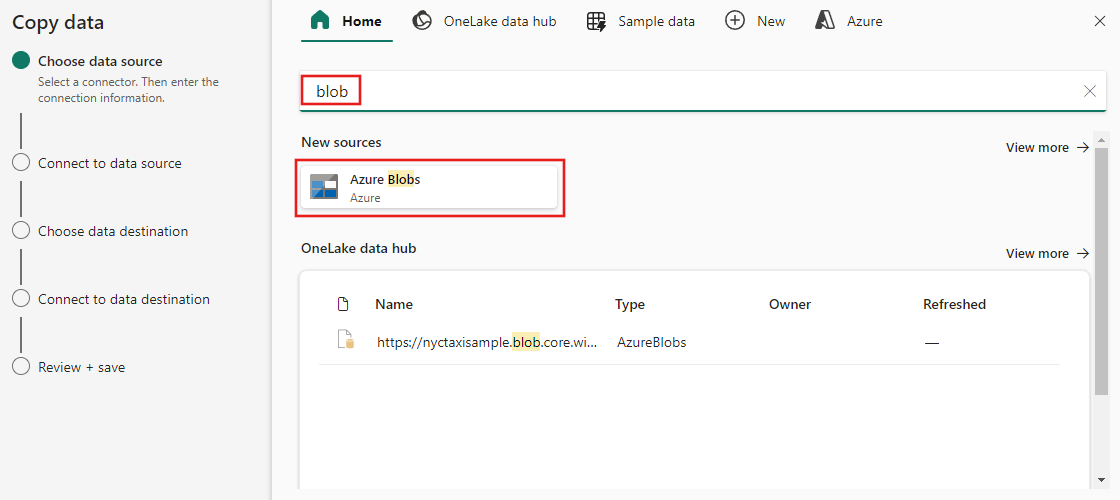
Opret en forbindelse til datakilden ved at vælge Opret ny forbindelse.
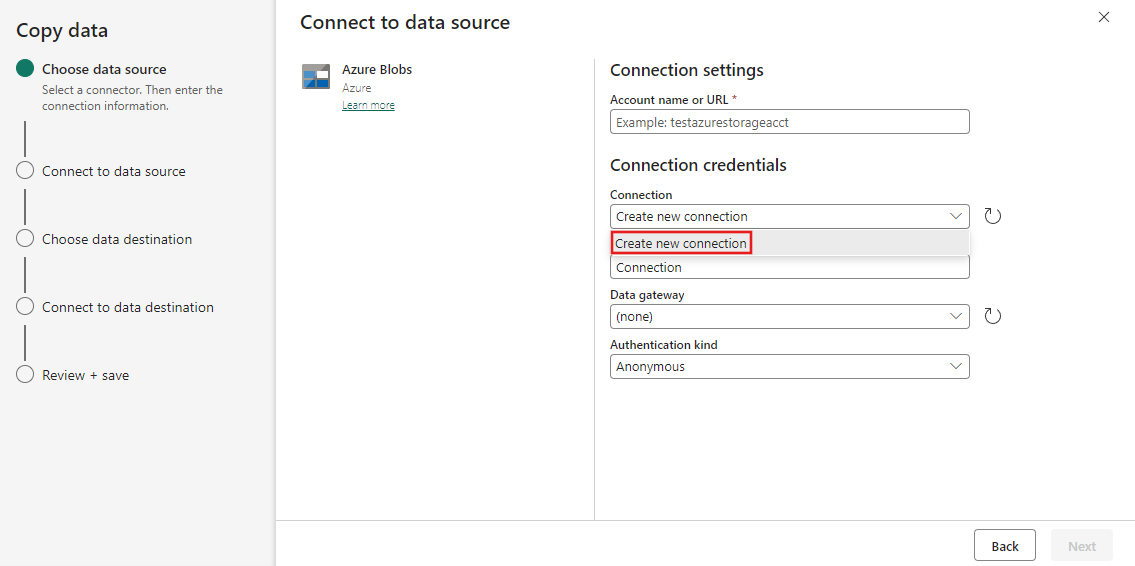
Når du har valgt Opret ny forbindelse, skal du udfylde de påkrævede forbindelsesoplysninger og derefter vælge Næste. Du kan finde flere oplysninger om oprettelse af forbindelse for hver type datakilde i hver connectorartikel.
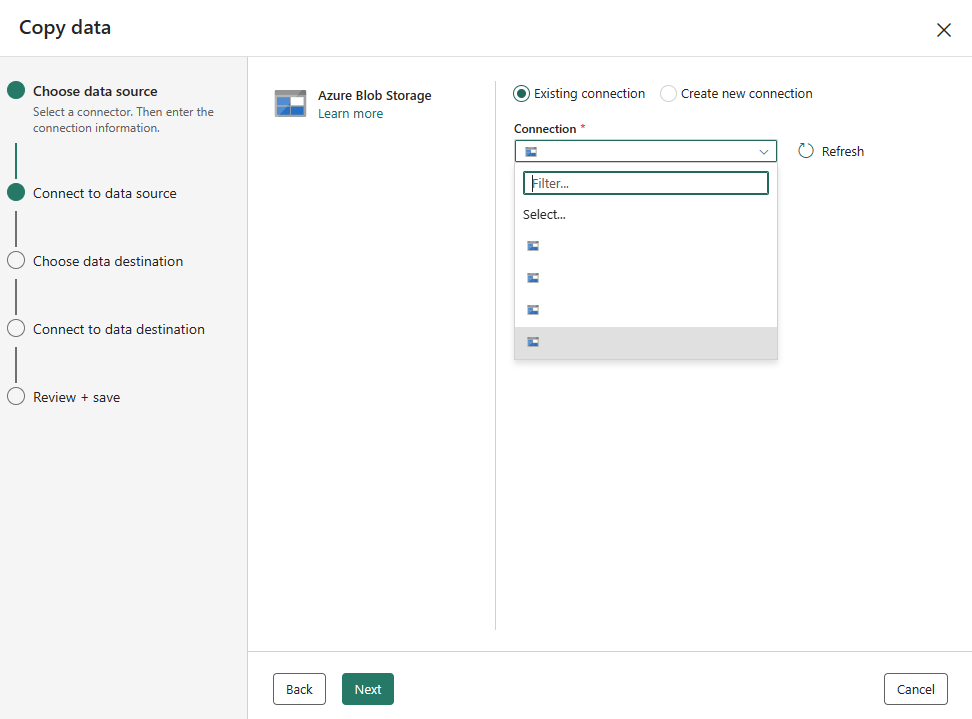
Hvis du allerede har forbindelser, kan du vælge Eksisterende forbindelse og vælge din forbindelse på rullelisten.
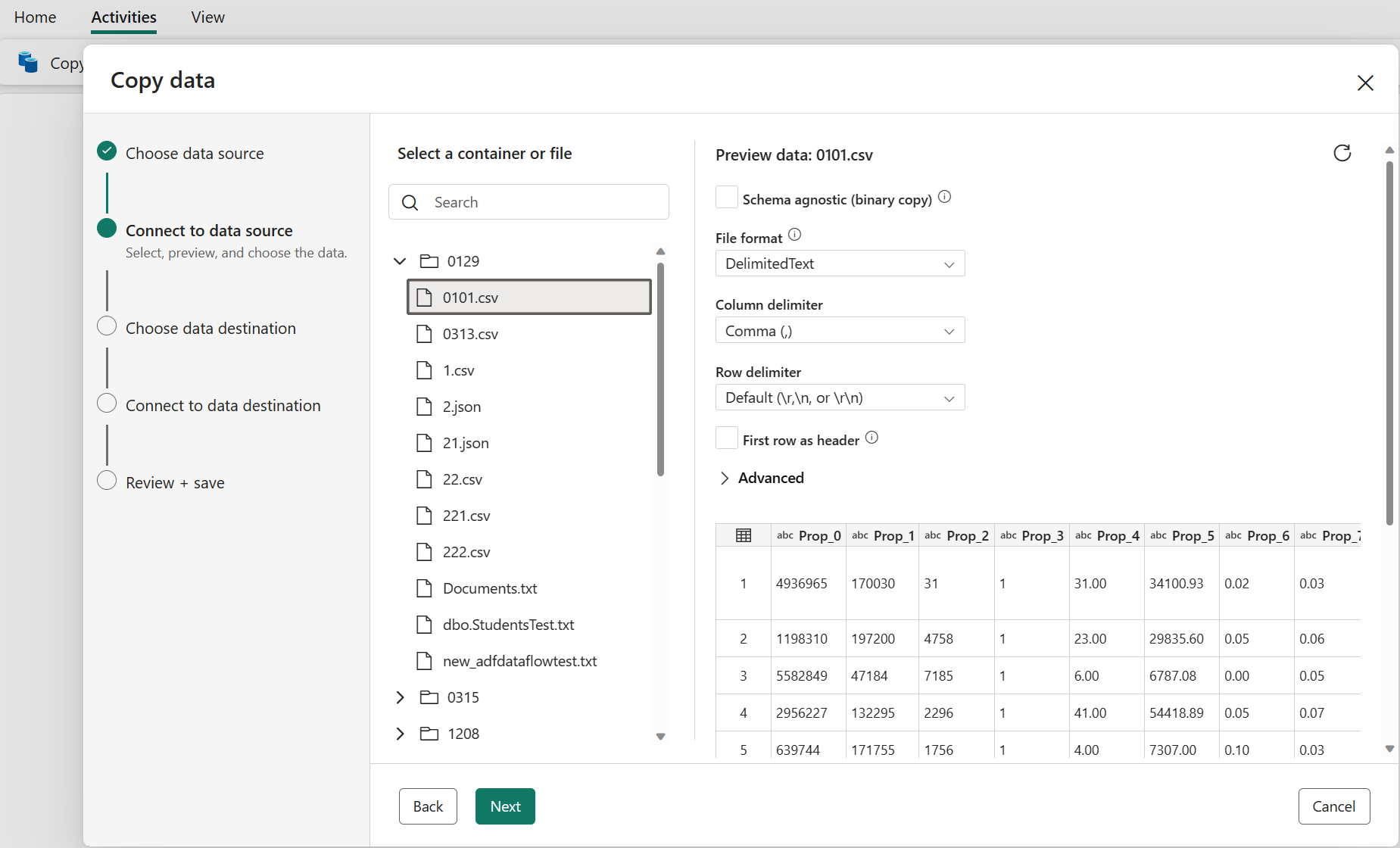
Vælg den fil eller mappe, der skal kopieres, i dette kildekonfigurationstrin, og vælg derefter Næste.




Konfigurer din destination
Vælg en datakildetype i kategorien. Du skal bruge Azure Blob Storage som eksempel. Du kan enten oprette en ny forbindelse, der linker til en ny Azure Blob Storage-konto, ved at følge trinnene i forrige afsnit eller bruge en eksisterende forbindelse fra rullelisten forbindelse. Funktionerne Test forbindelse og Rediger er tilgængelige for hver valgt forbindelse.
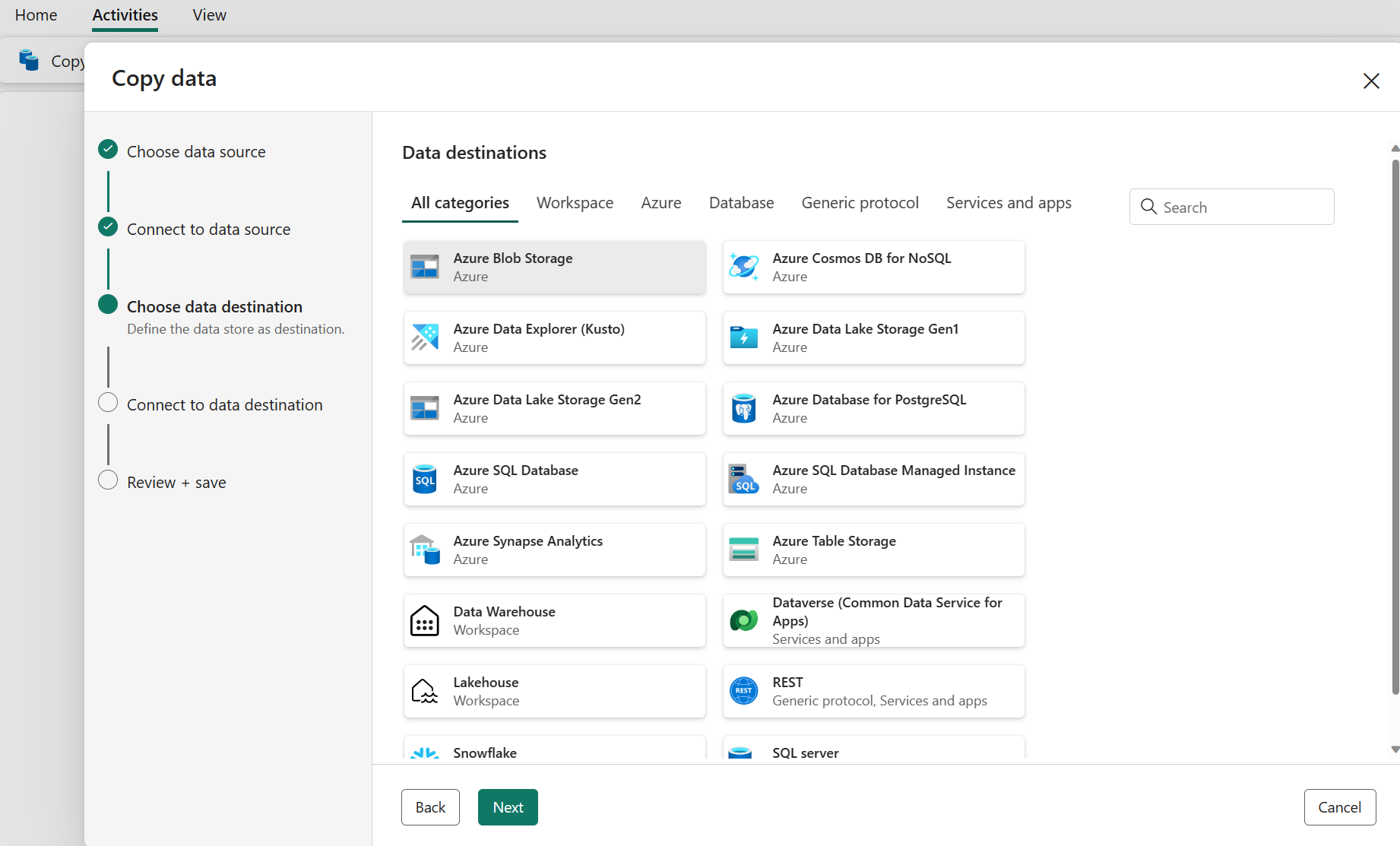
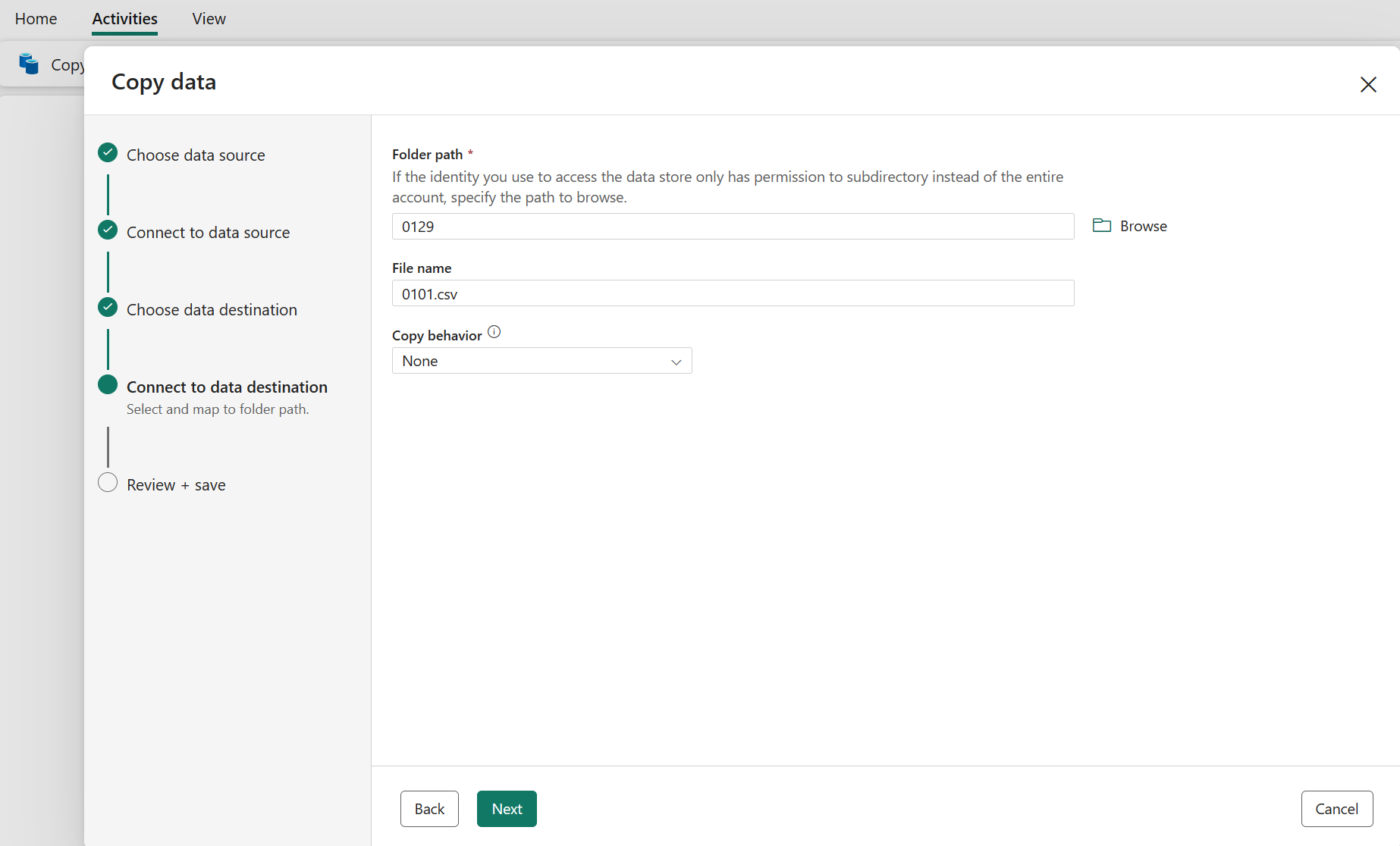
Konfigurer og knyt kildedataene til destinationen. Vælg derefter Næste for at afslutte dine destinationskonfigurationer.

Note
Du kan kun bruge en enkelt datagateway i det lokale miljø inden for den samme kopiaktivitet. Hvis både kilde og vask er datakilder i det lokale miljø, skal de bruge den samme gateway. Hvis du vil flytte data mellem datakilder i det lokale miljø med forskellige gateways, skal du kopiere ved hjælp af den første gateway til en mellemliggende cloudkilde i én kopiaktivitet. Derefter kan du bruge en anden kopiaktivitet til at kopiere den fra den mellemliggende cloudkilde ved hjælp af den anden gateway.



Gennemse og opret din kopiaktivitet
Gennemse dine indstillinger for kopieringsaktivitet i de forrige trin, og vælg OK for at afslutte. Du kan også gå tilbage til de forrige trin for at redigere dine indstillinger, hvis det er nødvendigt i værktøjet.
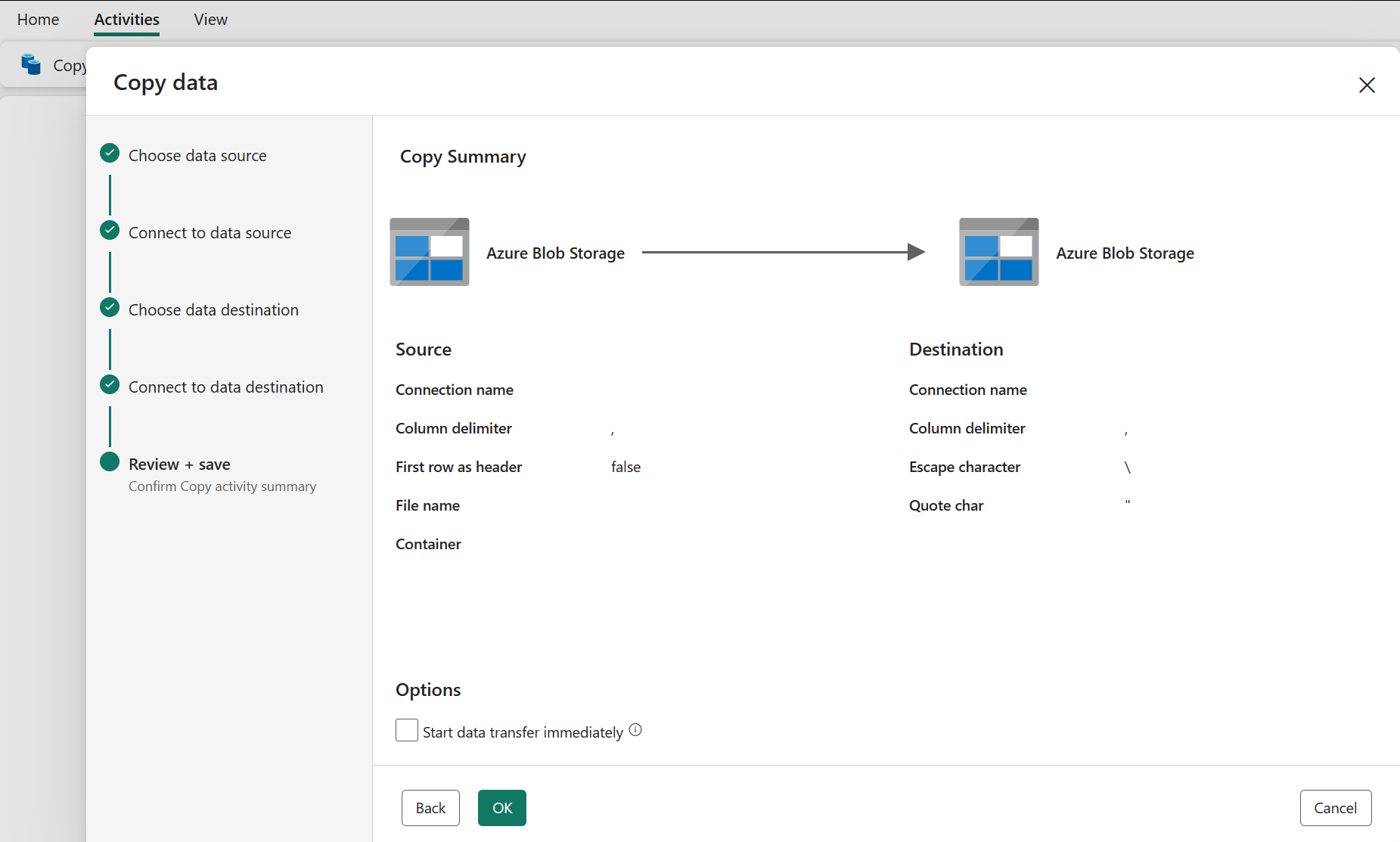

Når du er færdig, føjes kopiaktiviteten til dit pipelinelærred. Alle indstillinger, herunder avancerede indstillinger for denne kopiaktivitet, er tilgængelige under fanerne, når den er valgt.

Nu kan du enten gemme din pipeline med denne enkelt kopiaktivitet eller fortsætte med at designe din pipeline.
Tilføj en kopiaktivitet direkte
Følg disse trin for at tilføje en kopiaktivitet direkte.
Tilføj en kopiaktivitet
Åbn en eksisterende pipeline, eller opret en ny pipeline.
Tilføj en kopiaktivitet ved enten at vælge Tilføj pipelineaktivitet>Kopiér aktivitet eller ved at vælge Kopiér data>Føj til lærredetunder fanen Aktiviteter.
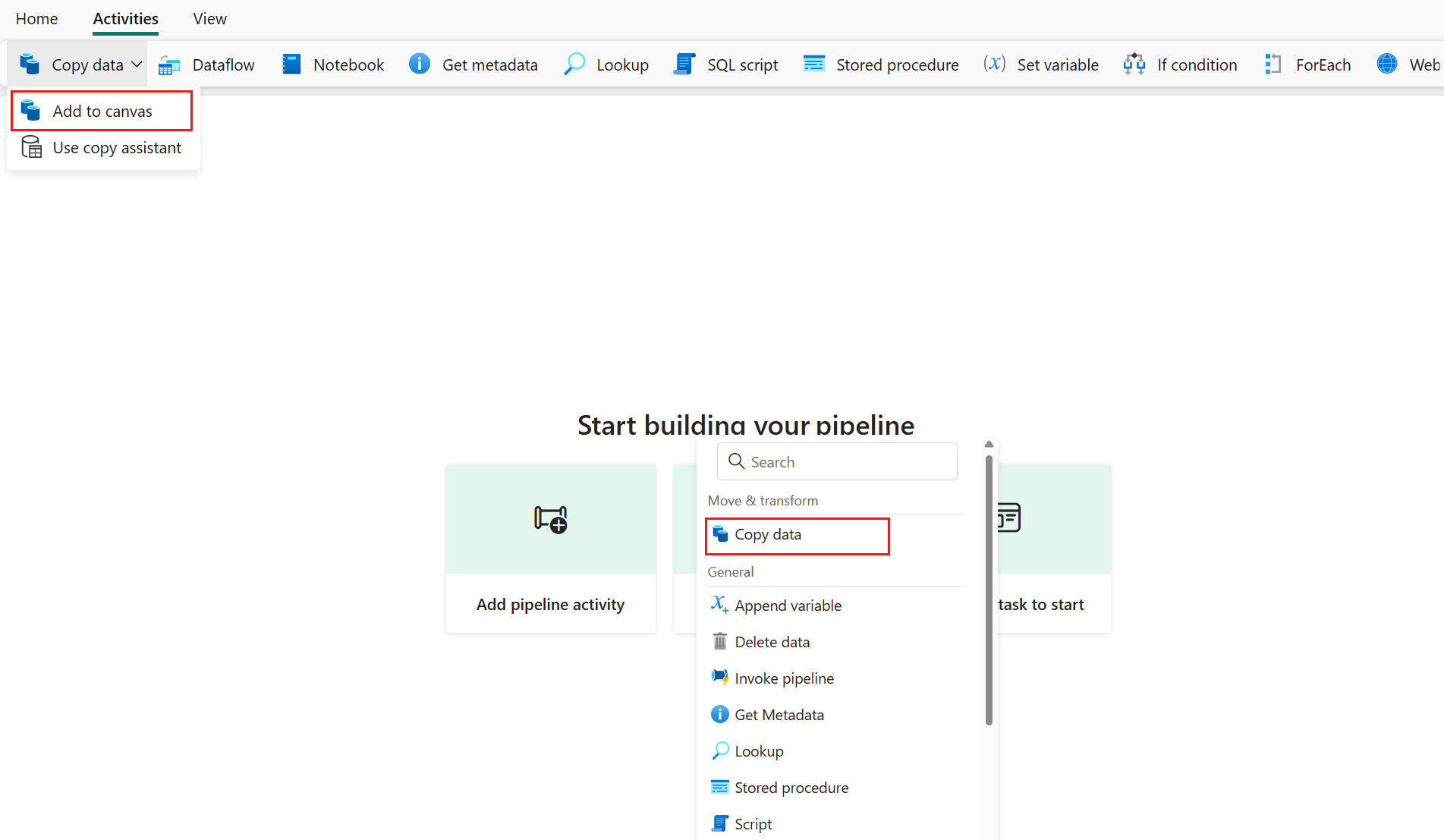

Konfigurer dine generelle indstillinger under fanen Generelt
Du kan få mere at vide om, hvordan du konfigurerer dine generelle indstillinger, under Generelt.
Konfigurer din kilde under kildefanen
Vælg en eksisterende forbindelse i Forbindelse, eller vælg Mere for at oprette en ny forbindelse.
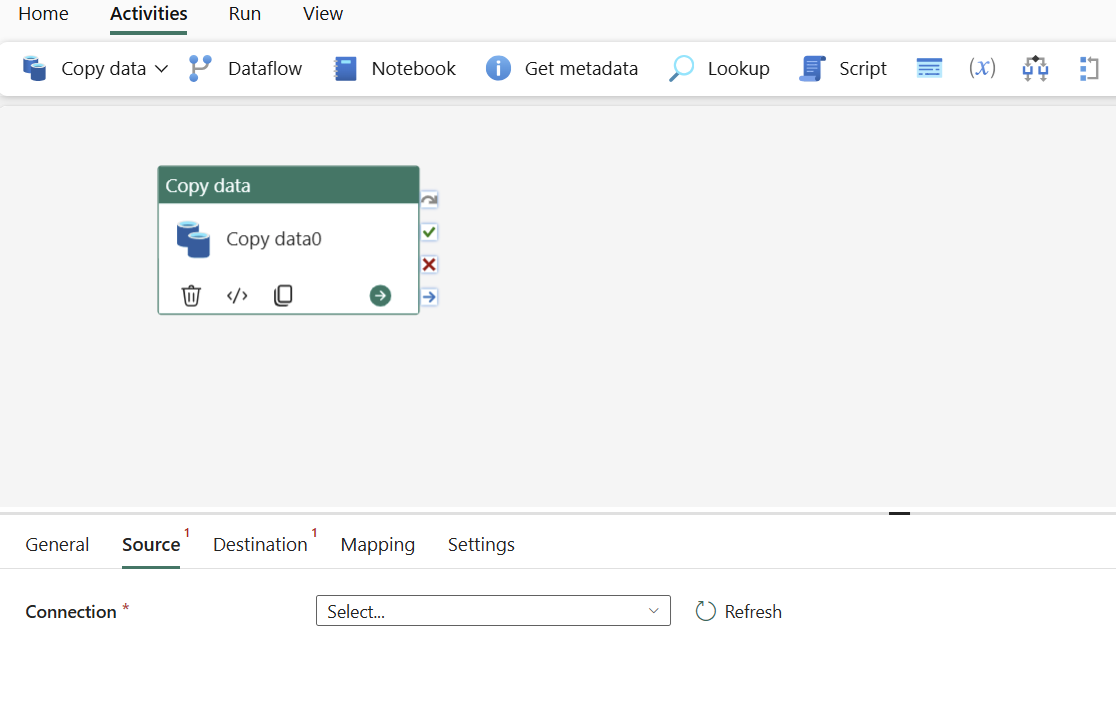
Vælg datakildetypen i pop op-vinduet. Du skal bruge Azure SQL Database som et eksempel. Vælg Azure SQL Database, og vælg derefter Fortsæt.
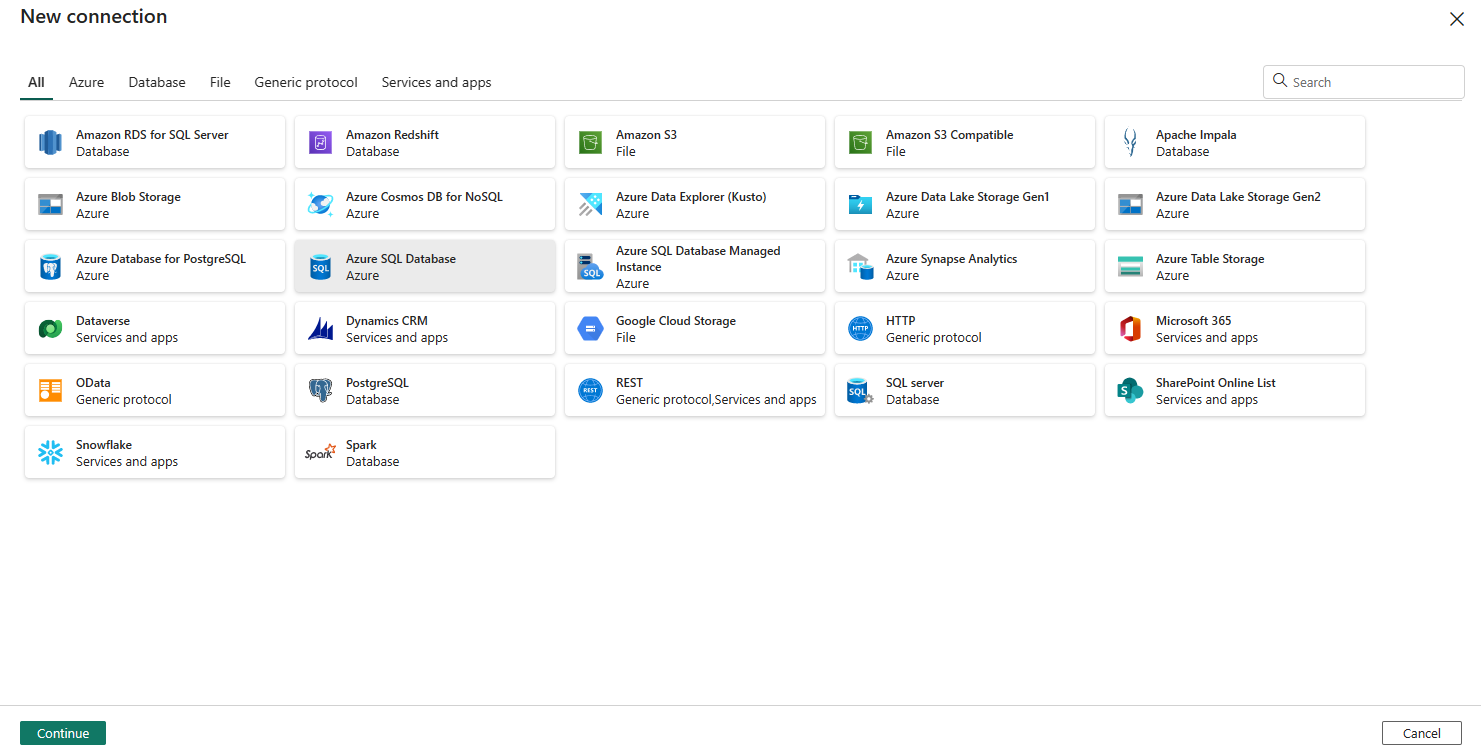
Den navigerer til siden til oprettelse af forbindelse. Udfyld de påkrævede forbindelsesoplysninger i panelet, og vælg derefter Opret. Du kan finde flere oplysninger om oprettelse af forbindelse for hver type datakilde i hver connectorartikel.
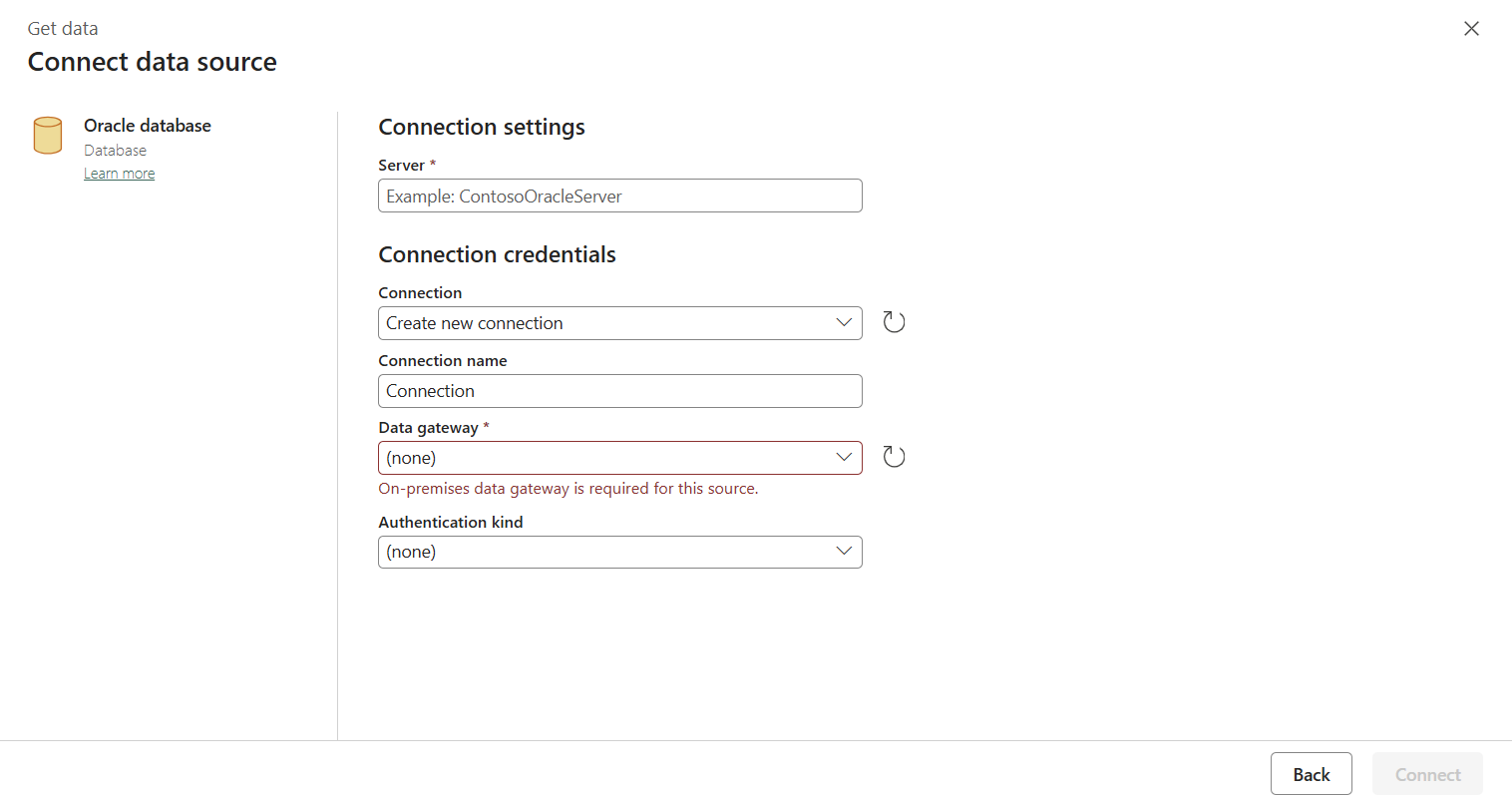
Når forbindelsen er oprettet, fører den dig tilbage til pipelinesiden. Vælg derefter Opdater for at hente den forbindelse, du har oprettet, på rullelisten. Du kan også vælge en eksisterende Azure SQL Database-forbindelse direkte fra rullelisten, hvis du allerede har oprettet den før. Funktionerne Test forbindelse og Rediger er tilgængelige for hver valgt forbindelse. Vælg derefter Azure SQL Database i Forbindelsestype .
Angiv en tabel, der skal kopieres. Vælg Vis data for at få vist kildetabellen. Du kan også bruge Forespørgsel og Gemt procedure til at læse data fra kilden.
Udvid Avanceret for at få mere avancerede indstillinger som timeout for forespørgsler eller partitionering. Avancerede indstillinger varierer afhængigt af connectoren.



Konfigurer din destination under fanen Destination
Vælg en eksisterende forbindelse i Forbindelse , eller vælg Mere for at oprette en ny forbindelse. Det kan enten være dit interne førsteklasses datalager fra dit arbejdsområde, f.eks. Lakehouse, eller dine eksterne datalagre. I dette eksempel bruger vi Lakehouse.
Når forbindelsen er oprettet, fører den dig tilbage til pipelinesiden. Vælg derefter Opdater for at hente den forbindelse, du har oprettet, på rullelisten. Du kan også vælge en eksisterende Lakehouse-forbindelse direkte fra rullemenuen, hvis du allerede har oprettet den før.
Angiv en tabel, eller konfigurer filstien for at definere filen eller mappen som destination. Vælg her Tabeller , og angiv en tabel til at skrive data.
Udvid Avanceret for at få mere avancerede indstillinger, f.eks. maks. antal rækker pr. fil eller tabelhandling. Avancerede indstillinger varierer afhængigt af connectoren.
Nu kan du enten gemme din pipeline med denne kopieringsaktivitet eller fortsætte med at designe din pipeline.
Konfigurer dine tilknytninger under tilknytningsfanen
Hvis den connector, du bruger, understøtter tilknytning, kan du gå til fanen Tilknytning for at konfigurere din tilknytning.
Vælg Importér skemaer for at importere dit dataskema.
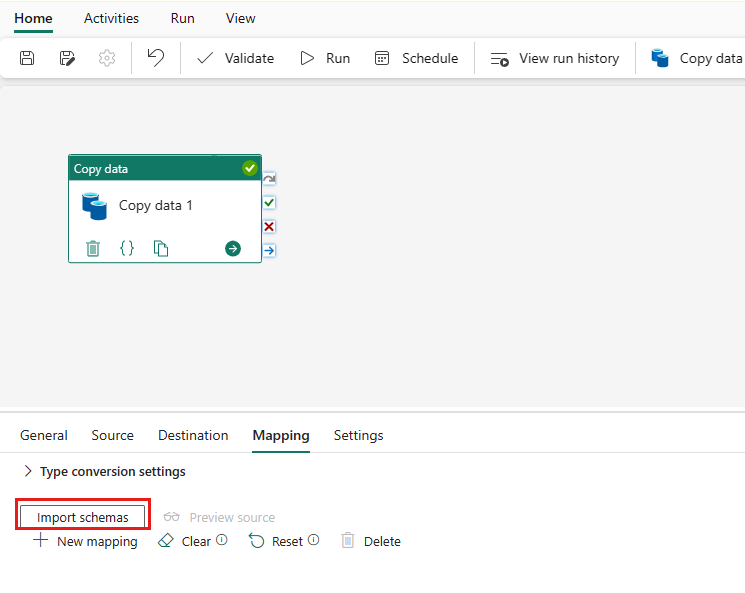
Du kan se, at den automatiske tilknytning vises. Angiv kolonnen Kilde og Destination . Hvis du opretter en ny tabel i destinationen, kan du tilpasse navnet på din destinationskolonne her. Hvis du vil skrive data til den eksisterende destinationstabel, kan du ikke ændre det eksisterende navn på destinationskolonnen . Du kan også få vist kolonnerne Type af kilde og destination.
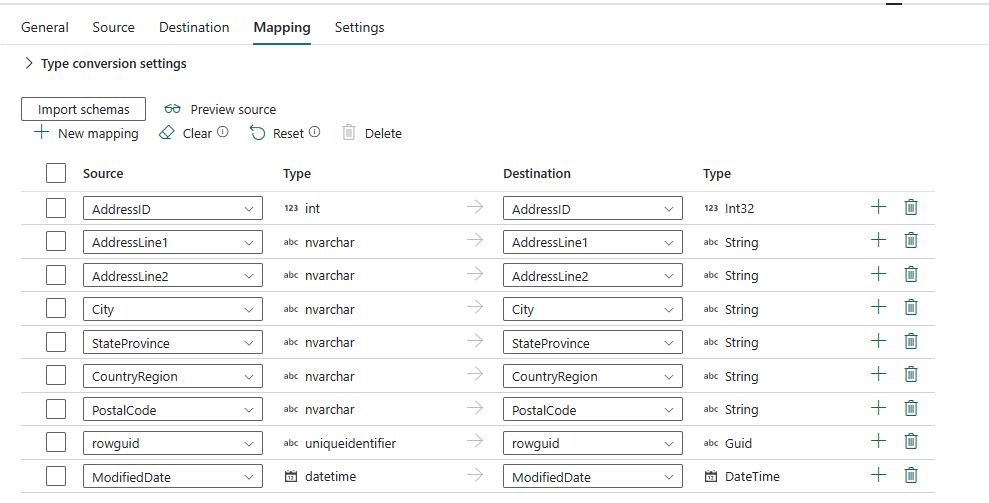


Du kan også vælge + Ny tilknytning for at tilføje ny tilknytning, vælge Ryd for at rydde alle tilknytningsindstillinger og vælge Nulstil for at nulstille kolonnen Kilde .
Datatypetilknytning
Kopiér aktivitet i pipelines og Kopiér job udfør kildetyper til tilknytning af destinationstyper med følgende flow:
- Konverter fra kildebaserede datatyper til midlertidige datatyper, der bruges af Fabric Data Factory.
- Konverter automatisk midlertidig datatype efter behov, så den matcher de tilsvarende destinationstyper.
- Konverter fra midlertidige datatyper til oprindelige destinationsdatatyper.
Kopiaktivitet i pipelines og kopijob understøtter i øjeblikket følgende midlertidige datatyper: Boolesk, Byte, Byte-matrix, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 og UInt64.
Følgende datatypekonverteringer understøttes mellem de midlertidige typer fra kilde til destination.
| Kilde\Destination | Boolean | Byte-matrix | dato og klokkeslæt | Decimal | Flydende punkt | GUID | Integer | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | |||||
| Byte-matrix | ✓ | ✓ | |||||||
| dato og klokkeslæt | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| Flydende punkt | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) Dato/klokkeslæt omfatter DateTime, DateTimeOffset, Dato og klokkeslæt.
(2) Float-point omfatter enkelt og dobbelt.
(3) Heltal omfatter SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 og UInt64.
Hvis du vil vide de detaljerede datatypekonverteringer for en bestemt connector, skal du gå til artiklen Kopier aktivitetskonfiguration for den pågældende connector herfra.
Note
I øjeblikket understøttes en sådan datatypekonvertering ved kopiering mellem tabeldata. Hierarkiske kilder/destinationer understøttes ikke, hvilket betyder, at der ikke er nogen systemdefineret datatypekonvertering mellem midlertidige kilde- og destinationstyper.
Konfigurer dine andre indstillinger under fanen Indstillinger
Fanen Indstillinger indeholder indstillingerne for ydeevne, iscenesættelse osv.

Se følgende tabel for at få en beskrivelse af hver indstilling.
| Setting | Description | JSON-scriptegenskab |
|---|---|---|
| Intelligent optimering af dataoverførselshastighed | Angiv for at optimere gennemløbet. Du kan vælge mellem: • Bil • Standard • Afbalanceret • Maksimum Når du vælger Automatisk, anvendes den optimale indstilling dynamisk baseret på kilde-destinationsparret og datamønsteret. Du kan også tilpasse din gennemstrømning, og brugerdefineret værdi kan være 4-256, mens højere værdi indebærer større gevinster. |
dataIntegrationUnits |
| Graden af kopi parallelitet | Angiv, hvor meget parallelitet dataindlæsningen skal bruge. | parallelCopies |
| Adaptiv ydelsesjustering (Forhåndsvisning) | Angiv, om tjenesten kan anvende ydelsesoptimeringer og tuning i henhold til den brugerdefinerede konfiguration. | adaptivPerformanceTuning |
| Datakonsistensverifikation | Hvis du sætter true for denne egenskab, vil kopieringsaktiviteten ved kopiering af binære filer tjekke filstørrelse, lastModifiedDate og kontrolsum for hver binær fil, der kopieres fra kilde til destinationsbutik for at sikre datakonsistens mellem kilde- og destinationslager. Når tabeldata kopieres, vil kopieringsaktiviteten kontrollere det samlede antal rækker efter jobafslutning, hvilket sikrer, at det samlede antal rækker læst fra kilden er det samme som antallet af rækker kopieret til destinationen plus antallet af inkompatible rækker, der blev sprunget over. Vær opmærksom på, at kopieringsydelsen påvirkes ved at aktivere denne mulighed. |
validateDataConsistency |
| Fejltolerance | Når du vælger denne indstilling, kan du ignorere nogle fejl, der opstår midt i kopiprocessen. Inkompatible rækker mellem kilde- og destinationslager, fil, der slettes under dataflytning osv. | • aktivereSkipIncompatibleRow • skipErrorFile: fileMissing fileForbidden invalidFileName |
| Aktiver logføring | Når du vælger denne indstilling, kan du logge kopierede filer, springe filer og rækker over. | / |
| Aktiver iscenesættelse | Angiv, om data skal kopieres via et midlertidigt midlertidigt lagringslager. Aktivér kun midlertidig lagring i nyttige scenarier. | enableStaging |
| Til arbejdsområde | ||
| Workspace | Angiv, at der skal bruges indbygget lagring af midlertidig lagring. Sørg for, at den sidst ændrede bruger for pipelinen har mindst en bidragyderrolle tildelt i arbejdsområdet. | / |
| Til ekstern | ||
| Midlertidig kontoforbindelse | Angiv forbindelsen til et Azure Blob Storage eller Azure Data Lake Storage Gen2, som refererer til den forekomst af Storage, som du bruger som et midlertidigt midlertidig lagringslager. Opret en midlertidig forbindelse, hvis du ikke har den. | forbindelse (under externalReferences) |
| Lagersti | Angiv den sti, du vil indeholde de faselagrede data. Hvis du ikke angiver en sti, opretter tjenesten en objektbeholder til lagring af midlertidige data. Angiv kun en sti, hvis du bruger Storage med en signatur for delt adgang, eller du har brug for midlertidige data for at være på en bestemt placering. | sti |
| Aktiver komprimering | Angiver, om data skal komprimeres, før de kopieres til destinationen. Denne indstilling reducerer mængden af data, der overføres. | enableCompression |
| Preserve | Angiv, om metadata/ACL'er skal bevares under datakopien. | preserve |
Note
Hvis du bruger faseinddelt kopi med komprimering aktiveret, understøttes godkendelse af tjenesteprincipalen for midlertidig blobforbindelse ikke.
Note
Workspace staging går ud efter 60 minutter. Til langvarige opgaver anbefales det at bruge ekstern lagring til staging.
Konfigurer parametre i en kopiaktivitet
Parametre kan bruges til at styre funktionsmåden for en pipeline og dens aktiviteter. Du kan bruge Tilføj dynamisk indhold til at angive parametre for dine egenskaber for kopiaktivitet. Lad os tage angivelse af Lakehouse/data warehouse som et eksempel for at se, hvordan du bruger det.
I din kilde eller destination skal du vælge Brug dynamisk indhold på rullelisten for Forbindelse.
Vælg under fanen Parametre i ruden Tilføj dynamisk indhold+.
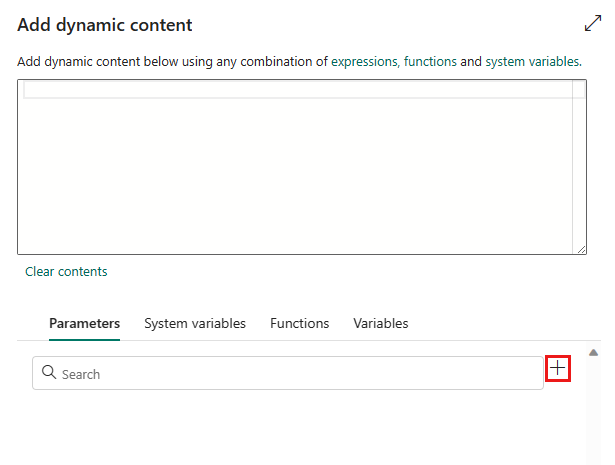
Angiv navnet på parameteren, og giv den en standardværdi, hvis du vil, eller du kan angive værdien for parameteren, når den udløses i pipelinen.

Parameterværdien skal være Lakehouse/data warehouse-forbindelses-id. Du kan hente den ved at åbne Administrer forbindelser og gateways, vælge den Lakehouse/data warehouse-forbindelse, du vil bruge, og åbne Indstillinger for at få dit forbindelses-id. Hvis du vil oprette en ny forbindelse, kan du vælge + Ny på denne side eller gå til siden Hent data via rullelisten Forbindelse .
Vælg Gem for at gå tilbage til ruden Tilføj dynamisk indhold . Vælg derefter din parameter, så den vises i udtryksfeltet. Vælg derefter OK. Du går tilbage til pipelinesiden og kan se, at parameterudtrykket er angivet efter Forbindelse.
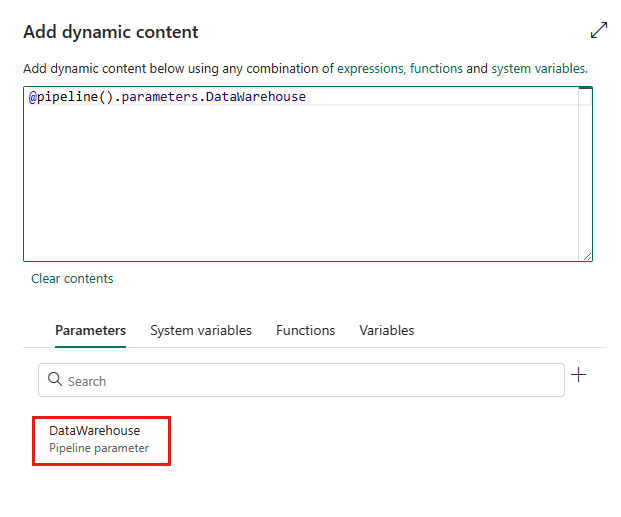
Angiv id'et for dit Lakehouse eller data warehouse. Du kan finde id'et ved at gå til dit Lakehouse eller data warehouse i dit arbejdsområde. Id'et vises i URL-adressen efter
/lakehouses/eller/datawarehouses/.Lakehouse ID:

Lager-id:
