Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Vigtigt
Dette er et mønster til trinvist at samle data med Dataflow Gen2. Dette er ikke det samme som trinvis opdatering. Trinvis opdatering er en funktion, der i øjeblikket er under udvikling. Denne funktion er en af de mest populære ideer på vores idéer hjemmeside. Du kan stemme på denne funktion på Fabric Ideas-webstedet.
Dette selvstudium tager 15 minutter og beskriver, hvordan data samles trinvist i et lakehouse ved hjælp af Dataflow Gen2.
Trinvist at samle data i en datadestination kræver en teknik til kun at indlæse nye eller opdaterede data i din datadestination. Denne teknik kan gøres ved hjælp af en forespørgsel til at filtrere dataene baseret på datadestinationen. I dette selvstudium kan du se, hvordan du opretter et dataflow for at indlæse data fra en OData-kilde i et lakehouse, og hvordan du føjer en forespørgsel til dataflowet for at filtrere dataene baseret på datadestinationen.
Trinnene på højt niveau i dette selvstudium er som følger:
- Opret et dataflow for at indlæse data fra en OData-kilde i et lakehouse.
- Føj en forespørgsel til dataflowet for at filtrere dataene baseret på datadestinationen.
- (Valgfrit) genindlæs data ved hjælp af notesbøger og pipelines.
Forudsætninger
Du skal have et Microsoft Fabric-aktiveret arbejdsområde. Hvis du ikke allerede har et, skal du se Opret et arbejdsområde. I selvstudiet forudsættes det også, at du bruger diagramvisningen i Dataflow Gen2. Hvis du vil kontrollere, om du bruger diagramvisningen, skal du gå til Vis på det øverste bånd og sørge for, at diagramvisning er valgt.
Opret et dataflow for at indlæse data fra en OData-kilde i et lakehouse
I dette afsnit skal du oprette et dataflow for at indlæse data fra en OData-kilde i et lakehouse.
Opret et nyt lakehouse i dit arbejdsområde.
Opret et nyt Dataflow Gen2 i dit arbejdsområde.
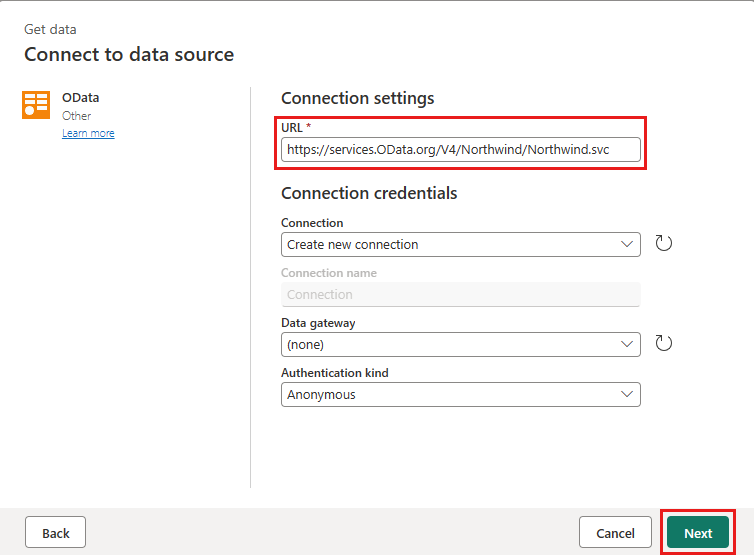
Føj en ny kilde til dataflowet. Vælg OData-kilden, og angiv følgende URL-adresse:
https://services.OData.org/V4/Northwind/Northwind.svc
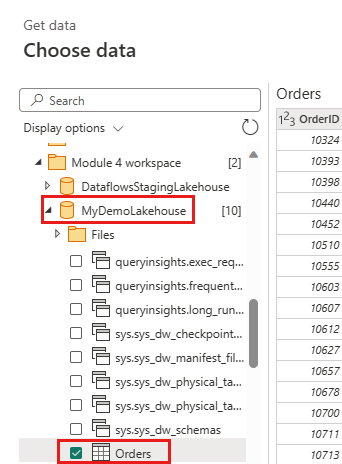
Vælg tabellen Orders, og vælg Næste.
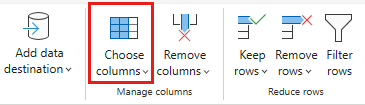
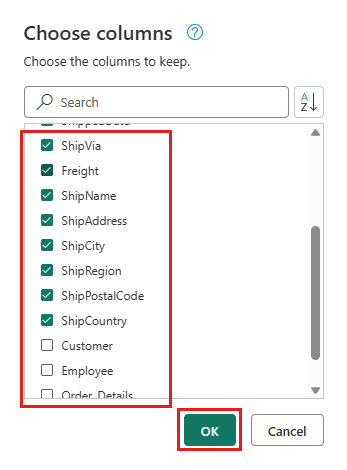
Vælg følgende kolonner, der skal bevares:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
Skift datatypen for
OrderDate,RequiredDateogShippedDatetildatetime.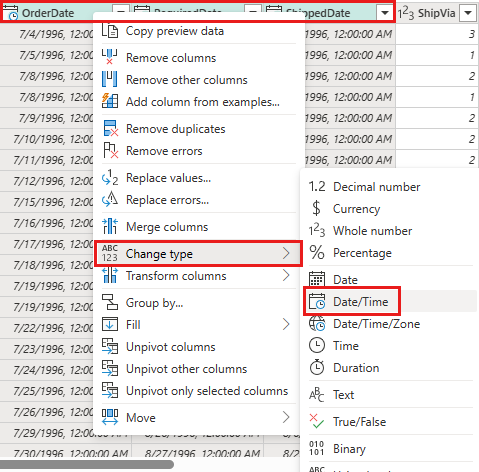
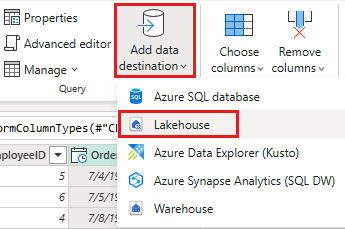
Konfigurer datadestinationen til dit lakehouse ved hjælp af følgende indstillinger:
- Datadestination:
Lakehouse - Lakehouse: Vælg det lakehouse, du oprettede i trin 1.
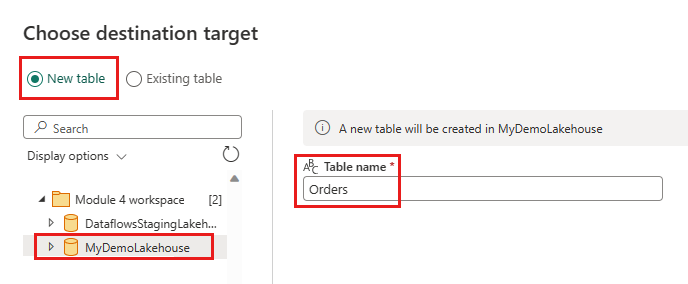
- Nyt tabelnavn:
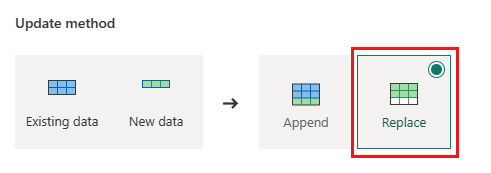
Orders - Opdateringsmetode:
Replace
- Datadestination:
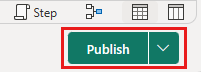
vælg Næste , og publicer dataflowet.



Du har nu oprettet et dataflow for at indlæse data fra en OData-kilde i et lakehouse. Dette dataflow bruges i næste afsnit til at føje en forespørgsel til dataflowet for at filtrere dataene baseret på datadestinationen. Derefter kan du bruge dataflowet til at genindlæse data ved hjælp af notesbøger og pipelines.
Føj en forespørgsel til dataflowet for at filtrere dataene baseret på datadestinationen
I dette afsnit føjes der en forespørgsel til dataflowet for at filtrere dataene baseret på dataene i destinationssøhuset. Forespørgslen får det maksimale antal OrderID i lakehouse i starten af opdateringen af dataflowet og bruger det maksimale OrderId til kun at hente ordrerne med et højere OrderId fra til kilde for at føje til din datadestination. Dette forudsætter, at ordrer føjes til kilden i stigende rækkefølge af OrderID. Hvis det ikke er tilfældet, kan du bruge en anden kolonne til at filtrere dataene. Du kan f.eks. bruge kolonnen OrderDate til at filtrere dataene.
Bemærk
OData-filtre anvendes i Fabric, når dataene er modtaget fra datakilden, men for databasekilder som SQL Server anvendes filteret i den forespørgsel, der sendes til backenddatakilden, og kun filtrerede rækker returneres til tjenesten.
Når dataflowet er opdateret, skal du åbne det dataflow, du oprettede i forrige afsnit, igen.
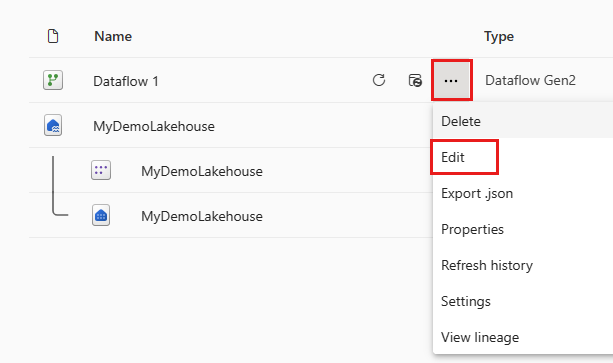
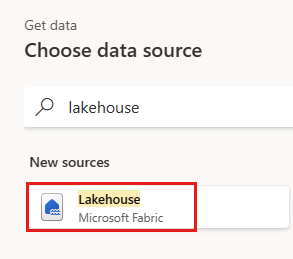
Opret en ny forespørgsel med navnet
IncrementalOrderID, og hent data fra tabellen Orders i det lakehouse, du oprettede i forrige afsnit.
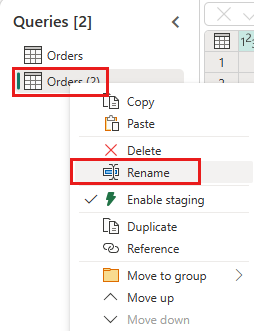
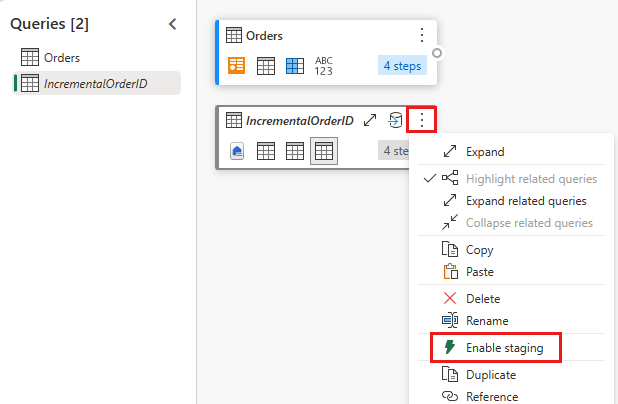
Deaktiver midlertidig lagring af denne forespørgsel.
Højreklik på kolonnen
OrderIDi dataeksemplet, og vælg Analysér ned.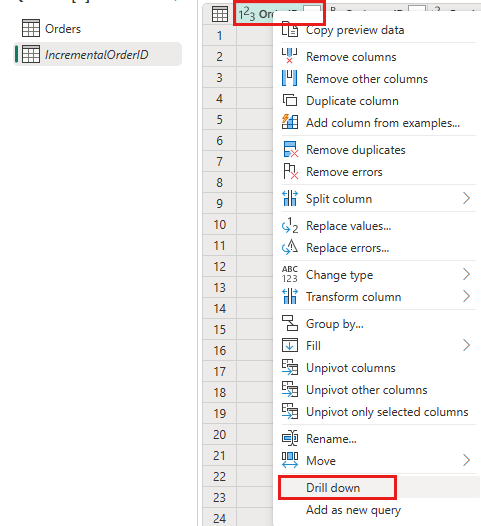
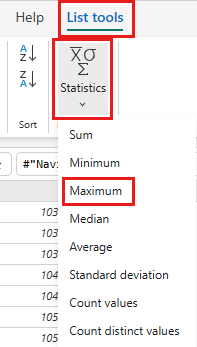
På båndet skal du vælge Listeværktøjer ->Statistik ->Maksimum.
Du har nu en forespørgsel, der returnerer det maksimale OrderID i lakehouse. Denne forespørgsel bruges til at filtrere dataene fra OData-kilden. I næste afsnit føjes der en forespørgsel til dataflowet for at filtrere dataene fra OData-kilden baseret på det maksimale OrderID i lakehouse.
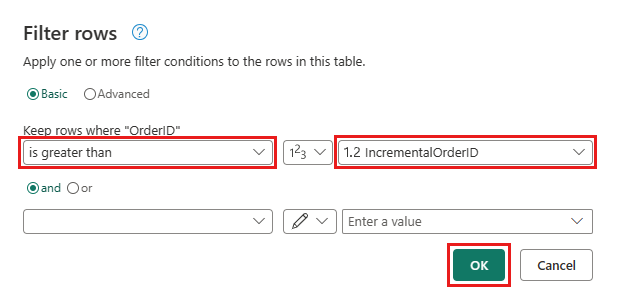
Gå tilbage til forespørgslen Ordrer, og tilføj et nyt trin for at filtrere dataene. Brug følgende indstillinger:
- Kolonne:
OrderID - Operation:
Greater than - Værdi: parameter
IncrementalOrderID

- Kolonne:
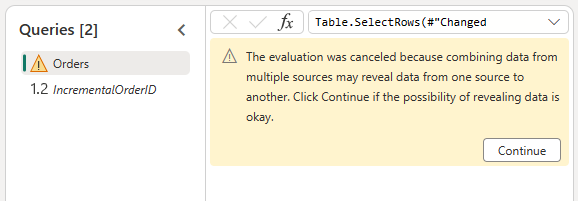
Tillad at kombinere dataene fra OData-kilden og lakehouse ved at bekræfte følgende dialogboks:
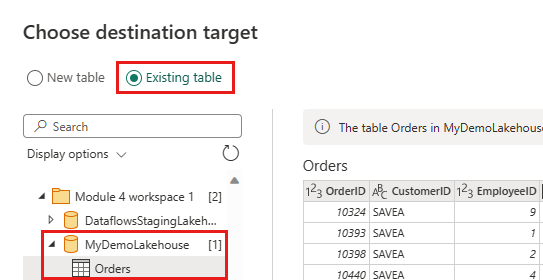
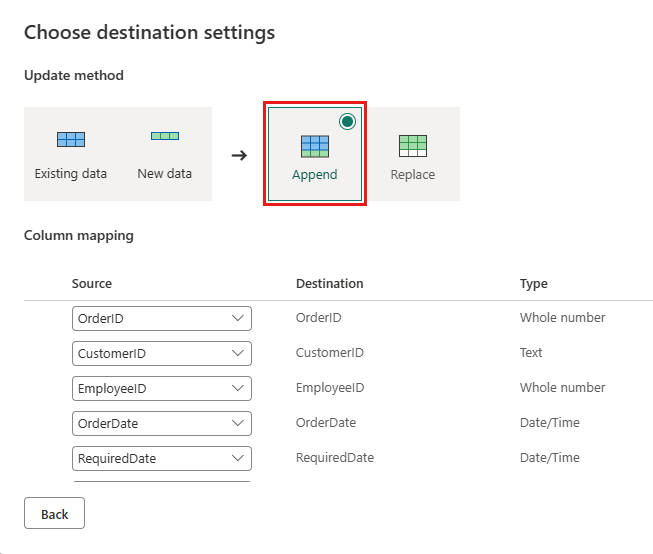
Opdater datadestinationen for at bruge følgende indstillinger:
- Opdateringsmetode:
Append

- Opdateringsmetode:
Publicer dataflowet.
Dit dataflow indeholder nu en forespørgsel, der filtrerer dataene fra OData-kilden baseret på det maksimale OrderID i lakehouse. Det betyder, at det kun er nye eller opdaterede data, der indlæses i lakehouse. I næste afsnit bruges dataflowet til at genindlæse data ved hjælp af notesbøger og pipelines.
(Valgfrit) genindlæs data ved hjælp af notesbøger og pipelines
Du kan eventuelt genindlæse bestemte data ved hjælp af notesbøger og pipelines. Med brugerdefineret pythonkode i notesbogen fjerner du de gamle data fra lakehouse. Når du derefter opretter en pipeline, hvor du først kører notesbogen og kører dataflowet sekventielt, genindlæses dataene fra OData-kilden til lakehouse'et. Notesbøger understøtter flere sprog, men i dette selvstudium bruges PySpark. Pyspark er en Python-API til Spark og bruges i dette selvstudium til at køre Spark SQL-forespørgsler.
Opret en ny notesbog i dit arbejdsområde.
Føj følgende PySpark-kode til din notesbog:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Kør notesbogen for at bekræfte, at dataene er fjernet fra lakehouse.
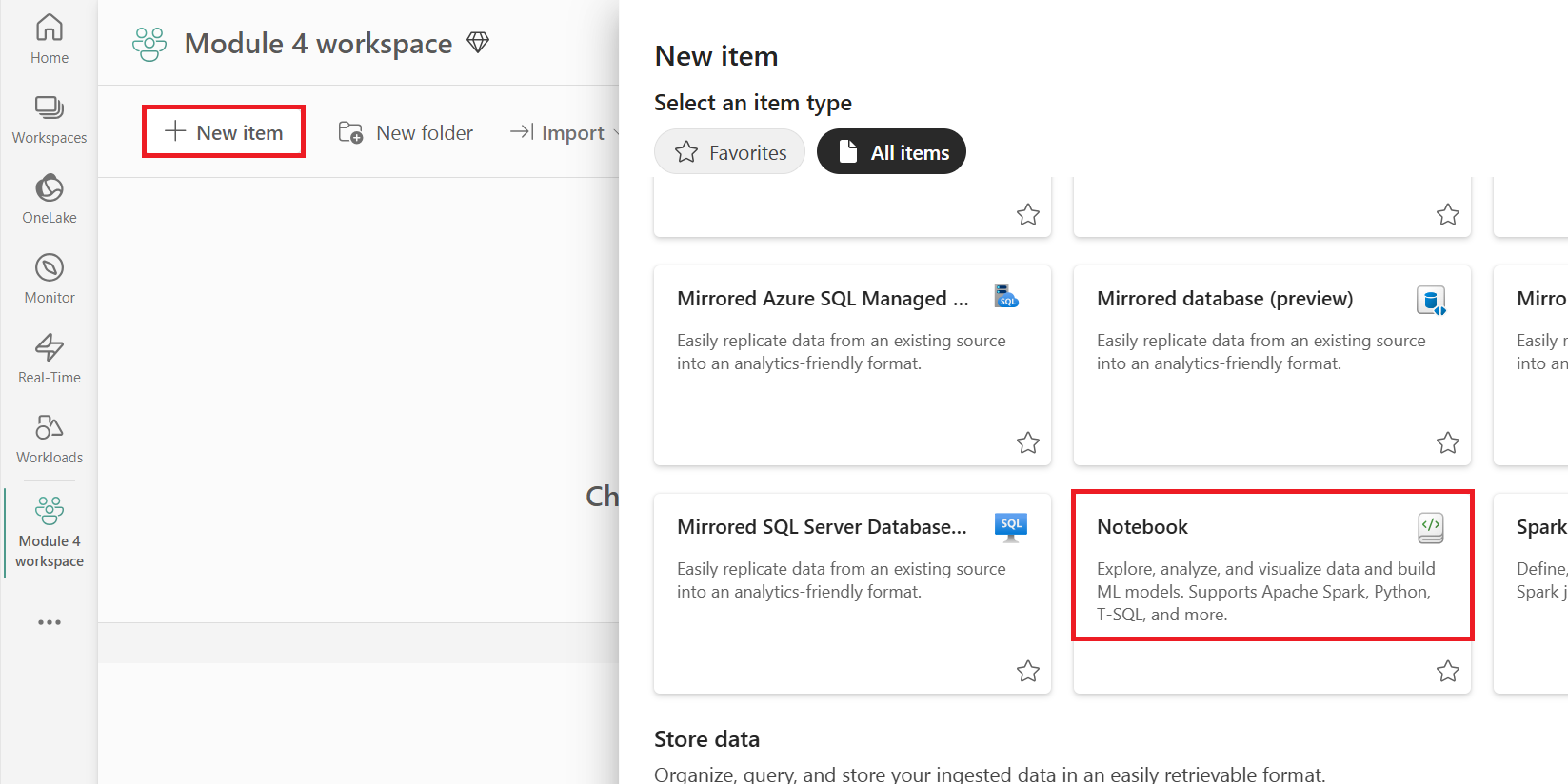
Opret en ny pipeline i dit arbejdsområde.
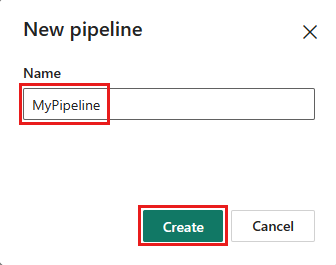
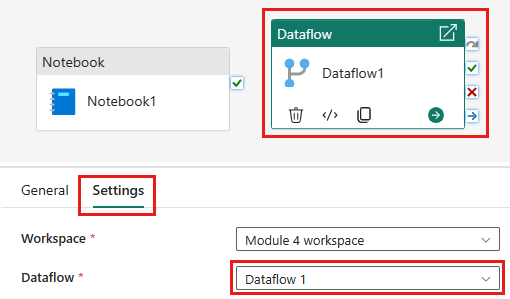
Føj en ny notesbogaktivitet til pipelinen, og vælg den notesbog, du oprettede i det forrige trin.
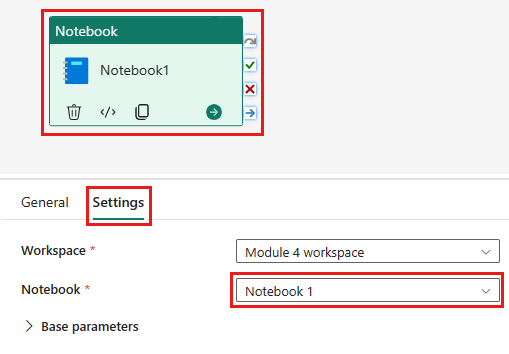
Føj en ny dataflowaktivitet til pipelinen, og vælg det dataflow, du oprettede i forrige afsnit.
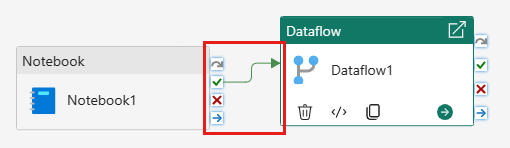
Sammenhold notesbogaktiviteten med dataflowaktiviteten med en succesudløser.
Gem og kør pipelinen.


Du har nu en pipeline, der fjerner gamle data fra lakehouse og genindlæser dataene fra OData-kilden til lakehouse'et. Med denne konfiguration kan du genindlæse dataene fra OData-kilden til lakehouse regelmæssigt.