Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
I dette selvstudium præsenteres et helt til slut-eksempel på en Synapse Data Science-arbejdsproces i Microsoft Fabric. Scenariet opretter en model for at forudsige, om bankkunderne aftager eller ej. Nedslidningssatsen eller nedslidningssatsen omfatter den rente, som bankkunderne afslutter deres forretning med banken til.
I dette selvstudium beskrives disse trin:
- Installér brugerdefinerede biblioteker
- Indlæs dataene
- Forstå og behandl dataene via udforskning af dataanalyser, og vis brugen af funktionen Fabric Data Wrangler
- Brug scikit-learn og LightGBM til at oplære modeller til maskinel indlæring og spore eksperimenter med funktionerne MLflow og Fabric Autologging
- Evaluer og gem den endelige model til maskinel indlæring
- Vis modellens ydeevne med Power BI-visualiseringer
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Microsoft Fabric-prøveversion.
Log på Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

- Opret om nødvendigt et Microsoft Fabric lakehouse som beskrevet i Opret et lakehouse i Microsoft Fabric.
Følg med i en notesbog
Du kan vælge en af disse indstillinger for at følge med i en notesbog:
- Åbn og kør den indbyggede notesbog.
- Upload din notesbog fra GitHub.
Åbn den indbyggede notesbog
Eksemplet Kundeafgang notesbog følger med dette selvstudium.
Hvis du vil åbne eksempelnotesbogen til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Importér notesbogen fra GitHub
Den AIsample – Bank Customer Churn.ipynb notesbog følger med dette selvstudium.
Hvis du vil åbne den medfølgende notesbog til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab importere notesbogen til dit arbejdsområde.
Hvis du hellere vil kopiere og indsætte koden fra denne side, kan du oprette en ny notesbog.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Trin 1: Installér brugerdefinerede biblioteker
I forbindelse med udvikling af modeller til maskinel indlæring eller ad hoc-dataanalyse skal du muligvis hurtigt installere et brugerdefineret bibliotek til din Apache Spark-session. Du har to muligheder for at installere biblioteker.
- Brug de indbyggede installationsegenskaber (
%pipeller%conda) i notesbogen til kun at installere et bibliotek i din aktuelle notesbog. - Du kan også oprette et Fabric-miljø, installere biblioteker fra offentlige kilder eller uploade brugerdefinerede biblioteker til det, og derefter kan administratoren af arbejdsområdet vedhæfte miljøet som standard for arbejdsområdet. Alle biblioteker i miljøet bliver derefter tilgængelige til brug i alle notesbøger og Spark-jobdefinitioner i arbejdsområdet. Du kan få flere oplysninger om miljøer under oprette, konfigurere og bruge et miljø i Microsoft Fabric.
I dette selvstudium skal du bruge %pip install til at installere imblearn-biblioteket i din notesbog.
Seddel
PySpark-kernen genstartes, når %pip install har kørt. Installer de nødvendige biblioteker, før du kører andre celler.
# Use pip to install libraries
%pip install imblearn
Trin 2: Indlæs dataene
Datasættet i churn.csv indeholder status for fald på 10.000 kunder sammen med 14 attributter, der omfatter:
- Kreditscore
- Geografisk placering (Tyskland, Frankrig, Spanien)
- Køn (mand, kvinde)
- Alder
- Ansættelse (antal år, personen var kunde i den pågældende bank)
- Kontosaldo
- Anslået løn
- Antal produkter, som en kunde har købt via banken
- Kreditkortstatus (uanset om en kunde har et kreditkort eller ej)
- Aktiv medlemsstatus (uanset om personen er en aktiv bankkunde eller ej)
Datasættet indeholder også kolonner med rækkenummer, kunde-id og kundenavn. Værdier i disse kolonner bør ikke påvirke en kundes beslutning om at forlade banken.
En hændelse for lukning af debitorbankkonto definerer kundeafgangen. Datasættet Exited kolonne refererer til kundens opgivelse. Da vi har lidt kontekst om disse attributter, behøver vi ikke baggrundsoplysninger om datasættet. Vi vil gerne forstå, hvordan disse attributter bidrager til Exited status.
Af disse 10.000 kunder forlod kun 2037 kunder (ca. 20%) banken. På grund af klasseubalanceforholdet anbefaler vi generering af syntetiske data. Nøjagtigheden af forvirringsmatrixen har muligvis ikke relevans for ubalanceret klassificering. Det kan være en god idé at måle nøjagtigheden ved hjælp af AUPRC (Area Under the Precision-Recall Curve).
- I denne tabel vises et eksempel på de
churn.csvdata:
| Kunde-id | Efternavn | CreditScore | Geografi | Køn | Alder | Embedstid | Saldo | NumOfProducts | HasCrCard | IsActiveMember | Anslåetsalær | Forladt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Frankrig | Kvindelig | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Bakke | 608 | Spanien | Kvindelig | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Download datasættet, og upload det til lakehouse
Definer disse parametre, så du kan bruge denne notesbog med forskellige datasæt:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Denne kode downloader en offentligt tilgængelig version af datasættet og gemmer derefter dette datasæt i et Fabric lakehouse:
Vigtig
Føj et lakehouse- til notesbogen, før du kører den. Hvis du ikke gør det, medfører det en fejl.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Begynd at optage den tid, det kræver at køre notesbogen:
# Record the notebook running time
import time
ts = time.time()
Læs rådata fra lakehouse
Denne kode læser rådata fra afsnittet Filer i lakehouse og tilføjer flere kolonner for forskellige datodele. Oprettelsen af den partitionerede deltatabel bruger disse oplysninger.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Opret en pandas DataFrame fra datasættet
Denne kode konverterer Spark DataFrame til en pandas DataFrame for at gøre det nemmere at behandle og visualisere:
df = df.toPandas()
Trin 3: Udfør udforskning af dataanalyse
Vis rådata
Udforsk rådata med display, beregn nogle grundlæggende statistikker, og vis diagramvisninger. Du skal først importere de påkrævede biblioteker til datavisualisering – f.eks. søfødte. Seaborn er et Python-datavisualiseringsbibliotek, og det giver en grænseflade på højt niveau til oprettelse af visualiseringer på dataframes og matrixer.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Brug Data Wrangler til at udføre indledende datarensning
Start Data Wrangler direkte fra notesbogen for at udforske og transformere pandas-datarammer. Vælg rullelisten Data Wrangler på den vandrette værktøjslinje for at gennemse de aktiverede pandas DataFrames, der er tilgængelige til redigering. Vælg den DataFrame, du vil åbne i Data Wrangler.
Seddel
Data Wrangler kan ikke åbnes, mens notesbogkernen er optaget. Celleudførelsen skal afsluttes, før du starter Data Wrangler. Få mere at vide om Data Wrangler.

Når Data Wrangler startes, oprettes der en beskrivende oversigt over datapanelet, som vist på følgende billeder. Oversigten indeholder oplysninger om dimensionen af DataFrame, eventuelle manglende værdier osv. Du kan bruge Data Wrangler til at generere scriptet til at slippe rækkerne med manglende værdier, de duplikerede rækker og kolonnerne med bestemte navne. Derefter kan du kopiere scriptet til en celle. Den næste celle viser det kopierede script.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Bestem attributter
Denne kode bestemmer kategori-, numeriske og målattributter:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Vis femtalsoversigten
Brug feltafbildninger til at få vist femtalsoversigten
- minimumresultatet
- første kvartil
- median
- tredje kvartil
- maksimumresultat
for de numeriske attributter.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
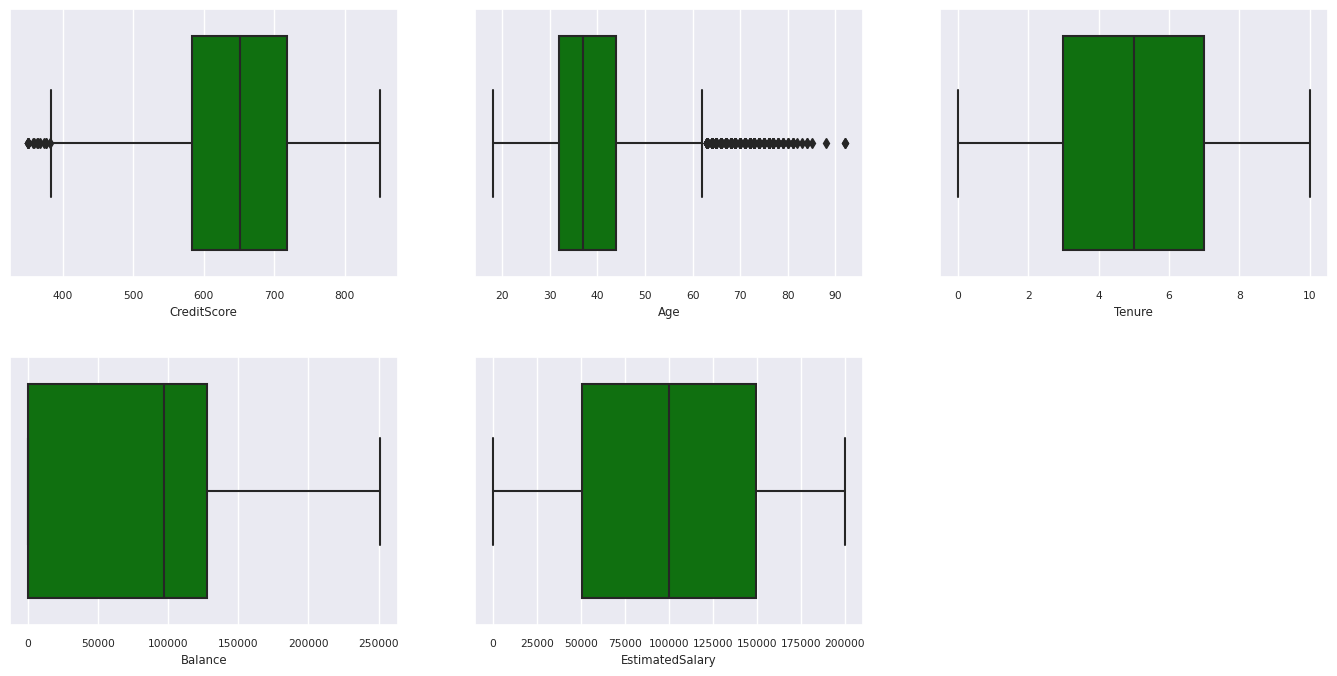
Vis distributionen af afsluttede og ikke-afsluttede kunder
Vis fordelingen af afsluttede kunder i forhold til ikke-afsluttede kunder på tværs af kategoriattributterne:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
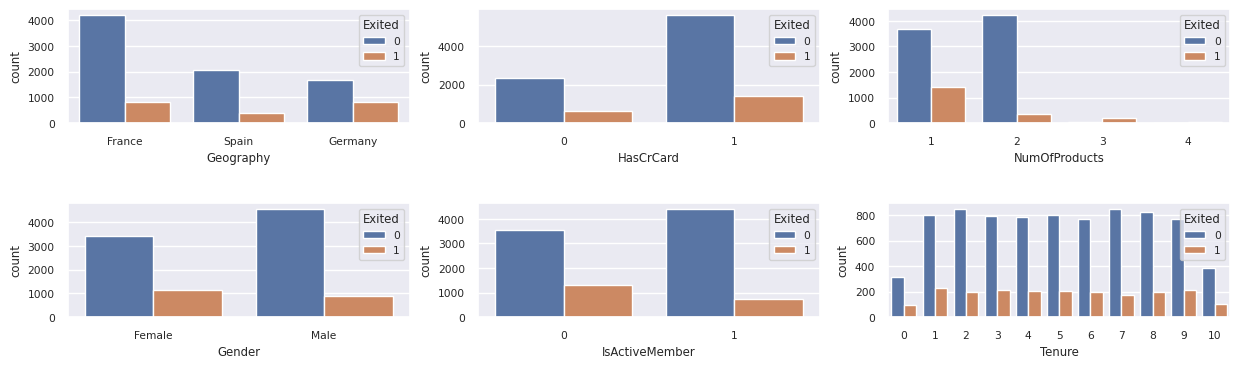
Vis fordelingen af numeriske attributter
Brug et histogram til at få vist frekvensfordelingen af numeriske attributter:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
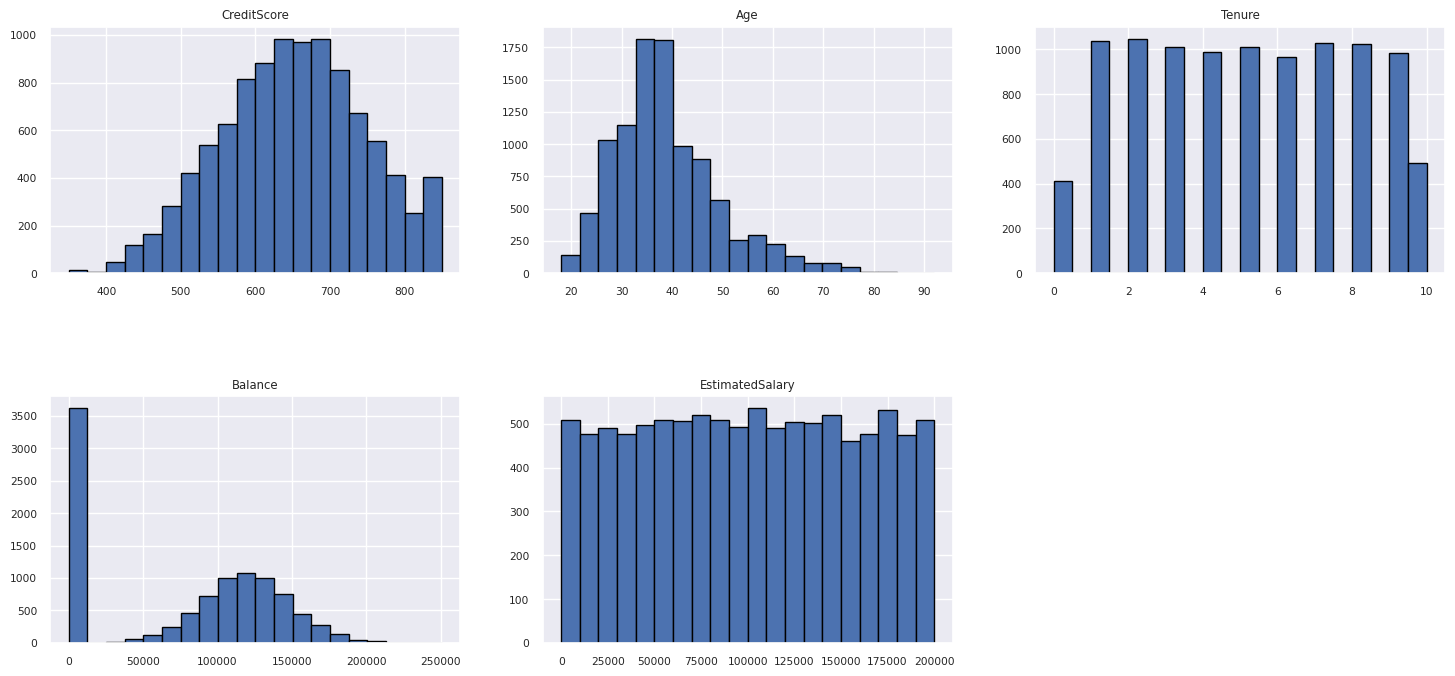
Udfør funktionskonstruktion
Denne funktionskonstruktion genererer nye attributter baseret på de aktuelle attributter:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Brug Data Wrangler til at udføre en-hot-kodning
Med de samme trin til at starte Data Wrangler, som beskrevet tidligere, kan du bruge Data Wrangler til at udføre en-hot kodning. I denne celle vises det kopierede genererede script til en-hot-kodning:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Opret en deltatabel for at generere Power BI-rapporten
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Oversigt over observationer fra den udforskende dataanalyse
- De fleste af kunderne er fra Frankrig. Spanien har den laveste faldrate sammenlignet med Frankrig og Tyskland.
- De fleste kunder har kreditkort
- Nogle kunder er begge over 60 år og har kreditresultater under 400. De kan dog ikke betragtes som udenforliggende værdier
- Meget få kunder har mere end to bankprodukter
- Inaktive kunder har en højere faldfrekvens
- Køn og ansættelse år har ringe indflydelse på en kundes beslutning om at lukke en bankkonto
Trin 4: Udfør modeltræning og -sporing
Når dataene er på plads, kan du nu definere modellen. Anvend tilfældige skov- og LightGBM-modeller i denne notesbog.
Brug bibliotekerne scikit-learn og LightGBM til at implementere modellerne med nogle få kodelinjer. Derudover kan du bruge MLfLow og Fabric Autologging til at spore eksperimenterne.
Dette kodeeksempel indlæser deltatabellen fra lakehouse. Du kan bruge andre deltatabeller, der selv bruger lakehouse som kilde.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generér et eksperiment til sporing og logføring af modellerne ved hjælp af MLflow
I dette afsnit kan du se, hvordan du genererer et eksperiment, og det angiver model- og oplæringsparametrene og målepunkterne for score. Derudover viser den, hvordan du oplærer modellerne, logfører dem og gemmer de oplærte modeller til senere brug.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Automatisk logning registrerer automatisk både inputparameterværdierne og outputmetrikværdierne for en model til maskinel indlæring, efterhånden som modellen oplæres. Disse oplysninger logføres derefter i dit arbejdsområde, hvor MLflow-API'erne eller det tilsvarende eksperiment i dit arbejdsområde kan få adgang til og visualisere dem.
Når eksperimentet er fuldført, ligner det dette billede:

Alle eksperimenter med deres respektive navne logføres, og du kan spore deres parametre og målepunkter for ydeevne. Hvis du vil vide mere om automatisk logning, skal du se Autologging i Microsoft Fabric.
Angiv specifikationer for eksperiment og automatisk logning
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Importér scikit-learn og LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Forbered oplærings- og testdatasæt
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Anvend SMOTE på oplæringsdata
Ubalanceret klassificering har et problem, fordi den har for få eksempler på mindretalsklassen til en model til effektivt at lære beslutningsgrænsen. For at håndtere dette er SMOTE (Synthetic Minority Oversampling Technique) den mest anvendte teknik til at syntetisere nye eksempler for minoritetsklassen. Få adgang til SMOTE med det imblearn bibliotek, du installerede i trin 1.
Anvend kun SMOTE på træningsdatasættet. Du skal lade testdatasættet være i dets oprindelige ubalancerede distribution for at få en gyldig tilnærmelse af modellens ydeevne på de oprindelige data. Dette eksperiment repræsenterer situationen i produktionen.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Du kan få flere oplysninger under SMOTE- og Fra tilfældig overtagning til SMOTE- og ADASYN-. Det ubalancerede learn-websted hoster disse ressourcer.
Oplær modellen
Brug Random Forest til at oplære modellen med en maksimal dybde på fire og med fire funktioner:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Brug Random Forest til at oplære modellen med en maksimal dybde på otte og med seks funktioner:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Oplær modellen med LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Få vist eksperimentartefakten for at spore modellens ydeevne
Eksperimentkørslerne gemmes automatisk i eksperimentartefakten. Du kan finde artefaktet i arbejdsområdet. Et artefaktnavn er baseret på det navn, der bruges til at angive eksperimentet. Alle oplærte modeller, deres kørsler, målepunkter for ydeevne og modelparametre logføres på eksperimentsiden.
Sådan får du vist dine eksperimenter:
- Vælg dit arbejdsområde i venstre panel.
- Find og vælg eksperimentnavnet, i dette tilfælde sample-bank-churn-experiment.
Trin 5: Evaluer og gem den endelige model til maskinel indlæring
Åbn det gemte eksperiment fra arbejdsområdet for at vælge og gemme den bedste model:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Vurder ydeevnen for de gemte modeller i testdatasættet
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Vis true/false positive/negatives ved hjælp af en forvirringsmatrix
Hvis du vil evaluere nøjagtigheden af klassificeringen, skal du oprette et script, der afbilder forvirringsmatrixen. Du kan også afbilde en forvirringsmatrix ved hjælp af SynapseML-værktøjer, som vist i eksemplet Fraud Detection.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
Opret en forvirringsmatrix for den tilfældige skovklassificering med en maksimal dybde på fire med fire funktioner:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
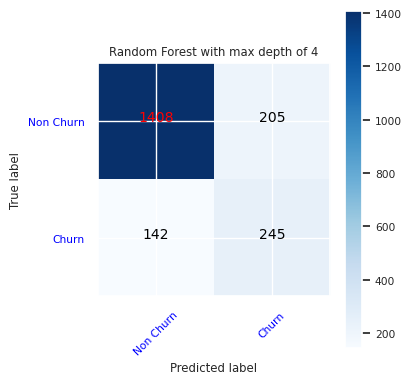
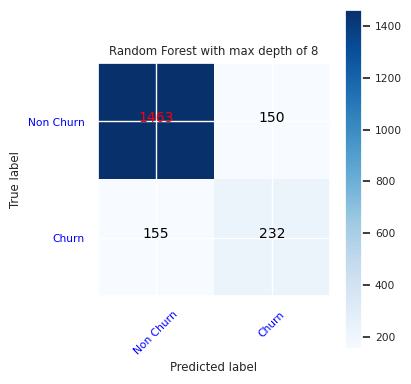
Opret en forvirringsmatrix for den tilfældige skovklassificering med maksimal dybde på otte med seks funktioner:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
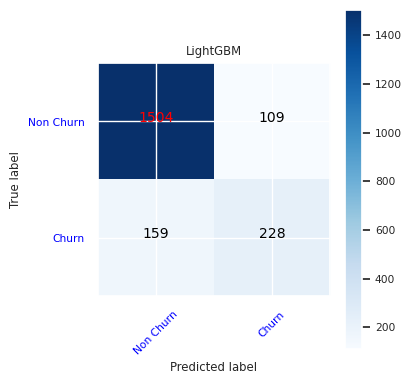
Opret en forvirringsmatrix for LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Gem resultater for Power BI
Gem deltarammen i lakehouse'et for at flytte resultaterne af modelforudsigelsen til en Power BI-visualisering.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Trin 6: Få adgang til visualiseringer i Power BI
Få adgang til din gemte tabel i Power BI:
- Vælg OneLaketil venstre.
- Vælg det lakehouse, du har føjet til denne notesbog.
- Vælg Åbni afsnittet Åbn dette Lakehouse- .
- På båndet skal du vælge Ny semantisk model. Vælg
df_pred_results, og vælg derefter Bekræft for at oprette en ny semantisk Power BI-model, der er knyttet til forudsigelserne. - Åbn en ny semantisk model. Du kan finde den i OneLake.
- Vælg Opret ny rapport under fil fra værktøjerne øverst på siden semantiske modeller for at åbne siden til oprettelse af Power BI-rapporter.
På følgende skærmbillede vises nogle eksempelvisualiseringer. Datapanelet viser de deltatabeller og -kolonner, der skal vælges fra en tabel. Når du har valgt den relevante kategoriakse (x) og værdiakse (y), kan du vælge filtre og funktioner , f.eks. sum eller gennemsnit af tabelkolonnen.
Seddel
På dette skærmbillede beskriver det illustrerede eksempel analysen af de gemte forudsigelsesresultater i Power BI:

Men for en reel kundeafgang kan brugeren have brug for et mere grundigt sæt af krav i visualiseringerne for at oprette, baseret på ekspertise inden for emnet, og hvad firmaets og forretningsanalyseteamet og firmaet har standardiseret som målepunkter.
Power BI-rapporten viser, at kunder, der bruger mere end to af bankprodukterne, har en højere fragangssats. Få kunder havde dog mere end to produkter. (Se afbildningen i nederste venstre panel). Banken bør indsamle flere data, men bør også undersøge andre funktioner, der korrelerer med flere produkter.
Bankkunder i Tyskland har en højere faldsats sammenlignet med kunder i Frankrig og Spanien. (Se afbildningen i nederste højre panel). Baseret på rapportens resultater kan en undersøgelse af de faktorer, der tilskyndede kunderne til at forlade, hjælpe.
Der er flere midaldrende kunder (mellem 25 og 45). Kunder mellem 45 og 60 har en tendens til at afslutte mere.
Endelig vil kunder med lavere kreditresultater sandsynligvis forlade banken for andre finansielle institutioner. Banken bør undersøge, hvordan man kan tilskynde kunder med lavere kreditresultater og kontosaldi til at blive hos banken.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")