Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
I dette selvstudium præsenteres et helt til slut-eksempel på en Synapse Data Science-arbejdsproces i Microsoft Fabric. I dette scenarie bygger vi en model til registrering af svindel i R med algoritmer til maskinel indlæring, der er oplært på historiske data. Vi bruger derefter modellen til at registrere fremtidige falske transaktioner.
I dette selvstudium beskrives disse trin:
- Installér brugerdefinerede biblioteker
- Indlæs dataene
- Forstå og behandl dataene med udforskende dataanalyse, og vis brugen af funktionen Fabric Data Wrangler
- Oplær modeller til maskinel indlæring med LightGBM
- Brug modeller til maskinel indlæring til scoring og forudsigelser
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Microsoft Fabric-prøveversion.
Log på Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

- Opret om nødvendigt et Microsoft Fabric lakehouse som beskrevet i Opret et lakehouse i Microsoft Fabric.
Følg med i en notesbog
Du kan vælge en af disse indstillinger for at følge med i en notesbog:
- Åbn og kør den indbyggede notesbog i Synapse Data Science-oplevelsen
- Upload din notesbog fra GitHub til Synapse Data Science-oplevelsen
Åbn den indbyggede notesbog
Eksemplet Registrering af svindel notesbog følger med dette selvstudium.
Hvis du vil åbne eksempelnotesbogen til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Importér notesbogen fra GitHub
Den AIsample – R Fraud Detection.ipynb notesbog følger med dette selvstudium.
Hvis du vil åbne den medfølgende notesbog til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab importere notesbogen til dit arbejdsområde.
Hvis du hellere vil kopiere og indsætte koden fra denne side, kan du oprette en ny notesbog.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Trin 1: Installér brugerdefinerede biblioteker
I forbindelse med udvikling af modeller til maskinel indlæring eller ad hoc-dataanalyse skal du muligvis hurtigt installere et brugerdefineret bibliotek til din Apache Spark-session. Du har to muligheder for at installere biblioteker.
- Brug indbyggede installationsressourcer, f.eks.
install.packagesogdevtools::install_version, til kun at installere i din aktuelle notesbog. - Du kan også oprette et Fabric-miljø, installere biblioteker fra offentlige kilder eller uploade brugerdefinerede biblioteker til det, og derefter kan administratoren af arbejdsområdet vedhæfte miljøet som standard for arbejdsområdet. Alle biblioteker i miljøet bliver derefter tilgængelige til brug i alle notesbøger og Spark-jobdefinitioner i arbejdsområdet. Du kan få flere oplysninger om miljøer under oprette, konfigurere og bruge et miljø i Microsoft Fabric.
I dette selvstudium skal du bruge install.version() til at installere det ubalancerede Learn-bibliotek:
# Install dependencies
devtools::install_version("bnlearn", version = "4.8")
# Install imbalance for SMOTE
devtools::install_version("imbalance", version = "1.0.2.1")
Trin 2: Indlæs dataene
Datasættet til registrering af svindel indeholder kreditkorttransaktioner fra september 2013, som europæiske kortholdere foretog i løbet af to dage. Datasættet indeholder kun numeriske funktioner på grund af en PCA-transformation (Principal Component Analysis), der er anvendt på de oprindelige funktioner. PCA transformerede alle funktioner undtagen Time og Amount. For at beskytte fortroligheden kan vi ikke levere de oprindelige funktioner eller flere baggrundsoplysninger om datasættet.
Disse oplysninger beskriver datasættet:
- Funktionerne
V1,V2,V3, ...,V28er de vigtigste komponenter, der er hentet med PCA - Funktionen
Timeindeholder de forløbne sekunder mellem en transaktion og den første transaktion i datasættet - Funktionen
Amounter transaktionsbeløbet. Du kan bruge denne funktion til eksempelafhængig, omkostningsfølsom læring - Kolonnen
Classer variablen svar (mål). Det har værdien1for svindel, og0ellers
Kun 492 transaktioner ud af 284.807 transaktioner i alt er falske. Datasættet er meget ubalanceret, fordi minoritetsklassen (falsk) kun tegner sig for ca. 0,172% af dataene.
I denne tabel vises et eksempel på de creditcard.csv data:
| Tidspunkt | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Beløb | Klasse |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.3598071336738 | -0.0727811733098497 | 2.53634673796914 | 1.37815522427443 | -0.338320769942518 | 0.462387777762292 | 0.239598554061257 | 0.0986979012610507 | 0.363786969611213 | 0.0907941719789316 | -0.551599533260813 | -0.617800855762348 | -0.991389847235408 | -0.311169353699879 | 1.46817697209427 | -0.470400525259478 | 0.207971241929242 | 0.0257905801985591 | 0.403992960255733 | 0.251412098239705 | -0.018306777944153 | 0.277837575558899 | -0.110473910188767 | 0.0669280749146731 | 0.128539358273528 | -0.189114843888824 | 0.133558376740387 | -0.0210530534538215 | 149.62 | "0" |
| 0 | 1.19185711131486 | 0.26615071205963 | 0.16648011335321 | 0.448154078460911 | 0.0600176492822243 | -0.0823608088155687 | -0.0788029833323113 | 0.0851016549148104 | -0.255425128109186 | -0.166974414004614 | 1.61272666105479 | 1.06523531137287 | 0.48909501589608 | -0.143772296441519 | 0.635558093258208 | 0.463917041022171 | -0.114804663102346 | -0.183361270123994 | -0.145783041325259 | -0.0690831352230203 | -0.225775248033138 | -0.638671952771851 | 0.101288021253234 | -0.339846475529127 | 0.167170404418143 | 0.125894532368176 | -0.00898309914322813 | 0.0147241691924927 | 2.69 | "0" |
Download datasættet, og upload det til lakehouse
Definer disse parametre, så du kan bruge denne notesbog med forskellige datasæt:
IS_CUSTOM_DATA <- FALSE # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE <- FALSE # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS <- 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT <- "/lakehouse/default"
DATA_FOLDER <- "Files/fraud-detection" # Folder with data files
DATA_FILE <- "creditcard.csv" # Data file name
Denne kode downloader en offentligt tilgængelig version af datasættet og gemmer den derefter i et Fabric lakehouse.
Vigtig
Sørg for at føje en lakehouse- til notesbogen, før du kører den. Ellers får du vist en fejl.
if (!IS_CUSTOM_DATA) {
# Download data files into a lakehouse if they don't exist
library(httr)
remote_url <- "https://synapseaisolutionsa.blob.core.windows.net/public/Credit_Card_Fraud_Detection"
fname <- "creditcard.csv"
download_path <- file.path(DATA_ROOT, DATA_FOLDER, "raw")
dir.create(download_path, showWarnings = FALSE, recursive = TRUE)
if (!file.exists(file.path(download_path, fname))) {
r <- GET(file.path(remote_url, fname), timeout(30))
writeBin(content(r, "raw"), file.path(download_path, fname))
}
message("Downloaded demo data files into lakehouse.")
}
Læs rådata fra lakehouse
Denne kode læser rådata fra afsnittet Filer i lakehouse:
data_df <- read.csv(file.path(DATA_ROOT, DATA_FOLDER, "raw", DATA_FILE))
Trin 3: Udfør udforskning af dataanalyse
Brug kommandoen display til at få vist datasættets statistik på højt niveau:
display(as.DataFrame(data_df, numPartitions = 3L))
# Print dataset basic information
message(sprintf("records read: %d", nrow(data_df)))
message("Schema:")
str(data_df)
# If IS_SAMPLE is True, use only SAMPLE_ROWS of rows for training
if (IS_SAMPLE) {
data_df = sample_n(data_df, SAMPLE_ROWS)
}
Udskriv fordelingen af klasser i datasættet:
# The distribution of classes in the dataset
message(sprintf("No Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 0)/nrow(data_df) * 100, 2)))
message(sprintf("Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 1)/nrow(data_df) * 100, 2)))
Denne klassedistribution viser, at de fleste af transaktionerne ikke er bedrageriske. Derfor er dataforbehandling påkrævet før modeltræning for at undgå overfitting.
Få vist fordelingen af falske transaktioner i forhold til ikke-bedrageriske transaktioner
Få vist fordelingen af falske transaktioner i forhold til ikke-bedrageriske transaktioner med en afbildning for at få vist klasseubalancen i datasættet:
library(ggplot2)
ggplot(data_df, aes(x = factor(Class), fill = factor(Class))) +
geom_bar(stat = "count") +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Class Distributions \n (0: No Fraud || 1: Fraud)") +
theme(plot.title = element_text(size = 10))
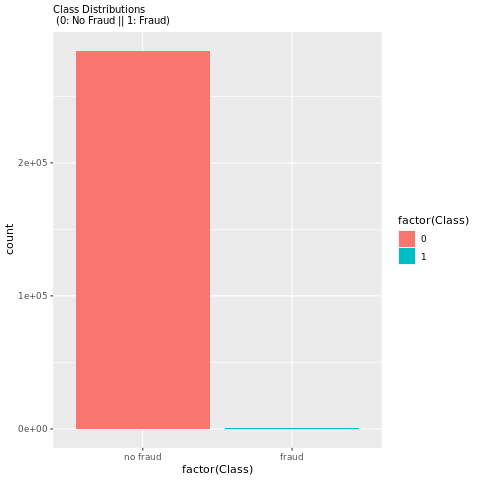
Afbildningen viser tydeligt ubalancen i datasættet:
Vis femtalsoversigten
Vis femtalsoversigten (minimumresultat, første kvartil, median, tredje kvartil og maksimumscore) for transaktionsbeløbet med feltafbildninger:
library(ggplot2)
library(dplyr)
ggplot(data_df, aes(x = as.factor(Class), y = Amount, fill = as.factor(Class))) +
geom_boxplot(outlier.shape = NA) +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Boxplot without Outliers") +
coord_cartesian(ylim = quantile(data_df$Amount, c(0.05, 0.95)))
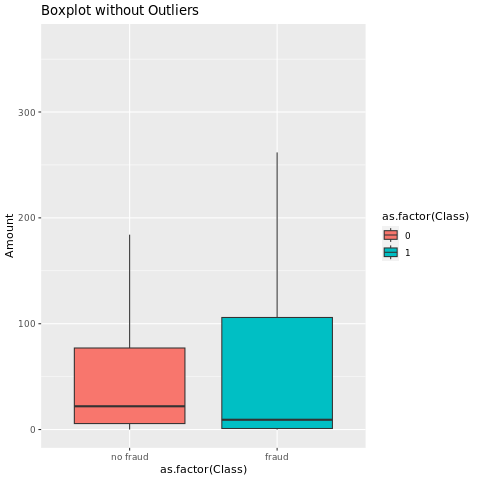
I forbindelse med data med høj ubalance viser feltafbildninger muligvis ikke nøjagtig indsigt. Du kan dog først løse problemet med Class ubalance og derefter oprette de samme afbildninger for at få mere nøjagtig indsigt.
Trin 4: Oplær og evaluer modellerne
Her kan du oplære en LightGBM-model til at klassificere svindeltransaktionerne. Du oplærer en LightGBM-model på både det ubalancerede datasæt og det balancerede datasæt. Derefter skal du sammenligne ydeevnen for begge modeller.
Forbered oplærings- og testdatasæt
Før oplæringen skal du opdele dataene i trænings- og testdatasættene:
# Split the dataset into training and test datasets
set.seed(42)
train_sample_ids <- base::sample(seq_len(nrow(data_df)), size = floor(0.85 * nrow(data_df)))
train_df <- data_df[train_sample_ids, ]
test_df <- data_df[-train_sample_ids, ]
Anvend SMOTE på træningsdatasættet
Ubalanceret klassificering har et problem. Der er for få eksempler på mindretalsklassen til, at en model effektivt kan lære beslutningsgrænsen at kende. SMOTE (Synthetic Minority Oversampling Technique) kan håndtere dette problem. SMOTE er den mest anvendte metode til at syntetisere nye prøver for minoritetsklassen. Du kan få adgang til SMOTE ved hjælp af biblioteket imbalance, som du installerede i trin 1.
Anvend kun SMOTE på træningsdatasættet i stedet for testdatasættet. Når du scorer modellen med testdataene, skal du have en tilnærmelse af modellens ydeevne for usete data i produktionen. For at opnå en gyldig tilnærmelse er dine testdata baseret på den oprindelige ubalancerede distribution for at repræsentere produktionsdata så tæt som muligt.
# Apply SMOTE to the training dataset
library(imbalance)
# Print the shape of the original (imbalanced) training dataset
train_y_categ <- train_df %>% select(Class) %>% table
message(
paste0(
"Original dataset shape ",
paste(names(train_y_categ), train_y_categ, sep = ": ", collapse = ", ")
)
)
# Resample the training dataset by using SMOTE
smote_train_df <- train_df %>%
mutate(Class = factor(Class)) %>%
oversample(ratio = 0.99, method = "SMOTE", classAttr = "Class") %>%
mutate(Class = as.integer(as.character(Class)))
# Print the shape of the resampled (balanced) training dataset
smote_train_y_categ <- smote_train_df %>% select(Class) %>% table
message(
paste0(
"Resampled dataset shape ",
paste(names(smote_train_y_categ), smote_train_y_categ, sep = ": ", collapse = ", ")
)
)
Du kan få flere oplysninger om SMOTE i -pakkens "ubalance" og Arbejde med ubalancerede datasæt ressourcer på CRAN-webstedet.
Oplær modellen med LightGBM
Oplær LightGBM-modellen med både det ubalancerede datasæt og det balancerede datasæt (via SMOTE). Sammenlign derefter deres ydeevne:
# Train LightGBM for both imbalanced and balanced datasets and define the evaluation metrics
library(lightgbm)
# Get the ID of the label column
label_col <- which(names(train_df) == "Class")
# Convert the test dataset for the model
test_mtx <- as.matrix(test_df)
test_x <- test_mtx[, -label_col]
test_y <- test_mtx[, label_col]
# Set up the parameters for training
params <- list(
objective = "binary",
learning_rate = 0.05,
first_metric_only = TRUE
)
# Train for the imbalanced dataset
message("Start training with imbalanced data:")
train_mtx <- as.matrix(train_df)
train_x <- train_mtx[, -label_col]
train_y <- train_mtx[, label_col]
train_data <- lgb.Dataset(train_x, label = train_y)
valid_data <- lgb.Dataset.create.valid(train_data, test_x, label = test_y)
model <- lgb.train(
data = train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = valid_data),
nrounds = 300L
)
# Train for the balanced (via SMOTE) dataset
message("\n\nStart training with balanced data:")
smote_train_mtx <- as.matrix(smote_train_df)
smote_train_x <- smote_train_mtx[, -label_col]
smote_train_y <- smote_train_mtx[, label_col]
smote_train_data <- lgb.Dataset(smote_train_x, label = smote_train_y)
smote_valid_data <- lgb.Dataset.create.valid(smote_train_data, test_x, label = test_y)
smote_model <- lgb.train(
data = smote_train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = smote_valid_data),
nrounds = 300L
)
Fastlæg vigtigheden af funktioner
Bestem vigtigheden af funktioner for den model, du oplærte i det ubalancerede datasæt:
imp <- lgb.importance(model, percentage = TRUE)
ggplot(imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_bar(stat = "identity") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(imp$Frequency) * 1.1)
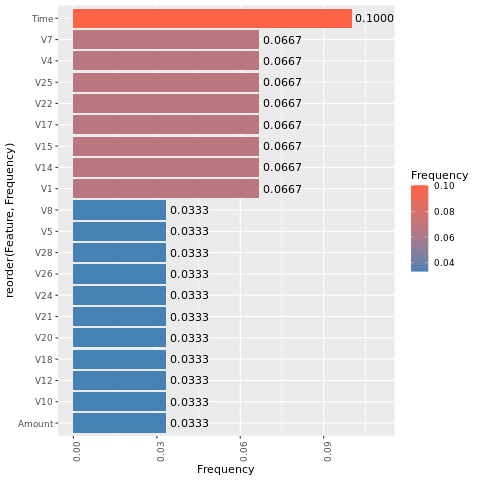
Beregn vigtigheden af funktionen for den model, du har oplært i det balancerede datasæt (via SMOTE):
smote_imp <- lgb.importance(smote_model, percentage = TRUE)
ggplot(smote_imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
geom_bar(stat = "identity") +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(smote_imp$Frequency) * 1.1)
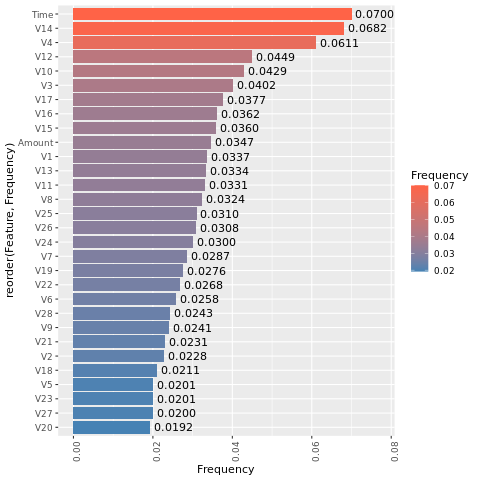
En sammenligning af disse afbildninger viser tydeligt, at balancerede og ubalancerede træningsdatasæt har store forskelle i vigtigheden af funktioner.
Evaluer modellerne
Her evaluerer du de to oplærte modeller:
-
modeloplært i rådata, ubalancerede data -
smote_modeloplært i balancerede data
preds <- predict(model, test_mtx[, -label_col])
smote_preds <- predict(smote_model, test_mtx[, -label_col])
Evaluer modellens ydeevne med en forvirringsmatrix
En forvirringsmatrix viser antallet af
- true positiver (TP)
- true negativer (TN)
- falske positiver (FP)
- falske negativer (FN)
som en model producerer, når den scores med testdata. I forbindelse med binær klassificering returnerer modellen en 2x2 forvirringsmatrix. I forbindelse med klassificering af flere klasser returnerer modellen en nxn forvirringsmatrix, hvor n er antallet af klasser.
Brug en forvirringsmatrix til at opsummere ydeevnen for de oplærte modeller til maskinel indlæring på testdataene:
plot_cm <- function(preds, refs, title) { library(caret) cm <- confusionMatrix(factor(refs), factor(preds)) cm_table <- as.data.frame(cm$table) cm_table$Prediction <- factor(cm_table$Prediction, levels=rev(levels(cm_table$Prediction))) ggplot(cm_table, aes(Reference, Prediction, fill = Freq)) + geom_tile() + geom_text(aes(label = Freq)) + scale_fill_gradient(low = "white", high = "steelblue", trans = "log") + labs(x = "Prediction", y = "Reference", title = title) + scale_x_discrete(labels=c("0", "1")) + scale_y_discrete(labels=c("1", "0")) + coord_equal() + theme(legend.position = "none") }Afbildning af forvirringsmatrixen for den model, der er oplært i det ubalancerede datasæt:
# The value of the prediction indicates the probability that a transaction is fraud # Use 0.5 as the threshold for fraud/no-fraud transactions plot_cm(ifelse(preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Imbalanced dataset)")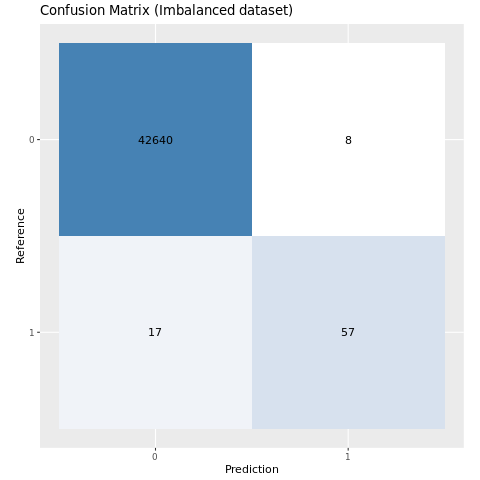
Afbildning af forvirringsmatrixen for den model, der er oplært i det balancerede datasæt:
plot_cm(ifelse(smote_preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Balanced dataset)")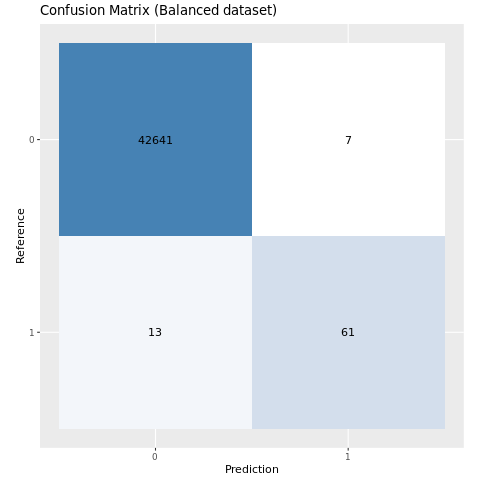
Evaluer modellens ydeevne med AUC-ROC- og AUPRC-målinger
Målingen Area Under the Curve Receiver Operating Characteristic (AUC-ROC) vurderer ydeevnen for binære klassificeringer. Diagrammet AUC-ROC visualiserer afvejninger mellem den sande positive rente (TPR) og den falske positive rente (FPR).
I nogle tilfælde er det mere hensigtsmæssigt at evaluere din klassificering baseret på målingen Area Under the Precision-Recall Curve (AUPRC). AUPRC-kurven kombinerer disse satser:
- Præcisionen eller den positive forudsigende værdi (PPV)
- Tilbagekaldelsen eller TPR
# Use the PRROC package to help calculate and plot AUC-ROC and AUPRC
install.packages("PRROC", quiet = TRUE)
library(PRROC)
Beregn målepunkterne AUC-ROC og AUPRC
Beregn og afbild målepunkterne AUC-ROC og AUPRC for de to modeller.
Ubalanceret datasæt
Beregn forudsigelserne:
fg <- preds[test_df$Class == 1]
bg <- preds[test_df$Class == 0]
Udskriv området under den AUC-ROC kurve:
# Compute AUC-ROC
roc <- roc.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(roc)
Afbild den AUC-ROC kurve:
# Plot AUC-ROC
plot(roc)
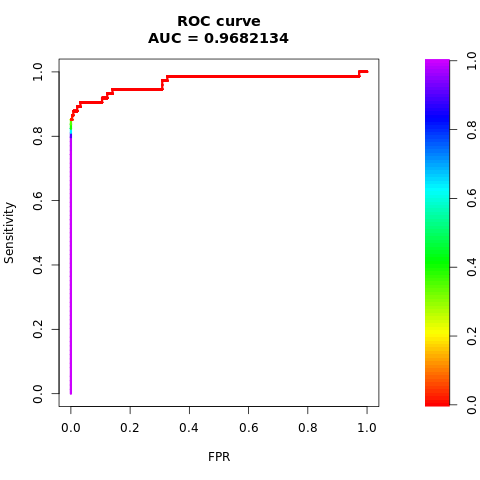
Udskriv AUPRC-kurven:
# Compute AUPRC
pr <- pr.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(pr)
Afbild AUPRC-kurven:
# Plot AUPRC
plot(pr)
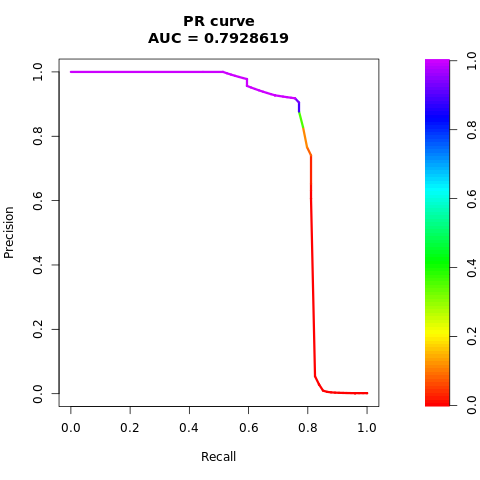
Balanceret datasæt (via SMOTE)
Beregn forudsigelserne:
smote_fg <- smote_preds[test_df$Class == 1]
smote_bg <- smote_preds[test_df$Class == 0]
Udskriv AUC-ROC-kurven:
# Compute AUC-ROC
smote_roc <- roc.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_roc)
Afbild den AUC-ROC kurve:
# Plot AUC-ROC
plot(smote_roc)
Udskriv AUPRC-kurven:
# Compute AUPRC
smote_pr <- pr.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_pr)
Afbild AUPRC-kurven:
# Plot AUPRC
plot(smote_pr)
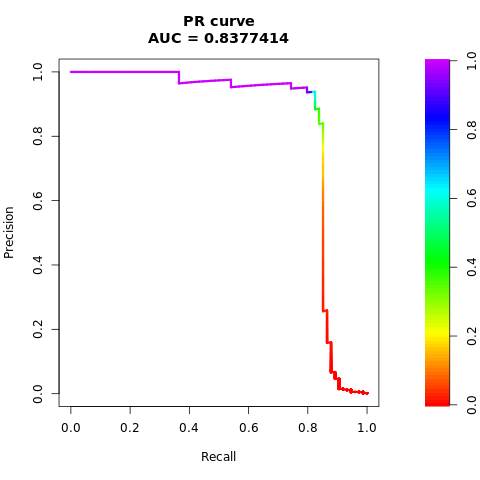
De tidligere tal viser tydeligt, at den model, der er oplært i det balancerede datasæt, klarer sig bedre end den model, der er oplært i det ubalancerede datasæt, for både AUC-ROC og AUPRC-scorer. Dette resultat antyder, at SMOTE effektivt forbedrer modellens ydeevne, når der arbejdes med data med høj ubalance.