Administration af R-bibliotek
Biblioteker indeholder kode, der kan genbruges, og som du måske vil medtage i dine programmer eller projekter til Microsoft Fabric Spark.
Microsoft Fabric understøtter en R-kørsel med mange populære R-pakker med åben kildekode, herunder TidyVerse, forudinstalleret. Når en Spark-forekomst starter, medtages disse biblioteker automatisk og kan bruges med det samme i notesbøger eller Spark-jobdefinitioner.
Du skal muligvis opdatere R-bibliotekerne af forskellige årsager. En af dine kerneafhængigheder har f.eks. udgivet en ny version, eller dit team har bygget en brugerdefineret pakke, som du har brug for, tilgængelig i dine Spark-klynger.
Der er to typer biblioteker, som du kan medtage på baggrund af dit scenarie:
Feedbiblioteker refererer til dem, der findes i offentlige kilder eller lagre, f.eks . CRAN eller GitHub.
Brugerdefinerede biblioteker er den kode, der er bygget af dig eller din organisation, .tar.gz kan administreres via portaler til biblioteksstyring.
Der er installeret to niveauer af pakker på Microsoft Fabric:
Miljø: Administrer biblioteker via et miljø for at genbruge det samme sæt biblioteker på tværs af flere notesbøger eller job.
Session : En installation på sessionsniveau opretter et miljø for en bestemt notesbogsession. Ændringen af biblioteker på sessionsniveau bevares ikke mellem sessioner.
Opsummering af de aktuelle tilgængelige funktionsmåder for administration af R-bibliotek:
| Bibliotekstype | Miljøinstallation | Installation på sessionsniveau |
|---|---|---|
| R-feed (CRAN) | Ikke understøttet | Understøttet |
| R-brugerdefineret | Understøttet | Understøttet |
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Prøveversion af Microsoft Fabric.
Brug oplevelsesskifteren i venstre side af startsiden til at skifte til Synapse Data Science-oplevelsen.

R-biblioteker på sessionsniveau
Når du udfører interaktiv dataanalyse eller maskinel indlæring, kan du prøve nyere pakker, eller du har muligvis brug for pakker, der i øjeblikket ikke er tilgængelige i dit arbejdsområde. I stedet for at opdatere indstillingerne for arbejdsområdet kan du bruge sessionsområder til at tilføje, administrere og opdatere sessionsafhængigheder.
- Når du installerer sessionsbaserede biblioteker, er det kun den aktuelle notesbog, der har adgang til de angivne biblioteker.
- Disse biblioteker påvirker ikke andre sessioner eller job, der bruger den samme Spark-gruppe.
- Disse biblioteker installeres oven på bibliotekerne på basiskørsels- og gruppeniveau.
- Notesbogbiblioteker har den højeste prioritet.
- Sessionsomfangede R-biblioteker bevares ikke på tværs af sessioner. Disse biblioteker installeres i starten af hver session, når de relaterede installationskommandoer udføres.
- Sessionsbaserede R-biblioteker installeres automatisk på tværs af både driver- og arbejdsnoderne.
Bemærk
Kommandoerne til administration af R-biblioteker er deaktiveret, når der køres pipelinejob. Hvis du vil installere en pakke i en pipeline, skal du bruge biblioteksadministrationsfunktionerne på arbejdsområdeniveau.
Installér R-pakker fra CRAN
Du kan nemt installere et R-bibliotek fra CRAN.
# install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Du kan også bruge CRAN-snapshots som lager for at sikre, at du downloader den samme pakkeversion hver gang.
# install a package from CRAN snapsho
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Installér R-pakker ved hjælp af devtools
Biblioteket devtools forenkler pakkeudvikling for at fremskynde almindelige opgaver. Dette bibliotek er installeret i Microsoft Fabric-standardkørslen.
Du kan bruge devtools til at angive en bestemt version af et bibliotek, der skal installeres. Disse biblioteker installeres på tværs af alle noder i klyngen.
# Install a specific version.
install_version("caesar", version = "1.0.0")
På samme måde kan du installere et bibliotek direkte fra GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
I øjeblikket understøttes følgende devtools funktioner i Microsoft Fabric:
| Kommando | Beskrivelse |
|---|---|
| install_github() | Installerer en R-pakke fra GitHub |
| install_gitlab() | Installerer en R-pakke fra GitLab |
| install_bitbucket() | Installerer en R-pakke fra BitBucket |
| install_url() | Installerer en R-pakke fra en vilkårlig URL-adresse |
| install_git() | Installerer fra et vilkårligt Git-lager |
| install_local() | Installerer fra en lokal fil på disken |
| install_version() | Installerer fra en bestemt version på CRAN |
Installér brugerdefinerede R-biblioteker
Hvis du vil bruge et brugerdefineret bibliotek på sessionsniveau, skal du først uploade det til et tilknyttet Lakehouse.
I venstre side skal du vælge Tilføj for at tilføje et eksisterende lakehouse eller oprette et lakehouse.
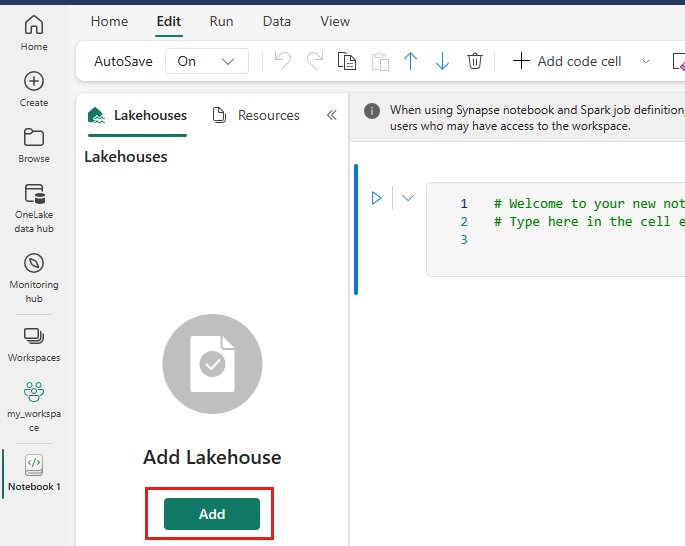
Hvis du vil føje filer til dette lakehouse, skal du vælge dit arbejdsområde og derefter vælge lakehouse.
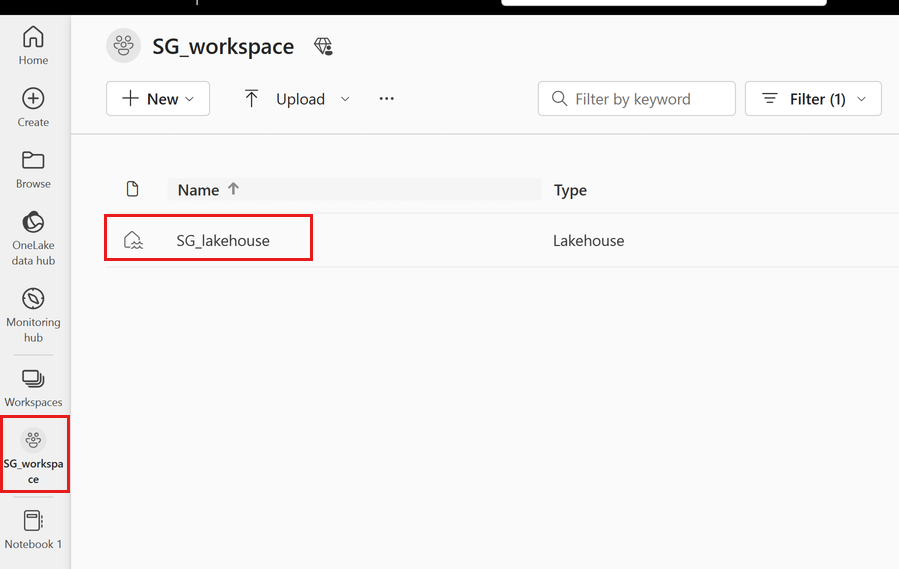
Højreklik eller vælg "..." ud for Filer for at uploade din .tar.gz fil.
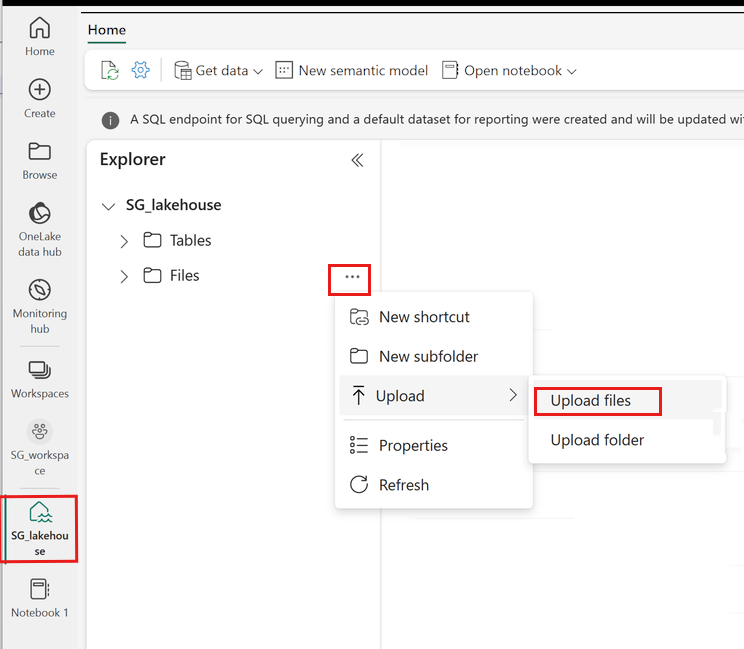
Når du har uploadet, skal du gå tilbage til din notesbog. Brug følgende kommando til at installere det brugerdefinerede bibliotek i din session:
install.packages("filepath/filename.tar.gz", repos = NULL, type = "source")
Vis installerede biblioteker
Forespørg alle de biblioteker, der er installeret i sessionen library , ved hjælp af kommandoen .
# query all the libraries installed in current session
library()
Brug funktionen packageVersion til at kontrollere bibliotekets version:
# check the package version
packageVersion("caesar")
Fjern en R-pakke fra en session
Du kan bruge funktionen detach til at fjerne et bibliotek fra navneområdet. Disse biblioteker forbliver på disken, indtil de indlæses igen.
# detach a library
detach("package: caesar")
Hvis du vil fjerne en pakke, der er omfattet af en session, fra en notesbog, skal du bruge kommandoen remove.packages() . Denne biblioteksændring har ingen indvirkning på andre sessioner i den samme klynge. Brugerne kan ikke fjerne eller fjerne indbyggede biblioteker for Microsoft Fabric-standardkørsel.
Bemærk
Du kan ikke fjerne kernepakker som SparkR, SparklyR eller R.
remove.packages("caesar")
Sessionsbaserede R-biblioteker og SparkR
Biblioteker, der er beregnet til notesbøger, er tilgængelige på SparkR-arbejdere.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Sessionsbaserede R-biblioteker og sparklyr
Med spark_apply() sparklyr kan du bruge alle R-pakker i Spark. Argumentet packages i sparklyr::spark_apply()angives som standard til FALSE. Dette kopierer biblioteker i de aktuelle libPaths til arbejderne, så du kan importere og bruge dem på arbejdere. Du kan f.eks. køre følgende for at generere en cæsarkrypteret meddelelse med sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- sparkR.version()
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Relateret indhold
Få mere at vide om R-funktionerne:
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om