Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Tidyverse er en samling R-pakker, som dataforskere ofte bruger i daglige dataanalyser. Den indeholder pakker til dataimport (readr), datavisualisering (ggplot2), datamanipulation (dplyr, tidyrfunktionsprogrammering (purrr) og modelopbygning (tidymodels) osv. Pakkerne i tidyverse er designet til at arbejde problemfrit sammen og følge et ensartet sæt designprincipper.
Microsoft Fabric distribuerer den nyeste stabile version af tidyverse med hver kørselsversion. Importér, og begynd at bruge dine velkendte R-pakker.
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Prøveversion af Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

Åbn eller opret en notesbog. Du kan få mere at vide under Sådan bruger du Microsoft Fabric-notesbøger.
Angiv sprogindstillingen til SparkR (R) for at ændre det primære sprog.
Vedhæft din notesbog til et lakehouse. I venstre side skal du vælge Tilføj for at tilføje et eksisterende lakehouse eller for at oprette et lakehouse.
Læs tidyverse
# load tidyverse
library(tidyverse)
Dataimport
readr er en R-pakke, der indeholder værktøjer til læsning af rektangulære datafiler, f.eks. CSV-, TSV- og filer med fast bredde.
readr gør det nemt og hurtigt at læse rektangulære datafiler, f.eks. funktioner read_csv() og read_tsv() læsning af henholdsvis CSV- og TSV-filer.
Lad os først oprette en R-data.frame, skrive den til lakehouse ved hjælp af readr::write_csv() og læse den tilbage med readr::read_csv().
Bemærk
Hvis du vil have adgang til Lakehouse-filer ved hjælp af readr, skal du bruge stien til fil-API'en. Højreklik på den fil eller mappe, du vil have adgang til, i Stifinder i Lakehouse, og kopiér dens fil-API-sti fra genvejsmenuen.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Lad os derefter skrive dataene til lakehouse ved hjælp af stien til fil-API'en.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Læs dataene fra lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Rydning af data
tidyr er en R-pakke, der indeholder værktøjer til at arbejde med rodede data. Hovedfunktionerne i tidyr er designet til at hjælpe dig med at omforme data til et ryddeligt format. Tidy-data har en bestemt struktur, hvor hver variabel er en kolonne, og hver observation er en række, hvilket gør det nemmere at arbejde med data i R og andre værktøjer.
Funktionen i gather() kan f.ekstidyr. bruges til at konvertere brede data til lange data. Her er et eksempel:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Funktionel programmering
purrr er en R-pakke, der forbedrer R's funktionelle programmeringsværktøjspakke ved at levere et komplet og ensartet sæt værktøjer til at arbejde med funktioner og vektorer. Det bedste sted at starte med purrr er den serie af map() funktioner, der giver dig mulighed for at erstatte mange for løkker med kode, der både er mere kortfattet og lettere at læse. Her er et eksempel på brug map() af til at anvende en funktion på hvert element på en liste:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Datamanipulation
dplyr er en R-pakke, der indeholder et ensartet sæt verber, der hjælper dig med at løse de mest almindelige problemer med datamanipulation, f.eks. valg af variabler baseret på navnene, pluksager baseret på værdierne, reduktion af flere værdier ned til en enkelt oversigt og ændring af rækkefølgen af rækkerne osv. Her er nogle eksempler:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Datavisualisering
ggplot2 er en R-pakke til deklarativ oprettelse af grafik baseret på Grafikkens grammatik. Du angiver dataene, fortæller ggplot2 , hvordan du knytter variabler til æstetik, hvilke grafiske primitiver der skal bruges, og det tager sig af detaljerne. Her er nogle eksempler:
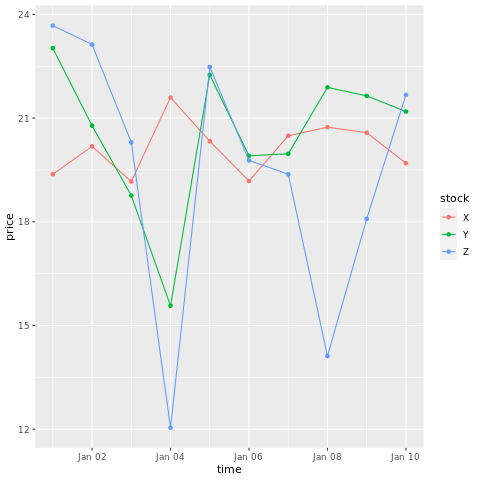
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
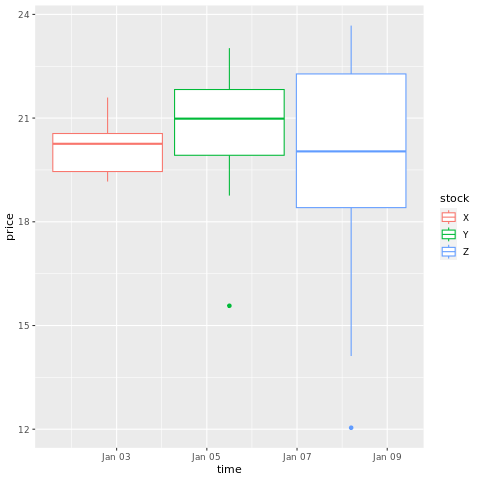
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Modelopbygning
Strukturen tidymodels er en samling pakker til modellering og maskinel indlæring ved hjælp af tidyverse principper. Den dækker en liste over kernepakker til en lang række modelopbygningsopgaver, f.eks rsample . opdeling af tog-/testdatasæteksempler, parsnip modelspecifikation, recipes dataforbehandling, workflows modellering af arbejdsprocesser, tune justering af hyperparametre, yardstick modelevaluering, broom klargøring af modeloutput og dials administration af justeringsparametre. Du kan få mere at vide om pakkerne ved at besøge webstedet tidymodels. Her er et eksempel på oprettelse af en lineær regressionsmodel for at forudsige miles pr. gallon (mpg) af en bil baseret på dens vægt (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
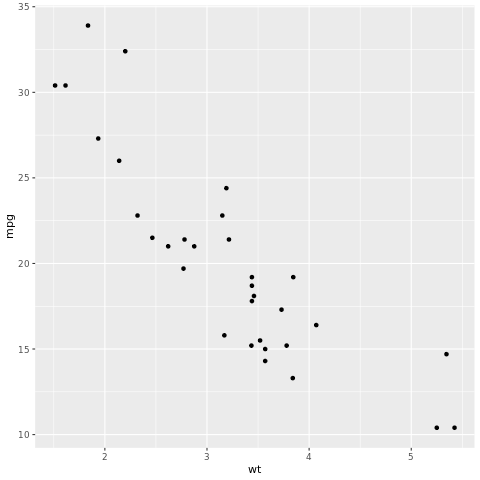
Fra punktdiagrammet ser relationen omtrent lineær ud, og variansen ser konstant ud. Lad os prøve at modellere dette ved hjælp af lineær regression.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Anvend den lineære regressionsmodel til at forudsige på testdatasæt.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
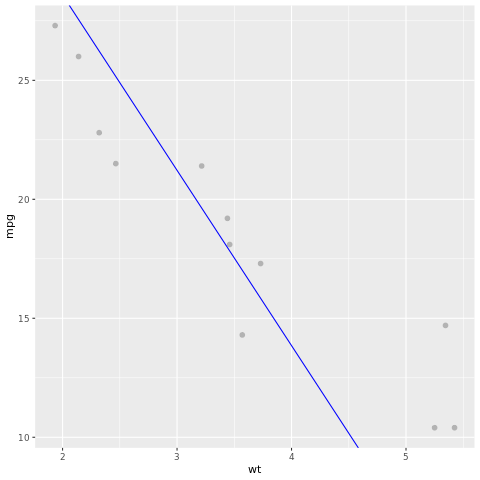
Lad os se nærmere på modelresultatet. Vi kan tegne modellen som et kurvediagram og sandhedsdata for testområdet som punkter i det samme diagram. Modellen ser godt ud.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")