Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Gælder for:✅ Lager i Microsoft Fabric
Denne artikel fremhæver funktionerne og innovationerne i Fabric Data Warehouses arkitektur, der driver dets ydeevne, skalerbarhed og omkostningseffektivitet.
Fabric Data Warehouse kører på en fremtidsklar arkitektur i en konvergeret dataplatform. Med et åbent Delta-lagringsformat og OneLake-integration er dine data i Fabric Data Warehouse klar til analyse.
Arkitektur på højt niveau

Fabric Data Warehouse er specialbygget til analyse i stor skala med følgende byggesten:
| Byggesten | Beskrivelse |
|---|---|
| Unified forespørgselsoptimering | Genererer en optimal eksekveringsplan for distribuerede cloud-miljøer, uanset kvaliteten af bruger-forfattede SQL-forespørgsler. |
| Distribueret forespørgselsbehandling | Understøtter massiv parallel forespørgselsudførelse med hurtig automatisk skalering af cloud-infrastruktur, hvilket øjeblikkeligt leverer nødvendige beregningsressourcer til forespørgsler. Separate SELECT- og DML-arbejdsbelastninger bruger separate puljer for effektiv og isoleret eksekvering. |
| Forespørgselsudførelsesmotor | En SQL-baseret motor til at udføre analyseforespørgsler på store mængder data med hurtig ydeevne og høj samtidighed. |
| Metadata og transaktionsstyring | Metadata findes i frontend, backend og både i den lokale SSD-cache og i den eksterne OneLake-lagring. Understøtter samtidige transaktioner og sikrer ACID-overholdelse. |
| Opbevaring i OneLake | Log Structured Tables implementeret ved brug af det åbne Delta-tabelformat, en lakehouse-model med sikker åben lagring. |
| Fabric Platform | Fabric Platform tilbyder en samlet autentificerings- og sikkerhedsmodel, overvågning og revision. Dit Fabric Data Warehouse er automatisk tilgængeligt for andre Fabric-platformtjenester for at opfylde forretningsbehov, herunder Power BI, datapipelines i Data Factory, Real-Time Intelligence og mere. |
Unified query optimizer-motor
Unified query optimizer i Fabric Data Warehouse er motoren, der beslutter den smarteste måde at køre dine SQL-forespørgsler på.
Når du indsender en forespørgsel, ser den samlede forespørgselsoptimerer på mulige måder at udføre den på: hvordan man joiner tabeller, hvor man flytter data hen, og hvordan man bruger ressourcer som CPU, hukommelse og netværk. Den samlede forespørgselsoptimering vælger ikke bare den første mulighed, men vælger den mest optimale plan inden for den tilladte tid ved at evaluere omkostninger på tværs af disse faktorer samt tilgængelige metadata og statistikker.
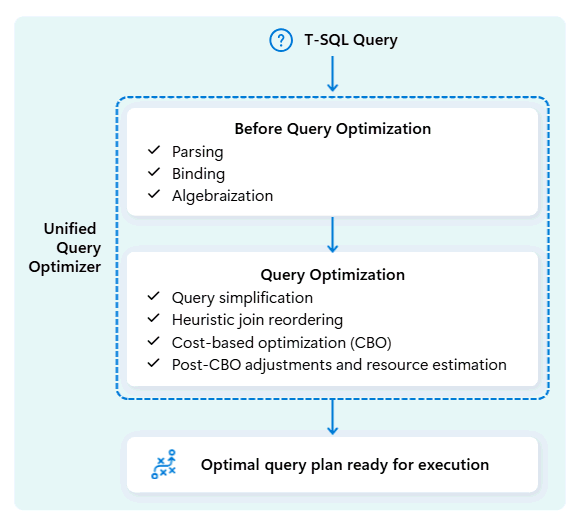
Når man optimerer en forespørgsels eksekveringsplan, tager den samlede forespørgselsoptimering alt i betragtning på én gang: formen på din forespørgsel, datafordelingen i dine tabeller og omkostningerne ved at flytte data kontra lokal behandling. Den samlede forespørgselsoptimering kan foretage smarte afvejninger som at beslutte, om det er billigere at udsende en lille tabel end at blande en stor. Det betyder færre unødvendige dataomskiftninger, bedre brug af beregning og hurtigere ydeevne, selv for komplekse eller dårligt skrevne T-SQL-forespørgsler.
Konsekvent ydeevne kræver ikke, at udviklere bruger tid på manuel T-SQL-forespørgselsoptimering. For eksempel behøver du ikke manuelt at bestemme den bedste JOIN rækkefølge i forespørgsler. Hvis din SQL først viser den store tabel og en mindre, meget selektiv datatabel som nummer to, kan optimereren automatisk skifte position for bedre ydeevne. Den vil bruge den mindre tabel som udgangspunkt for matchende rækker ("build"-siden) og den større tabel som den, man skal søge igennem ("probe"-siden, der tjekkes for matches). Denne tilgang minimerer hukommelsesforbruget, reducerer dataflytning og forbedrer parallelisme, samtidig med at den leverer nøjagtige resultater.
Den samlede forespørgselsoptimering lærer løbende af tidligere forespørgselsudførelser, efterhånden som arbejdsbelastningerne udvikler sig, og forfiner sin optimeringsalgoritme for at levere den bedst mulige ydeevne. Brugere drager fordel af hurtig forespørgselsudførelse automatisk, uanset kompleksitet og uden at skulle gribe ind.
Distribueret forespørgselsbehandlingsmotor
I Fabric Data Warehouse allokerer den distribuerede forespørgselsbehandlingsmotor computerressourcer til opgaver i forespørgselsplaner. Den distribuerede forespørgselsbehandlingsmotor kan planlægge opgaver på tværs af beregningsnoder, så hver node kører en del af en forespørgselsplan, hvilket muliggør parallel udførelse for hurtigere ydeevne. Komplekse rapporter på store datasæt kan drage fordel af distribueret forespørgselsbehandling.
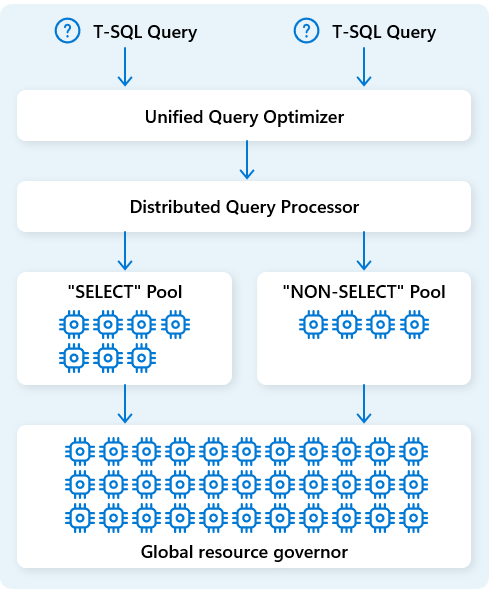
For yderligere at optimere ressourcer opdeler den distribuerede forespørgselsbehandlingsmotor beregningsressourcer i to puljer: til SELECT forespørgsler og til dataindlæsningsopgaver (NON-SELECT forespørgsler). Hver arbejdsbyrde modtager dedikerede ressourcer efter behov. Det betyder for eksempel, at dine natlige ETL-opgaver ikke vil forsinke morgendashboards.
Med hurtig nodeprovisionering i skyen skalerer den distribuerede forespørgselsbehandlingsmotor automatisk compute-ressourcer op eller ned som reaktion på ændringer i forespørgselsmængde, datastørrelse og forespørgselskompleksitet. Fabric Data Warehouse har parallelle behandlingsmuligheder for små datasæt eller data i multi-petabyte skala.
Forespørgselsudførelsesmotor
Forespørgselsudførelsesmotoren er en proces, der kører dele af den distribuerede eksekveringsplan, som er tildelt de enkelte beregningsnoder. Forespørgselsudførelsesmotoren er baseret på den samme motor, som SQL Server og Azure SQL Database bruger til at bruge batch-udførelse og kolonnedataformater til effektiv analyse af big data til optimal pris.
Forespørgselsudførelsesmotoren læser data direkte fra Delta Parquet-filer, der er gemt i Fabric OneLake, og udnytter flere caching-lag (hukommelse og SSD) for at accelerere forespørgselsydelsen og sikre, at forespørgsler udføres med optimal hastighed. Forespørgselsudførelsesmotoren behandler data i hukommelsen og henter, når nødvendigt, yderligere data fra SSD-cachen eller OneLake-lageret.
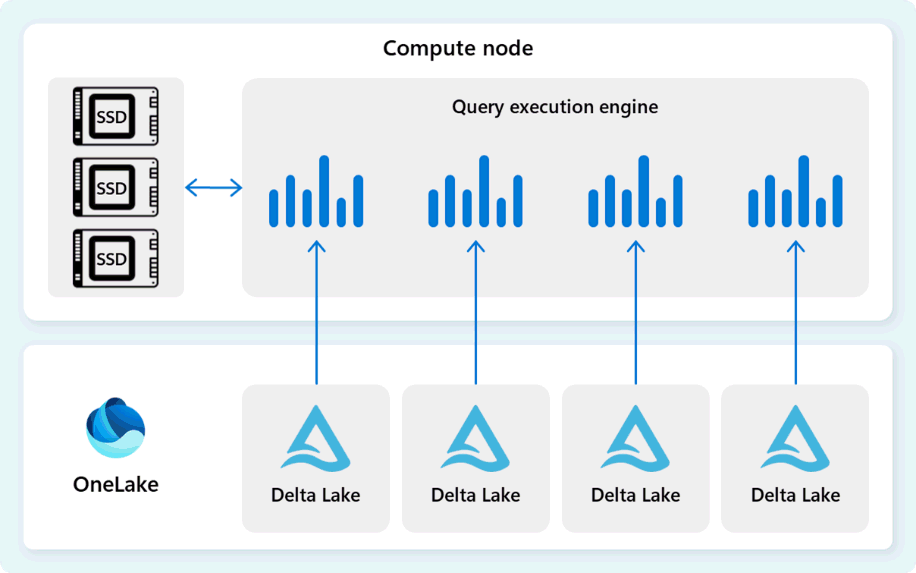
Mens den behandler data, udfører forespørgselsudførelsesmotoren kolonne- og rækkegruppeeliminering for at springe segmenter over, der ikke er relevante for forespørgslen. Denne optimering reducerer mængden af data, der scannes fra filerne og hukommelsescachen, hvilket hjælper med at minimere ressourceforbruget og forbedre den samlede eksekveringstid.
Forespørgselsudførelsesmotoren udmærker sig ved at filtrere og aggregere milliarder af rækker og understøtter de generiske dataanalytiske mønstre, der anvendes i moderne datalagerløsninger. Batch-tilstandsudførelsen udnytter moderne CPU's evne til at behandle flere rækker parallelt, hvilket dramatisk reducerer overhead og får forespørgsler til at køre op til hundrede gange hurtigere sammenlignet med traditionel række-for-række-eksekvering.
Metadata og transaktionsstyring
Warehouse-motoren bruger metadata til at beskrive tabelskema, filorganisering, versionshistorik og transaktionstilstande. Disse metadata gør det muligt for warehouse-motoren effektivt at håndtere og forespørge data. Fabric Data Warehouse tilbyder en robust og omfattende metadata- og transaktionsstyringsarkitektur, der udvider en OLTP-transaktionsmanager til at orkestrere meget samtidige metadataoperationer og sikre ACID-overholdelse.
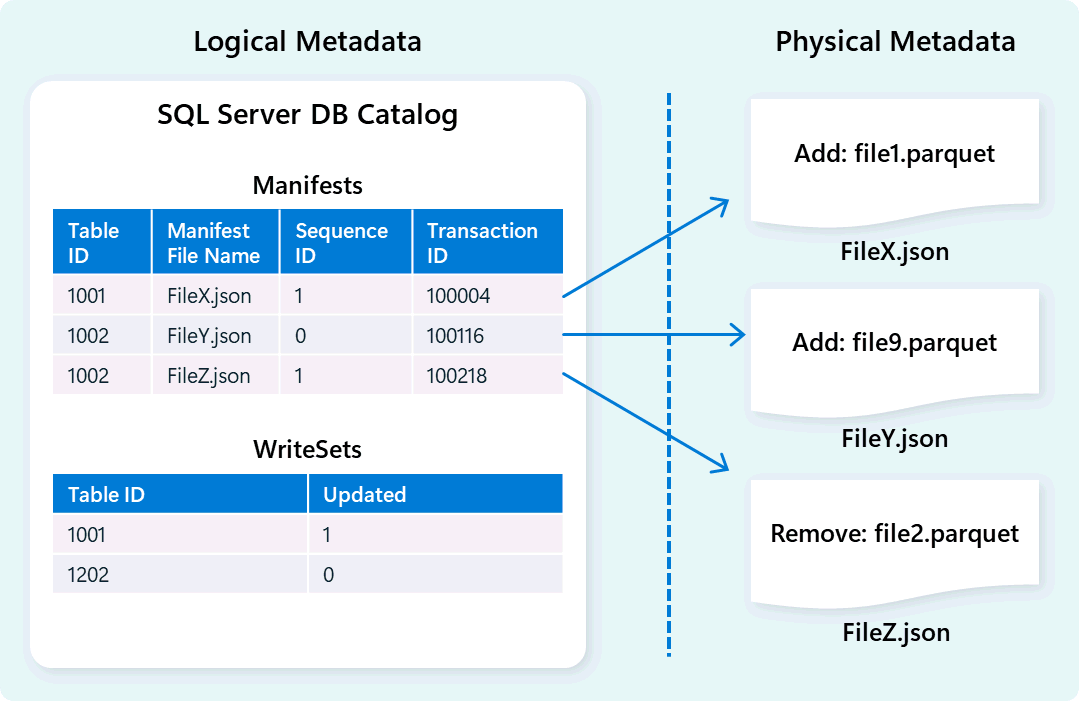
Dette design muliggør hurtig og pålidelig navigation af transaktionstilstande, understøtter arbejdsbelastninger med høj samtidighed samtidig med, at konsistens sikres.
Lagring og dataindlæsning
Fabric Data Warehouse bruger en lakehouse-arkitektur med open source Delta-formatet for skalerbar, sikker og højtydende lagring. Delta-tabelformatet understøtter dataversionering, hvilket muliggør øjeblikkelig adgang til historiske snapshots via tidsrejser og nul-kopi-kloning til sikker testning og rollback-operationer. Brugerdata gemmes i OneLake, hvilket gør det muligt for alle Fabric-motorer effektivt at få adgang til delte data uden redundans.
Med udgangspunkt i dette fundament er Fabric Data Warehouse designet til at levere optimal dataindlæsningsydelse med fokus på enkelhed og fleksibilitet. Motoren håndterer effektivt tabeldatalagring gennem automatisk datakomprimering, som konsoliderer fragmenterede filer i baggrunden for at reducere unødvendig datascanning. Dens intelligente datadistributionsmetode opdeler og organiserer data i mikroopdelte celler for at øge parallel behandling og forbedre forespørgselsresultater. Disse funktioner fungerer autonomt uden behov for manuelle justeringer.