Indfødning af data i dit lager ved hjælp af datapipelines
Gælder for:![]() Warehouse i Microsoft Fabric
Warehouse i Microsoft Fabric
Datapipelines er et alternativ til at bruge kommandoen COPY via en grafisk brugergrænseflade. En datapipeline er en logisk gruppering af aktiviteter, der tilsammen udfører en dataindtagelsesopgave. Pipelines giver dig mulighed for at administrere etl-aktiviteter (extract, transform and load) i stedet for at administrere hver enkelt.
I dette selvstudium skal du oprette en ny pipeline, der indlæser eksempeldata i et lager i Microsoft Fabric.
Bemærk
Nogle funktioner fra Azure Data Factory er ikke tilgængelige i Microsoft Fabric, men koncepterne er udskiftelige. Du kan få mere at vide om Azure Data Factory og Pipelines på Pipelines og aktiviteter i Azure Data Factory og Azure Synapse Analytics. Du kan få en hurtig introduktion ved at gå til Hurtig start: Opret din første pipeline for at kopiere data.
Opret en datapipeline
Hvis du vil oprette en ny pipeline, skal du navigere til dit arbejdsområde ved at vælge knappen +Ny og vælge Datapipeline.
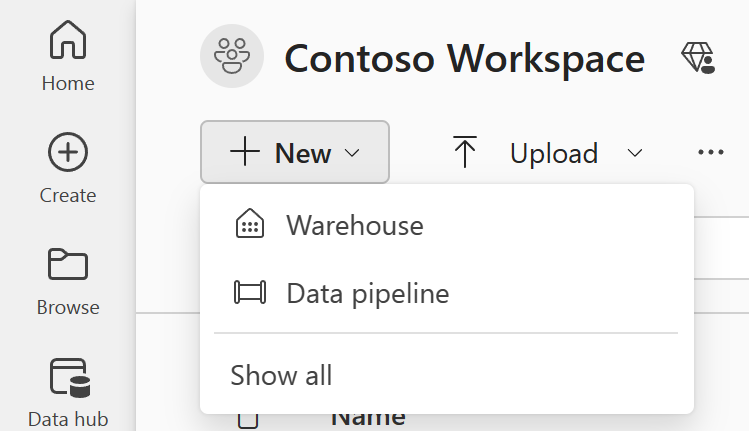
I dialogboksen Ny pipeline skal du angive et navn til din nye pipeline og vælge Opret.
Du lander i pipelinelærredet, hvor du kan se tre muligheder for at komme i gang: Tilføj en pipelineaktivitet, Kopiér data og Vælg en opgave, der skal startes.
Hver af disse indstillinger tilbyder forskellige alternativer til at oprette en pipeline:
- Tilføj pipelineaktivitet: Denne indstilling starter pipelineeditoren, hvor du kan oprette nye pipelines fra bunden ved hjælp af pipelineaktiviteter.
- Kopiér data: Denne indstilling starter en trinvis assistent, der hjælper dig med at vælge en datakilde, en destination og konfigurere indstillinger for dataindlæsning, f.eks. kolonnetilknytninger. Når den er fuldført, oprettes der en ny pipelineaktivitet med en Kopiér data-opgave , der allerede er konfigureret for dig.
- Vælg en opgave, der skal startes: Denne indstilling starter et sæt foruddefinerede skabeloner for at hjælpe dig i gang med pipelines, der er baseret på forskellige scenarier.
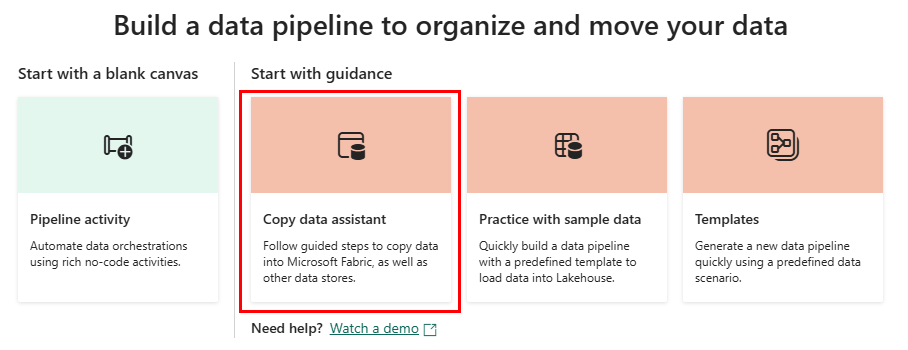
Vælg indstillingen Kopiér data for at starte Kopiér assistent.
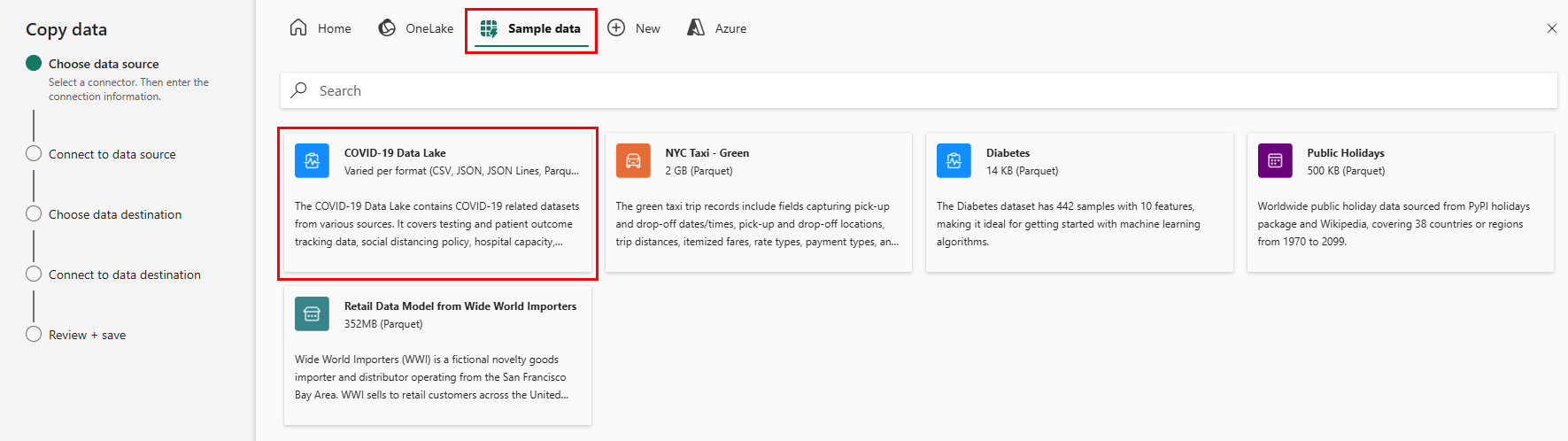
Den første side i Kopiér dataassistent hjælper dig med at vælge dine egne data fra forskellige datakilder eller vælge mellem et af de angivne eksempler for at komme i gang. I dette selvstudium bruger vi COVID-19 Data Lake-eksemplet . Vælg denne indstilling, og vælg Næste.
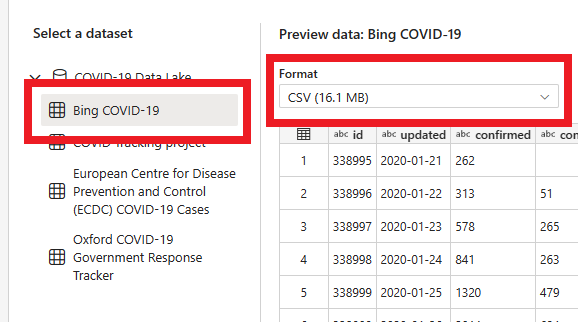
På den næste side kan du vælge et datasæt, kildefilformatet og få vist det valgte datasæt. Vælg Bing COVID-19, CSV-formatet , og vælg Næste.
På den næste side, Datadestinationer, kan du konfigurere destinationsarbejdsområdets type. Vi indlæser data i et lager i vores arbejdsområde, så vælg fanen Lager og indstillingen Data Warehouse. Vælg Næste.
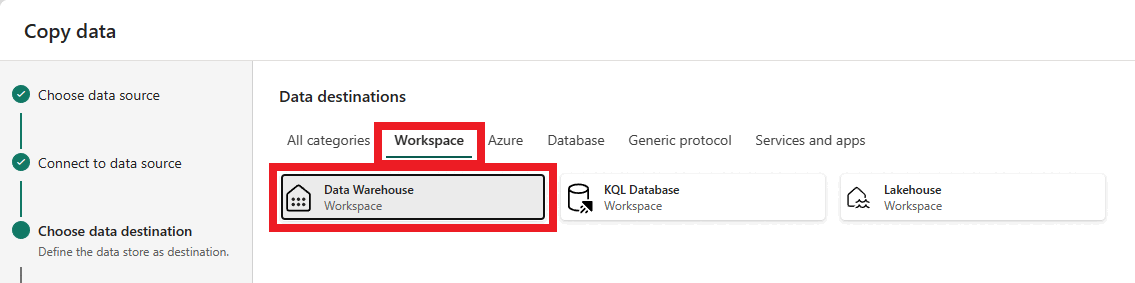
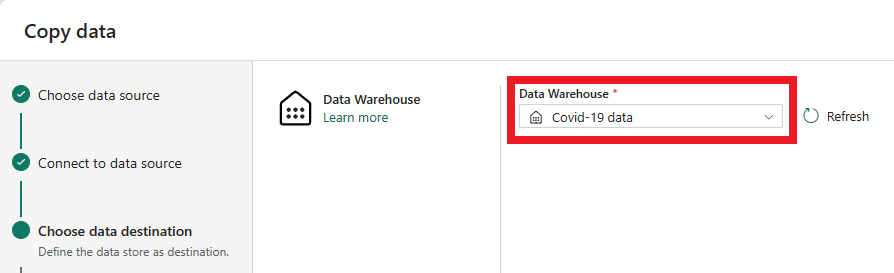
Nu er det tid til at vælge det lager, der skal indlæses data i. Vælg det ønskede lager på rullelisten, og vælg Næste.
Det sidste trin til at konfigurere destinationen er at angive et navn til destinationstabellen og konfigurere kolonnetilknytningerne. Her kan du vælge at indlæse dataene i en ny eller eksisterende tabel, angive et skema og tabelnavne, ændre kolonnenavne, fjerne kolonner eller ændre deres tilknytninger. Du kan acceptere standarderne eller justere indstillingerne efter dine præferencer.
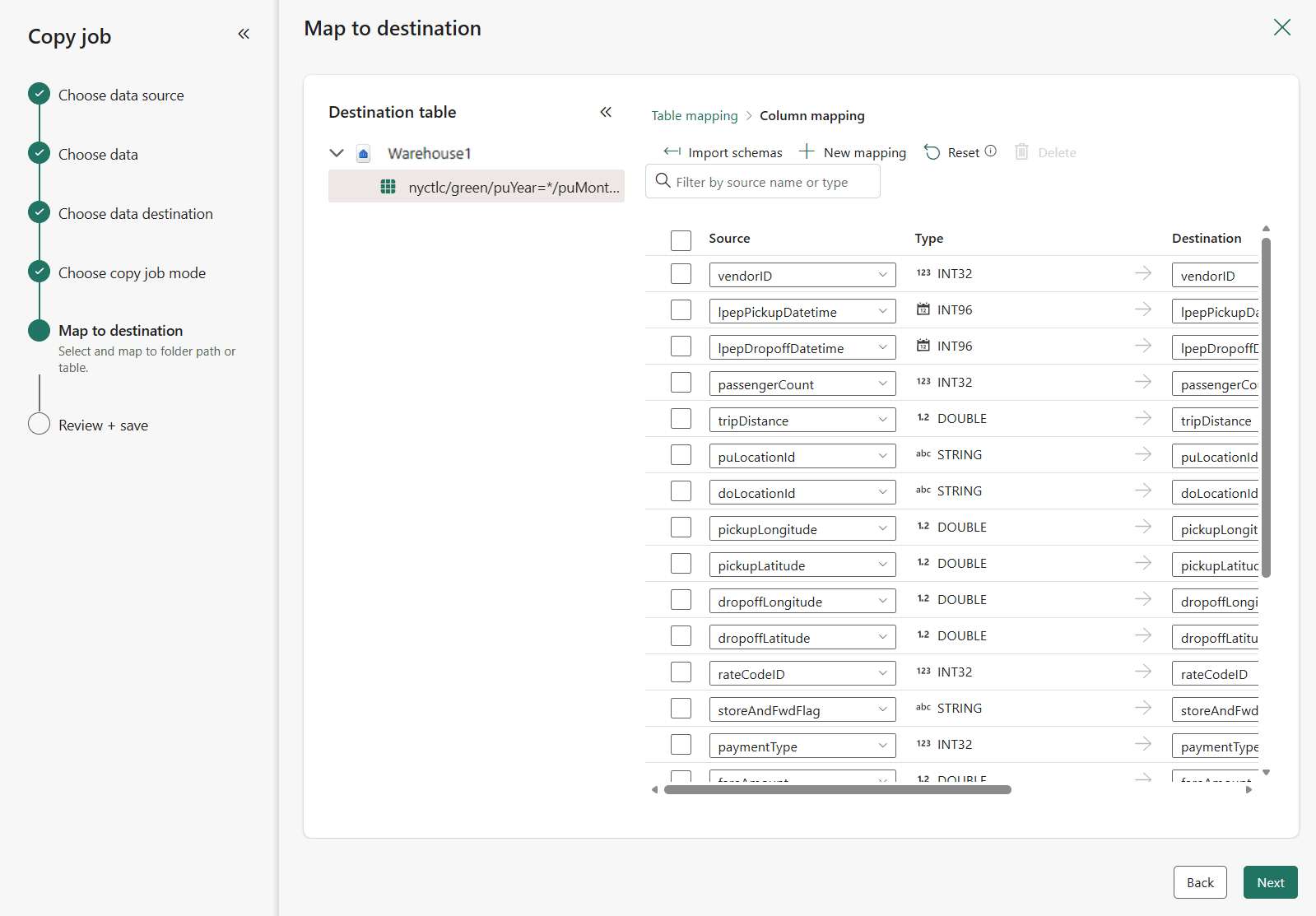
Når du er færdig med at gennemse indstillingerne, skal du vælge Næste.
Den næste side giver dig mulighed for at bruge midlertidig lagring eller angive avancerede indstillinger for datakopihandlingen (som bruger kommandoen T-SQL COPY). Gennemse indstillingerne uden at ændre dem, og vælg Næste.
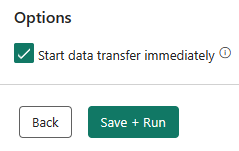
Den sidste side i assistenten indeholder en oversigt over kopiaktiviteten. Vælg indstillingen Start dataoverførsel med det samme , og vælg Gem + Kør.
Du omdirigeres til pipelinelærredet, hvor der allerede er konfigureret en ny kopidataaktivitet for dig. Pipelinen begynder at køre automatisk. Du kan overvåge status for pipelinen i ruden Output :
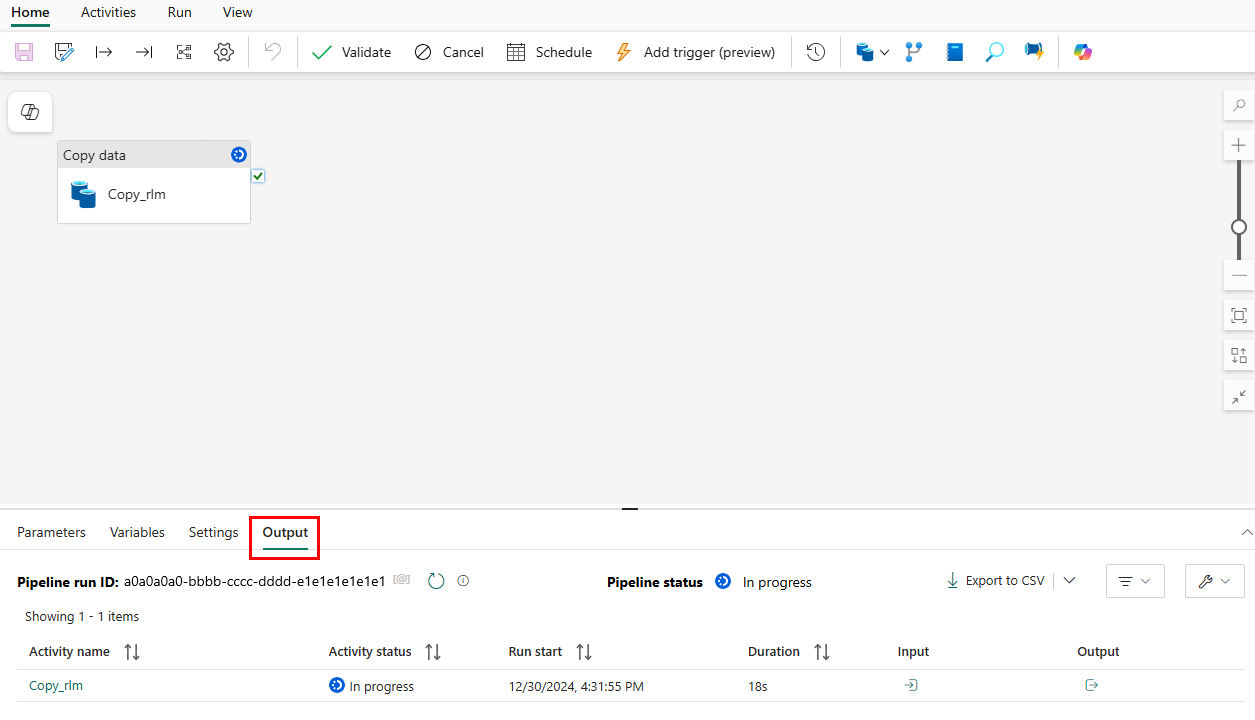
Efter et par sekunder afsluttes pipelinen. Når du navigerer tilbage til lageret, kan du vælge din tabel for at få vist dataene og bekræfte, at kopieringen blev afsluttet.
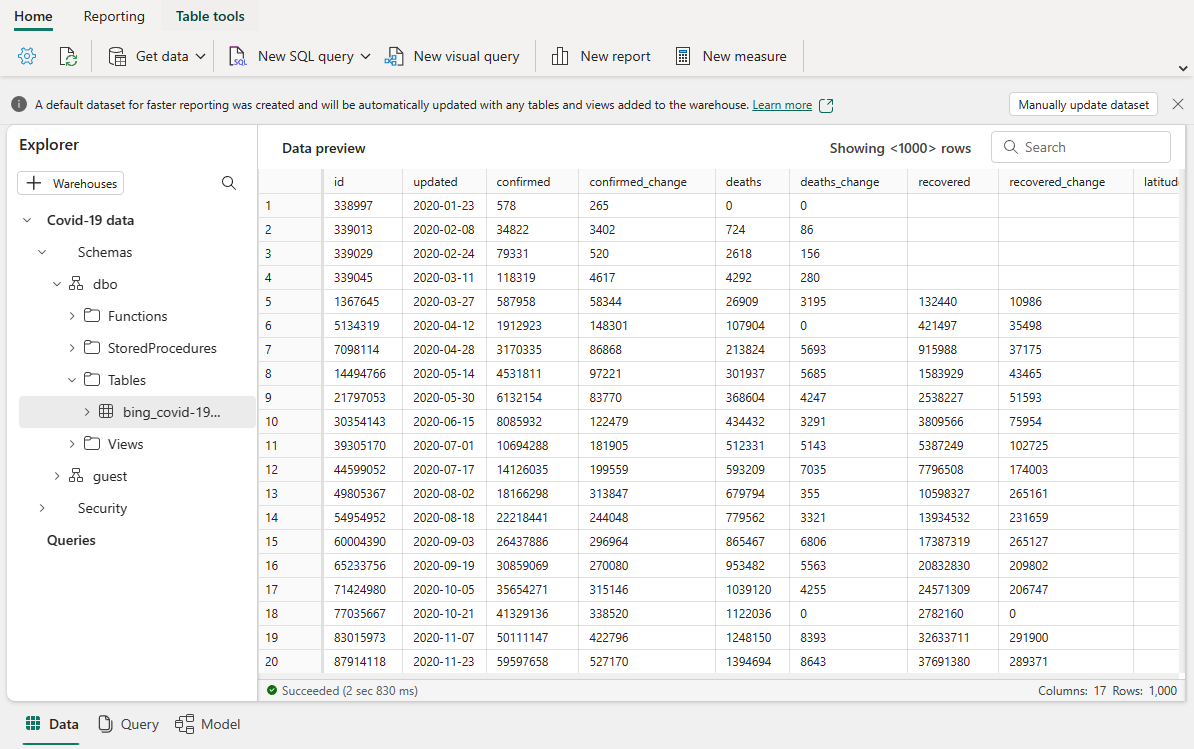







Du kan finde flere oplysninger om dataindtagelse i dit lager i Microsoft Fabric ved at besøge:
- Indtagelse af data i lageret
- Indfødning af data i lageret ved hjælp af COPY-sætningen
- Indfødning af data i dit lager ved hjælp af Transact-SQL
Næste trin
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om