Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
I denne artikel beskrives tilknytning af datavisninger, og det beskrives, hvordan dataroller bruges til at oprette forskellige typer visualiseringer. Den forklarer, hvordan du angiver betingede krav til dataroller og de forskellige dataMappings typer.
Hver gyldig tilknytning opretter en datavisning. Du kan angive flere datatilknytninger under visse betingelser. De understøttede tilknytningsindstillinger er:
"dataViewMappings": [
{
"conditions": [ ... ],
"categorical": { ... },
"single": { ... },
"table": { ... },
"matrix": { ... }
}
]
Power BI opretter kun en tilknytning til en datavisning, hvis den gyldige tilknytning også er defineret i dataViewMappings.
Det kan med andre ord være defineret i dataViewMappings , categorical men det er andre tilknytninger, f.ekstable. eller single, muligvis ikke. I dette tilfælde opretter Power BI en datavisning med en enkelt categorical tilknytning, mens table og andre tilknytninger forbliver udefinerede. Eksempler:
"dataViewMappings": [
{
"categorical": {
"categories": [ ... ],
"values": [ ... ]
},
"metadata": { ... }
}
]
Betingelser
I conditions afsnittet fastsættes regler for en bestemt datatilknytning. Hvis dataene stemmer overens med et af de beskrevne sæt betingelser, accepterer visualiseringen dataene som gyldige.
For hvert felt kan du angive en minimum- og maksimumværdi. Værdien repræsenterer antallet af felter, der kan bindes til den pågældende datarolle.
Bemærk
Hvis en datarolle udelades i betingelsen, kan den have et vilkårligt antal felter.
I følgende eksempel er begrænset til ét datafelt, category og measure er begrænset til to datafelter.
"conditions": [
{ "category": { "max": 1 }, "measure": { "max": 2 } },
]
Du kan også angive flere betingelser for en datarolle. I så fald er dataene gyldige, hvis en af betingelserne er opfyldt.
"conditions": [
{ "category": { "min": 1, "max": 1 }, "measure": { "min": 2, "max": 2 } },
{ "category": { "min": 2, "max": 2 }, "measure": { "min": 1, "max": 1 } }
]
I det forrige eksempel kræves en af følgende to betingelser:
- Præcis ét kategorifelt og præcis to målinger
- Præcis to kategorier og præcis én måling
Tilknytning af enkelt data
Enkelt datatilknytning er den enkleste form for datatilknytning. Den accepterer et enkelt målingsfelt og returnerer totalen. Hvis feltet er numerisk, returneres summen. Ellers returneres et antal entydige værdier.
Hvis du vil bruge en enkelt datatilknytning, skal du definere navnet på den datarolle, du vil tilknytte. Denne tilknytning fungerer kun sammen med et felt med en enkelt måling. Hvis der tildeles et andet felt, genereres der ingen datavisning, så det er en god idé at inkludere en betingelse, der begrænser dataene til et enkelt felt.
Bemærk
Denne datatilknytning kan ikke bruges sammen med andre datatilknytninger. Det er beregnet til at reducere data til en enkelt numerisk værdi.
Eksempler:
{
"dataRoles": [
{
"displayName": "Y",
"name": "Y",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"conditions": [
{
"Y": {
"max": 1
}
}
],
"single": {
"role": "Y"
}
}
]
}
Den resulterende datavisning kan stadig indeholde andre typer tilknytninger, f.eks. tabel eller kategori, men hver tilknytning indeholder kun den enkelte værdi. Den bedste praksis er kun at få adgang til værdien i en enkelt tilknytning.
{
"dataView": [
{
"metadata": null,
"categorical": null,
"matrix": null,
"table": null,
"tree": null,
"single": {
"value": 94163140.3560001
}
}
]
}
Følgende kodeeksempel behandler tilknytning af simple datavisninger:
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewSingle = powerbi.DataViewSingle;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private valueText: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.valueText = document.createElement("p");
this.target.appendChild(this.valueText);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const singleDataView: DataViewSingle = dataView.single;
if (!singleDataView ||
!singleDataView.value ) {
return
}
this.valueText.innerText = singleDataView.value.toString();
}
}
Det forrige kodeeksempel resulterer i visning af en enkelt værdi fra Power BI:
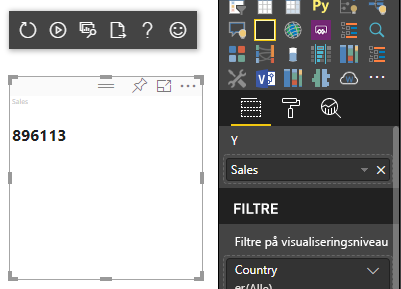
Kategorisk datatilknytning
Kategorisk datatilknytning bruges til at hente uafhængige grupperinger eller kategorier af data. Kategorierne kan også grupperes ved hjælp af "Gruppér efter" i datatilknytningen.
Grundlæggende kategorisk datatilknytning
Overvej følgende dataroller og tilknytninger:
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
}
],
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" }
},
"values": {
"select": [
{ "bind": { "to": "measure" } }
]
}
}
}
I det forrige eksempel står der "Tilknyt min category datarolle, så dataene for hvert felt, jeg trækker til category, knyttes til categorical.categories. Knyt også min measure datarolle til categorical.values."
- for... i: Inkluderer alle elementer i denne datarolle i dataforespørgslen.
- binde... til: Giver det samme resultat som for... i , men forventer, at datarollen har en betingelse, der begrænser den til et enkelt felt.
Gruppekategoridata
I det næste eksempel bruges de samme to dataroller som i det forrige eksempel, og der tilføjes yderligere to dataroller med navnet grouping og measure2.
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Grouping with",
"name": "grouping",
"kind": "Grouping"
},
{
"displayName": "X Axis",
"name": "measure2",
"kind": "Grouping"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "grouping",
"select": [{
"bind": {
"to": "measure"
}
},
{
"bind": {
"to": "measure2"
}
}
]
}
}
}
}
]
Forskellen mellem denne tilknytning og den grundlæggende tilknytning er, hvordan categorical.values tilknyttes. Når du knytter datarollerne measure og measure2 til datarollen grouping, kan x- og y-aksen skaleres korrekt.
Gruppér hierarkiske data
I det næste eksempel bruges de kategoriske data til at oprette et hierarki, som kan bruges til at understøtte detailudledningshandlinger .
I følgende eksempel vises datarollerne og tilknytningerne:
"dataRoles": [
{
"displayName": "Categories",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Measures",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Series",
"name": "series",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
]
}
}
}
}
]
Overvej følgende kategoriske data:
| Land/område | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|
| USA | x | x | 650 | 350 |
| Canada | x | 630 | 490 | x |
| Mexico | 645 | x | x | x |
| UK | x | x | 831 | x |
Power BI opretter en kategorisk datavisning med følgende sæt kategorier.
{
"categorical": {
"categories": [
{
"source": {...},
"values": [
"Canada",
"USA",
"UK",
"Mexico"
],
"identity": [...],
"identityFields": [...],
}
]
}
}
Hver af category dem knyttes til et sæt .values Hver af disse values grupperes efter series, som udtrykkes som år.
Hver matrix repræsenterer f.eks values . ét år.
Desuden har hver values matrix fire værdier: Canada, USA, Storbritannien og Mexico.
{
"values": [
// Values for year 2013
{
"source": {...},
"values": [
null, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
645 // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2014
{
"source": {...},
"values": [
630, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2015
{
"source": {...},
"values": [
490, // Value for `Canada` category
650, // Value for `USA` category
831, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2016
{
"source": {...},
"values": [
null, // Value for `Canada` category
350, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
}
]
}
Følgende kodeeksempel er til behandling af tilknytning af kategoriske datavisninger. I dette eksempel oprettes den hierarkiske struktur Værdi for land/område>.>
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewCategorical = powerbi.DataViewCategorical;
import DataViewValueColumnGroup = powerbi.DataViewValueColumnGroup;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private categories: HTMLElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.categories = document.createElement("pre");
this.target.appendChild(this.categories);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const categoricalDataView: DataViewCategorical = dataView.categorical;
if (!categoricalDataView ||
!categoricalDataView.categories ||
!categoricalDataView.categories[0] ||
!categoricalDataView.values) {
return;
}
// Categories have only one column in data buckets
// To support several columns of categories data bucket, iterate categoricalDataView.categories array.
const categoryFieldIndex = 0;
// Measure has only one column in data buckets.
// To support several columns on data bucket, iterate years.values array in map function
const measureFieldIndex = 0;
let categories: PrimitiveValue[] = categoricalDataView.categories[categoryFieldIndex].values;
let values: DataViewValueColumnGroup[] = categoricalDataView.values.grouped();
let data = {};
// iterate categories/countries-regions
categories.map((category: PrimitiveValue, categoryIndex: number) => {
data[category.toString()] = {};
// iterate series/years
values.map((years: DataViewValueColumnGroup) => {
if (!data[category.toString()][years.name] && years.values[measureFieldIndex].values[categoryIndex]) {
data[category.toString()][years.name] = []
}
if (years.values[0].values[categoryIndex]) {
data[category.toString()][years.name].push(years.values[measureFieldIndex].values[categoryIndex]);
}
});
});
this.categories.innerText = JSON.stringify(data, null, 6);
console.log(data);
}
}
Her er den resulterende visualisering:
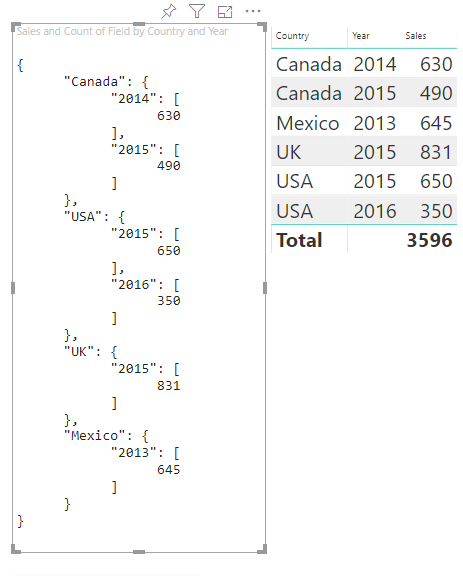
Tilknytning af tabeller
Tabeldatavisningen er i bund og grund en liste over datapunkter, hvor numeriske datapunkter kan aggregeres.
Brug f.eks. de samme data i det forrige afsnit, men med følgende funktioner:
"dataRoles": [
{
"displayName": "Column",
"name": "column",
"kind": "Grouping"
},
{
"displayName": "Value",
"name": "value",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"table": {
"rows": {
"select": [
{
"for": {
"in": "column"
}
},
{
"for": {
"in": "value"
}
}
]
}
}
}
]
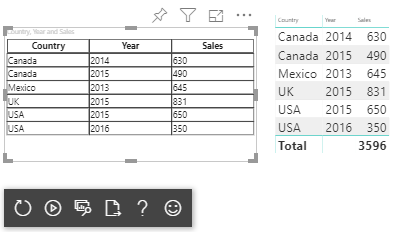
Visualiser tabeldatavisningen som i dette eksempel:
| Land/område | Year | Salg |
|---|---|---|
| USA | 2016 | 100 |
| USA | 2015 | 50 |
| Canada | 2015 | 200 |
| Canada | 2015 | 50 |
| Mexico | 2013 | 300 |
| UK | 2014 | 150 |
| USA | 2015 | 75 |
Databinding:
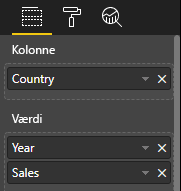
Power BI viser dine data som tabeldatavisningen. Antag ikke, at dataene er sorteret.
{
"table" : {
"columns": [...],
"rows": [
[
"Canada",
2014,
630
],
[
"Canada",
2015,
490
],
[
"Mexico",
2013,
645
],
[
"UK",
2014,
831
],
[
"USA",
2015,
650
],
[
"USA",
2016,
350
]
]
}
}
Hvis du vil aggregere dataene, skal du vælge det ønskede felt og derefter vælge Sum.
Kodeeksempel til behandling af tilknytning af tabeldatavisning.
"use strict";
import "./../style/visual.less";
import powerbi from "powerbi-visuals-api";
// ...
import DataViewMetadataColumn = powerbi.DataViewMetadataColumn;
import DataViewTable = powerbi.DataViewTable;
import DataViewTableRow = powerbi.DataViewTableRow;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private table: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.table = document.createElement("table");
this.target.appendChild(this.table);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const tableDataView: DataViewTable = dataView.table;
if (!tableDataView) {
return
}
while(this.table.firstChild) {
this.table.removeChild(this.table.firstChild);
}
//draw header
const tableHeader = document.createElement("th");
tableDataView.columns.forEach((column: DataViewMetadataColumn) => {
const tableHeaderColumn = document.createElement("td");
tableHeaderColumn.innerText = column.displayName
tableHeader.appendChild(tableHeaderColumn);
});
this.table.appendChild(tableHeader);
//draw rows
tableDataView.rows.forEach((row: DataViewTableRow) => {
const tableRow = document.createElement("tr");
row.forEach((columnValue: PrimitiveValue) => {
const cell = document.createElement("td");
cell.innerText = columnValue.toString();
tableRow.appendChild(cell);
})
this.table.appendChild(tableRow);
});
}
}
Filen med visualiseringstypografier style/visual.less indeholder layoutet for tabellen:
table {
display: flex;
flex-direction: column;
}
tr, th {
display: flex;
flex: 1;
}
td {
flex: 1;
border: 1px solid black;
}
Den resulterende visualisering ser sådan ud:
Matrixdatatilknytning
Matrixdatatilknytning ligner tabeldatatilknytning, men rækkerne præsenteres hierarkisk. En hvilken som helst af datarolleværdierne kan bruges som en kolonneoverskriftsværdi.
{
"dataRoles": [
{
"name": "Category",
"displayName": "Category",
"displayNameKey": "Visual_Category",
"kind": "Grouping"
},
{
"name": "Column",
"displayName": "Column",
"displayNameKey": "Visual_Column",
"kind": "Grouping"
},
{
"name": "Measure",
"displayName": "Measure",
"displayNameKey": "Visual_Values",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"matrix": {
"rows": {
"for": {
"in": "Category"
}
},
"columns": {
"for": {
"in": "Column"
}
},
"values": {
"select": [
{
"for": {
"in": "Measure"
}
}
]
}
}
}
]
}
Hierarkisk struktur af matrixdata
Power BI opretter en hierarkisk datastruktur. Roden af træhierarkiet indeholder data fra kolonnen Overordnede for datarollen Category med underordnede elementer fra kolonnen Underordnede i datarolletabellen.
Semantisk model:
| Overordnede elementer | Underordnede | Børnebørn | Kolonner | Værdier |
|---|---|---|---|---|
| Overordnet1 | Underordnet1 | Underordnet underordnet1 | Kol1 | 5 |
| Overordnet1 | Underordnet1 | Underordnet underordnet1 | Col2 | 6 |
| Overordnet1 | Underordnet1 | Underordnet underordnet2 | Kol1 | 7 |
| Overordnet1 | Underordnet1 | Underordnet underordnet2 | Col2 | 8 |
| Overordnet1 | Underordnet2 | Underordnet underordnet3 | Kol1 | 5 |
| Overordnet1 | Underordnet2 | Underordnet underordnet3 | Col2 | 3 |
| Overordnet1 | Underordnet2 | Underordnet underordnet4 | Kol1 | 4 |
| Overordnet1 | Underordnet2 | Underordnet underordnet4 | Col2 | 9 |
| Overordnet1 | Underordnet2 | Underordnet underordnet5 | Kol1 | 3 |
| Overordnet1 | Underordnet2 | Underordnet underordnet5 | Col2 | 5 |
| Overordnet2 | Underordnet3 | Underordnet underordnet6 | Kol1 | 0 |
| Overordnet2 | Underordnet3 | Underordnet underordnet6 | Col2 | 2 |
| Overordnet2 | Underordnet3 | Underordnet underordnet7 | Kol1 | 7 |
| Overordnet2 | Underordnet3 | Underordnet underordnet7 | Col2 | 0 |
| Overordnet2 | Underordnet3 | Underordnet (underordnet)8 | Kol1 | 10 |
| Overordnet2 | Underordnet3 | Underordnet (underordnet)8 | Col2 | 13 |
Power BI's kernematrixvisualisering gengiver dataene som en tabel.
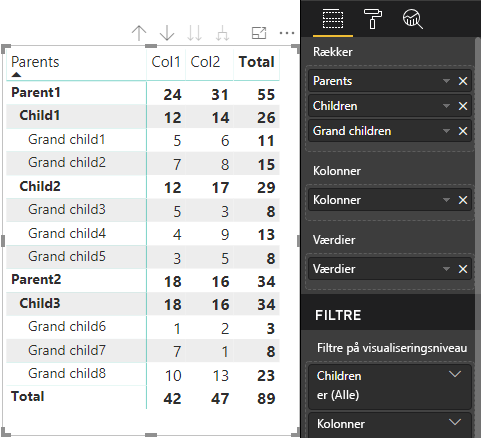
Visualiseringen henter datastrukturen som beskrevet i følgende kode (kun de første to tabelrækker vises her):
{
"metadata": {...},
"matrix": {
"rows": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Parent1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 1,
"levelValues": [...],
"value": "Child1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 2,
"levelValues": [...],
"value": "Grand child1",
"identity": {...},
"values": {
"0": {
"value": 5 // value for Col1
},
"1": {
"value": 6 // value for Col2
}
}
},
...
]
},
...
]
},
...
]
}
},
"columns": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Col1",
"identity": {...}
},
{
"level": 0,
"levelValues": [...],
"value": "Col2",
"identity": {...}
},
...
]
}
},
"valueSources": [...]
}
}
Udvid og skjul rækkeoverskrifter
For API 4.1.0 eller nyere understøtter matrixdata udvidelse og skjulning af rækkeoverskrifter. Fra API 4.2 kan du udvide/skjule hele niveauet programmatisk. Funktionen Udvid og skjul optimerer hentning af data til dataView ved at give brugeren mulighed for at udvide eller skjule en række uden at hente alle dataene til det næste niveau. Den henter kun dataene for den valgte række. Udvidelsestilstanden for rækkeoverskriften forbliver ensartet på tværs af bogmærker og endda på tværs af gemte rapporter. Det er ikke specifikt for hver enkelt visualisering.
Udvid og skjul kommandoer kan føjes til genvejsmenuen ved at angive dataRoles parameteren til showContextMenu metoden .
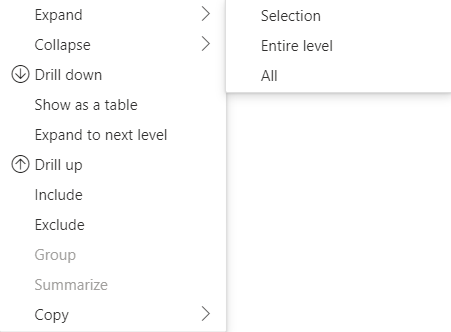
Hvis du vil udvide et stort antal datapunkter, skal du bruge API'en til hentning af flere data med API'en udvid/skjul.
API-funktioner
Følgende elementer er føjet til API version 4.1.0 for at aktivere udvidelse og skjulning af rækkeoverskrifter:
Flaget
isCollapsedDataViewTreeNodei :interface DataViewTreeNode { //... /** * TRUE if the node is Collapsed * FALSE if it is Expanded * Undefined if it cannot be Expanded (e.g. subtotal) */ isCollapsed?: boolean; }Metoden
toggleExpandCollapsei grænsefladenISelectionManger:interface ISelectionManager { //... showContextMenu(selectionId: ISelectionId, position: IPoint, dataRoles?: string): IPromise<{}>; // dataRoles is the name of the role of the selected data point toggleExpandCollapse(selectionId: ISelectionId, entireLevel?: boolean): IPromise<{}>; // Expand/Collapse an entire level will be available from API 4.2.0 //... }Flaget
canBeExpandedi DataViewHierarchyLevel:interface DataViewHierarchyLevel { //... /** If TRUE, this level can be expanded/collapsed */ canBeExpanded?: boolean; }
Krav til visualiseringer
Sådan aktiverer du funktionen Udvid skjul i en visualisering ved hjælp af matrixdatavisningen:
Føj følgende kode til filen capabilities.json:
"expandCollapse": { "roles": ["Rows"], //”Rows” is the name of rows data role "addDataViewFlags": { "defaultValue": true //indicates if the DataViewTreeNode will get the isCollapsed flag by default } },Bekræft, at rollerne kan analyseres:
"drilldown": { "roles": ["Rows"] },For hver node skal du oprette en forekomst af valggeneratoren
withMatrixNodeved at kalde metoden på det valgte nodehierarkiniveau og oprette enselectionId. Eksempler:let nodeSelectionBuilder: ISelectionIdBuilder = visualHost.createSelectionIdBuilder(); // parantNodes is a list of the parents of the selected node. // node is the current node which the selectionId is created for. parentNodes.push(node); for (let i = 0; i < parentNodes.length; i++) { nodeSelectionBuilder = nodeSelectionBuilder.withMatrixNode(parentNodes[i], levels); } const nodeSelectionId: ISelectionId = nodeSelectionBuilder.createSelectionId();Opret en forekomst af valgstyringen, og brug
selectionManager.toggleExpandCollapse()metoden med parameteren for ,selectionIdsom du har oprettet for den valgte node. Eksempel:// handle click events to apply expand\collapse action for the selected node button.addEventListener("click", () => { this.selectionManager.toggleExpandCollapse(nodeSelectionId); });
Bemærk
- Hvis den valgte node ikke er en rækkenode, ignorerer PowerBI udvidelses- og skjulkald, og kommandoerne udvid og skjul fjernes fra genvejsmenuen.
- Parameteren
dataRoleser kun påkrævet forshowContextMenumetoden, hvis visualiseringen understøtterdrilldownellerexpandCollapsefunktioner. Hvis visualiseringen understøtter disse funktioner, men dataRoles ikke blev angivet, sendes der en fejl til konsollen, når udviklervisualiseringen bruges, eller hvis der foretages fejlfinding af en offentlig visualisering med fejlfindingstilstand aktiveret.
Overvejelser og begrænsninger
- Når du har udvidet en node, anvendes der nye datagrænser på DataView. Den nye DataView indeholder muligvis ikke nogle af de noder, der blev præsenteret i den forrige DataView.
- Når du bruger udvid eller skjul, tilføjes totaler, også selvom visualiseringen ikke har anmodet om dem.
- Udvidelse og skjulning af kolonner understøttes ikke.
Bevar alle metadatakolonner
For API 5.1.0 eller nyere understøttes opbevaring af alle metadatakolonner. Denne funktion gør det muligt for visualiseringen at modtage metadataene for alle kolonner, uanset hvad deres aktive projektioner er.
Føj følgende linjer til din capabilities.json-fil :
"keepAllMetadataColumns": {
"type": "boolean",
"description": "Indicates that visual is going to receive all metadata columns, no matter what the active projections are"
}
Hvis du angiver denne egenskab til true , modtager du alle metadataene, herunder fra skjulte kolonner. Hvis du angiver eller lader den false være udefineret, modtager du kun metadata for kolonner med aktive projektioner (f.eks. udvidet).
Algoritme til datareduktion
Algoritmen til datareduktion styrer, hvilke data og hvor mange data der modtages i datavisningen.
Antallet er angivet til det maksimale antal værdier, som datavisningen kan acceptere. Hvis der er mere end antal værdier, bestemmer datareduktionsalgoritmen, hvilke værdier der skal modtages.
Algoritmetyper for datareduktion
Der er fire typer indstillinger for algoritmen til datareduktion:
top: De første antal værdier hentes fra den semantiske model.bottom: De sidste antal værdier hentes fra den semantiske model.sample: De første og sidste elementer er inkluderet, og antallet af elementer med lige store intervaller mellem dem. Hvis du f.eks. har en semantisk model [0, 1, 2, ... 100] og et antal på 9, modtager du værdierne [0, 10, 20 ... 100].window: Indlæser ét vindue med datapunkter ad gangen, der indeholder antal elementer.topI øjeblikket ogwindower tilsvarende. Fremover understøttes en vinduesindstilling fuldt ud.
Som standard anvendes den øverste algoritme til datareduktion i alle Power BI-visualiseringer, hvor antallet er angivet til 1000 datapunkter. Denne standard svarer til at angive følgende egenskaber i filen capabilities.json :
"dataReductionAlgorithm": {
"top": {
"count": 1000
}
}
Du kan ændre optællingsværdien til en vilkårlig heltalsværdi op til 30000. R-baserede Power BI-visualiseringer kan understøtte op til 15.000 rækker.
Brug af algoritme til datareduktion
Algoritmen til datareduktion kan bruges i tilknytning af datavisning efter kategori, tabel eller matrix.
I kategorisk datatilknytning kan du føje algoritmen til afsnittet "kategorier" og/eller "gruppe" i values for kategorisk datatilknytning.
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" },
"dataReductionAlgorithm": {
"window": {
"count": 300
}
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
],
"dataReductionAlgorithm": {
"top": {
"count": 100
}
}
}
}
}
}
I tilknytning af tabeldatavisning skal du anvende algoritmen til datareduktion på rows sektionen i tilknytningstabellen Datavisning.
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"top": {
"count": 2000
}
}
}
}
}
]
Du kan anvende algoritmen til datareduktion på afsnittene rows og columns i tilknytningsmatrixen Datavisning.