Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
I denne artikel opsummeres skalerbarhed og ydeevneforskelle mellem sideinddelte rapporter i Power BI-tjenesten i forhold til SQL Server Reporting Services/Power BI-rapportserver. Artiklen er beregnet til brugere, der overfører sideinddelte rapporter fra det lokale miljø til Power BI-tjenesten. Derudover giver den også indsigt i, hvordan du optimerer ydeevnen for sideinddelte rapporter i tjenesten.
Overvejelser i forbindelse med skalerbarhed
Når du sammenligner skalerbarheden af sideinddelte rapporter i Power BI-tjenesten i forhold til det lokale miljø, er der to primære overvejelser: Om udførelsesmiljøet er optimeret til at håndtere de udtryk, du bruger, og mængden af data. Dette er nogle af de faktorer, der er afgørende for at forbedre skalerbarheden af dine sideinddelte rapporter i tjenesten.
Udførelsesmiljø
En sideinddelt rapport kan køre i to forskellige udførelsesmiljøer: standardmiljøet og det optimerede miljø. Den primære forskel mellem disse miljøer er, at optimeret miljø kan håndtere højere datamængder sammenlignet med standardkørselsmiljøet. De udtryk, der bruges i rapporten, bestemmer udførelsesmiljøet, og brugerne kan ikke ændre det via nogen indstillinger eller konfigurationer. Den eneste måde at sikre, at en rapport kører i et optimeret miljø, er ved at fjerne ikke-understøttede udtryk, fordi det optimerede miljø kun understøtter et bestemt undersæt af rapportudtryk.
Hvis din rapport indeholder udtryk, der ikke understøttes, kan du overveje at fjerne eller opdatere disse udtryk for at sikre, at rapporten kører i et optimeret miljø. En metode er at flytte beregninger til datasætforespørgslen. En anden fordel ved at bruge beregnede felter i datakilderne for den semantiske model er, at andre rapporter også kan bruge dem. Power Query er en anden mulighed for at udføre avancerede beregninger og databehandlinger uden for den sideinddelte rapport. Du kan finde flere oplysninger her.
Bemærk
Et eksempel på et udtryk, der ikke understøttes, er brugen af beregnede felter i RDL'en, f.eks.: If(Weekday(Fields!SalesDate.Value) > 5, "Relax", "Work"). Weekday er en funktion, der endnu ikke er optimeret. I stedet for at bruge et rapportudtryk kan dette beregnes som en del af en SQL-forespørgsel. For SQL Server/Azure SQL, der kan udføres ved hjælp af Funktionerne Transact SQL DATEPART og IF..ELSE.
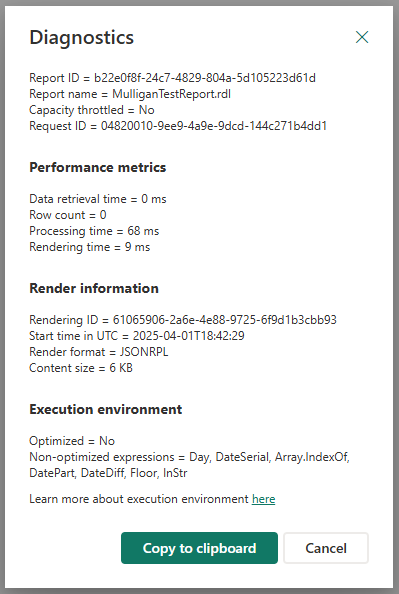
Hvis du vil kontrollere, om en rapport blev kørt i det optimerede miljø, skal du klikke på knappen Diagnosticering i den sideinddelte rapport og se afsnittet 'Udførelsesmiljø'. Hvis rapporten kører i det optimerede miljø, vises 'Optimeret' med 'Ja'. Hvis rapporten kører i det ikke-optimerede standardmiljø, vises der en liste over ikke-understøttede rapportudtryk i afsnittet Udførelsesmiljø. Du kan finde flere oplysninger om de målepunkter for ydeevnen, der vises på kortet Diagnosticering , her.
Store datamængder
Både standardmiljøer og optimerede udførelsesmiljøer for sideinddelte rapporter har specifikke grænser for datamængde, der, når de overskrides, gør behandlingen af rapporter betydeligt langsommere. Når ydeevnen bliver langsommere under eksportrapportscenariet, får brugeren vist advarslen på dette billede:
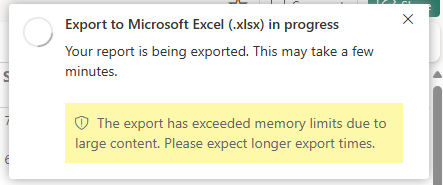
Dette problem opstår typisk i to scenarier:
Datadumps af tabeller uden grupperinger og mange kolonner/rækker: Disse datadumps kræver betydelige ressourcer, når den sideinddelte rapport eksporteres til Excel. Du kan også overveje at eksportere rapporten til CSV-format, hvilket er mindre intensivt.
Sammenlægning af store datamængder under rapportbehandling: I stedet for at aggregere store datamængder i sideinddelte rapporter skal du udføre disse sammenlægninger i den forespørgsel, der bruges af et datasæt for sideinddelte rapporter. Denne fremgangsmåde reducerer mængden af data, der behandles af sideinddelte rapporter, og forbedrer typisk den overordnede ydeevne, fordi datakilder som SQL Server eller Power BI Semantic Model er stærkt optimeret til datasammenlægning.
Den anbefalede tærskel for datamængde i et standardudførelsesmiljø, før rapportbehandlingen bliver markant langsommere, er 1.000.000 rækker med 15-20 kolonner, der består af en blanding af numeriske datatyper, datoer og strengdatatyper af lille til mellem lang længde.
Denne grænse fordobles for optimerede udførelsesmiljøer. Hvis du føjer billeddata (byte[]) til datadumps, øges datamængderne betydeligt. På samme måde vil valg af flere eller færre kolonner end angivet også påvirke datamængderne, og det samme gælder blandingen af datatyper.
Ydelsesovervejelser
Selv for mellemstore til små datamængder er der flere faktorer, der kan påvirke ydeevnen af sideinddelte rapporter i tjenesten i disse scenarier:
- Behandler rapportparametre , hver gang en rapport åbnes i Power BI-tjenesten.
- Gengivelse af rapporten, når en bruger klikker på knappen "Vis rapport".
- Hentning af data fra forskellige datakilder
Bedste fremgangsmåder til at forbedre behandlingen af rapportparametre
Rapportparametre kan understøttes af datasæt med tilgængelige værdier og standardværdier, hvilket ofte er tilfældet for flere parametre. Parametre kan også afhænge af andre parametre, f.eks. overlappende parametre. Derfor udføres parameterforespørgsler sekventielt. Når en rapport har overlappende parametre, køres hver parameteriseret forespørgsel, hver gang efterfølgende værdier vælges.
Da parameterværdier normalt er statiske og ikke ændres ofte, bruger SQL Server Reporting Services (SSRS) denne fordel til at tilbyde robust understøttelse af datasætcacher (som forklaret her ), hvilket forbedrer behandlingen af rapportparametre i SSRS. Sideinddelte rapporter i tjenesten understøtter dog ikke cachelagre af datasæt. Brugerne bør derfor følge disse bedste fremgangsmåder for at forbedre udførelsestiden for parameterforespørgsler for sideinddelte rapporter i tjenesten:
- Undgå at bruge parameterforespørgsler, der kører mod datakilder i det lokale miljø, som du får adgang til via en Power BI Gateway. Brug i stedet en semantisk Power BI-model som cache.
- Reducer mængden af data, der hentes af parameterforespørgsler, for at sikre effektivitet. Hentning af mere end 1.000 værdier kan være tidskrævende og er muligvis ikke brugervenlig i brugergrænsefladen.
- Brug Dataudvidelsen EnterData til et statisk sæt parameterværdier for at integrere dem i RDL'en. Ud over at angive parameterværdier kan disse datasæt også bruges i din rapport uden at køre en forespørgsel.
Bedste fremgangsmåder til forbedring af gengivelse af sideinddelte rapporter
På samme måde som med de retningslinjer, der er angivet i afsnittet om skalerbarhed, skal du undgå at bruge dynamiske forespørgsler til datakilder i det lokale miljø, der tilgås via en Power BI Gateway. Hvis du vil forbedre gengivelsen af rapporter i sideinddelte rapporter, skal du i stedet bruge en semantisk Power BI-model som cache. I stedet for at aggregere data i den sideinddelte rapport skal du udføre sammenlægninger i datasætforespørgslen for at reducere datamængden og forbedre ydeevnen. Brug datakilder som Azure SQL eller semantiske Power BI-modeller, der er optimeret til behandling af aggregeringer.
Undgå desuden at bruge datasæt- eller tabel-/matrixfiltre, da sideinddelte rapporter henter alle data først og derefter anvender filtre internt, hvilket påvirker ydeevnen. Brug i stedet filtre i forespørgsler om datasæt, når det er muligt.
Bedste praksis for effektiv datahentning
Multi-geo-miljøer, hvor rapporten og datakilden som en semantisk model befinder sig i forskellige områder, gør datahentning langsommere. Du kan finde mere vejledning til effektiv datahentning for sideinddelte rapporter her.
Relateret indhold
Du kan få flere oplysninger, der er relateret til denne artikel, i følgende ressourcer: