Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
I Power Query kan du transformere kolonner til attributværdipar, hvor kolonner bliver til rækker.
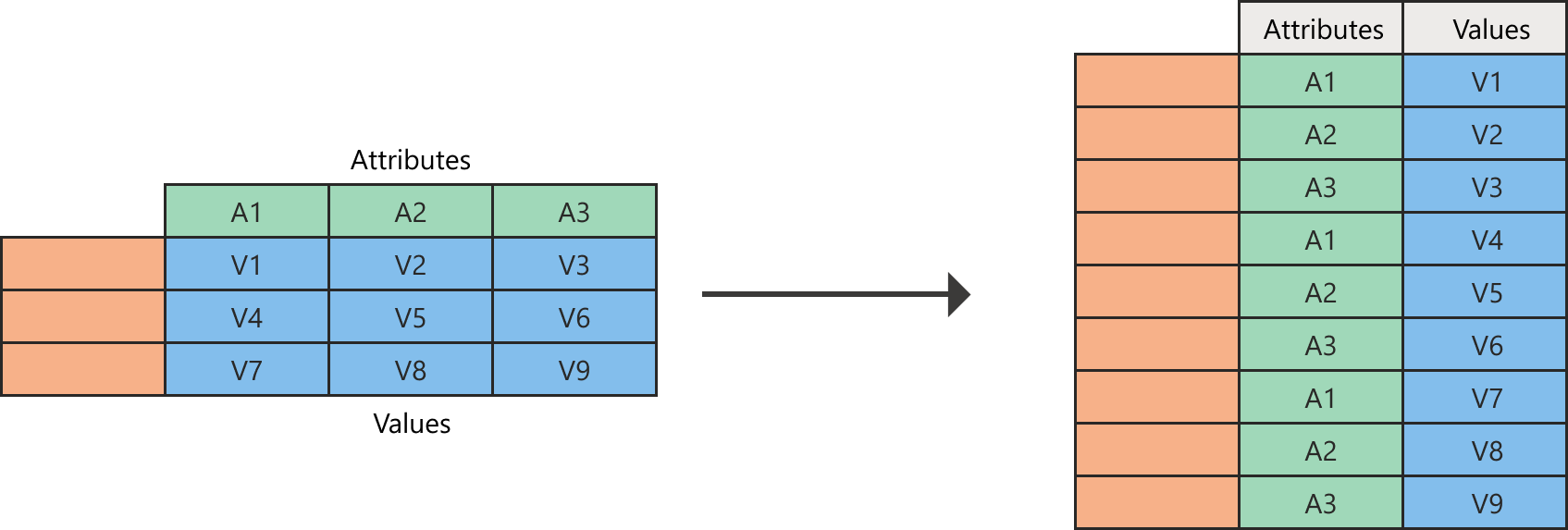
Diagram, der viser den venstre tabel med en tom kolonne og rækker og attributterne A1, A2 og A3 som kolonneoverskrifter. I denne tabel indeholder kolonnen A1 værdierne V1, V4 og V7. Kolonnen A2 indeholder værdierne V2, V5 og V8. Kolonnen A3 indeholder værdierne V3, V6 og V9. Når kolonnerne ikke erpivoterede, indeholder den højre tabel i diagrammet en tom kolonne og rækker. Kolonnen Attributter indeholder også ni rækker, hvor A1, A2 og A3 gentages tre gange. Til sidst indeholder kolonnen Values værdierne V1 til og med V9.
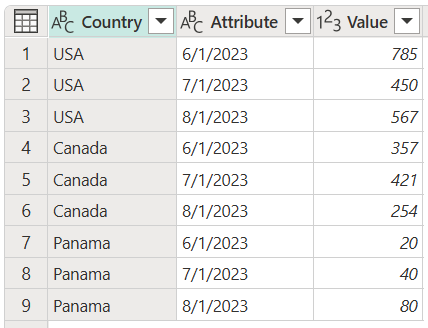
Hvis du f.eks. får en tabel som følgende, hvor landerækker og datokolonner opretter en matrix med værdier, er det svært at analysere dataene på en skalerbar måde.
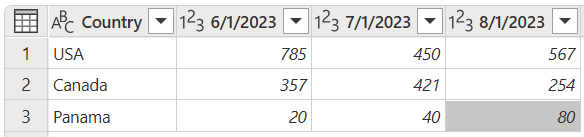
Skærmbillede af en tabel, der indeholder kolonnen Country i datatypen Text, og tre kolonner med datoerne 1. juni 2023, 1. juli 2023 og 1. august 2023 angivet som datatypen Heltal. Kolonnen Country indeholder USA i række 1, Canada i række 2 og Panama i række 3.
Du kan i stedet transformere tabellen til en tabel med ikke-udpivoterede kolonner, som vist på følgende billede. I den transformerede tabel er det nemmere at bruge datoen som en attribut til at filtrere efter.
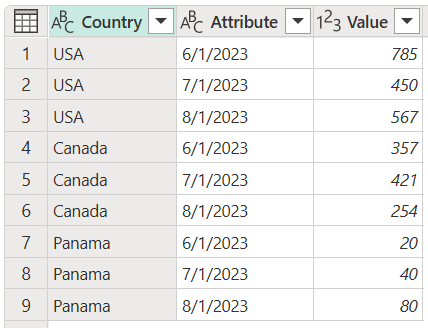
Skærmbillede af tabellen, der indeholder en kolonne af typen Country, der er angivet som datatypen Text, en attributkolonne, der er angivet som datatypen Text, og en værdikolonne, der er angivet som datatypen Heltal. Kolonnen Country indeholder USA i de første tre rækker, Canada i de næste tre rækker og Panama i de sidste tre rækker. Kolonnen Attribute indeholder datoen 1. juni 2023 i den første, fjerde og syvende række. Datoen den 1. juli 2023 vises i den anden, femte og ottende række. Til sidst findes datoen den 1. august 2023 i den tredje, sjette og niende række.
Nøglen i denne transformation er, at du har et sæt datoer i tabellen, som alle skal være en del af en enkelt kolonne. Den respektive værdi for hver dato og hvert land skal være i en anden kolonne og effektivt oprette et attributværdipar.
Power Query opretter altid attributværdiparret ved hjælp af to kolonner:
- Attribut: Navnet på de kolonneoverskrifter, der ikke blev hentet.
- Value: De værdier, der var under hver af de ikke-udpivoterede kolonneoverskrifter.
Der er flere steder i brugergrænsefladen, hvor du kan finde Unpivot-kolonner. Du kan højreklikke på de kolonner, du vil frigøre, eller du kan vælge kommandoen på fanen Transformér på båndet.
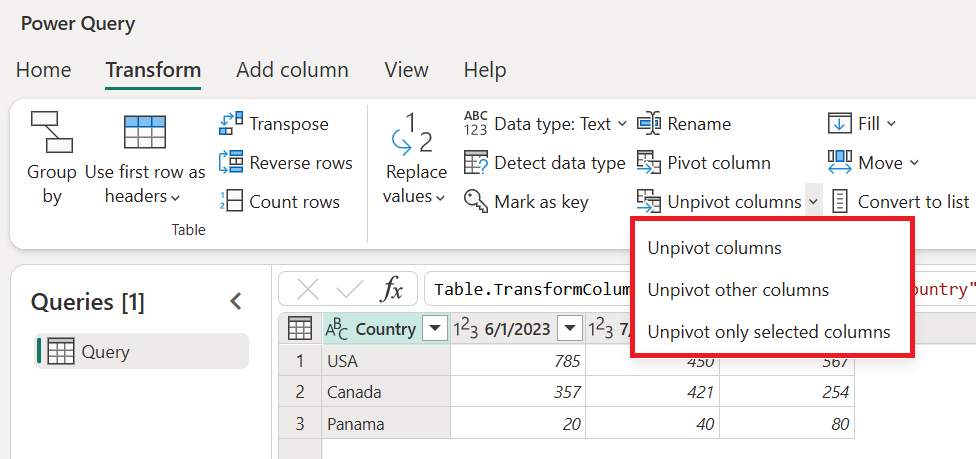
Du kan frigøre kolonner fra en tabel på tre måder:
- unpivotkolonner
- Frigør andre kolonner
- Ophæv kun markerede kolonner
Fjernpivotér kolonner
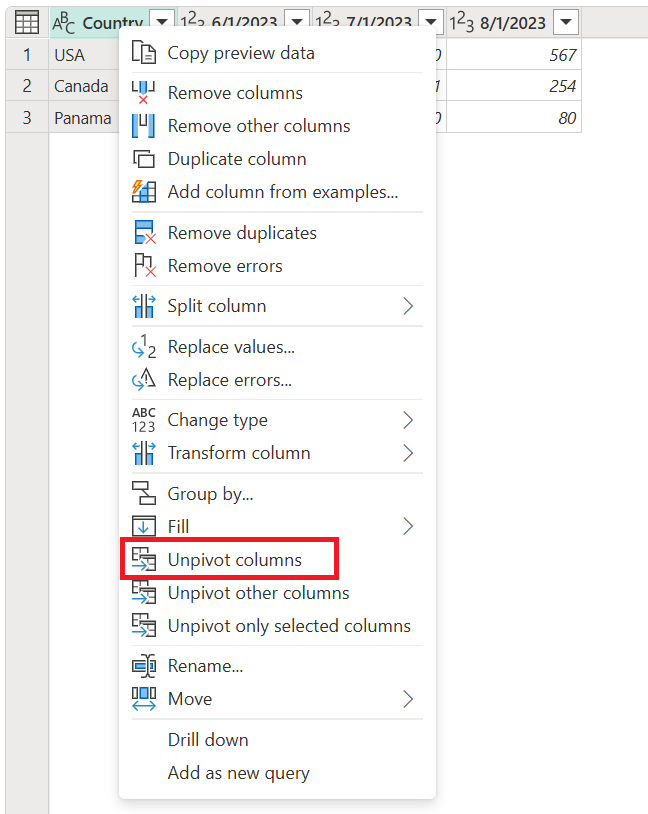
I det tidligere beskrevne scenarie skal du først vælge de kolonner, du vil frigøre. Du kan vælge Ctrl, når du vælger lige så mange kolonner, du har brug for. I dette scenarie skal du markere alle kolonner undtagen den med navnet Country. Når du har valgt kolonnerne, skal du højreklikke på en af de markerede kolonner og derefter vælge Ophæv kolonner.
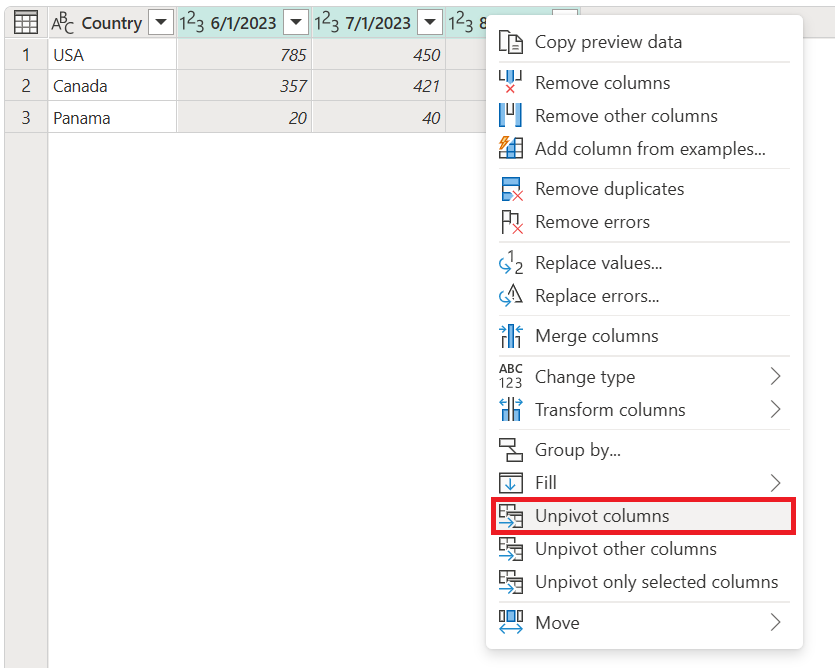
Skærmbillede af tabellen med kolonnerne 1. juni 2023, 1. juli 2023 og 1. august 2023 markeret, og kommandoen Unpivot columns er valgt i genvejsmenuen."
Resultatet af denne handling giver det resultat, der vises på følgende billede.

Særlige overvejelser
Når du har oprettet din forespørgsel fra de forrige trin, kan du forestille dig, at din indledende tabel opdateres, så den ligner følgende skærmbillede.
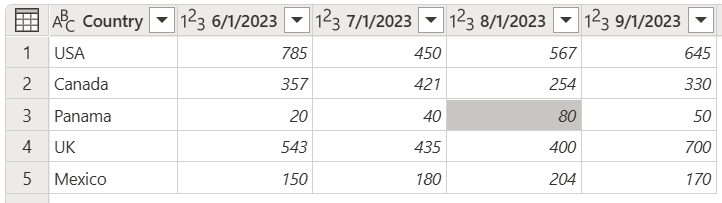
Skærmbillede af tabellen med de samme oprindelige datokolonner land, 1. juni 2023, 1. juli 2023 og august 2023 med tilføjelse af en datokolonne den 1. september 2023. Kolonnen Country indeholder stadig værdierne USA, Canada og Panama, men storbritannien er også føjet til fjerde række, og Mexico er føjet til femte række.
Bemærk, at du tilføjer en ny kolonne for datoen 1. september 2023 (1/9/2023) og to nye rækker for lande/områder Storbritannien og Mexico.
Hvis du opdaterer forespørgslen, kan du se, at handlingen udføres på den opdaterede kolonne, men ikke påvirker den kolonne, der ikke oprindeligt blev valgt (Countryi dette eksempel). Denne funktionsmåde betyder, at alle nye kolonner, du har føjet til kildetabellen, også fjernes.
På følgende billede kan du se, hvordan din forespørgsel ser ud efter opdateringen med den nye opdaterede kildetabel.
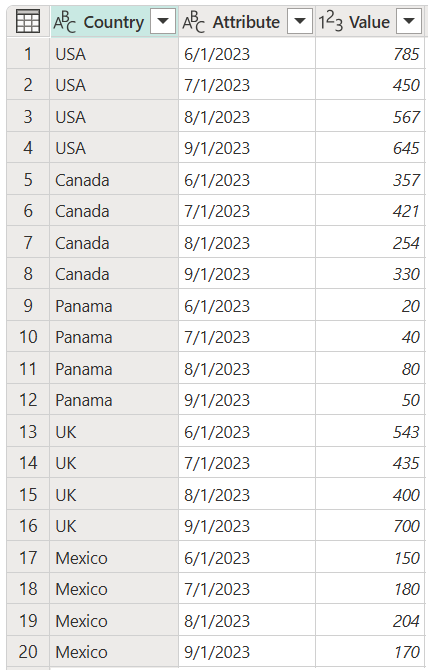
Skærmbillede af tabellen med kolonnerne Land, Attribut og Værdi. De første fire rækker i kolonnen Country indeholder USA, de anden fire rækker indeholder Canada, de tredje fire rækker indeholder Panama, de fire fjerde rækker indeholder Storbritannien, og de femte fire rækker indeholder Mexico. Kolonnen Attribute indeholder datoerne 1. juni 2023, 1. juli 2023 og august 2023 i de første fire rækker, som gentages for hvert land.
Frigør andre kolonner
Du kan også markere de kolonner, du ikke vil frigøre og frigøre resten af kolonnerne i tabellen. Denne handling er stedet, hvor Unpivot andre kolonner, kommer i spil.
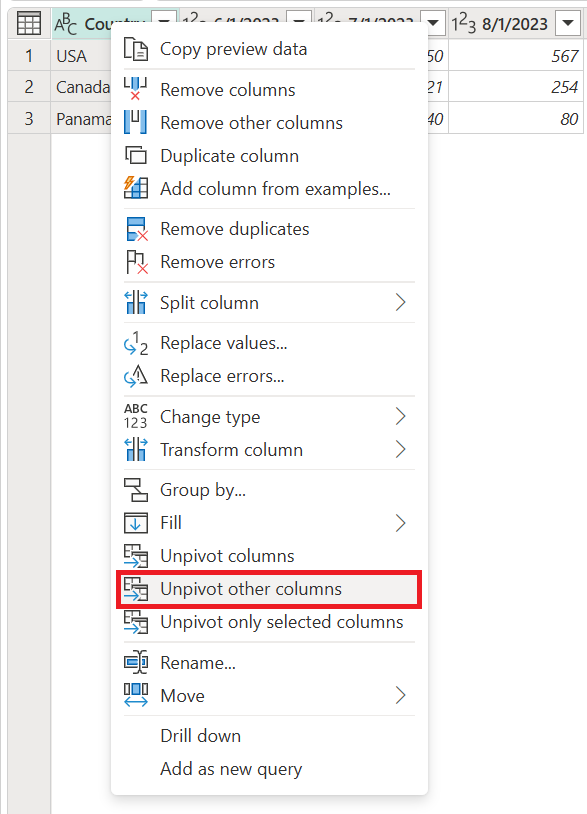
Resultatet af denne handling giver nøjagtigt det samme resultat som det, du fik fra Unpivot-kolonner.
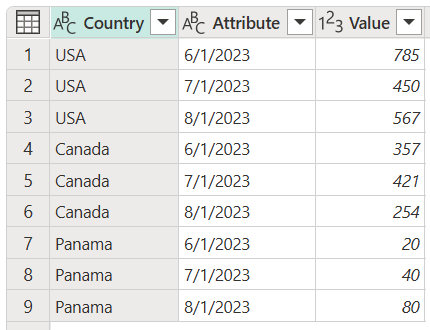
Skærmbillede af tabellen, der indeholder en kolonne af typen Country, der er angivet som datatypen Text, en attributkolonne, der er angivet som datatypen Text, og en værdikolonne, der er angivet som datatypen Heltal. Kolonnen Country indeholder USA i de første tre rækker, Canada i de næste tre rækker og Panama i de sidste tre rækker. Kolonnen Attribute indeholder datoen 1. juni 2023 i den første, fjerde og syvende række. Datoen den 1. juli 2023 er i den anden, femte og ottende række. Datoen den 1. august 2023 vises i tredje, sjette og niende række.
Seddel
Denne transformation er afgørende for forespørgsler, der har et ukendt antal kolonner. Handlingen fjerner alle kolonner fra tabellen med undtagelse af dem, du har valgt. Denne type transformation er en ideel løsning, hvis datakilden i dit scenarie fik nye datokolonner i en opdatering, fordi disse nye kolonner hentes og fjernes.
Særlige overvejelser
På samme måde som med de Unpivot-kolonner handling, hvis din forespørgsel opdateres, og der hentes flere data fra datakilden, fjernes alle kolonner undtagen dem, der tidligere er valgt.
For at illustrere denne proces skal du sige, at du har en ny tabel som den på følgende billede.
Skærmbillede af tabellen med kolonnerne Country, June 1, 2023, July 1, 2023, August 1, 2023 og 1. september 2023, hvor alle kolonner er angivet til datatypen Tekst. Kolonnen Country indeholder, fra top til bund, USA, Canada, Panama, Storbritannien og Mexico.
Du kan vælge kolonnen Country og derefter vælge Ophæv anden kolonne, hvilket giver følgende resultat.
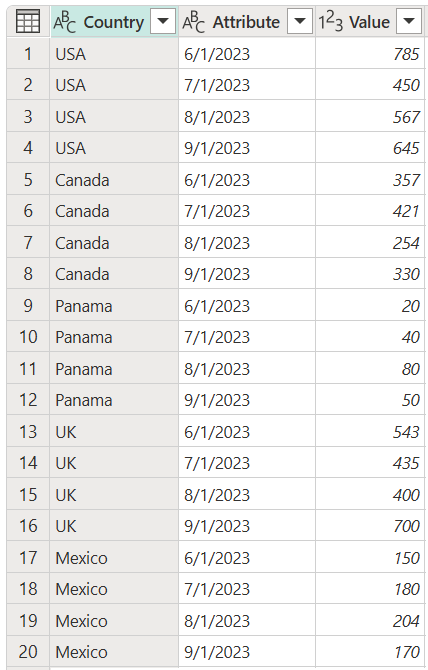
Skærmbillede af tabellen med kolonnerne Land, Attribut og Værdi. Kolonnerne Land og Attribut er angivet til datatypen Tekst. Kolonnen Værdi er angivet til datatypen Hele værdien. De første fire rækker i kolonnen Country indeholder USA, de anden fire rækker indeholder Canada, de tredje fire rækker indeholder Panama, de fire fjerde rækker indeholder Storbritannien, og de femte fire rækker indeholder Mexico. Kolonnen Attribute indeholder 1. juni 2023, 1. juli 2023, 1. august 2023 og 1. september 2023 i de første fire rækker, som gentages for hvert land.
Ophæv kun markerede kolonner
Formålet med denne sidste indstilling er kun at frigøre bestemte kolonner fra tabellen. Denne indstilling er vigtig i scenarier, hvor du arbejder med et ukendt antal kolonner fra din datakilde. Det giver dig mulighed for kun at frigøre de markerede kolonner.
Hvis du vil udføre denne handling, skal du vælge de kolonner, der skal frigøres, hvilket i dette eksempel er alle kolonner undtagen kolonnen Country. Højreklik derefter på en af de valgte kolonner, og vælg derefter Ophæv kun markerede kolonner.
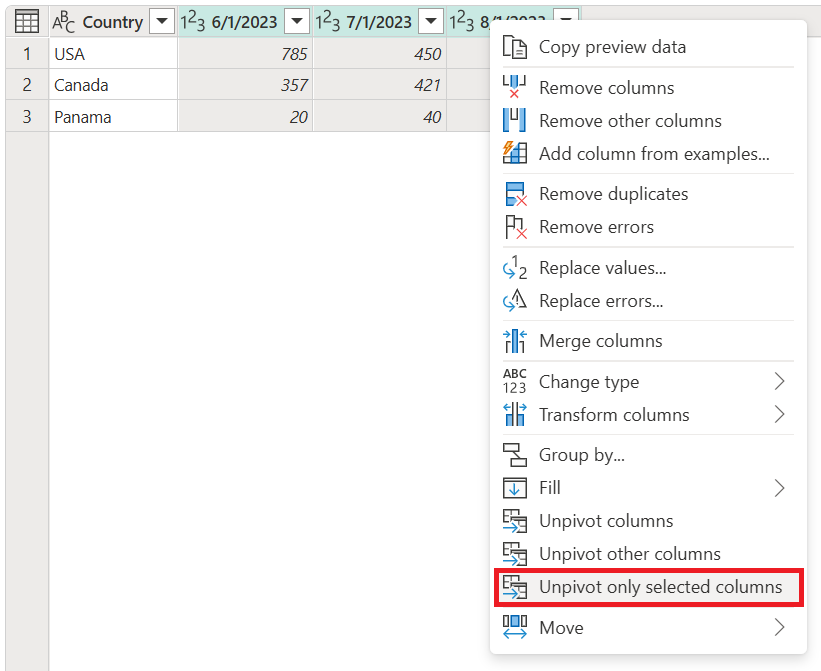
Bemærk, hvordan denne handling giver det samme output som de tidligere eksempler.
Skærmbillede af tabellen, der indeholder en kolonne af typen Country, der er angivet som datatypen Text, en attributkolonne, der er angivet som datatypen Text, og en værdikolonne, der er angivet som datatypen Heltal. Kolonnen Country indeholder USA i de første tre rækker, Canada i de næste tre rækker og Panama i de sidste tre rækker. Kolonnen Attribute indeholder datoen 1. juni 2023 i den første, fjerde og syvende række. Datoen den 1. juli 2023 er i den anden, femte og ottende række. Datoen den 1. august 2023 vises i tredje, sjette og niende række.
Særlige overvejelser
Hvis vores kildetabel efter en opdatering ændres til at have en ny 1.9.2020 kolonne og nye rækker for Storbritannien og Mexico, er resultatet af forespørgslen anderledes end i de forrige eksempler. Lad os sige, at vores kildetabel efter en opdatering ændres til tabellen på følgende billede.
Outputtet af vores forespørgsel ligner følgende billede.
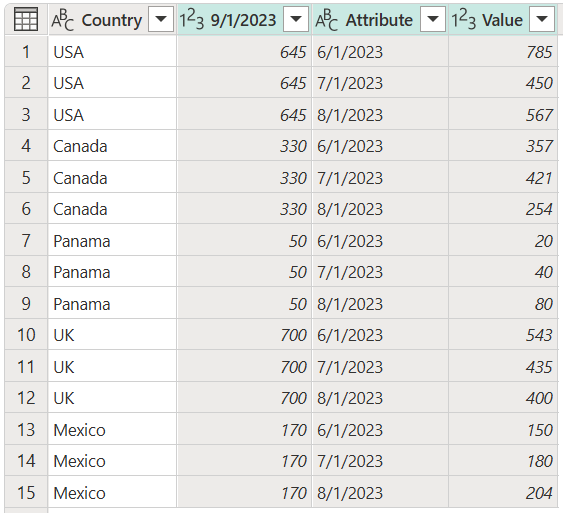
Det ser sådan ud, fordi unpivot-handlingen kun blev anvendt på 1/6/2020, 7/1/2020og 8/1/2020 kolonner, så kolonnen med overskriften 9/1/2020 forbliver uændret.