Notfallwiederherstellung in Azure Service Fabric
Zur Gewährleistung von hoher Verfügbarkeit muss unter anderem sichergestellt werden, dass Dienste verschiedenste Arten von Ausfällen überstehen können. Dies ist besonders wichtig bei Ausfällen, die überraschend auftreten oder sich Ihrer Kontrolle entziehen.
In diesem Artikel werden einige allgemeine Ausfälle beschrieben, die sich als äußerst problematisch erweisen könnten, wenn sie nicht angemessen im Modell berücksichtigt und behandelt werden. Darüber hinaus enthält der Artikel Informationen zu Abhilfen und Maßnahmen, die Sie ergreifen können, wenn dennoch ein Notfall eintritt. Dadurch soll das Risiko von Ausfallzeiten oder Datenverlusten im Falle von geplanten oder anderweitigen Ausfällen möglichst gering gehalten oder ganz beseitigt werden.
Vermeiden von Notfällen
Das Hauptziel von Azure Service Fabric ist, Sie dabei zu unterstützen, Ihre Umgebung und Ihre Dienste so zu gestalten, dass sich allgemeine Ausfälle nicht zu einem Notfall entwickeln.
Grundsätzlich kann zwischen zwei Arten von Notfall-/Ausfallszenarien unterschieden werden:
- Hardware- und Softwarefehler
- Vorgangsbedingte Fehler
Hardware- und Softwarefehler
Hardware- und Softwarefehler sind unberechenbar. Sie lassen sich am einfachsten kompensieren, indem mehrere Kopien des Diensts über die Fehlergrenzen von Hardware oder Software hinweg ausgeführt werden.
Wenn der Dienst beispielsweise nur auf einem Computer ausgeführt wird, ist der Ausfall dieses Computers ein schwerwiegendes Problem für diesen Dienst. Dieses Problem lässt sich am einfachsten vermeiden, indem der Dienst auf mehreren Computern ausgeführt wird. Darüber hinaus muss mithilfe von Tests sichergestellt werden, dass der Ausfall eines der Computer die Dienstausführung nicht beeinträchtigt. Die Kapazitätsplanung stellt sicher, dass an anderer Stelle eine Ersatzinstanz erstellt werden kann und die Verringerung der Kapazität keine Überlastung der übrigen Dienste zur Folge hat.
Das gleiche Muster kann auch zur Vermeidung aller anderen Arten von Ausfällen verwendet werden. Wenn Sie sich z. B. Sorgen um den Ausfall eines SANs machen, nutzen Sie mehrere SANs. Wenn Sie sich Sorgen um den Verlust eines Serverracks machen, nutzen Sie mehrere Serverracks. Wenn Sie sich Sorgen um den Verlust von Rechenzentren machen, sollte Ihr Dienst in mehreren Azure-Regionen, Azure-Verfügbarkeitszonen oder Ihren eigenen Rechenzentren ausgeführt werden.
Wenn ein Dienst auf mehrere physische Instanzen (Computer, Racks, Rechenzentren, Regionen) verteilt wird, unterliegen Sie weiterhin einigen Typen gleichzeitiger Ausfälle. Einzelne und sogar mehrere Ausfälle eines bestimmten Typs (z. B. eines einzelnen virtuellen Computers oder einer fehlerhaften Netzwerkverbindung) werden automatisch verarbeitet und sind daher kein „Notfall“ mehr.
Service Fabric bietet Mechanismen zur Erweiterung des Clusters und kümmert sich um die Wiederherstellung ausgefallener Knoten und Dienste. Darüber hinaus ermöglicht Service Fabric das Ausführen mehrerer Instanzen Ihrer Dienste, um zu vermeiden, dass ungeplante Ausfälle sich zu echten Notfällen entwickeln.
Manchmal ist es jedoch möglicherweise aus diversen Gründen nicht sinnvoll, eine Bereitstellung zu verwenden, die groß genug ist, um Ausfälle zu überbrücken. Beispielsweise könnte die Menge an benötigten Hardwareressourcen so groß und das Risiko für einen Ausfall so gering sein, dass sich die Ausgaben für die Ressourcen nicht lohnen. Im Zusammenhang mit verteilten Anwendungen führen zusätzliche Kommunikations-Hops oder Zustandsreplikationen über geografische Entfernungen hinweg möglicherweise zu nicht akzeptablen Verzögerungen. Diese Grenze ist jeweils anwendungsspezifisch.
Bei Softwarefehlern könnte der Fehler auch auf den Dienst zurückzuführen sein, den Sie skalieren möchten. In diesem Fall lässt sich ein Notfall nicht durch mehrere Kopien verhindern, da die Fehlerbedingung in allen Instanzen vorhanden ist.
Vorgangsbedingte Fehler
Selbst wenn Ihr Dienst über den gesamten Globus verteilt und durch mehrere Redundanzen abgesichert ist, kann es noch zu einem Notfall kommen. So könnte beispielsweise jemand versehentlich die Konfiguration des DNS-Namens für den Dienst ändern oder sogar den gesamten Dienst löschen.
Angenommen, Sie verfügen über einen zustandsbehafteten Service Fabric-Dienst, und jemand löscht diesen Dienst versehentlich. Sofern keine andere risikomindernde Maßnahme ergriffen wurde, geht dadurch der Dienst mitsamt seinen Zustandsinformationen verloren. Diese Arten von vorgangsbedingten Notfällen („Hoppla“) erfordern andere risikomindernde Maßnahmen und Wiederherstellungsschritte als reguläre ungeplante Ausfälle.
Sie lassen sich am besten wie folgt vermeiden:
- Operativen Zugriff auf die Umgebung einschränken.
- Gefährliche Vorgänge streng überwachen.
- Automatisierung erzwingen, manuelle Änderungen oder Out-of-Band-Änderungen verhindern sowie bestimmte Umgebungsänderungen vor deren Anwendung überprüfen.
- Stellen Sie sicher, dass destruktive Vorgänge „vorläufig“ sind. Vorläufige Vorgänge werden nicht sofort wirksam oder können innerhalb eines Zeitfensters rückgängig gemacht werden.
Service Fabric bietet Mechanismen zur Verhinderung vorgangsbedingter Fehler – unter anderem eine rollenbasierte Zugriffssteuerung für Clustervorgänge. Die meisten dieser vorgangsbedingten Fehler lassen sich jedoch nur mit organisatorischen Maßnahmen und anderen Systemen vermeiden. Service Fabric bietet Mechanismen zur Bewältigung vorgangsbedingter Fehler. Hierzu zählen insbesondere die Sicherung und Wiederherstellung für zustandsbehaftete Dienste.
Bewältigen von Ausfällen
Das Ziel von Service Fabric ist die automatische Bewältigung von Ausfällen. Zur Bewältigung einiger Ausfallarten müssen Dienste jedoch über zusätzlichen Code verfügen. Andere Arten von Ausfällen sollten hingegen aus Sicherheitsgründen sowie zur Gewährleistung der Geschäftskontinuität nicht automatisch behandelt werden.
Behandeln einzelner Ausfälle
Einzelne Computer können aus verschiedensten Gründen ausfallen. Manche Ausfälle sind auf Hardwareprobleme wie etwa den Ausfall des Netzteils oder der Netzwerkhardware zurückzuführen. Andere sind softwarebedingt. Hierzu zählt etwa der Ausfall des Betriebssystems und des eigentlichen Diensts. Service Fabric erkennt diese Arten von Ausfällen automatisch – einschließlich Fälle, in denen der Computer aufgrund von Netzwerkproblemen nicht mehr mit anderen Computern kommunizieren kann.
Die Ausführung einer einzelnen Dienstinstanz führt unabhängig von der Art des Diensts zu Ausfallzeiten für diesen Dienst, wenn bei dieser einzelnen Kopie des Codes aus irgendeinem Grund ein Fehler auftritt.
Einen einzelnen Ausfall können Sie am einfachsten behandeln, indem Sie dafür sorgen, dass Ihre Dienste standardmäßig auf mehreren Knoten ausgeführt werden. Stellen Sie für zustandslose Dienste sicher, dass InstanceCount größer als 1 ist. Bei zustandsbehafteten Diensten wird für TargetReplicaSetSize und MinReplicaSetSize mindestens der Wert 3 empfohlen. Durch die Ausführung mehrerer Kopien des Dienstcodes wird sichergestellt, dass der Dienst automatisch mit einem einzelnen Ausfall zurechtkommt.
Behandeln koordinierter Ausfälle
Koordinierte Ausfälle können in einem Cluster aufgrund von geplanten oder ungeplanten Infrastrukturausfällen und -änderungen sowie aufgrund von geplanten Softwareänderungen auftreten. Service Fabric modelliert Infrastrukturzonen, in denen koordinierte Ausfälle auftreten, als Fehlerdomänen. Bereiche, in denen koordinierte Softwareänderungen auftreten, werden als Upgradedomänen modelliert. Weitere Informationen zu Fehlerdomänen, Upgradedomänen und Clustertopologie finden Sie unter Beschreiben eines Service Fabric-Clusters in Azure mithilfe des Clusterressourcen-Managers.
Fehler- und Upgradedomänen werden von Service Fabric bei der Planung des Ausführungsorts Ihrer Dienste standardmäßig berücksichtigt. Service Fabric versucht standardmäßig, Ihre Dienste über mehrere Fehler- und Upgradedomänen hinweg auszuführen, um im Falle von geplanten oder ungeplanten Änderungen die Verfügbarkeit Ihrer Dienste zu gewährleisten.
Ein Beispiel: Angenommen, aufgrund eines defekten Netzteils fallen mehrere Computer eines Racks gleichzeitig aus. Wenn mehrere Kopien des Diensts ausgeführt werden, ist der Verlust mehrerer Computer in der ausgefallenen Fehlerdomäne nur ein weiteres Beispiel für einen einzelnen Ausfall eines Diensts. Aus diesem Grund ist die Verwaltung von Fehler- und Upgradedomänen so wichtig, um die Hochverfügbarkeit Ihrer Dienste zu gewährleisten.
Wenn Service Fabric in Azure ausgeführt wird, erfolgt die Verwaltung von Fehler- und Upgradedomänen automatisch. In anderen Umgebungen ist das unter Umständen nicht der Fall. Wenn Sie Ihre eigenen Cluster lokal erstellen, achten Sie auf eine korrekte Zuordnung und Planung des Fehlerdomänenlayouts.
Upgradedomänen eignen sich für die Modellierung von Bereichen mit gleichzeitigen Softwareupgrades. Daher definieren Upgradedomänen häufig auch die Bereiche, in denen Software während geplanter Upgrades offline geschaltet wird. Upgrades für Service Fabric und Ihre Dienste folgen dem gleichen Modell. Weitere Informationen zu parallelen Upgrades, Upgradedomänen und dem Service Fabric-Integritätsmodell, mit dem unter anderem verhindert wird, dass unbeabsichtigte Änderungen den Cluster und den Dienst beeinträchtigen, finden Sie hier:
- Anwendungsupgrade
- Tutorial für das Upgraden von Service Fabric-Anwendungen mithilfe von Visual Studio
- Einführung in die Service Fabric-Integritätsüberwachung
Mithilfe der von Service Fabric Explorer bereitgestellten Clusterzuweisung können Sie das Layout Ihres Clusters visualisieren:
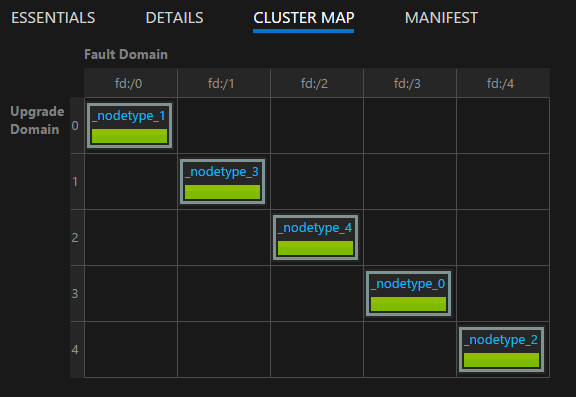
Hinweis
Die Modellierung von Ausfallbereichen, parallele Upgrades, die Ausführung mehrerer Instanzen Ihres Dienstcodes und -zustands, Platzierungsregeln, die sicherstellen, dass Ihre Dienste über Fehler- und Upgradedomänen hinweg ausgeführt werden, sowie die integrierte Integritätsüberwachung sind nur einige der Features, mit denen Service Fabric dafür sorgt, dass sich normale Betriebsprobleme und Ausfälle nicht zu Notfällen entwickeln.
Behandeln gleichzeitiger Hardware- oder Softwareausfälle
Wir haben über einzelne Ausfälle gesprochen. Wie Sie sehen, können Sie diese sowohl bei zustandslosen als auch bei zustandsbehafteten Diensten recht einfach behandeln, indem Sie mehrere Kopien des Codes (und des Zustands) über Fehler- und Upgradedomänen hinweg ausführen.
Es können allerdings auch gleichzeitig mehrere willkürliche Ausfälle auftreten. Hierbei ist die Gefahr einer Ausfallzeit oder eines echten Notfalls größer.
Zustandslose Dienste
Die Anzahl der Instanzen für einen zustandslosen Dienst gibt die gewünschte Anzahl von Instanzen an, die ausgeführt werden müssen. Wenn eine der Instanzen fehlerhaft ist (oder alle es sind), reagiert Service Fabric durch das automatische Erstellen von Ersatzinstanzen auf anderen Knoten. Dies wird von Service Fabric so lange fortgesetzt, bis wieder die gewünschte Anzahl von Dienstinstanzen erreicht ist.
Nehmen Sie z. B. an, dass der zustandslose Dienst den InstanceCount-Wert „-1“ aufweist. Dieser Wert bedeutet, dass auf jedem Knoten im Cluster eine Instanz ausgeführt werden sollte. Wenn bei einigen dieser Instanzen ein Fehler auftritt, erkennt Service Fabric, dass der Dienst nicht den gewünschten Zustand aufweist, und versucht, die Instanzen auf den Knoten, auf denen sie fehlen, zu erstellen.
Zustandsbehaftete Dienste
Es gibt zwei Arten von zustandsbehafteten Diensten:
- Zustandsbehaftet mit persistentem Zustand.
- Zustandsbehaftet mit nicht persistentem Zustand. (Status wird im Arbeitsspeicher gespeichert.)
Die Wiederherstellung zustandsbehafteter Dienste nach einem Fehler hängt vom Typ des zustandsbehafteten Diensts ab und davon, wie viele Replikate der Dienst hatte und bei wie vielen ein Fehler aufgetreten ist.
Bei einem zustandsbehafteten Dienst werden eingehende Daten zwischen Replikaten (primären und aktiv sekundären) repliziert. Wenn die meisten der Replikate die Daten empfangen, werden die Daten als im Quorum committet angesehen. (Bei fünf Replikaten gelten drei als Quorum.) Dies bedeutet, dass zu jedem Zeitpunkt mindestens ein Quorum von Replikaten mit den neuesten Daten vorhanden ist. Wenn bei Replikaten Fehler auftreten (z. B. zwei von fünf), können wir anhand des Quorumwerts berechnen, ob eine Wiederherstellung möglich ist. (Da die restlichen drei von fünf Replikaten immer noch aktiv sind, wird sichergestellt, dass mindestens ein Replikat über umfassende Daten verfügt.)
Wenn ein Quorum der Replikate nicht gebildet werden kann, wird die Partition als in einen Zustand des Quorumverlusts befindlich deklariert. Nehmen wir an, eine Partition verfügt über fünf Replikate, d. h. mindestens drei verfügen über vollständige Daten. Wenn ein Quorum (drei aus fünf) der Replikate nicht gebildet werden kann, kann Service Fabric nicht ermitteln, ob die verbleibenden Replikate (zwei aus fünf) über genügend Daten verfügen, um die Partition wiederherzustellen. In Fällen, in denen Service Fabric einen Quorumverlust erkennt, werden gemäß dem Standardverhalten zusätzliche Schreibvorgänge in die Partition verhindert, der Quorumverlust deklariert und gewartet, bis ein Quorum der Replikate wiederhergestellt wird.
Die Bestimmung, ob bei einem zustandsbehafteten Dienst ein Notfall vorliegt, und der Umgang mit der Situation umfassen drei Stufen:
Bestimmen, ob ein Quorumverlust vorliegt.
Ein Quorumverlust liegt vor, wenn die Mehrheit der Replikate eines zustandsbehafteten Diensts zur gleichen Zeit ausgefallen ist.
Bestimmen, ob es sich um einen dauerhaften Quorumverlust handelt.
Die meisten Ausfälle sind vorübergehend. Prozesse, Knoten und virtuelle Computer werden neu gestartet, und Netzwerkpartitionen werden korrigiert. Manche Ausfälle sind jedoch dauerhaft. Ob Ausfälle permanent sind oder nicht, hängt davon ab, ob der zustandsbehaftete Dienst den Status beibehält oder ihn nur im Arbeitsspeicher speichert:
- Bei Diensten ohne persistenten Zustand führt der Ausfall eines Quorums oder weiterer Replikate zu einem sofortigen und dauerhaften Quorumverlust. Wenn Service Fabric einen Quorumverlust für einen nicht persistenten zustandsbehafteten Dienst feststellt, folgt sofort Schritt 3 – es wird also ein (potenzieller) Datenverlust deklariert. Mit dem Datenverlust fortzufahren, ist sinnvoll, denn Service Fabric erkennt, dass das Warten auf die Wiederherstellung der Replikate keinen Sinn hätte. Auch wenn sie wiederhergestellt würden, wären die Daten verloren, da der Dienst nicht persistent ist.
- Bei persistenten zustandsbehafteten Diensten führt der Ausfall eines Quorums oder weiterer Replikate dazu, dass Service Fabric auf die Wiederherstellung der Replikate wartet, um das Quorum wiederherzustellen. Dies führt zu einem Dienstausfall für alle Schreibvorgänge in der betroffenen Partition (Replikatsatz) des Diensts. Lesevorgänge sind dagegen unter Umständen weiterhin möglich, allerdings mit geringerer Konsistenzgarantie. Service Fabric wartet standardmäßig unendlich lange auf die Quorumwiederherstellung, da auf den Quorumverlust ein (potenzieller) Datenverlust mit anderen Risiken folgt. Dies bedeutet, dass Service Fabric erst dann mit dem nächsten Schritt fortfährt, wenn ein Administrator Maßnahmen zum Deklarieren von Datenverlusten ergreift.
Ermitteln, ob Daten verloren gehen, und Wiederherstellen von Sicherungen.
Wenn ein Quorumverlust deklariert wurde (entweder automatisch oder durch administrative Maßnahmen), fahren Service Fabric und die Dienste fort, um zu bestimmen, ob die Daten tatsächlich verloren gegangen sind. An diesem Punkt steht für Service Fabric auch fest, dass die anderen Replikate nicht wiederhergestellt werden können. Diese Entscheidung ist gefallen, als beschlossen wurde, nicht weiter auf die Auflösung des Quorumverlusts zu warten. In den meisten Fällen empfiehlt es sich, dass der Dienst einfach einfriert und auf Eingriffe durch einen Administrator wartet.
Wenn Service Fabric die
OnDataLossAsync-Methode aufruft, dann immer aufgrund eines vermuteten Datenverlusts. Service Fabric stellt sicher, dass dieser Aufruf immer für das beste verbleibende Replikat erfolgt. Dabei handelt es sich um das Replikat mit dem größten Fortschritt.Wir sprechen von vermutetem Datenverlust, da es durchaus sein kann, dass das verbleibende Replikat über die gleichen Zustandsinformationen verfügt wie das primäre Replikat zum Zeitpunkt des Quorumverlusts. Da dieser Zustand jedoch nicht für einen Vergleich zur Verfügung steht, können Service Fabric und die Betreiber dies nicht mit Gewissheit sagen.
Wie läuft also eine typische Implementierung der Methode
OnDataLossAsyncab?Die Implementierung protokolliert, dass
OnDataLossAsyncausgelöst wurde, und die erforderlichen administrativen Warnungen werden ausgelöst.In der Regel wird die Implementierung angehalten und auf weitere Entscheidungen und manuelle Aktionen gewartet. Der Grund: Gegebenenfalls verfügbare Sicherungen müssten unter Umständen erst vorbereitet werden.
Wenn also beispielsweise zwei verschiedene Dienste Informationen koordinieren, müssten diese Sicherungen möglicherweise geändert werden, um sicherzustellen, dass die relevanten Informationen für die beiden Dienste nach der Wiederherstellung konsistent sind.
Zudem sind häufig noch andere Telemetriedaten oder Ausgaben des Diensts vorhanden. Diese Metadaten könnten in anderen Diensten oder in Protokollen enthalten sein. Auf der Grundlage dieser Informationen lässt sich ermitteln, ob vom primären Replikat Aufrufe empfangen und verarbeitet wurden, die in der Sicherung nicht vorhanden waren oder nicht in diesem speziellen Replikat repliziert wurden. Diese Aufrufe müssten ggf. vor der Wiederherstellung wiederholt oder der Sicherung hinzugefügt werden.
Der Zustand des verbleibenden Replikats wird von der Implementierung mit dem Zustand ggf. verfügbarer Sicherungen verglichen. Bei Verwendung zuverlässiger Service Fabric-Auflistungen stehen hierfür entsprechende Tools und Prozesse zur Verfügung. Auf diese Weise wird ermittelt, ob der Zustand innerhalb des Replikats ausreicht bzw. was in der Sicherung möglicherweise fehlt.
Nach Abschluss des Vergleichs und (ggf.) der Wiederherstellung gibt der Dienstcode true zurück, sofern Zustandsänderungen vorgenommen wurden. Falls es sich bei dem Replikat um die beste verfügbare Kopie des Zustands handelt und keine Änderungen vorgenommen wurden, wird false zurückgegeben.
Bei true sind andere verbleibende Replikate nun möglicherweise nicht mehr mit diesem Replikat konsistent. Sie werden gelöscht und auf der Grundlage dieses Replikats neu erstellt. Bei false wurde der Zustand nicht geändert, und die anderen Replikate können unverändert bleiben.
Dienstautoren müssen unbedingt mögliche Datenverlust- und Ausfallszenarien üben, bevor Dienste in der Produktionsumgebung bereitgestellt werden. Zum Schutz vor Datenverlusten empfiehlt sich die regelmäßige Sicherung des Zustands sämtlicher zustandsbehafteter Dienste in einem geografisch redundanten Speicher.
Vergewissern Sie sich zudem, dass Sie den Zustand wiederherstellen können. Da Sicherungen von vielen unterschiedlichen Diensten zu unterschiedlichen Zeiten erstellt werden, müssen Sie sich nach einer Wiederherstellung vergewissern, dass Ihre Dienste untereinander jeweils über eine konsistente Sicht verfügen.
Stellen Sie sich beispielsweise eine Situation vor, in der ein Dienst eine Zahl generiert, speichert und dann an einen anderen Dienst sendet, der sie ebenfalls speichert. Nach einer Wiederherstellung stellen Sie unter Umständen fest, dass der zweite Dienst über die Zahl verfügt, der erste aber nicht, da der entsprechende Vorgang nicht in dessen Sicherung enthalten war.
Wenn Sie in einem Szenario mit Datenverlust feststellen, dass die verbleibenden Replikate nicht ausreichen und sich der Dienstzustand nicht anhand von Telemetriedaten oder Ausgaben rekonstruieren lässt, hängt Ihre bestmögliche Recovery Point Objective (RPO) von der Häufigkeit Ihrer Sicherungen ab. Service Fabric bietet viele Tools zum Testen verschiedener Ausfallszenarien – einschließlich dauerhafter Quorum- und Datenverluste, die die Wiederherstellung einer Sicherung erfordern. Diese Szenarien sind Teil der vom Fault Analysis Service verwalteten Testability-Tools in Service Fabric. Weitere Informationen zu diesen Tools und Mustern finden Sie unter Testability – Übersicht.
Hinweis
Systemdienste können auch von einem Quorumverlust betroffen sein. Die Auswirkung hängt vom jeweiligen Dienst ab. Beispielsweise wirkt sich der Quorumverlust im Naming Service auf die Namensauflösung aus. Im Failover-Manager-Dienst verhindert der Quorumverlust hingegen das Erstellen neuer Dienste sowie Failover.
Die Service Fabric-Systemdienste folgen zwar dem gleichen Muster wie Ihre Dienste für die Zustandsverwaltung, wir raten aber dennoch davon ab, zu versuchen, sie aus dem Quorumverlust in den potenziellen Datenverlust zu überführen. Stattdessen sollten Sie sich an den Support wenden, um eine Lösung zu finden, die Ihrer Situation entspricht. In der Regel ist es besser, zu warten, bis die ausgefallenen Replikate wiederhergestellt wurden.
Beheben von Problemen bei Quorumverlusten
Replikate sind aufgrund eines vorübergehenden Fehlers möglicherweise nicht mehr aktiv. Warten Sie einige Zeit, da Service Fabric versucht, sie wieder zu aktivieren. Wenn Replikate länger als den zu erwartenden Zeitraum nicht verfügbar sind, führen Sie die folgenden Maßnahmen zur Problembehandlung aus:
- Replikate könnten abstürzen. Überprüfen Sie die Integritätsberichte und Anwendungsprotokolle auf Replikatebene. Erfassen Sie Absturzabbilder, und ergreifen Sie erforderliche Maßnahmen zur Wiederherstellung.
- Der Replikatprozess reagiert möglicherweise nicht mehr. Überprüfen Sie die Anwendungsprotokolle, um dies zu überprüfen. Erfassen Sie das Prozessabbild, und beenden Sie dann den nicht reagierenden Prozess. Service Fabric erstellt einen Ersatzprozess und versucht, das Replikat wiederherzustellen.
- Knoten, die die Replikate hosten, sind möglicherweise ausgefallen. Starten Sie den zugrunde liegenden virtuellen Computer neu, um die Knoten wieder zu starten.
Manchmal ist es möglicherweise nicht möglich, Replikate wiederherzustellen. Dies ist beispielsweise der Fall, wenn alle Laufwerke ausgefallen sind oder die Computer aus irgendeinem Grund physisch nicht reagieren. In diesen Fällen muss Service Fabric angewiesen werden, nicht auf die Wiederherstellung der Replikate zu warten.
Verwenden Sie diese Methode nicht, wenn ein möglicher Datenverlust nicht akzeptabel ist, um den Dienst online zu schalten. In diesem Fall sollten Sie alle Maßnahmen zur Wiederherstellung physischer Computer durchgeführt haben.
Die folgenden Aktionen könnten zu Datenverlusten führen. Berücksichtigen Sie dies, bevor Sie sie ausführen.
Hinweis
Aus Sicherheitsgründen dürfen diese Methoden ausschließlich gezielt für bestimmte Partitionen verwendet werden.
- Verwenden Sie die
Repair-ServiceFabricPartition -PartitionId- oderSystem.Fabric.FabricClient.ClusterManagementClient.RecoverPartitionAsync(Guid partitionId)-API. Diese API ermöglicht die Angabe der ID für die Partition, die aus Quorumverlust in den potenziellen Datenverlust überführt werden soll. - Wenn in Ihrem Cluster häufig Fehler auftreten, die zu einem Quorumverlust von Diensten führen und potenzielle Datenverluste akzeptabel sind, kann die automatische Wiederherstellung des Diensts durch Angabe eines entsprechenden Werts für QuorumLossWaitDuration unterstützt werden. Service Fabric wartet die durch
QuorumLossWaitDurationangegebene Zeit (der Standardwert ist unendlich), bevor die Wiederherstellung durchgeführt wird. Diese Methode wird nicht empfohlen, da sie zu unerwarteten Datenverlusten führen kann.
Verfügbarkeit des Service Fabric-Clusters
Der Service Fabric-Cluster ist im Großen und Ganzen eine hochgradig verteilte Umgebung ohne Single Points of Failure. Der Ausfall eines Knotens führt nicht zu Problemen mit der Verfügbarkeit oder Zuverlässigkeit des Clusters. Das liegt in erster Linie daran, dass die Service Fabric-Systemdienste den zuvor angegebenen Richtlinien folgen. Das bedeutet, dass sie standardmäßig immer mit mindestens drei Replikaten betrieben werden, und zustandslose Systemdienste werden auf allen Knoten ausgeführt.
Die zugrunde liegenden Netzwerk- und Ausfallerkennungsebenen von Service Fabric sind vollständig verteilt. Die meisten Systemdienste können auf der Grundlage von Metadaten im Cluster neu erstellt werden oder ihren Zustand über andere Orte synchronisieren. Die Verfügbarkeit des Clusters kann beeinträchtigt werden, wenn bei Systemdiensten Quorumverluste auftreten, wie weiter oben beschrieben. In diesen Fällen könnten möglicherweise bestimmte Vorgänge für den Cluster (beispielsweise das Starten eines Upgrades oder das Bereitstellen neuer Dienste) nicht ausgeführt werden, obwohl der Cluster selbst noch aktiv ist.
Auf einem Cluster ausgeführte Dienste werden in diesem Fall weiter ausgeführt, sofern sie nicht in die Systemdienste schreiben müssen. Wenn der Failover-Manager z. B. einen Quorumverlust hat, werden alle Dienste weiterhin ausgeführt. Aber alle Dienste, die ausfallen, können nicht automatisch neu gestartet werden, da dies die Einbindung des Failover-Manager erfordert.
Ausfall eines Rechenzentrums oder einer Azure-Region
In seltenen Fällen kann es vorkommen, dass ein physisches Rechenzentrum aufgrund eines Stromausfalls oder einer Unterbrechung der Netzwerkverbindung vorübergehend nicht verfügbar ist. In einem solchen Fall sind Ihre Service Fabric-Cluster und -Dienste im betroffenen Datencenter oder in der betroffenen Azure-Region nicht verfügbar. Ihre Daten bleiben jedoch erhalten.
Für in Azure ausgeführte Cluster können Sie aktuelle Informationen zu Ausfällen auf der Azure-Statusseite nachlesen. Im äußerst unwahrscheinlichen Fall der vollständigen oder teilweisen Zerstörung eines physischen Rechenzentrums könnten sämtliche dort gehosteten Service Fabric-Cluster sowie die darin enthaltenen Dienste verloren gehen. Dieser Verlust schließt sämtliche Zustandsinformationen ein, die nicht außerhalb des Rechenzentrums oder der Region gesichert wurden.
Dem dauerhaften Ausfall eines einzelnen Rechenzentrums oder einer einzelnen Region kann mit vielen unterschiedlichen Strategien begegnet werden:
Betreiben Sie separate Service Fabric-Cluster in mehreren Regionen, und nutzen Sie einen Failover- und Failbackmechanismus zwischen diesen Umgebungen. Dieses Modell mit mehreren Clustern (aktiv/aktiv oder aktiv/passiv) ist mit zusätzlichem Verwaltungsaufwand verbunden und erfordert zusätzlichen Vorgangscode. Darüber hinaus müssen bei diesem Modell Sicherungen der Dienste in einem Rechenzentrum oder in einer Region koordiniert werden, damit sie bei einem Ausfall in anderen Rechenzentren oder Regionen verfügbar sind.
Betreiben Sie einen einzelnen Service Fabric-Cluster, der sich über mehrere Rechenzentren erstreckt. Für diese Strategie müssen mindestens drei Rechenzentren konfiguriert werden. Weitere Informationen finden Sie unter Bereitstellen eines Service Fabric-Clusters über Verfügbarkeitszonen hinweg.
Für dieses Modell sind zusätzliche Einrichtungsschritte erforderlich. Es hat jedoch den Vorteil, dass der Ausfall eines Rechenzentrums keinen Notfall mehr darstellt, sondern nur noch einen normalen Ausfall. Diese Ausfälle können von den Mechanismen bewältigt werden, die für Cluster innerhalb einer einzelnen Region zum Einsatz kommen. Dank Fehlerdomänen, Upgradedomänen und Platzierungsregeln von Service Fabric werden Arbeitslasten so verteilt, dass sie normale Ausfälle tolerieren.
Weitere Informationen zu hilfreichen Richtlinien für den Betrieb von Diensten in dieser Art von Cluster finden Sie unter Platzierungsrichtlinien für Service Fabric-Dienste.
Betreiben Sie einen einzelnen eigenständigen Service Fabric-Cluster, der sich über mehrere Regionen erstreckt. Die empfohlene Anzahl von Regionen ist drei. Weitere Informationen zum eigenständigen Service Fabric-Setup finden Sie unter Erstellen eines eigenständigen Clusters.
Clusterausfälle aufgrund von zufälligen Ausfällen
Bei Service Fabric kommt das Seedknoten-Konzept zur Anwendung. Hierbei handelt es sich um Knoten zur Aufrechterhaltung der Verfügbarkeit des zugrunde liegenden Clusters.
Seedknoten gewährleisten die Verfügbarkeit des Clusters durch die Einrichtung von Leases mit anderen Knoten. Darüber hinaus fungieren sie als entscheidendes Element bei bestimmten Arten von Ausfällen. Falls nach zufälligen Ausfällen ein Großteil der Seedknoten im Cluster nicht mehr verfügbar ist und nicht schnell wiederhergestellt wird, wird der Cluster automatisch heruntergefahren. Der Cluster fällt dann aus.
In Azure verwaltet der Service Fabric-Ressourcenanbieter Service Fabric-Clusterkonfigurationen. Standardmäßig verteilt der Ressourcenanbieter Seedknoten auf Fehler- und Upgradedomänen für den primären Knotentyp. Wenn der primäre Knotentyp mit der Dauerhaftigkeit Silber oder Gold gekennzeichnet ist, versucht der Cluster beim Entfernen eines Seedknotens (entweder durch Skalieren in Ihrem primären Knotentyp oder durch manuelles Entfernen) einen anderen Nicht-Seedknoten aus der verfügbaren Kapazität des primären Knotentyps heraufzustufen. Dieser Versuch gelingt nicht, wenn für Ihren primären Knotentyp weniger Kapazität verfügbar ist, als die Zuverlässigkeitsstufe Ihres Clusters erfordert.
Sowohl in eigenständigen Service Fabric-Clustern als auch in Azure werden die Seeds vom primären Knotentyp ausgeführt. Beim Definieren eines primären Knotentyps verwendet Service Fabric automatisch die Anzahl bereitgestellter Knoten und erstellt bis zu neun Seedknoten und sieben Replikate der einzelnen Systemdienste. Wenn die Mehrzahl dieser Systemdienstreplikate überraschend gleichzeitig ausfällt, tritt für die Systemdienste ein Quorumverlust ein. Geht die Mehrzahl der Seedknoten verloren, wird der Cluster kurz darauf heruntergefahren.
Nächste Schritte
- Erfahren Sie, wie Sie verschiedene Ausfälle mit dem Testability-Framework simulieren können.
- Lesen Sie weitere Artikel zu Wiederherstellung und hoher Verfügbarkeit. Microsoft hat sehr umfassende Anleitungen zu diesen Themen veröffentlicht. Während sich einige dieser Ressourcen auf bestimmte Techniken für die Verwendung in anderen Produkten beziehen, enthalten viele allgemeine bewährte Methoden, die Sie im Service Fabric-Kontext anwenden können:
- Informieren Sie sich über Service Fabric-Supportoptionen.