Tutorial: Implementieren des Data Lake-Erfassungsmusters zum Aktualisieren einer Databricks Delta-Tabelle
In diesem Tutorial wird veranschaulicht, wie Sie Ereignisse in einem Speicherkonto mit einem hierarchischen Namespace verarbeiten.
Sie erstellen eine kleine Lösung, mit der ein Benutzer eine Databricks Delta-Tabelle füllen kann, indem er eine CSV-Datei (Comma-Separated Values) mit Daten zur Beschreibung eines Verkaufsauftrags hochlädt. Sie erstellen diese Lösung, indem Sie in Azure Databricks ein Event Grid-Abonnement, eine Azure-Funktion und einen Auftrag verbinden.
In diesem Lernprogramm lernen Sie Folgendes:
- Erstellen Sie ein Event Grid-Abonnement, das eine Azure-Funktion aufruft.
- Erstellen Sie eine Azure-Funktion, die eine Benachrichtigung von einem Ereignis empfängt und den Auftrag dann in Azure Databricks ausführt.
- Erstellen Sie einen Databricks-Auftrag, mit dem eine Kundenbestellung in eine Databricks Delta-Tabelle eingefügt wird, die unter dem Speicherkonto vorhanden ist.
Wir erstellen diese Lösung in umgekehrter Reihenfolge, indem wir mit dem Azure Databricks-Arbeitsbereich beginnen.
Voraussetzungen
Erstellen Sie ein Speicherkonto mit einem hierarchischen Namespace (Azure Data Lake Storage Gen2). In diesem Tutorial wird ein Speicherkonto mit dem Namen
contosoordersverwendet.Lesen Sie die Informationen unter Erstellen eines Speicherkontos für die Verwendung mit Azure Data Lake Storage Gen2.
Vergewissern Sie sich, dass Ihrem Benutzerkonto die Rolle Mitwirkender an Storage-Blobdaten zugewiesen ist.
Erstellen Sie einen Dienstprinzipal, erstellen Sie einen geheimen Clientschlüssel, und gewähren Sie dem Dienstprinzipal dann Zugriff auf das Speicherkonto.
Informationen dazu erhalten Sie unter Tutorial: Herstellen einer Verbindung mit Azure Data Lake Storage Gen2 (Schritte 1 bis 3). Kopieren Sie nach dem Ausführen dieser Schritte unbedingt die Werte für Mandanten-ID, App-ID und geheimen Clientschlüssel in eine Textdatei. Sie benötigen sie in Kürze.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Erstellen eines Verkaufsauftrags
Erstellen Sie zuerst eine CSV-Datei, mit der ein Verkaufsauftrag beschrieben wird, und laden Sie diese Datei dann in das Speicherkonto hoch. Später verwenden Sie die Daten aus dieser Datei dann, um die erste Zeile der Databricks Delta-Tabelle zu füllen.
Navigieren Sie im Azure-Portal zu Ihrem neuen Speicherkonto.
Wählen Sie Speicherbrowser>Blobcontainer-Container>Container hinzufügen aus, und erstellen Sie einen neuen Container namens data.
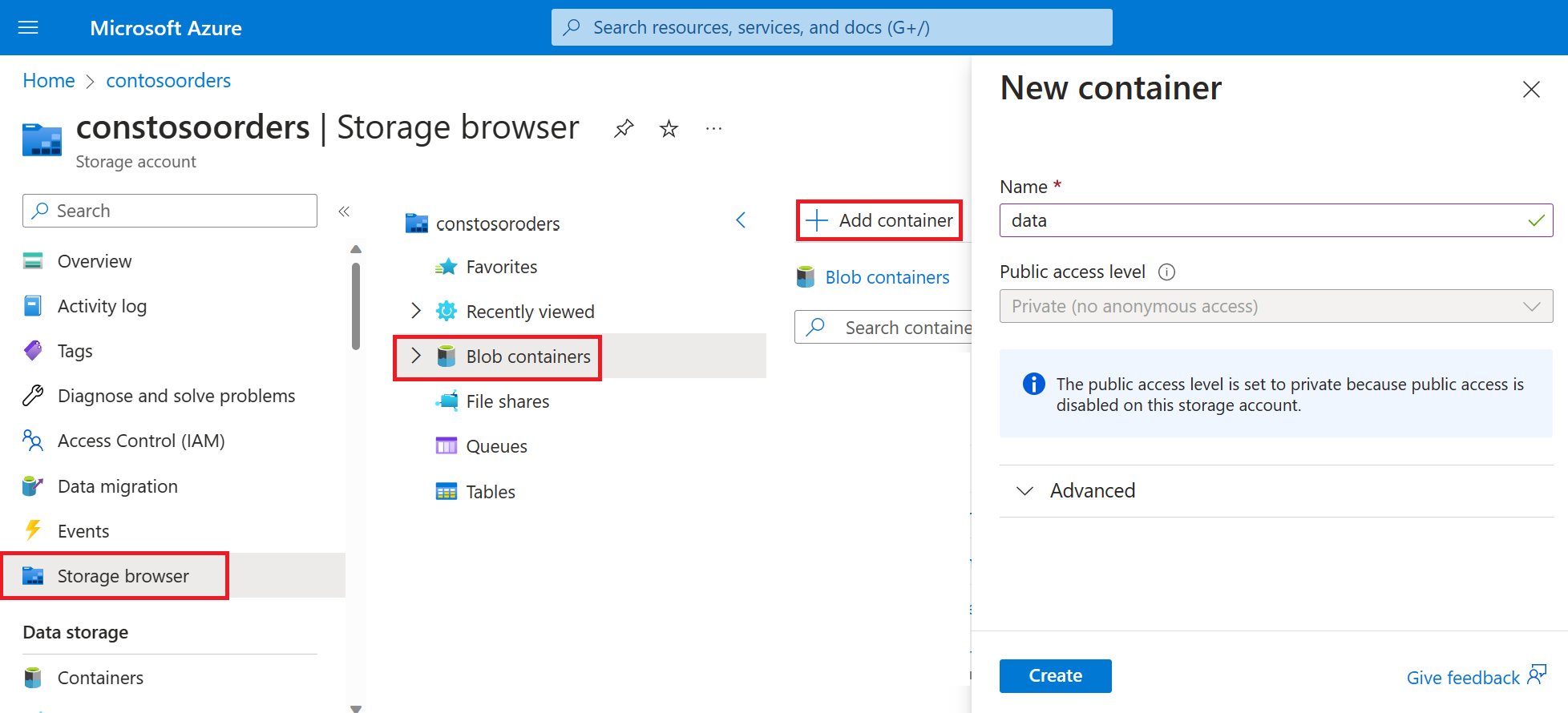
Erstellen Sie im Container data ein Verzeichnis mit dem Namen input.
Fügen Sie in einem Text-Editor den folgenden Text ein:
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomSpeichern Sie diese Datei auf Ihrem lokalen Computer, und geben Sie ihr den Namen data.csv.
Laden Sie diese Datei im Speicherbrowser in den Ordner input hoch.
Erstellen eines Auftrags in Azure Databricks
In diesem Abschnitt führen Sie die folgenden Aufgaben aus:
- Erstellen eines Azure Databricks-Arbeitsbereichs
- Erstellen Sie ein Notebook.
- Erstellen und Auffüllen einer Databricks Delta-Tabelle
- Hinzufügen von Code, mit dem Zeilen in die Databricks Delta-Tabelle eingefügt werden
- Erstellen eines Auftrags
Erstellen eines Azure Databricks-Arbeitsbereichs
In diesem Abschnitt erstellen Sie einen Azure Databricks-Arbeitsbereich über das Azure-Portal.
Erstellen eines Azure Databricks-Arbeitsbereichs Nennen Sie diesen Arbeitsbereich
contoso-orders. Weitere Informationen finden Sie unter Erstellen eines Azure Databricks-Arbeitsbereichs.Erstellen eines Clusters Nennen Sie den Cluster
customer-order-cluster. Weitere Informationen finden Sie unter Erstellen eines Clusters.Erstellen Sie ein Notebook. Nennen Sie das Notebook
configure-customer-table, und wählen Sie Python als Standardsprache für das Notebook aus. Weitere Informationen finden Sie unter Erstellen eines Notebooks.
Erstellen und Auffüllen einer Databricks Delta-Tabelle
Kopieren Sie im erstellten Notebook den folgenden Codeblock, und fügen Sie ihn in die erste Zelle ein, aber führen Sie den Code noch nicht aus.
Ersetzen Sie die Platzhalterwerte
appId,passwordundtenantdurch die Werte, die Sie bei der Vorbereitung dieses Tutorials gesammelt haben.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Mit diesem Code wird ein Widget mit dem Namen source_file erstellt. Später erstellen Sie eine Azure-Funktion, mit der dieser Code aufgerufen und ein Dateipfad an das Widget übergeben wird. Mit diesem Code wird auch Ihr Dienstprinzipal beim Speicherkonto authentifiziert, und es werden einige Variablen erstellt, die Sie in anderen Zellen verwenden.
Hinweis
In einer Produktionsumgebung empfiehlt es sich, Ihren Authentifizierungsschlüssel in Azure Databricks zu speichern. Fügen Sie dem Codeblock dann einen Suchschlüssel anstelle des Authentifizierungsschlüssels hinzu.
Anstelle der Codezeilespark.conf.set("fs.azure.account.oauth2.client.secret", "<password>")verwenden Sie die folgende Codezeile:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Sehen Sie sich nach Abschluss dieses Tutorials die Beispiele für diesen Ansatz im Artikel Azure Data Lake Storage Gen2 auf der Azure Databricks-Website an.Drücken Sie UMSCHALT+EINGABE, um den Code in diesem Block auszuführen.
Kopieren Sie den folgenden Codeblock, und fügen Sie ihn in eine andere Zelle ein. Drücken Sie anschließend UMSCHALT+EINGABE, um den Code in diesem Block auszuführen.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Mit diesem Code wird die Databricks Delta-Tabelle in Ihrem Speicherkonto erstellt, und anschließend werden einige Anfangsdaten aus der CSV-Datei geladen, die Sie zuvor hochgeladen haben.
Nachdem dieser Codeblock erfolgreich ausgeführt wurde, sollten Sie ihn aus dem Notebook entfernen.
Hinzufügen von Code, mit dem Zeilen in die Databricks Delta-Tabelle eingefügt werden
Kopieren Sie den folgenden Codeblock, und fügen Sie ihn in eine andere Zelle ein, aber führen Sie diese Zelle nicht aus.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Mit diesem Code werden Daten in eine temporäre Tabellenansicht eingefügt, indem Daten aus einer CSV-Datei verwendet werden. Der Pfad zu dieser CSV-Datei stammt aus dem Eingabewidget, das Sie in einem früheren Schritt erstellt haben.
Kopieren Sie den folgenden Codeblock, und fügen Sie ihn in eine andere Zelle ein. Dieser Code führt den Inhalt der temporären Tabellenansicht mit der Databricks Delta-Tabelle zusammen.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Erstellen eines Auftrags
Erstellen Sie einen Auftrag, mit dem das zuvor erstellte Notebook ausgeführt wird. Später erstellen Sie eine Azure-Funktion, mit der dieser Auftrag bei Auslösung eines Ereignisses ausgeführt wird.
Wählen Sie Neu>Auftrag aus.
Geben Sie dem Auftrag einen Namen, und wählen Sie das von Ihnen erstellte Notebook und den Cluster aus. Wählen Sie anschließend Erstellen aus, um den Auftrag zu erstellen.
Erstellen einer Azure Function
Erstellen Sie eine Azure-Funktion, die den Auftrag ausführt.
Klicken Sie in Ihrem Azure Databricks-Arbeitsbereich auf der oberen Leiste auf Ihren Azure Databricks-Benutzernamen, und wählen Sie dann in der Dropdownliste die Option Benutzereinstellungen aus.
Wählen Sie auf der Registerkarte Zugriffstoken die Option Neues Token generieren aus.
Kopieren Sie das angezeigte Token, und klicken Sie anschließend auf Fertig.
Wählen Sie in der oberen Ecke des Databricks-Arbeitsbereichs das Symbol „Personen“, und wählen Sie dann Benutzereinstellungen.

Wählen Sie die Schaltfläche Neues Token generieren und dann die Schaltfläche Generieren aus.
Kopieren Sie das Token an einen sicheren Speicherort. Ihre Azure-Funktion benötigt dieses Token für die Authentifizierung mit Databricks, damit der Auftrag ausgeführt werden kann.
Wählen Sie im Menü des Azure-Portals oder auf der Startseite die Option Ressource erstellen aus.
Wählen Sie auf der Seite Neu die Option Compute>Funktions-App aus.
Wählen Sie auf der Registerkarte Grundlagen der Seite Funktions-App erstellen eine Ressourcengruppe aus, und ändern bzw. überprüfen Sie die folgenden Einstellungen:
Einstellung Wert Name der Funktions-App contosoorder Laufzeitstapel .NET Veröffentlichen Code Betriebssystem Windows Plantyp Verbrauchstarif (Serverloses Computing) Klicken Sie auf Überprüfen und erstellen und dann auf Erstellen.
Wählen Sie nach Abschluss der Bereitstellung die Option Zu Ressource wechseln aus, um die Übersichtsseite der Funktions-App zu öffnen.
Wählen Sie in der Gruppe Einstellungen die Option Konfiguration aus.
Wählen Sie auf der Seite Anwendungseinstellungen die Schaltfläche Neue Anwendungseinstellung, um die einzelnen Einstellungen hinzuzufügen.

Fügen Sie die folgenden Einstellungen hinzu:
Einstellungsname Wert DBX_INSTANCE Die Region Ihres Databricks-Arbeitsbereichs. Beispiel: westus2.azuredatabricks.netDBX_PAT Das persönliche Zugriffstoken, das Sie zuvor generiert haben. DBX_JOB_ID Der Bezeichner des ausgeführten Auftrags. Wählen Sie Speichern aus, um diese Einstellungen zu committen.
Wählen Sie in der Gruppe Funktionen die Option Funktionen und anschließend Erstellen aus.
Wählen Sie Azure Event Grid-Trigger.
Installieren Sie die Erweiterung Microsoft.Azure.WebJobs.Extensions.EventGrid, wenn Sie dazu aufgefordert werden. Bei der Installation müssen Sie erneut Azure Event Grid-Trigger wählen, um die Funktion zu erstellen.
Der Bereich Neue Funktion wird angezeigt.
Geben Sie im Bereich Neue Funktion der Funktion den Namen UpsertOrder, und wählen Sie dann die Schaltfläche Erstellen aus.
Ersetzen Sie den Inhalt der Codedatei durch diesen Code, und wählen Sie dann die Schaltfläche Speichern aus:
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Mit diesem Code werden Informationen zum ausgelösten Speicherereignis analysiert, und anschließend wird eine Anforderungsnachricht mit der URL der Datei, die das Ereignis ausgelöst hat, erstellt. Im Rahmen der Nachricht übergibt die Funktion einen Wert an das Widget source_file, das Sie zuvor erstellt haben. Der Funktionscode sendet die Nachricht an den Databricks-Auftrag und verwendet das Token, das Sie abgerufen haben, als Authentifizierung.
Erstellen eines Event Grid-Abonnements
In diesem Abschnitt erstellen Sie ein Event Grid-Abonnement, mit dem die Azure-Funktion aufgerufen wird, wenn Dateien in das Speicherkonto hochgeladen werden.
Wählen Sie Integration und dann auf der Seite Integration die Option Event Grid-Trigger aus.
Legen Sie im Bereich Trigger bearbeiten den Namen des Ereignisses auf
eventGridEventfest, und wählen Sie anschließend Ereignisabonnement erstellen aus.Hinweis
Der Name
eventGridEvententspricht dem angegebenen Parameter, der an die Azure-Funktion übergeben wird.Ändern bzw. überprüfen Sie auf der Registerkarte Grundlagen der Seite Ereignisabonnement erstellen die folgenden Einstellungen:
Einstellung Wert Name contoso-order-event-subscription Thementyp Speicherkonto Quellressource contosoorders Name des Systemthemas <create any name>Nach Ereignistypen filtern „Blob erstellt“ und „Blob gelöscht“ Wählen Sie die Schaltfläche Erstellen.
Testen des Event Grid-Abonnements
Erstellen Sie eine Datei mit dem Namen
customer-order.csv, fügen Sie die folgenden Informationen in diese Datei ein, und speichern Sie sie auf Ihrem lokalen Computer.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneLaden Sie diese Datei im Storage-Explorer in den Ordner input Ihres Speicherkontos hoch.
Durch das Hochladen einer Datei wird das Ereignis Microsoft.Storage.BlobCreated ausgelöst. Event Grid benachrichtigt alle Abonnenten über dieses Ereignis. In unserem Fall ist die Azure-Funktion der einzige Abonnent. Die Azure-Funktion analysiert die Ereignisparameter, um zu ermitteln, welches Ereignis eingetreten ist. Anschließend übergibt sie die URL der Datei an den Databricks-Auftrag. Der Databricks-Auftrag liest die Datei und fügt der Databricks Delta-Tabelle in Ihrem Speicherkonto eine Zeile hinzu.
Sehen Sie sich die Ausführungen für Ihren Auftrag an, um zu überprüfen, ob der Auftrag erfolgreich war. Es wird ein Abschlussstatus angezeigt. Weitere Informationen zum Anzeigen von Ausführungen für einen Auftrag finden Sie unter Anzeigen der Ausführungen eines Auftrags.
Führen Sie in einer neuen Arbeitsmappenzelle diese Abfrage in einer Zelle aus, um die aktualisierte Deltatabelle anzuzeigen.
%sql select * from customer_dataIn der zurückgegebenen Tabelle wird der aktuelle Datensatz angezeigt.

Erstellen Sie zum Aktualisieren dieses Datensatzes eine Datei mit dem Namen
customer-order-update.csv, fügen Sie die folgenden Informationen in diese Datei ein, und speichern Sie sie auf Ihrem lokalen Computer.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneDiese CSV-Datei ist fast vollständig mit der vorherigen identisch. Lediglich die Bestellmenge wird von
228in22geändert.Laden Sie diese Datei im Storage-Explorer in den Ordner input Ihres Speicherkontos hoch.
Führen Sie die Abfrage
selecterneut aus, um die aktualisierte Delta-Tabelle anzuzeigen.%sql select * from customer_dataIn der zurückgegebenen Tabelle wird der aktualisierte Datensatz angezeigt.

Bereinigen von Ressourcen
Löschen Sie die Ressourcengruppe und alle dazugehörigen Ressourcen, wenn Sie sie nicht mehr benötigen. Wählen Sie hierzu die Ressourcengruppe für das Speicherkonto und anschließend Löschen aus.
Nächste Schritte
Reacting to Blob storage events (preview) (Reagieren auf Blob Storage-Ereignisse (Vorschauversion))