Erstellen und Ausführen von Azure Databricks-Aufträgen
In diesem Artikel wird beschrieben, wie Sie Azure Databricks-Aufträge mithilfe der Benutzeroberfläche für Aufträge erstellen und ausführen.
Informationen zu Konfigurationsoptionen für Aufträge und zum Bearbeiten Ihrer vorhandenen Aufträge finden Sie unter Konfigurieren von Einstellungen für Azure Databricks-Aufträge.
Informationen zum Verwalten und Überwachen von Auftragsausführungen finden Sie unter Anzeigen und Verwalten von Auftragsausführungen.
Informationen zum Erstellen Ihres ersten Workflows mit einem Azure Databricks-Auftrag finden Sie im Schnellstart.
Wichtig
- Ein Arbeitsbereich ist auf 1000 gleichzeitige Auftragsausführungen beschränkt. Wenn Sie eine Ausführung anfordern, die nicht sofort gestartet werden kann, wird eine
429 Too Many Requests-Antwort zurückgegeben. - Die Anzahl von Aufträgen, die von einem Arbeitsbereich innerhalb einer Stunde erstellt werden können, ist auf 10000 beschränkt (einschließlich „runs submit“). Diese Beschränkung wirkt sich auch auf Aufträge aus, die mit den REST-API- und Notebook-Workflows erstellt wurden.
Erstellen und Ausführen von Aufträgen mit der CLI, der API oder Notebooks
- Informationen zur Verwendung der Databricks CLI zum Erstellen und Ausführen von Aufträgen finden Sie unter Was ist die Databricks-CLI?.
- Informationen zur Verwendung der Auftrags-API zum Erstellen und Ausführen von Aufträgen finden Sie im Abschnitt zu Aufträgen in der REST-API-Referenz.
- Informationen zum Ausführen und Planen von Aufträgen direkt in einem Databricks-Notebook finden Sie unter Erstellen und Verwalten geplanter Notebookaufträge.
Erstellen eines Auftrags
Führen Sie eines der folgenden Verfahren aus:
- Klicken Sie in der Seitenleiste auf
 Workflows und dann auf die Schaltfläche
Workflows und dann auf die Schaltfläche  .
. - Klicken Sie auf der Seitenleiste auf
 Neu, und wählen Sie Auftrag aus.
Neu, und wählen Sie Auftrag aus.
Die Registerkarte Aufgaben wird mit dem Dialogfeld „Aufgabe erstellen“ zusammen mit dem Seitenbereich Auftragsdetails angezeigt, der Einstellungen auf Auftragsebene enthält.
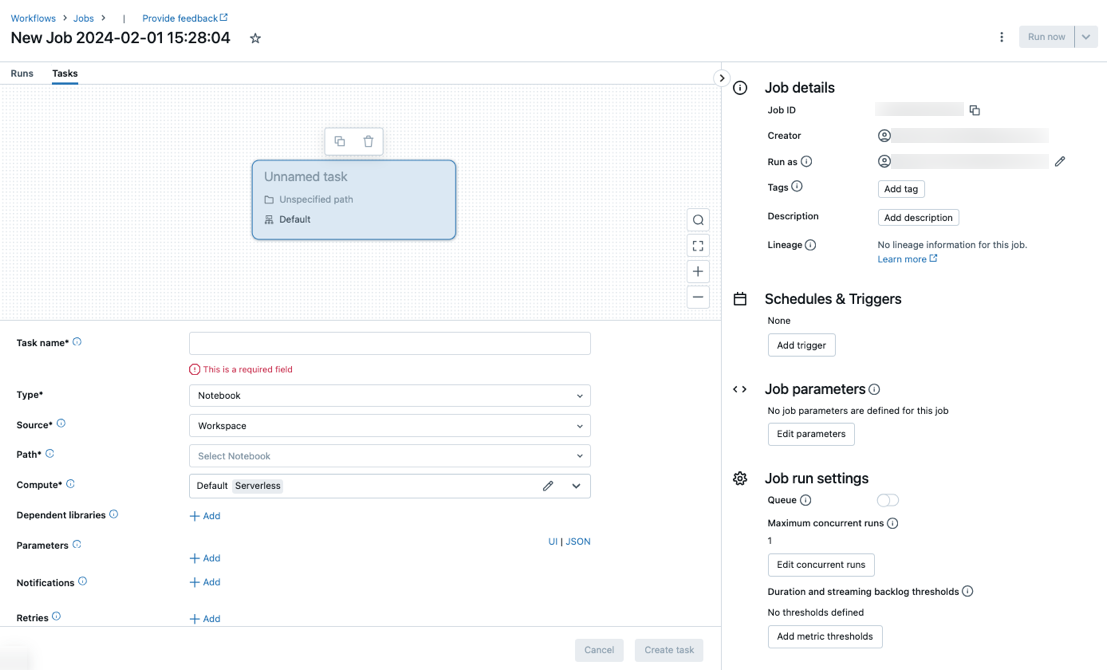
- Klicken Sie in der Seitenleiste auf
Ersetzen Sie Neuer Auftrag… durch Ihren Auftragsnamen.
Geben Sie im Feld Aufgabenname einen Namen für die Aufgabe ein.
Wählen Sie im Dropdownmenü Typ den Typ der auszuführenden Aufgabe aus. Weitere Informationen finden Sie unter Optionen für Aufgabentypen.
Konfigurieren Sie den Cluster, in dem die Aufgabe ausgeführt wird. Standardmäßig wird serverloses Computing ausgewählt, wenn sich Ihr Arbeitsbereich in einem Arbeitsbereich mit Unity Catalog befindet und Sie eine Aufgabe ausgewählt haben, die vom serverlosen Computing für Workflows unterstützt wird. Weitere Informationen finden Sie unter Ausführen Ihres Azure Databricks-Auftrags mit serverlosem Computing für Workflows. Wenn serverloses Computing nicht verfügbar ist oder Sie einen anderen Computetyp verwenden möchten, können Sie im Dropdownmenü Computing einen neuen Auftragscluster oder einen vorhandenen universellen Cluster auswählen.
- Neuer Auftragscluster: Klicken Sie im Dropdownmenü Cluster auf Bearbeitenund schließen Sie die Clusterkonfiguration ab.
- Vorhandener Allzweck-Cluster: Wählen Sie im Dropdownmenü Cluster einen vorhandenen Cluster aus. Um den Cluster auf einer neuen Seite zu öffnen, klicken Sie auf das
 Symbol rechts neben dem Clusternamen und der Beschreibung.
Symbol rechts neben dem Clusternamen und der Beschreibung.
Weitere Informationen zum Auswählen und Konfigurieren von Clustern zum Ausführen von Aufgaben finden Sie unter Verwenden von Azure Databricks-Compute mit Ihren Aufträgen.
Um abhängige Bibliotheken hinzuzufügen, klicken Sie neben Abhängige Bibliotheken auf + Hinzufügen. Weitere Informationen finden Sie unter Konfigurieren abhängiger Bibliotheken.
Sie können Parameter für Ihre Aufgabe übergeben. Informationen zu den Anforderungen für das Formatieren und Übergeben von Parametern finden Sie unter Übergeben von Parametern an eine Azure Databricks-Auftragsaufgabe.
Klicken Sie neben E-Mails auf + Hinzufügen, um optional Benachrichtigungen für Start, Erfolg oder Fehler der Aufgabe zu erhalten. Fehlerbenachrichtigungen werden beim Fehlschlagen der ursprünglichen Aufgabe und allen nachfolgenden Wiederholungen gesendet. Um Benachrichtigungen zu filtern und die Anzahl der gesendeten E-Mails zu reduzieren, aktivieren Sie Benachrichtigungen für übersprungene Ausführungen stummschalten, Benachrichtigungen für abgebrochene Ausführungen stummschalten oder Benachrichtigungen bis zur letzten Wiederholung stummschalten.
Um optional eine Wiederholungsrichtlinie für die Aufgabe zu konfigurieren, klicken Sie neben Wiederholungsversuche auf + Hinzufügen. Weitere Informationen finden Sie unter Konfigurieren einer Wiederholungsrichtlinie für eine Aufgabe.
Um optional die erwartete Dauer oder Zeitüberschreitung der Task zu konfigurieren, klicken Sie auf + Hinzufügen neben Schwellenwert für Dauer. Weitere Informationen finden Sie unter Konfigurieren einer erwarteten Abschlusszeit oder eines Timeouts für eine Aufgabe.
Klicken Sie auf Erstellen.
Nach dem Erstellen der ersten Aufgabe können Sie Einstellungen auf Auftragsebene konfigurieren, z. B. Benachrichtigungen, Auftragstrigger und Berechtigungen. Siehe Bearbeiten eines Auftrags.
Wenn Sie eine weitere Aufgabe hinzufügen möchten, klicken Sie in der DAG-Ansicht auf  . Es wird eine Option für einen freigegebenen Cluster bereitgestellt, wenn Sie serverloses Computing ausgewählt oder einen neuen Auftragscluster für eine vorherige Aufgabe konfiguriert haben. Sie können auch einen Cluster für jede Aufgabe konfigurieren, wenn Sie eine Aufgabe erstellen oder bearbeiten. Weitere Informationen zum Auswählen und Konfigurieren von Clustern zum Ausführen von Aufgaben finden Sie unter Verwenden von Azure Databricks-Compute mit Ihren Aufträgen.
. Es wird eine Option für einen freigegebenen Cluster bereitgestellt, wenn Sie serverloses Computing ausgewählt oder einen neuen Auftragscluster für eine vorherige Aufgabe konfiguriert haben. Sie können auch einen Cluster für jede Aufgabe konfigurieren, wenn Sie eine Aufgabe erstellen oder bearbeiten. Weitere Informationen zum Auswählen und Konfigurieren von Clustern zum Ausführen von Aufgaben finden Sie unter Verwenden von Azure Databricks-Compute mit Ihren Aufträgen.
Sie können optional Einstellungen auf Auftragsebene konfigurieren, z. B. Benachrichtigungen, Auftragstrigger und Berechtigungen. Siehe Bearbeiten eines Auftrags. Sie können auch Parameter auf Auftragsebene konfigurieren, die für die Aufgaben des Auftrags freigegeben werden. Weitere Informationen finden Sie unter Hinzufügen von Parametern für alle Auftragsaufgaben.
Optionen für Aufgabentypen
Im Folgenden sind die Aufgabentypen aufgeführt, die Sie Ihrem Azure Databricks-Auftrag hinzufügen können, sowie die verfügbaren Optionen für die verschiedenen Aufgabentypen:
Notebook: Wählen Sie im Dropdownmenü QuelleWorkspace aus, um ein Notebook zu verwenden, das sich in einem Azure Databricks-Arbeitsbereichsordner befindet, oder Git-Anbieter für ein Notebook das sich in einem Remote-Git-Repository befindet.
Arbeitsbereich: Verwenden Sie den Dateibrowser, um das Notebook zu suchen, klicken Sie auf den Namen des Notebooks und dann auf Bestätigen.
Git-Anbieter: Wählen Sie Bearbeiten oder Git-Verweis hinzufügen aus und geben Sie die Git-Repositoryinformationen ein. Weitere Informationen finden Sie unter Verwenden eines Notebooks aus einem Git-Remoterepository.
Hinweis
Die Ausgabe der Notebookzellen insgesamt (die kombinierte Ausgabe aller Notebookzellen) unterliegt einer Größenbeschränkung von 20 MB. Außerdem ist die Ausgabe einzelner Zellen auf 8 MB beschränkt. Wenn die Zellausgabe insgesamt 20 MB übersteigt, oder wenn die Ausgabe einer einzelnen Zelle größer als 8 MB ist, wird die Ausführung abgebrochen und als fehlgeschlagen markiert.
Wenn Sie Hilfe benötigen, um die Zellen zu finden, die das Limit (bald) überschreiten, führen Sie das Notebook für einen All-Purpose-Cluster aus, und verwenden Sie diese Technik zur automatischen Notebookspeicherung.
JAR: Geben Sie die Hauptklasse an. Verwenden Sie den vollqualifizierten Namen der Klasse, die die Hauptklasse enthält, z. B.
org.apache.spark.examples.SparkPi. Klicken Sie dann unter Abhängige Bibliotheken auf Hinzufügen, um die für die Ausführung der Aufgabe erforderlichen Bibliotheken hinzuzufügen. Eine dieser Bibliotheken muss die Hauptklasse enthalten.Weitere Informationen zu JAR-Aufgaben finden Sie unter Verwenden von JAR in einem Azure Databricks-Auftrag.
Spark Submit: Geben Sie im Textfeld Parameter die Hauptklasse, den Pfad zur JAR-Bibliothek und alle Argumente an, formatiert als JSON-Array aus Zeichenfolgen. Im folgenden Beispiel wird eine spark-submit-Aufgabe konfiguriert, um
DFSReadWriteTestaus den Apache Spark-Beispielen auszuführen:["--class","org.apache.spark.examples.DFSReadWriteTest","dbfs:/FileStore/libraries/spark_examples_2_12_3_1_1.jar","/discover/databricks-datasets/README.md","/FileStore/examples/output/"]Wichtig
Es gelten verschiedene Einschränkungen für spark-submit-Aufgaben:
- Sie können spark submit-Aufgaben nur für neue Cluster ausführen.
- „spark-submit“ unterstützt keine automatische Clusterskalierung. Weitere Informationen zur automatischen Skalierung finden Sie unter Automatische Clusterskalierung.
- „spark-submit” unterstützt keine Databricks-Hilfsprogramme (dbutils). Verwenden Sie stattdessen JAR-Aufgaben, um Databricks-Hilfsprogramme zu verwenden.
- Falls Sie einen Cluster mit Unity Catalog-Unterstützung verwenden, wird „spark-submit“ nur unterstützt, wenn der Cluster den zugewiesenen Zugriffsmodus verwendet. Der Modus für gemeinsamen Zugriff wird nicht unterstützt.
- Für Spark-Streamingaufträge sollte die maximale Anzahl gleichzeitiger Ausführungen nie auf einen Wert von mehr als 1 festgelegt werden. Streamingaufträge sollten so festgelegt werden, dass sie mithilfe des Cron-Ausdrucks
"* * * * * ?"(jede Minute) ausgeführt werden. Da eine Streamingaufgabe kontinuierlich ausgeführt wird, sollte sie immer die letzte Task in einem Auftrag sein.
Python-Skript: Wählen Sie im Dropdownmenü Quelle einen Speicherort für das Python-Skript aus: Arbeitsbereich für ein Skript im lokalen Arbeitsbereich, DBFS für ein Skript in DBFS oder Git-Anbieter für ein Skript, das sich in einem Git-Repository befindet. Geben Sie im Textfeld Pfad den Pfad zum Python-Skript ein:
Workspace: Navigieren Sie im Dialogfeld Python-Datei auswählen zum Python-Skript und klicken Sie auf Bestätigen.
DBFS: Geben Sie den URI eines Python-Skripts auf DBFS oder Cloud-Speicher ein; zum Beispiel,
dbfs:/FileStore/myscript.py.Git-Anbieter: Klicken Sie auf Bearbeiten, und geben Sie die Git-Repositoryinformationen ein. Weitere Informationen finden Sie unter Verwenden von Python-Code aus einem Git-Remoterepository.
Delta Live Tables-Pipeline: Wählen Sie im Dropdown-Menü Pipeline eine vorhandene Delta Live Tables-Pipeline aus.
Wichtig
Sie können nur getriggerte Pipelines mit der Pipeline-Aufgabe verwenden. Kontinuierliche Pipelines werden nicht als Auftragsaufgabe unterstützt. Weitere Informationen zu ausgelösten und kontinuierlichen Pipelines finden Sie unter Ausführen von kontinuierlichen und ausgelösten Pipelines.
Python Wheel: Geben Sie in das Textfeld Paketname das zu importierende Paket ein, z. B.
myWheel-1.0-py2.py3-none-any.whl. Geben Sie im Textfeld Einstiegspunkt die Funktion ein, die beim Start der Python-Wheel-Datei aufgerufen werden soll. Klicken Sie unter Abhängige Bibliotheken auf Hinzufügen, um die für die Ausführung der Aufgabe erforderlichen Bibliotheken hinzuzufügen.SQL: Wählen Sie im Dropdownmenü SQL-Aufgabe die Option Abfrage, Legacy-Dashboard, Warnung oder Datei aus.
Hinweis
- Die SQL-Aufgabe erfordert Databricks SQL und ein SQL-Warehouse des Typs „Serverlos“ oder „Pro“.
Abfrage: Wählen Sie im Dropdownmenü SQL-Abfrage die Abfrage aus, die ausgeführt werden soll, wenn die Task ausgeführt wird.
Legacy-Dashboard: Wählen Sie im Dropdownmenü SQL-Dashboard ein Dashboard aus, das aktualisiert werden soll, wenn die Aufgabe ausgeführt wird.
Warnung: Wählen Sie im Dropdownmenü SQL-Warnung eine Warnung aus, die zur Auswertung ausgelöst werden soll.
Datei: Um eine SQL-Datei zu verwenden, die sich in einem Azure Databricks-Arbeitsbereich-Ordner befindet, wählen Sie im Dropdown-Menü Quelle die Option Arbeitsbereich, suchen Sie mit dem Dateibrowser die SQL-Datei, klicken Sie auf den Dateinamen und dann auf Bestätigen. Um eine SQL-Datei zu verwenden, die sich in einem Remote-Git-Repository befindet, wählen Sie Git-Anbieter aus, klicken Sie auf Bearbeiten oder Git-Verweis hinzufügen, und geben Sie Details für das Git-Repository ein. Weitere Informationen finden Sie unter Verwenden von SQL-Abfragen aus einem Git-Remoterepository.
Wählen Sie im Dropdownmenü SQL-Warehouse ein Warehouse des Typs „Serverlos“ oder „Pro“ zur Ausführung der Aufgabe aus.
dbt: Unter Verwenden von dbt-Transformationen in einem Azure Databricks-Auftrag finden Sie ein detailliertes Beispiel für die Konfiguration einer dbt-Task.
Auftrag ausführen: Wählen Sie im Dropdownmenü Auftrag einen Auftrag aus, der von der Aufgabe ausgeführt werden soll. Um nach dem auszuführenden Auftrag zu suchen, beginnen Sie mit der Eingabe des Auftragsnamens im Menü Auftrag.
Wichtig
Sie sollten keine Aufträge mit Ringabhängigkeiten erstellen, wenn Sie die Aufgabe
Run Joboder Aufträge verwenden, in denen mehr als dreiRun Job-Aufgaben geschachtelt sind. Ringabhängigkeiten sindRun Job-Aufgaben, die sich direkt oder indirekt gegenseitig auslösen. Beispielsweise löst Auftrag A Auftrag B und Auftrag B Auftrag A aus. Databricks unterstützt keine Aufträge mit Ringabhängigkeiten oder Aufträge, in denen als dreiRun Job-Aufgaben geschachtelt sind, sodass die Ausführung dieser Aufträge in zukünftigen Releases möglicherweise nicht zulässig ist.If/else: Informationen zur Verwendung der
If/else condition-Aufgabe finden Sie unter Hinzufügen von Verzweigungslogik zu Ihrem Auftrag mit der If/Else-Bedingungsaufgabe.
Übergeben von Parametern an eine Azure Databricks-Auftragsaufgabe
Sie können Parameter an viele Auftragsaufgabentypen übergeben. Jeder Aufgabentyp hat unterschiedliche Anforderungen in Bezug auf die Formatierung und die Übergabe der Parameter.
Verwenden Sie dynamische Wertverweise, um auf Informationen über die aktuelle Task zuzugreifen, z. B. den Task-Namen, oder um Kontext über den aktuellen Lauf zwischen Auftrags-Tasks weiterzugeben, z. B. die Startzeit des Auftrags oder die Kennung der aktuellen Auftragsausführung. Um eine Liste der verfügbaren dynamischen Wertreferenzen anzuzeigen, klicken Sie auf Dynamische Werte durchsuchen.
Wenn Auftragsparameter für den Auftrag konfiguriert sind, zu dem ein Vorgang gehört, werden diese Parameter angezeigt, wenn Sie Vorgangsparameter hinzufügen. Wenn Auftrags- und Vorgangsparameter einen Schlüssel gemeinsam nutzen, hat der Auftragsparameter Vorrang. In der Benutzeroberfläche wird eine Warnung angezeigt, wenn Sie versuchen, einen Aufgabenparameter mit demselben Schlüssel wie ein Auftragsparameter hinzuzufügen. Um Auftragsparameter an Aufgaben zu übergeben, die nicht mit Schlüsselwertparametern konfiguriert sind, wie z. B. JAR oder Spark Submit-Aufgaben, formatieren Sie die Argumente als {{job.parameters.[name]}}, wobei Sie das [name] durch das key ersetzen, das den Parameter identifiziert.
Notebook: Klicken Sie auf Hinzufügen, und geben Sie den Schlüssel und den Wert für jeden Parameter an, der an die Aufgabe übergeben werden soll. Sie können Parameter überschreiben oder zusätzliche Parameter hinzufügen, wenn Sie eine Aufgabe mit der Option Auftrag mit anderen Parametern ausführen manuell ausführen. Parameter legen den Wert für das Notebook-Widget fest, das durch den Schlüssel des Parameters angegeben wird.
JAR: Verwenden Sie ein JSON-formatiertes Array aus Zeichenfolgen, um Parameter anzugeben. Diese Zeichenfolgen werden als Argumente an die main-Methode der Hauptklasse übergeben. Siehe Konfigurieren von JAR-Auftragsparametern.
Spark Submit: Parameter werden als JSON-formatiertes Array aus Zeichenfolgen angegeben. Gemäß Apache Spark-Konvention für „spark-submit“ werden Parameter nach dem JAR-Pfad an die main-Methode der Hauptklasse übergeben.
Python-Wheel: Wählen Sie in der Dropdownliste Parameter die Option Positionelle Argumente aus, um die Parameter als JSON-formatiertes Array von Zeichenfolgen einzugeben, oder wählen Sie die Option Schlüsselwortargumente > Hinzufügen aus, um den Schlüssel und den Wert jedes Parameters einzugeben. Sowohl positionelle als auch Schlüsselwortargumente werden als Befehlszeilenargumente an die Python-Wheel-Aufgabe übergeben. Ein Beispiel für das Lesen von Argumenten in einem Python-Skript, das in einer Python-Wheel-Datei gepackt ist, finden Sie unter Verwenden einer Python-Wheel-Datei in einem Azure Databricks-Auftrag.
Ausführungsauftrag: Geben Sie den Schlüssel und wert der einzelnen Auftragsparameter ein, die an den Auftrag übergeben werden sollen.
Python-Skript: Verwenden Sie ein JSON-formatiertes Array von Zeichenfolgen, um Parameter anzugeben. Diese Zeichenfolgen werden als Argumente übergeben und können als positionelle Argumente gelesen oder mithilfe des argparse-Moduls in Python analysiert werden. Ein Beispiel für das Lesen von positionellen Argumenten in einem Python-Skript finden Sie unter Schritt 2: Erstellen eines Skripts zum Abrufen von GitHub-Daten.
SQL: Wenn Ihre Aufgabe eine parametrisierte Abfrage oder ein parametrisiertes Dashboard ausführt, geben Sie Werte für die Parameter in die bereitgestellten Textfelder ein.
Kopieren eines Aufgabenpfads
Bei bestimmten Aufgabentypen, z. B. Notebookaufgaben, können Sie den Pfad zum Quellcode der Aufgabe kopieren:
- Klicken Sie auf die Registerkarte Aufgaben.
- Wählen Sie die Aufgabe aus, die den zu kopierenden Pfad enthält.
- Klicken Sie auf
 neben dem Aufgabenpfad, um den Pfad in die Zwischenablage zu kopieren.
neben dem Aufgabenpfad, um den Pfad in die Zwischenablage zu kopieren.
Erstellen eines Auftrags aus einem vorhandenen Auftrag
Sie können schnell einen neuen Auftrag erstellen, indem Sie einen vorhandenen Auftrag klonen. Beim Klonen eines Auftrags wird, abgesehen von der Auftrags-ID, eine identische Kopie des Auftrags erstellt. Klicken Sie auf der Seite des Auftrags neben dem Auftragsnamen auf Mehr..., und wählen Sie im Dropdownmenü die Option Klonen aus.
Erstellen einer Aufgabe aus einer vorhandenen Aufgabe
Sie können schnell eine neue Aufgabe erstellen, indem Sie eine vorhandene Aufgabe klonen:
- Klicken Sie auf der Seite des Auftrags auf die Registerkarte Aufgaben.
- Wählen Sie die Aufgabe aus, die Sie klonen möchten.
- Klicken Sie auf
 , und wählen Sie Aufgabe klonen aus.
, und wählen Sie Aufgabe klonen aus.
Löschen eines Auftrags
Um einen Auftrag zu löschen, klicken Sie auf der Seite des Auftrags neben dem Auftragsnamen auf Mehr..., und wählen Sie im Dropdownmenü die Option Löschen aus.
Löschen einer Aufgabe
So löschen Sie eine Aufgabe
- Klicken Sie auf die Registerkarte Aufgaben.
- Wählen Sie die zu löschende Aufgabe aus.
- Klicken Sie auf , und wählen Sie Aufgabe entfernen aus.
Ausführen eines Auftrags
- Klicken Sie auf der Randleiste auf Workflows.
- Wählen Sie einen Auftrag aus, und klicken Sie auf die Registerkarte Ausführungen. Sie können einen Auftrag sofort ausführen oder zur späteren Ausführung planen.
Wenn eine oder mehrere Tasks in einem Auftrag mit mehreren Tasks nicht erfolgreich sind, können Sie die Teilmenge von nicht erfolgreichen Tasks erneut ausführen. Weitere Informationen finden Sie unter Erneutes Ausführen fehlgeschlagener und übersprungener Aufgaben.
Sofortiges Ausführen eines Auftrags
Klicken Sie auf  , um den Auftrag sofort auszuführen.
, um den Auftrag sofort auszuführen.
Tipp
Sie können eine Testausführung eines Auftrags mit einer Notebookaufgabe durchführen, indem Sie auf Jetzt ausführen klicken. Wenn Sie Änderungen am Notebook vornehmen müssen, klicken Sie nach der Bearbeitung des Notebooks erneut auf Jetzt ausführen, um automatisch die neue Version des Notebooks zu starten.
Ausführen eines Auftrags mit anderen Parametern
Mithilfe der Option Jetzt mit anderen Parametern ausführen können Sie einen Auftrag mit anderen Parametern oder anderen Werten für vorhandene Parameter erneut ausführen.
Hinweis
Sie können Auftragsparameter nicht außer Kraft setzen, wenn ein Auftrag, der vor der Einführung von Auftragsparametern ausgeführt wurde, Vorgangsparameter mit demselben Schlüssel überschreiben.
- Klicken Sie auf
 neben Jetzt ausführen, und wählen Sie Jetzt mit anderen Parametern ausführen, oder klicken Sie in der Tabelle Aktive Ausführungen auf Jetzt mit anderen Parametern ausführen. Geben Sie die neuen Parameter je nach Typ der Aufgabe ein. Siehe Übergeben von Parametern an eine Azure Databricks-Auftragsaufgabe.
neben Jetzt ausführen, und wählen Sie Jetzt mit anderen Parametern ausführen, oder klicken Sie in der Tabelle Aktive Ausführungen auf Jetzt mit anderen Parametern ausführen. Geben Sie die neuen Parameter je nach Typ der Aufgabe ein. Siehe Übergeben von Parametern an eine Azure Databricks-Auftragsaufgabe. - Klicken Sie auf Ausführen.
Ausführen eines Auftrags als Dienstprinzipal
Hinweis
Wenn Ihr Auftrag SQL-Abfragen mithilfe der SQL-Aufgabe ausführt, wird die zum Ausführen der Abfragen verwendete Identität durch die Freigabeeinstellungen jeder Abfrage bestimmt, auch wenn der Auftrag als Dienstprinzipal ausgeführt wird. Wenn eine Abfrage als Run as owner konfiguriert ist, wird die Abfrage immer mit der Identität der Besitzerin bzw. des Besitzers und nicht mit der Identität des Dienstprinzipals ausgeführt. Wenn eine Abfrage als Run as viewer konfiguriert ist, wird die Abfrage mit der Identität des Dienstprinzipals ausgeführt. Weitere Informationen zu Freigabeeinstellungen für Abfragen finden Sie unter Konfigurieren von Abfrageberechtigungen.
Standardmäßig werden Aufträge als Identität des Auftragsbesitzers oder der Auftragsbesitzerin ausgeführt. Das bedeutet, dass der Auftrag die Berechtigungen des Auftragsbesitzers oder der Auftragsbesitzerin annimmt. Der Auftrag kann nur auf Daten und Azure Databricks-Objekte zugreifen, für die der*die Auftragsbesitzer*in über Zugriffsberechtigungen verfügt. Sie können die Identität, die der Auftrag ausführt, in einen Dienstprinzipal ändern. Anschließend übernimmt der Auftrag die Berechtigungen dieses Dienstprinzipals und nicht die des Besitzers oder der Besitzerin.
Um die Einstellung Ausführen als zu ändern, benötigen Sie für den Auftrag entweder die Berechtigung KANN VERWALTEN oder IST BESITZER. Sie können die Einstellung Ausführen als auf sich selbst oder auf einen beliebigen Dienstprinzipal im Arbeitsbereich festlegen, für den Sie über die Rolle Dienstprinzipalbenutzer verfügen. Weitere Informationen finden Sie unter Rollen zum Verwalten von Dienstprinzipalen.
Hinweis
Wenn die Einstellung RestrictWorkspaceAdmins für einen Arbeitsbereich auf ALLOW ALL festgelegt ist, können Arbeitsbereichsadmins auch die Einstellung Ausführung als in ein beliebiges Benutzerkonto in ihrem Arbeitsbereich ändern. Informationen zum Einschränken von Arbeitsbereichsadmins auf das Ändern der Einstellung Ausführen als auf sich selbst oder auf Dienstprinzipale, für die sie die Rolle Dienstprinzipalbenutzer haben, finden Sie unter Einschränken von Arbeitsbereichsadmins.
Gehen Sie wie folgt vor, um das Feld „Ausführen als“ zu ändern:
- Klicken Sie auf der Seitenleiste auf Workflows.
- Klicken Sie in der Spalte Name auf den Auftragsnamen.
- Klicken Sie im Seitenbereich Auftragsdetails auf das Stiftsymbol neben dem Feld Ausführen als.
- Suchen Sie den Dienstprinzipal, und wählen Sie ihn aus.
- Klicken Sie auf Speichern.
Mithilfe der Dienstprinzipal-API für Arbeitsbereiche können Sie auch die Dienstprinzipale auflisten, für die Sie über die Rolle Benutzer verfügen. Weitere Informationen finden Sie unter Auflisten der Dienstprinzipale, die Sie verwenden können.
Ausführen eines Auftrags nach einem Zeitplan
Sie können einen Zeitplan verwenden, um Ihren Azure Databricks-Auftrag zu bestimmten Zeiten und in bestimmten Zeiträumen automatisch auszuführen. Weitere Informationen finden Sie unter Hinzufügen eines Auftragszeitplans.
Ausführen eines fortlaufenden Auftrags
Sie können sicherstellen, dass Ihr Auftrag immer aktiv ausgeführt wird. Weitere Informationen finden Sie unter Ausführen eines fortlaufenden Auftrags.
Ausführen eines Auftrags beim Eintreffen neuer Dateien
Um einen Auftrag auszulösen, wenn neue Dateien an einem externen Speicherort oder Volume eines Unity-Katalogs ankommen, verwenden Sie einen Dateiankunftstrigger.
Anzeigen und Ausführen eines mit Databricks-Ressourcenbundle erstellten Auftrags
Sie können die Benutzeroberfläche für Azure Databricks-Aufträge verwenden, um Aufträge anzuzeigen und auszuführen, die mit einem Databricks-Ressourcenbundle bereitgestellt wurden. Standardmäßig sind diese Aufträge auf der Auftragsbenutzeroberfläche schreibgeschützt. Wenn Sie einen Auftrag bearbeiten möchten, der mit einem Bundle bereitgestellt wurde, ändern Sie die Konfigurationsdatei des Bundles und stellen den Auftrag erneut bereit. Durch Anwenden von Änderungen ausschließlich auf die Bundlekonfiguration wird sichergestellt, dass die Quelldateien des Bundles immer die aktuelle Auftragskonfiguration widerspiegeln.
Wenn Sie jedoch sofortige Änderungen an einem Auftrag vornehmen müssen, können Sie den Auftrag von der Bundlekonfiguration trennen, um die Bearbeitung der Auftragseinstellungen auf der Benutzeroberfläche zu ermöglichen. Um den Auftrag zu trennen, wählen Sie Von Quelle trennen aus. Wählen Sie im Dialogfeld Von Quelle trennen die Option Trennen aus, um die Auswahl zu bestätigen.
Änderungen, die Sie auf der Benutzeroberfläche an dem Auftrag vornehmen, werden nicht auf die Bundlekonfiguration angewandt. Um Änderungen, die Sie auf der Benutzeroberfläche am Bundle vorgenommen haben, auf das Bundle anzuwenden, müssen Sie die Bundlekonfiguration manuell aktualisieren. Um den Auftrag erneut mit der Bundlekonfiguration zu verbinden, stellen Sie ihn mithilfe des Bundles erneut bereit.
Was muss ich tun, wenn mein Auftrag aufgrund von Parallelitätsgrenzwerten nicht ausgeführt werden kann?
Hinweis
Warteschlangen sind standardmäßig aktiviert, wenn Aufträge auf der Benutzeroberfläche erstellt werden.
Um zu verhindern, dass Ausführungen eines Auftrags aufgrund von Parallelitätsgrenzwerten übersprungen werden, können Sie die Warteschlange für den Auftrag aktivieren. Wenn die Warteschlange aktiviert ist und keine Ressourcen für eine Auftragsausführung verfügbar sind, wird die Ausführung für bis zu 48 Stunden in die Warteschlange eingereiht. Wenn Kapazitäten verfügbar sind, wird die Einreihung des Auftrags in die Warteschlange aufgehoben und der Auftrag wird ausgeführt. In die Warteschlange eingereihte Ausführungen werden in der Ausführungsliste für den Auftrag und der Liste der letzten Auftragsausführungen angezeigt.
Eine Ausführung wird in die Warteschlange eingereiht, wenn eine der folgenden Grenzwerte erreicht ist:
- Die maximale Anzahl gleichzeitig aktiver Ausführungen im Arbeitsbereich
- Die maximale Anzahl gleichzeitiger Ausführungen der
Run Job-Aufgabe im Arbeitsbereich - Die maximale Anzahl gleichzeitiger Ausführungen des Auftrags
Die Warteschlange ist eine Eigenschaft auf Auftragsebene, in die nur Ausführungen für den jeweiligen Auftrag gestellt werden.
Um Warteschlangen zu aktivieren oder zu deaktivieren, wählen Sie Erweiterte Einstellungen und dann im Seitenbereich Auftragsdetails die Umschaltfläche Warteschlange aus.