Kopieren von Daten vom HDFS-Server mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Daten vom HDFS-Server (Hadoop Distributed File System) kopiert werden. Weitere Informationen finden Sie in den Einführungsartikeln zu Azure Data Factory und Synapse Analytics.
Unterstützte Funktionen
Dieser HDFS-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/-) | ① ② |
| Lookup-Aktivität | ① ② |
| Delete-Aktivität | ① ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Der HDFS-Connector unterstützt insbesondere Folgendes:
- Kopieren von Dateien mithilfe der Windows-Authentifizierung (Kerberos) oder der anonymen Authentifizierung
- Kopieren von Dateien mithilfe des WebHDFS-Protokolls oder der integrierten DistCp-Unterstützung
- Kopieren von Dateien im jeweiligen Zustand oder Analysieren oder Generieren von Dateien mit den unterstützten Dateiformaten und Codecs für die Komprimierung
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in einer virtuellen privaten Amazon-Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Hinweis
Stellen Sie sicher, dass die Integration Runtime auf alle folgenden Komponenten des Hadoop-Clusters zugreifen kann: [Namenknotenserver]:[Namenknotenport] und [Datenknotenserver]:[Datenknotenport]. Der Standardwert für den [Namenknotenport] ist 50070, der Standardwert für den [Datenknotenport] ist 50075.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts für HDFS über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um über die Benutzeroberfläche des Azure-Portals einen verknüpften Dienst für HDFS zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie dann auf „Neu“:
Suchen Sie nach HDFS, und wählen Sie den HDFS-Connector aus.
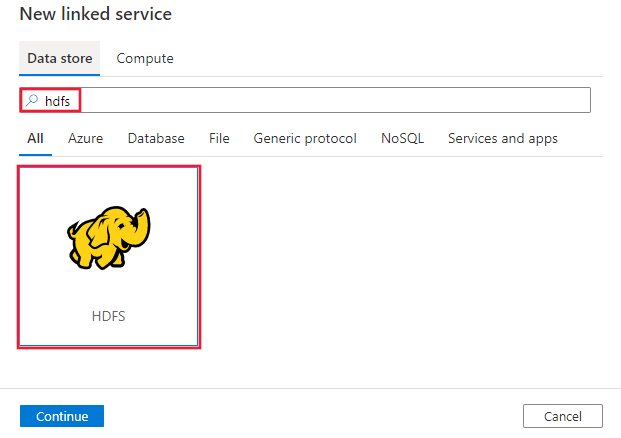
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
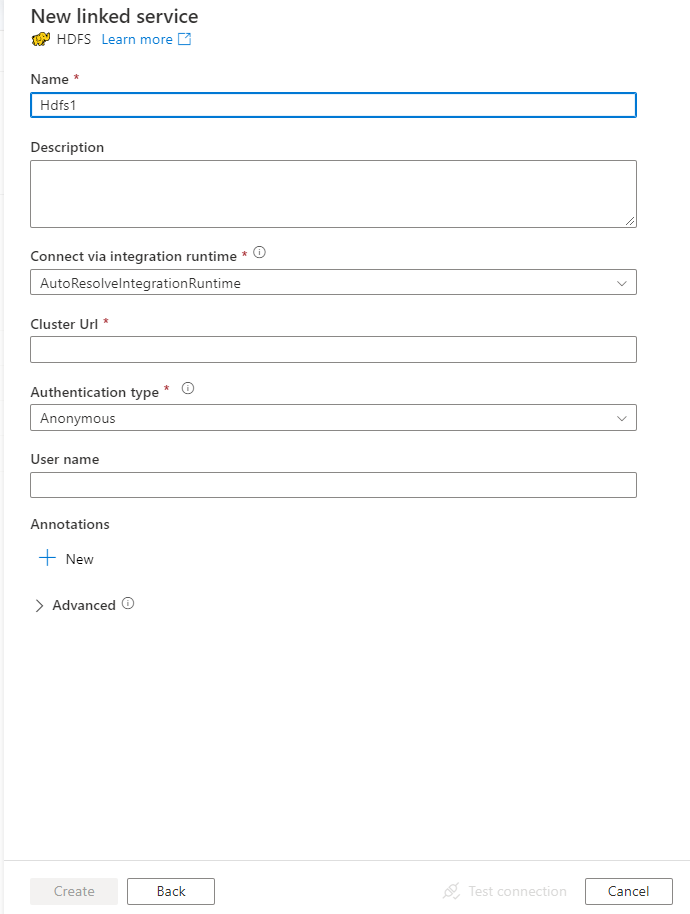
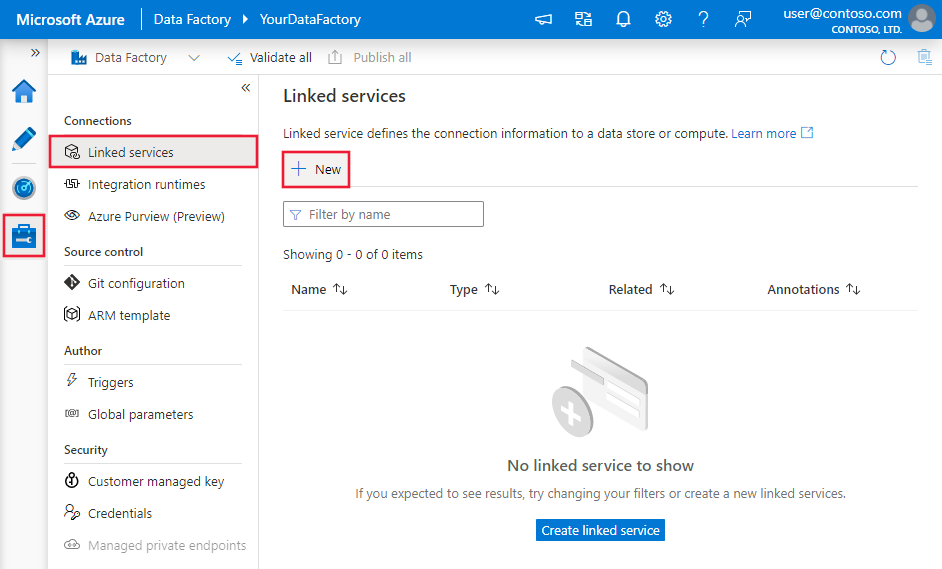
Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für HDFS verwendet werden.
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit HDFS verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf Hdfs festgelegt werden. | Ja |
| url | Die HDFS-URL | Ja |
| authenticationType | Die zulässigen Werte sind Anonymous oder Windows. Informationen zum Einrichten Ihrer lokalen Umgebung finden Sie im Abschnitt Verwenden der Kerberos-Authentifizierung für den HDFS-Connector. |
Ja |
| userName | Diese Eigenschaft gibt den Benutzernamen für die Windows-Authentifizierung an. Geben Sie für die Kerberos-Authentifizierung <Benutzername>@<Domäne>.com an. | Ja (für die Windows-Authentifizierung) |
| password | Diese Eigenschaft gibt das Kennwort für die Windows-Authentifizierung an. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Schlüsseltresor gespeichertes Geheimnis. | Ja (für die Windows-Authentifizierung) |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn die Integration Runtime nicht angegeben ist, verwendet der Dienst die Standard-Azure Integration Runtime. | Nein |
Beispiel: Verwenden der anonymen Authentifizierung
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Verwenden der Windows-Authentifizierung
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie unter Datasets.
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Folgende Eigenschaften werden für HDFS unter den location-Einstellungen im formatbasierten Dataset unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft unter location im Dataset muss auf HdfsLocation festgelegt werden. |
Ja |
| folderPath | Diese Eigenschaft gibt den Pfad zum Ordner an. Wenn Sie einen Platzhalter verwenden möchten, um den Ordner zu filtern, überspringen Sie diese Einstellung, und geben Sie den Pfad in den Aktivitätsquelleneinstellungen an. | Nein |
| fileName | Der Name der Datei unter dem angegebenen folderPath. Wenn Sie einen Platzhalter verwenden möchten, um Dateien zu filtern, überspringen Sie diese Einstellung, und geben Sie den Dateinamen in den Aktivitätsquelleneinstellungen an. | Nein |
Beispiel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den verfügbaren Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Pipelines und Aktivitäten. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der HDFS-Quelle unterstützt werden.
HDFS als Quelle
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Folgende Eigenschaften werden für HDFS unter den storeSettings-Einstellungen in der formatbasierten Kopierquelle unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft unter storeSettings muss auf HdfsReadSettings festgelegt werden. |
Ja |
| Suchen der zu kopierenden Dateien | ||
| OPTION 1: statischer Pfad |
Kopieren Sie aus dem im Dataset angegebenen Ordner oder Dateipfad. Wenn Sie alle Dateien aus einem Ordner kopieren möchten, geben Sie zusätzlich für wildcardFileName den Wert * an. |
|
| OPTION 2: Platzhalter – wildcardFolderPath |
Der Ordnerpfad mit Platzhalterzeichen, um Quellordner zu filtern. Folgende Platzhalter sind zulässig: * (entspricht null [0] oder mehr Zeichen) und ? (entspricht null [0] oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn der tatsächliche Ordnername einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Nein |
| OPTION 2: Platzhalter – wildcardFileName |
Der Dateiname mit Platzhalterzeichen unter dem angegebenen folderPath/wildcardFolderPath für das Filtern von Quelldateien. Zulässige Platzhalter sind: * (entspricht 0 oder mehr Zeichen) und ? (entspricht 0 oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr tatsächlicher Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Ja |
| OPTION 3: eine Liste von Dateien – fileListPath |
Diese Eigenschaft gibt an, dass eine angegebene Dateigruppe kopiert werden soll. Verweisen Sie auf eine Textdatei, die eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile, mit dem relativen Pfad zu dem im Dataset konfigurierten Pfad. Wenn Sie diese Option verwenden, geben Sie keinen Dateinamen im Dataset an. Weitere Beispiele finden Sie unter Beispiele für Dateilisten. |
Nein |
| Zusätzliche Einstellungen | ||
| recursive | Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Wenn recursive auf true festgelegt ist und es sich bei der Senke um einen dateibasierten Speicher handelt, wird ein leerer Ordner oder Unterordner nicht in die Senke kopiert oder dort erstellt. Zulässige Werte sind true (Standard) und false. Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| deleteFilesAfterCompletion | Gibt an, ob die Binärdateien nach dem erfolgreichen Verschieben in den Zielspeicher aus dem Quellspeicher gelöscht werden. Die Dateien werden einzeln gelöscht, sodass Sie bei einem Fehler der Kopieraktivität feststellen werden, dass einige Dateien bereits ins Ziel kopiert und aus der Quelle gelöscht wurden, wohingegen sich andere weiter im Quellspeicher befinden. Diese Eigenschaft ist nur im Szenario zum Kopieren von Binärdateien gültig. Standardwert: FALSE. |
Nein |
| modifiedDatetimeStart | Die Dateien werden anhand des Attributs Zuletzt bearbeitet gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format 2018-12-01T05:00:00Z angewandt. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewandt wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEnd NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd einen datetime-Wert aufweist, aber modifiedDatetimeStart NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist.Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| modifiedDatetimeEnd | Wie oben. | |
| enablePartitionDiscovery | Geben Sie bei partitionierten Dateien an, ob die Partitionen anhand des Dateipfads analysiert und als zusätzliche Quellspalten hinzugefügt werden sollen. Zulässige Werte sind false (Standard) und true. |
Nein |
| partitionRootPath | Wenn die Partitionsermittlung aktiviert ist, geben Sie den absoluten Stammpfad an, um partitionierte Ordner als Datenspalten zu lesen. Ohne Angabe gilt standardmäßig Folgendes: - Wenn Sie den Dateipfad im Dataset oder die Liste der Dateien in der Quelle verwenden, ist der Partitionsstammpfad der im Dataset konfigurierte Pfad. Wenn Sie einen Platzhalterordnerfilter verwenden, ist der Stammpfad der Partition der Unterpfad vor dem ersten Platzhalter. Angenommen, Sie konfigurieren den Pfad im Dataset als „root/folder/year=2020/month=08/day=27“: - Wenn Sie den Stammpfad der Partition als „root/folder/year=2020“ angeben, generiert die Kopieraktivität zusätzlich zu den Spalten in den Dateien die beiden weiteren Spalten month und day mit den Werten „08“ bzw. „27“.- Wenn kein Stammpfad für die Partition angegeben ist, wird keine zusätzliche Spalte generiert. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
| DistCp-Einstellungen | ||
| distcpSettings | Diese Eigenschaftengruppe sollte bei Verwendung von HDFS DistCp verwendet werden. | Nein |
| resourceManagerEndpoint | Der YARN-Endpunkt (Yet Another Resource Negotiator) | Ja, wenn DistCp verwendet wird |
| tempScriptPath | Diese Eigenschaft gibt einen Ordnerpfad zum Speichern der temporären DistCp-Befehlsskripts an. Die Skriptdatei wird generiert und nach Abschluss des Copy-Auftrags entfernt. | Ja, wenn DistCp verwendet wird |
| distcpOptions | Zusätzliche für den DistCp-Befehl bereitgestellte Optionen | Nein |
Beispiel:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Beispiele für Ordner- und Dateifilter
Dieser Abschnitt beschreibt das sich ergebende Verhalten, wenn Sie für den Ordnerpfad und den Dateinamen einen Platzhalterfilter verwenden.
| folderPath | fileName | recursive | Quellordnerstruktur und Filterergebnis (Dateien mit Fettformatierung werden abgerufen.) |
|---|---|---|---|
Folder* |
(empty, use default) | false | FolderA Datei1.csv File2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
(empty, use default) | true | FolderA Datei1.csv File2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
*.csv |
false | FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
*.csv |
true | FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Beispiele für Dateilisten
In diesem Abschnitt wird das aus der Verwendung eines Dateilistenpfads in der Quelle einer Kopieraktivität resultierende Verhalten beschrieben. Es wird angenommen, dass Sie die folgende Quellordnerstruktur verwenden und die Dateien kopieren möchten, deren Namen fett formatiert sind:
| Beispielquellstruktur | Inhalt in „FileListToCopy.txt“ | Konfiguration |
|---|---|---|
| root FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv Metadaten FileListToCopy.txt |
Datei1.csv Unterordner1/Datei3.csv Unterordner1/Datei5.csv |
Im Dataset: – Ordnerpfad: root/FolderAIn der Quelle der Kopieraktivität: – Dateilistenpfad: root/Metadata/FileListToCopy.txt Der Dateilistenpfad verweist auf eine Textdatei im selben Datenspeicher, der eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile, mit dem relativen Pfad zu dem im Dataset konfigurierten Pfad. |
Kopieren von Daten aus einem HDFS mithilfe von DistCp
DistCp ist ein natives Hadoop-Befehlszeilentool, um verteilte Kopiervorgänge in einem Hadoop-Cluster durchzuführen. Wenn Sie einen Befehl in DistCp ausführen, werden zunächst alle zu kopierenden Dateien aufgelistet und dann mehrere Zuordnungsaufträge im Hadoop-Cluster erstellt. Jeder Zuordnungsauftrag führt eine Binärkopieraktivität von der Quelle in die Senke durch.
Die Kopieraktivität unterstützt mithilfe von DistCp das Kopieren von Dateien im jeweiligen Zustand in Azure Blob Storage (einschließlich der gestaffelten Kopie) oder einen Azure Data Lake-Speicher. In diesem Fall kann DistCp von der Leistung Ihres Clusters profitieren, anstatt über die selbstgehostete Integration Runtime ausgeführt zu werden. Durch die Verwendung von DistCp erreichen Sie einen besseren Kopierdurchsatz, insbesondere dann, wenn Sie über einen äußerst leistungsstarken Cluster verfügen. Basierend auf der Konfiguration erstellt die Copy-Aktivität automatisch einen DistCp-Befehl, sendet diesen an Ihren Hadoop-Cluster und überwacht den Kopierstatus.
Voraussetzungen
Wenn Sie mithilfe von DistCp Dateien im jeweiligen Zustand aus HDFS in Azure Blob Storage (einschließlich der gestaffelten Kopie) oder Azure Data Lake Store kopieren möchten, müssen Sie sicherstellen, dass Ihr Hadoop-Cluster die folgenden Anforderungen erfüllt:
Die Dienste MapReduce und YARN sind aktiviert.
Die YARN-Version ist 2.5 oder höher.
Der HDFS-Server ist mit Ihrem Zieldatenspeicher integriert: Azure Blob Storage oder Azure Data Lake Storage (ADLS Gen1) :
- Das Azure-Blobdateisystem wird nativ ab Hadoop 2.7 unterstützt. Sie müssen lediglich den JAR-Pfad bei der Konfiguration der Hadoop-Umgebung angeben.
- Das Azure Data Lake Store-Dateisystem wird ab Hadoop 3.0.0-alpha1 verpackt. Wenn Sie eine frühere Version des Hadoop-Clusters verwenden, müssen Sie zu Azure Data Lake Storage gehörige JAR-Pakete (azure-datalake-store.jar) von hier aus manuell in den Cluster importieren und den Pfad der JAR-Datei bei der Konfiguration der Hadoop-Umgebung angeben.
Bereiten Sie einen temporären Ordner in HDFS vor. In diesem temporären Ordner wird ein DistCp-Shellskript gespeichert, sodass Speicherplatz im KB-Bereich belegt wird.
Stellen Sie sicher, dass das Benutzerkonto, das im mit HDFS verknüpften Dienst bereitgestellt wird, über die Berechtigungen für Folgendes verfügt:
- Übermitteln einer Anwendung in YARN
- Erstellen eines Unterordners und Lesen/Schreiben von Dateien im temporären Ordner
Configurations
Informationen zu DistCp-bezogenen Konfigurationen sowie Beispiele finden Sie im Abschnitt HDFS als Quelle.
Verwenden der Kerberos-Authentifizierung für den HDFS-Connector
Es gibt zwei Optionen zum Einrichten der lokalen Umgebung zur Verwendung der Kerberos-Authentifizierung für den HDFS-Connector. Wählen Sie die Option, die für Ihren Fall besser geeignet ist.
- Option 1: Beitreten zum Computer mit der selbstgehosteten Integration Runtime im Kerberosbereich
- Option 2: Aktivieren von gegenseitiger Vertrauensstellung zwischen der Windows-Domäne und dem Kerberos-Bereich
Stellen Sie für beide Optionen sicher, dass Sie webhdfs für Hadoop-Cluster aktivieren:
Erstellen Sie den HTTP-Prinzipal und die Schlüsseltabelle für webhdfs.
Wichtig
Der HTTP-Kerberos-Prinzipal muss gemäß der Kerberos-HTTP-SPNEGO-Spezifikation mit „HTTP/ “ beginnen. Weitere Informationen dazu finden Sie hier.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>HDFS-Konfigurationsoptionen: Fügen Sie die folgenden drei Eigenschaften in
hdfs-site.xmlhinzu.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
Option 1: Beitreten zum Computer mit der selbstgehosteten Integration Runtime im Kerberosbereich
Requirements (Anforderungen)
- Der Computer mit der selbstgehosteten Integration Runtime muss dem Kerberosbereich beitreten und darf in keine Windows-Domäne eingebunden sein.
Vorgehensweise zur Konfiguration
KDC-Server:
Erstellen Sie einen Prinzipal, und geben Sie das Kennwort an.
Wichtig
Der Benutzername darf nicht den Hostnamen enthalten.
Kadmin> addprinc <username>@<REALM.COM>
Auf dem Computer mit der selbstgehosteten Integration Runtime:
Führen Sie das Ksetup-Hilfsprogramm aus, um den Kerberos-KDC-Server (Key Distribution Center) und -Bereich zu konfigurieren.
Der Computer muss als Mitglied einer Arbeitsgruppe konfiguriert werden, da sich Kerberos-Bereiche von Windows-Domänen unterscheiden. Diese Konfiguration erreichen Sie, indem Sie mithilfe der folgenden Befehle den Kerberosbereich festlegen und einen KDC-Server hinzufügen. Ersetzen Sie REALM.COM durch Ihren eigenen Bereichsnamen.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>Nachdem Sie diese Befehle ausgeführt haben, starten Sie den Computer neu.
Überprüfen Sie die Konfiguration mit dem
Ksetup-Befehl. Die Ausgabe sollte wie folgt sein:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
In Ihrem Data Factory. oder Synapse-Arbeitsbereich:
- Konfigurieren Sie den HDFS-Connector mithilfe der Windows-Authentifizierung zusammen mit dem Namen und Kennwort Ihres Kerberos-Prinzipals, um eine Verbindung mit der HDFS-Datenquelle herzustellen. Genaue Informationen zur Konfiguration finden Sie im Abschnitt Eigenschaften des verknüpften Diensts.
Option 2: Aktivieren von gegenseitiger Vertrauensstellung zwischen der Windows-Domäne und dem Kerberos-Bereich
Requirements (Anforderungen)
- Der Computer mit der selbstgehosteten Integration Runtime muss einer Windows-Domäne beitreten.
- Sie benötigen die Berechtigung zum Aktualisieren der Einstellungen des Domänencontrollers.
Vorgehensweise zur Konfiguration
Hinweis
Ersetzen Sie REALM.COM und AD.COM im folgenden Tutorial durch Ihren eigenen Bereichsnamen und Domänencontroller.
KDC-Server:
Bearbeiten Sie die KDC-Konfiguration in der Datei krb5.conf mithilfe der folgenden Konfigurationsvorlage so, dass KDC der Windows-Domäne vertraut. Standardmäßig befindet sich die Konfiguration unter /etc/krb5.conf.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }Nachdem Sie die Datei konfiguriert haben, starten Sie den KDC-Dienst neu.
Bereiten Sie einen Prinzipal namens krbtgt/REALM.COM@AD.COM mit dem folgenden Befehl auf dem KDC-Server vor:
Kadmin> addprinc krbtgt/REALM.COM@AD.COMFügen Sie
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//zur HDFS-Dienstkonfigurationsdatei hadoop.security.auth_to_local hinzu.
Domänencontroller:
Führen Sie die folgenden
Ksetup-Befehle aus, um einen Bereichseintrag hinzuzufügen:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMStellen Sie Vertrauensstellung zwischen der Windows-Domäne und dem Kerberos-Bereich her. „[password]“ ist das Kennwort für den Prinzipal krbtgt/REALM.COM@AD.COM.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Wählen Sie den in Kerberos verwendeten Verschlüsselungsalgorithmus aus.
a. Klicken Sie auf Server Manager>Group Policy Management>Domain>Group Policy Objects>Default or Active Domain Policy (Server-Manager > Gruppenrichtlinienverwaltung > Domäne > Gruppenrichtlinienobjekte > Standard- oder aktive Domänenrichtlinie), und klicken Sie dann auf Bearbeiten.
b. Klicken Sie im Bereich Gruppenrichtlinienverwaltungs-Editor auf Computerkonfiguration>Richtlinien>Windows-Einstellungen>Sicherheitseinstellungen>Lokale Richtlinien>Sicherheitsoptionen, und konfigurieren Sie die Einstellung Netzwerksicherheit: Für Kerberos zulässige Verschlüsselungstypen konfigurieren.
c. Wählen Sie den Verschlüsselungsalgorithmus aus, den Sie beim Herstellen einer Verbindung mit KDC verwenden möchten. Sie können alle Optionen auswählen.
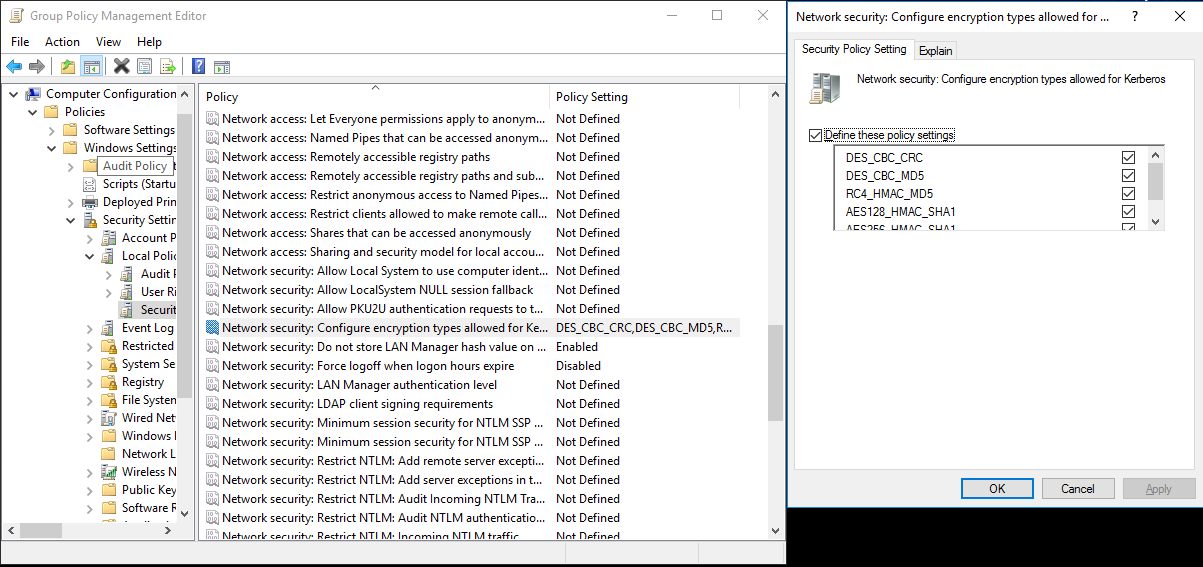
d. Verwenden Sie den Befehl
Ksetup, um den Verschlüsselungsalgorithmus anzugeben, der in dem bestimmten Bereich verwendet werden soll.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Erstellen Sie die Zuordnung zwischen dem Domänenkonto und dem Kerberos-Prinzipal, sodass Sie den Kerberos-Prinzipal in der Windows-Domäne verwenden können.
a. Klicken Sie auf Verwaltung>Active Directory-Benutzer und -Computer.
b. Konfigurieren Sie erweiterte Funktionen unter Ansicht>Erweiterte Funktionen.
c. Klicken Sie im Bereich Erweiterte Features mit der rechten Maustaste auf das Konto, für das Sie Zuordnungen erstellen möchten, und klicken Sie im Bereich Namenszuordnungen auf die Registerkarte Kerberos-Namen.
d. Fügen Sie einen Prinzipal aus dem Bereich hinzu.
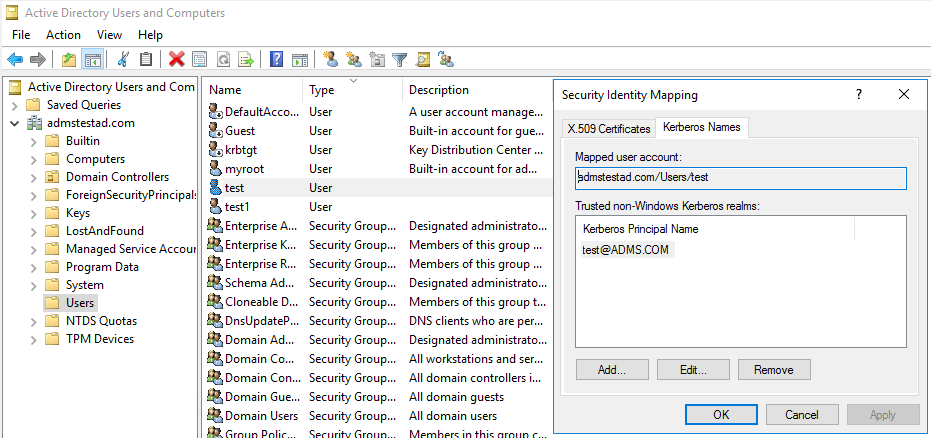
Auf dem Computer mit der selbstgehosteten Integration Runtime:
Führen Sie die folgenden
Ksetup-Befehle aus, um einen Bereichseintrag hinzuzufügen.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
In Ihrem Data Factory. oder Synapse-Arbeitsbereich:
- Konfigurieren Sie den HDFS-Connector mithilfe der Windows-Authentifizierung zusammen mit Ihrem Domänenkonto oder Ihrem Kerberos-Prinzipal, um eine Verbindung mit der HDFS-Datenquelle herzustellen. Genaue Informationen zur Konfiguration finden Sie im Abschnitt Eigenschaften des verknüpften Diensts.
Eigenschaften der Lookup-Aktivität
Weitere Informationen zu den Eigenschaften der Lookup-Aktivität finden Sie unter Lookup-Aktivität.
Eigenschaften der Delete-Aktivität
Weitere Informationen zu den Eigenschaften der Löschaktivität finden Sie unter Löschaktivität.
Legacy-Modelle
Hinweis
Die folgenden Modelle werden aus Gründen der Abwärtskompatibilität weiterhin unverändert unterstützt. Es wird empfohlen, das zuvor beschriebene neue Modell zu verwenden, da auf der Erstellungsbenutzeroberfläche nun das neue Modell generieren wird.
Legacy-Datasetmodell
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf FileShare festgelegt werden. | Ja |
| folderPath | Diese Eigenschaft gibt den Pfad zum Ordner an. Ein Platzhalterfilter wird unterstützt. Zulässige Platzhalter sind: * (entspricht 0 oder mehr Zeichen) und ? (entspricht 0 oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr tatsächlicher Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Beispiele: Stammordner/Unterordner/. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Ja |
| fileName | Diese Eigenschaft gibt den Namen oder Platzhalterfilter für die Dateien unter dem angegebenen Wert für „folderPath“ an. Wenn Sie für diese Eigenschaft keinen Wert angeben, verweist das Dataset auf alle Dateien im Ordner. Für Filter sind folgende Platzhalter zulässig: * (entspricht 0 oder mehr Zeichen) und ? (entspricht 0 oder einem einzelnen Zeichen).- Beispiel 1: "fileName": "*.csv"- Beispiel 2: "fileName": "???20180427.txt"Verwenden Sie ^ als Escapezeichen, wenn der tatsächliche Ordnername einen Platzhalter oder dieses Escapezeichen enthält. |
Nein |
| modifiedDatetimeStart | Die Dateien werden anhand des Attributs Zuletzt bearbeitet gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format 2018-12-01T05:00:00Z angewandt. Beachten Sie, dass die generelle Leistung der Datenverschiebung beeinträchtigt wird, wenn Sie diese Einstellung aktivieren und einen Dateifilter auf eine große Anzahl von Dateien anwenden möchten. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewandt wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEnd NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd einen datetime-Wert aufweist, aber modifiedDatetimeStart NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist. |
Nein |
| modifiedDatetimeEnd | Die Dateien werden anhand des Attributs Zuletzt bearbeitet gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format 2018-12-01T05:00:00Z angewandt. Beachten Sie, dass die generelle Leistung der Datenverschiebung beeinträchtigt wird, wenn Sie diese Einstellung aktivieren und einen Dateifilter auf eine große Anzahl von Dateien anwenden möchten. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewandt wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEnd NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd einen datetime-Wert aufweist, aber modifiedDatetimeStart NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist. |
Nein |
| format | Wenn Sie Dateien unverändert zwischen dateibasierten Speichern kopieren möchten (binäre Kopie), überspringen Sie den Formatabschnitt in den Definitionen der Eingabe- und Ausgabedatasets. Für das Analysieren von Dateien mit einem bestimmten Format werden die folgenden Dateiformattypen unterstützt: TextFormat, JsonFormat, AvroFormat, OrcFormat und ParquetFormat. Sie müssen die type -Eigenschaft unter „format“ auf einen dieser Werte festlegen. Weitere Informationen finden Sie in den Abschnitten Textformat, JSON-Format, Avro-Format, ORC-Format und Parquet-Format. |
Nein (nur für Szenarien mit Binärkopien) |
| compression | Geben Sie den Typ und den Grad der Komprimierung für die Daten an. Weitere Informationen finden Sie unter Unterstützte Dateiformate und Codecs für die Komprimierung. Folgende Typen werden unterstützt: Gzip, Deflate, Bzip2 und ZipDeflate. Folgende Ebenen werden unterstützt: Optimal und Fastest. |
Nein |
Tipp
Wenn Sie alle Dateien eines Ordners kopieren möchten, geben Sie nur folderPath an.
Wenn Sie eine einzelne Datei mit einem bestimmten Namen kopieren möchten, geben Sie folderPath mit der Ordnerkomponente und fileName mit dem Dateinamen an.
Wenn Sie eine Teilmenge der Dateien eines Ordners kopieren möchten, geben Sie folderPath mit dem Ordner und fileName mit dem Platzhalterfilter an.
Beispiel:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Legacy-Quellenmodell der Kopieraktivität
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf HdfsSource festgelegt werden. | Ja |
| recursive | Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Wenn „recursive“ auf true festgelegt ist und es sich bei der Senke um einen dateibasierten Speicher handelt, wird ein leerer Ordner oder Unterordner nicht in die Senke kopiert oder dort erstellt. Zulässige Werte sind true (Standard) und false. |
Nein |
| distcpSettings | Dies ist die Eigenschaftengruppe bei der Verwendung von HDFS DistCp. | Nein |
| resourceManagerEndpoint | Der YARN-Ressourcen-Manager-Endpunkt | Ja, wenn DistCp verwendet wird |
| tempScriptPath | Diese Eigenschaft gibt einen Ordnerpfad zum Speichern der temporären DistCp-Befehlsskripts an. Die Skriptdatei wird generiert und nach Abschluss des Copy-Auftrags entfernt. | Ja, wenn DistCp verwendet wird |
| distcpOptions | Mit dieser Eigenschaft werden zusätzliche Optionen für den DistCp-Befehl bereitgestellt. | Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
Beispiel: HDFS-Quelle in der Kopieraktivität unter Verwendung von DistCp
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quellen und Senken für die Copy-Aktivität unterstützt werden, finden Sie hier Unterstützte Datenspeicher.