Kopieren von Daten aus Oracle Cloud Storage mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie Daten vom Oracle Cloud Storage kopieren. Weitere Informationen finden Sie in den Einführungsartikeln zu Azure Data Factory und Synapse Analytics.
Unterstützte Funktionen
Dieser Oracle Cloud Storage Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/-) | ① ② |
| Lookup-Aktivität | ① ② |
| GetMetadata-Aktivität | ① ② |
| Delete-Aktivität | ① ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Der Oracle Cloud Storage-Connector unterstützt insbesondere das Kopieren von Dateien im jeweiligen Zustand oder Analysieren von Dateien mit den unterstützten Dateiformaten und Codecs für die Komprimierung. Es nutzt die S3-kompatible Interoperabilität von Oracle Cloud Storage.
Voraussetzungen
Wenn Sie Daten aus Oracle Cloud Storage kopieren möchten, finden Sie hier Informationen zu den Voraussetzungen und erforderlichen Berechtigungen.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts mit Oracle Cloud Storage über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um über die Benutzeroberfläche des Azure-Portals einen verknüpften Dienst für Oracle Cloud Storage zu erstellen.
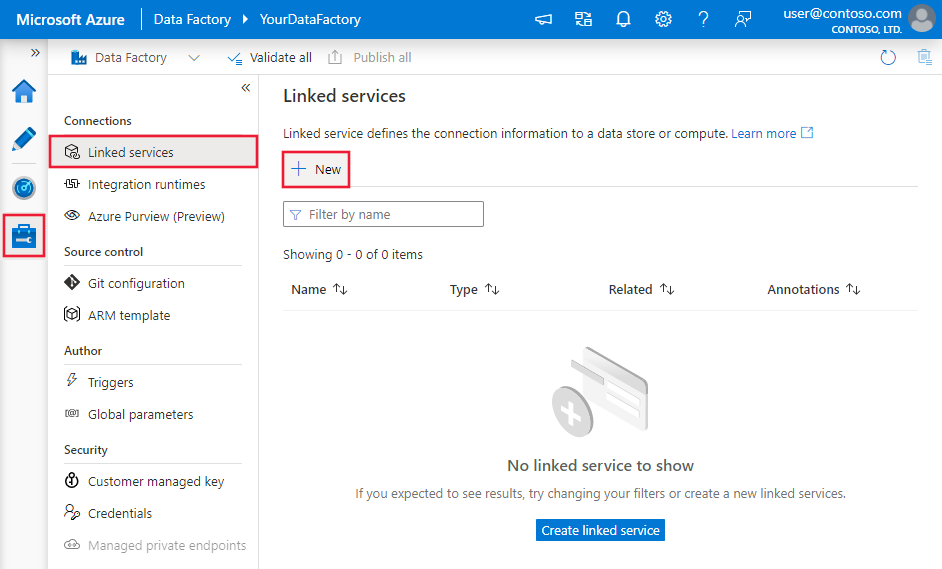
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie dann auf „Neu“:
Suchen Sie nach Oracle, und wählen Sie den Oracle Cloud Storage-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
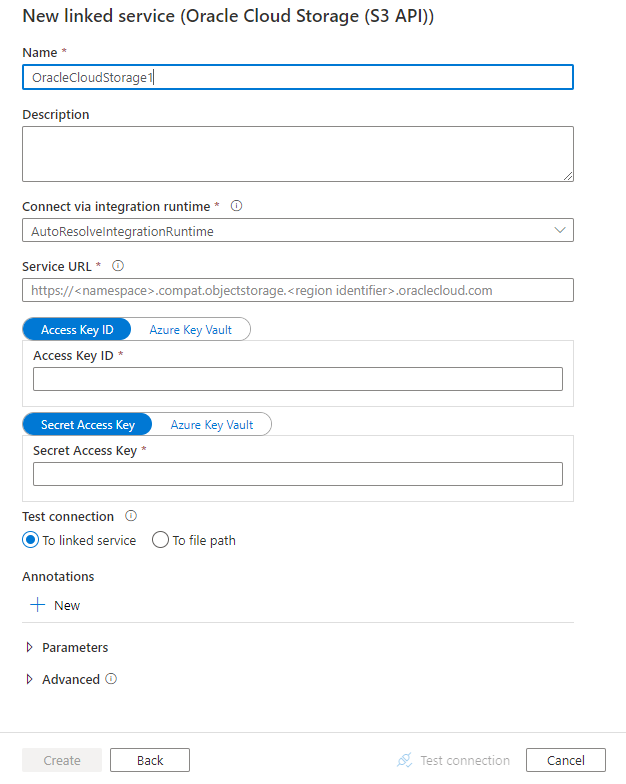
Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Oracle Cloud Storage-spezifischen Entitäten verwendet werden.
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für mit Oracle Cloud Storage verknüpfte Dienste unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf OracleCloudStorage festgelegt werden. | Ja |
| accessKeyId | ID des geheimen Zugriffsschlüssels. Informationen zum Ermitteln des Zugriffsschlüssels und des Geheimnisses finden Sie unter Voraussetzungen. | Ja |
| secretAccessKey | Der geheime Zugriffsschlüssel selbst. Markieren Sie dieses Feld als einen SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Ja |
| serviceUrl | Geben Sie den benutzerdefinierten Endpunkt als https://<namespace>.compat.objectstorage.<region identifier>.oraclecloud.com an. Ausführlichere Informationen finden Sie hier. |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn diese Eigenschaft nicht angegeben ist, verwendet der Dienst die normale Azure Integration Runtime. | Nein |
Hier sehen Sie ein Beispiel:
{
"name": "OracleCloudStorageLinkedService",
"properties": {
"type": "OracleCloudStorage",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"serviceUrl": "https://<namespace>.compat.objectstorage.<region identifier>.oraclecloud.com"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Folgende Eigenschaften werden für Oracle Cloud Storage unter location-Einstellungen in einem formatbasierten Dataset unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft unter location im Dataset muss auf OracleCloudStorageLocation festgelegt werden. |
Ja |
| bucketName | Der Name des Oracle Cloud Storage-Buckets. | Ja |
| folderPath | Der Pfad zum Ordner unter dem angegebenen Bucket. Wenn Sie einen Platzhalter verwenden möchten, um den Ordner zu filtern, überspringen Sie diese Einstellung, und geben Sie entsprechende Aktivitätsquelleneinstellungen an. | Nein |
| fileName | Der Name der Datei unter dem angegebenen Bucket und Ordnerpfad. Wenn Sie einen Platzhalter verwenden möchten, um die Dateien zu filtern, überspringen Sie diese Einstellung, und geben Sie entsprechende Aktivitätsquelleneinstellungen an. | Nein |
Beispiel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Oracle Cloud Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "OracleCloudStorageLocation",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Oracle Cloud Storage-Quelle unterstützt werden.
Oracle Cloud Storage als Quelle
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Folgende Eigenschaften werden für Oracle Cloud Storage unter storeSettings-Einstellungen in einer formatbasierten Kopierquelle unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft unter storeSettings muss auf OracleCloudStorageReadSettings festgelegt werden. |
Ja |
| Suchen Sie die zu kopierenden Dateien: | ||
| OPTION 1: statischer Pfad |
Kopieren Sie aus dem im Dataset angegebenen Bucket oder Ordner/Dateipfad. Wenn Sie alle Dateien aus einem Bucket oder Ordner kopieren möchten, geben Sie zusätzlich für wildcardFileName den Wert * an. |
|
| OPTION 2: Oracle Cloud Storage-Präfix – prefix |
Das Präfix für den Namen des Oracle Cloud Storage-Schlüssels unter dem angegebenen Bucket, konfiguriert im Dataset zum Filtern von Oracle Cloud Storage-Dateien. Es werden die Oracle Cloud Storage-Schlüssel ausgewählt, deren Namen mit bucket_in_dataset/this_prefix beginnen. Es wird der dienstseitige Oracle Cloud Storage-Filter verwendet, dessen Leistung im Vergleich zu Platzhalterfiltern besser ist. |
Nein |
| OPTION 3: Platzhalter – wildcardFolderPath |
Der Ordnerpfad mit Platzhalterzeichen unter dem angegebenen Bucket, der in einem Dataset für das Filtern von Quellordnern konfiguriert ist. Folgende Platzhalter sind zulässig: * (entspricht null [0] oder mehr Zeichen) und ? (entspricht null [0] oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr Ordnername einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Nein |
| OPTION 4: Platzhalter – wildcardFileName |
Der Dateiname mit Platzhalterzeichen unter dem angegebenen Bucket und Ordnerpfad (oder Platzhalterordnerpfad) für das Filtern von Quelldateien. Folgende Platzhalter sind zulässig: * (entspricht null [0] oder mehr Zeichen) und ? (entspricht null [0] oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn der tatsächliche Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Ja |
| OPTION 5: eine Liste von Dateien – fileListPath |
Gibt an, dass eine bestimmte Dateigruppe kopiert werden soll. Verweisen Sie auf eine Textdatei, die eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile. Dies ist der relative Pfad zu dem im Dataset konfigurierten Pfad. Wenn Sie diese Option verwenden, geben Sie keinen Dateinamen im Dataset an. Weitere Beispiele finden Sie unter Beispiele für Dateilisten. |
Nein |
| Zusätzliche Einstellungen: | ||
| recursive | Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Beachten Sie Folgendes: Wenn recursive auf TRUE festgelegt ist und es sich bei der Senke um einen dateibasierten Speicher handelt, wird ein leerer Ordner oder Unterordner nicht in die Senke kopiert und dort auch nicht erstellt. Zulässige Werte sind true (Standard) und false. Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| deleteFilesAfterCompletion | Gibt an, ob die Binärdateien nach dem erfolgreichen Verschieben in den Zielspeicher aus dem Quellspeicher gelöscht werden. Die Dateien werden einzeln gelöscht, sodass Sie bei einem Fehler der Kopieraktivität feststellen werden, dass einige Dateien bereits ins Ziel kopiert und aus der Quelle gelöscht wurden, wohingegen sich andere weiter im Quellspeicher befinden. Diese Eigenschaft ist nur im Szenario zum Kopieren von Binärdateien gültig. Standardwert: FALSE. |
Nein |
| modifiedDatetimeStart | Die Dateien werden anhand des Attributs „Letzte Änderung“ gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format „2018-12-01T05:00:00Z“ angewandt. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewendet wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEndNULL ist, werden die Dateien ausgewählt, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd den datetime-Wert aufweist, aber modifiedDatetimeStartNULL ist, werden die Dateien ausgewählt, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist.Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| modifiedDatetimeEnd | Wie oben. | Nein |
| enablePartitionDiscovery | Geben Sie bei partitionierten Dateien an, ob die Partitionen anhand des Dateipfads analysiert und als zusätzliche Quellspalten hinzugefügt werden sollen. Zulässige Werte sind false (Standard) und true. |
Nein |
| partitionRootPath | Wenn die Partitionsermittlung aktiviert ist, geben Sie den absoluten Stammpfad an, um partitionierte Ordner als Datenspalten zu lesen. Ohne Angabe gilt standardmäßig Folgendes: - Wenn Sie den Dateipfad im Dataset oder die Liste der Dateien in der Quelle verwenden, ist der Partitionsstammpfad der im Dataset konfigurierte Pfad. Wenn Sie einen Platzhalterordnerfilter verwenden, ist der Stammpfad der Partition der Unterpfad vor dem ersten Platzhalter. Angenommen, Sie konfigurieren den Pfad im Dataset als „root/folder/year=2020/month=08/day=27“: - Wenn Sie den Stammpfad der Partition als „root/folder/year=2020“ angeben, generiert die Kopieraktivität zusätzlich zu den Spalten in den Dateien die beiden weiteren Spalten month und day mit den Werten „08“ bzw. „27“.- Wenn kein Stammpfad für die Partition angegeben ist, wird keine zusätzliche Spalte generiert. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
Beispiel:
"activities":[
{
"name": "CopyFromOracleCloudStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "OracleCloudStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Beispiele für Ordner- und Dateifilter
Dieser Abschnitt beschreibt das sich ergebende Verhalten für den Ordnerpfad und den Dateinamen mit Platzhalterfiltern.
| bucket | Schlüssel | recursive | Quellordnerstruktur und Filterergebnis (Dateien mit Fettformatierung werden abgerufen.) |
|---|---|---|---|
| bucket | Folder*/* |
false | bucket FolderA Datei1.csv File2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
| bucket | Folder*/* |
true | bucket FolderA Datei1.csv File2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
| bucket | Folder*/*.csv |
false | bucket FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
| bucket | Folder*/*.csv |
true | bucket FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Beispiele für Dateilisten
In diesem Abschnitt wird das resultierende Verhalten beschrieben, wenn ein Dateilistenpfad in der Quelle einer Kopieraktivität verwendet wird.
Angenommen, Sie haben die folgende Quellordnerstruktur und möchten die Dateien kopieren, deren Namen fett formatiert sind:
| Beispielquellstruktur | Inhalt in „FileListToCopy.txt“ | Konfiguration |
|---|---|---|
| bucket FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv Metadaten FileListToCopy.txt |
Datei1.csv Unterordner1/Datei3.csv Unterordner1/Datei5.csv |
Im Dataset: – Bucket: bucket– Ordnerpfad: FolderAIn der Quelle der Kopieraktivität: – Dateilistenpfad: bucket/Metadata/FileListToCopy.txt Der Dateilistenpfad verweist auf eine Textdatei im selben Datenspeicher, der eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile. Diese enthält den relativen Pfad zu dem im Dataset konfigurierten Pfad. |
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Eigenschaften der GetMetadata-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter GetMetadata-Aktivität.
Eigenschaften der Delete-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Delete-Aktivität.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die diese Kopieraktivität als Quellen und Senken unterstützt, finden Sie unter Unterstützte Datenspeicher.