Erstellen erweiterter Systeme der erweiterten Abruferweiterung
Im vorherigen Artikel wurden zwei Optionen für die Erstellung eines "Chats über Ihre Daten"-Anwendung erörtert, einer der ersten Anwendungsfälle für generative KI in Unternehmen:
- Das Abrufen einer erweiterten Generation (RAG), die eine LLM-Schulung (Large Language Model) mit einer Datenbank durchsuchbarer Artikel ergänzt, die basierend auf Ähnlichkeit mit den Abfragen der Benutzer abgerufen und zur Fertigstellung an die LLM übergeben werden können.
- Feinabstimmung, die die LLM-Schulung erweitert, um mehr über die Problemdomäne zu verstehen.
Im vorherigen Artikel wurde auch erläutert, wann die einzelnen Ansätze, Pro und Cons von jedem Ansatz und mehrere andere Überlegungen verwendet werden sollen.
In diesem Artikel wird die RAG genauer untersucht, insbesondere alle Erforderlichen, um eine produktionsfähige Lösung zu erstellen.
Im vorherigen Artikel wurden die Schritte oder Phasen der RAG anhand des folgenden Diagramms dargestellt.
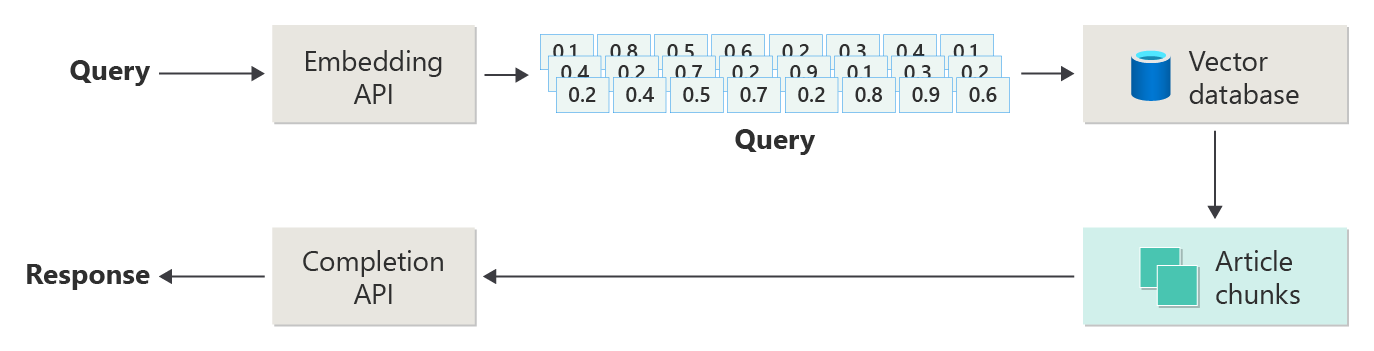
Diese Darstellung wurde als "naive RAG" bezeichnet und ist eine nützliche Möglichkeit, zunächst die Mechanismen, Rollen und Verantwortlichkeiten zu verstehen, die zum Implementieren eines RAG-basierten Chatsystems erforderlich sind.
Eine realere Implementierung verfügt jedoch über viele weitere Schritte vor und nach der Verarbeitung, um die Artikel, die Abfragen und die antworten für die Verwendung vorzubereiten. Das folgende Diagramm ist eine realistischere Darstellung einer RAG, die manchmal als "erweiterte RAG" bezeichnet wird.

Dieser Artikel enthält ein konzeptionelles Framework für das Verständnis der Arten von Problemen vor und nach der Verarbeitung in einem echten RAG-basierten Chatsystem, das wie folgt organisiert ist:
- Aufnahmephase
- Ableitungspipelinephase
- Auswertungsphase
Als konzeptionelle Übersicht werden die Schlüsselwörter und Ideen als Kontext und Ausgangspunkt für weitere Erkundungen und Forschungen bereitgestellt.
Erfassung
Bei der Aufnahme geht es in erster Linie darum, die Dokumente Ihrer Organisation so zu speichern, dass sie einfach abgerufen werden können, um die Frage eines Benutzers zu beantworten. Die Herausforderung besteht darin, sicherzustellen, dass sich die Teile der Dokumente, die am besten mit der Abfrage des Benutzers übereinstimmen, befinden und während der Ableitung verwendet werden. Der Abgleich erfolgt in erster Linie durch vektorisierte Einbettungen und eine Kosinus-Ähnlichkeitssuche. Es wird jedoch erleichtert, die Art des Inhalts (Muster, Formular usw.) und die Datenorganisationsstrategie (die Struktur der Daten beim Speichern in der Vektordatenbank) zu verstehen.
Zu diesem Zweck müssen Entwickler Folgendes berücksichtigen:
- Vorabverarbeitung und Extraktion von Inhalten
- Blockierungsstrategie
- Abteilungsorganisation
- Updatestrategie
Vorabverarbeitung und Extraktion von Inhalten
Saubere und genaue Inhalte sind eine der besten Möglichkeiten, um die Gesamtqualität eines RAG-basierten Chatsystems zu verbessern. Dazu müssen Entwickler zunächst die Form und Form der dokumente analysieren, die indiziert werden sollen. Entsprechen die Dokumente bestimmten Inhaltsmustern wie dokumentation? Wenn nicht, welche Arten von Fragen können die Dokumente beantworten?
Mindestens sollten Entwickler Schritte in der Aufnahmepipeline erstellen, um:
- Standardisieren von Textformaten
- Behandeln von Sonderzeichen
- Entfernen von nicht verknüpften, veralteten Inhalten
- Konto für versionsierte Inhalte
- Konto für die Inhaltserfahrung (Registerkarten, Bilder, Tabellen)
- Extrahieren von Metadaten
Einige dieser Informationen (z. B. Metadaten) können hilfreich sein, um das Dokument in der Vektordatenbank zur Verwendung während des Abruf- und Auswertungsprozesses in der Ableitungspipeline oder in Kombination mit dem Textblock zu verwenden, um die Vektoreinbettung des Blocks zu überzeugen.
Blockierungsstrategie
Entwickler müssen entscheiden, wie ein längeres Dokument in kleinere Abschnitte unterteilt werden soll. Dies kann die Relevanz der zusätzlichen Inhalte verbessern, die an die LLM gesendet werden, um die Abfrage des Benutzers genau zu beantworten. Darüber hinaus müssen Entwickler überlegen, wie sie die Blöcke beim Abruf nutzen können. Dies ist ein Bereich, in dem Systemdesigner einige Forschungen zu Techniken durchführen sollten, die in der Branche verwendet werden, und einige Experimente durchführen, sogar in einer begrenzten Kapazität in ihrer Organisation zu testen.
Entwickler müssen Folgendes berücksichtigen:
- Optimierung der Blockgröße – Bestimmen Sie, was die ideale Größe des Blocks ist, und wie Sie einen Block festlegen. Nach Abschnitt? Nach Absatz? Nach Satz?
- Überlappende und gleitende Fensterblöcke – Bestimmen Sie, wie der Inhalt in einzelne Blöcke unterteilt werden soll. Oder überlappen sich die Blöcke? Oder beides (Gleitfenster)?
- Small2Big - Wenn Blöcke auf einer granularen Ebene wie ein einzelner Satz unterteilt werden, wird der Inhalt so organisiert, dass es leicht ist, die benachbarten Sätze oder den Absatz zu finden? (Siehe "Blockierungsorganisation".) Durch das Abrufen dieser zusätzlichen Informationen und das Bereitstellen dieser Informationen an das LLM könnte sie beim Beantworten der Abfrage des Benutzers mehr Kontext bereitstellen.
Abteilungsorganisation
In einem RAG-System ist die Organisation von Daten in der Vektordatenbank entscheidend für den effizienten Abruf relevanter Informationen zur Erweiterung des Erzeugungsprozesses. Hier sind die Arten von Indizierungs- und Abrufstrategien, die Entwickler berücksichtigen können:
- Hierarchische Indizes – Bei diesem Ansatz werden mehrere Ebenen von Indizes erstellt, bei denen ein Index der obersten Ebene (Zusammenfassungsindex) den Suchbereich schnell auf eine Teilmenge potenziell relevanter Blöcke einschränkt und ein Index der zweiten Ebene (Index der Blöcke) detailliertere Zeiger auf die tatsächlichen Daten bereitstellt. Diese Methode kann den Abrufvorgang erheblich beschleunigen, da dadurch die Anzahl der Einträge reduziert wird, die im detaillierten Index durch filtern, indem zuerst der Zusammenfassungsindex gefiltert wird.
- Spezialisierte Indizes – Spezialisierte Indizes wie graphbasierte oder relationale Datenbanken können abhängig von der Art der Daten und der Beziehungen zwischen Blöcken verwendet werden. Beispiel:
- Graphbasierte Indizes sind nützlich, wenn die Blöcke über miteinander verbundene Informationen oder Beziehungen verfügen, die den Abruf verbessern können, z. B. Zitatnetzwerke oder Wissensdiagramme.
- Relationale Datenbanken können effektiv sein, wenn die Blöcke in einem tabellarischen Format strukturiert sind, in dem SQL-Abfragen verwendet werden können, um Daten basierend auf bestimmten Attributen oder Beziehungen zu filtern und abzurufen.
- Hybridindizes – Ein Hybridansatz kombiniert mehrere Indizierungsstrategien, um die Stärken der einzelnen zu nutzen. Entwickler können beispielsweise einen hierarchischen Index für die anfängliche Filterung und einen graphbasierten Index verwenden, um Beziehungen zwischen Blöcken während des Abrufs dynamisch zu untersuchen.
Ausrichtungsoptimierung
Um die Relevanz und Genauigkeit der abgerufenen Blöcke zu verbessern, kann es von Vorteil sein, sie genauer an die Arten von Fragen oder Abfragen auszurichten, die sie beantworten sollen. Eine Strategie, um dies zu erreichen, besteht darin, eine hypothetische Frage für jeden Block zu generieren und einzufügen, der angibt, welche Frage der Block am besten für die Beantwortung geeignet ist. Dies hilft auf verschiedene Arten:
- Verbesserte Übereinstimmung: Während des Abrufs kann das System die eingehende Abfrage mit diesen hypothetischen Fragen vergleichen, um die beste Übereinstimmung zu finden und die Relevanz der abgerufenen Blöcke zu verbessern.
- Schulungsdaten für Machine Learning-Modelle: Diese Kopplungen von Fragen und Blöcken können als Schulungsdaten dienen, um die machine Learning-Modelle zu verbessern, die dem RAG-System zugrunde liegen, um zu lernen, welche Arten von Fragen am besten beantwortet werden.
- Direkte Abfragebehandlung: Wenn eine echte Benutzerabfrage eng mit einer hypothetischen Frage übereinstimmt, kann das System den entsprechenden Block schnell abrufen und verwenden, um die Antwortzeit zu beschleunigen.
Die hypothetische Frage jedes Blocks fungiert als eine Art "Bezeichnung", die den Abrufalgorithmus leitet, wodurch er fokussierter und kontextbezogener wird. Dies ist in Szenarien hilfreich, in denen die Blöcke eine breite Palette von Themen oder Informationstypen abdecken.
Aktualisieren von Strategien
Wenn Ihre Organisation Dokumente indizieren muss, die häufig aktualisiert werden, ist es wichtig, einen aktualisierten Korpus beizubehalten, um sicherzustellen, dass die Retriever-Komponente (die Logik im System, die für die Durchführung der Abfrage für die Vektordatenbank verantwortlich ist und die Ergebnisse zurückgibt) auf die aktuellsten Informationen zugreifen kann. Hier sind einige Strategien zum Aktualisieren der Vektordatenbank in solchen Systemen:
- Inkrementelle Updates:
- Regelmäßige Intervalle: Planen Sie Aktualisierungen in regelmäßigen Intervallen (z. B. täglich, wöchentlich), abhängig von der Häufigkeit der Dokumentänderungen. Diese Methode stellt sicher, dass die Datenbank regelmäßig aktualisiert wird.
- Triggerbasierte Updates: Implementieren eines Systems, in dem Updates eine erneute Indizierung auslösen. Beispielsweise könnte jede Änderung oder Ergänzung eines Dokuments automatisch eine Neuindizierung der betroffenen Abschnitte initiieren.
- Teilaktualisierungen:
- Selektive Neuindizierung: Statt die gesamte Datenbank neu zu indizieren, aktualisieren Sie selektiv nur die Teile des Korpus, die sich geändert haben. Dies kann effizienter als die vollständige erneute Indizierung sein, insbesondere für große Datasets.
- Delta-Codierung: Speichern Sie nur die Unterschiede zwischen den vorhandenen Dokumenten und ihren aktualisierten Versionen. Durch diesen Ansatz wird die Datenverarbeitungslast reduziert, da keine unveränderten Daten verarbeitet werden müssen.This approach reduces the data processing load by avoiding the need to process unchanged data.
- Versionsverwaltung:
- Momentaufnahme: Verwalten von Versionen des Dokumentkorpus zu verschiedenen Zeitpunkten. Auf diese Weise kann das System bei Bedarf zurückgesetzt oder auf frühere Versionen verweisen und einen Sicherungsmechanismus bereitstellt.
- Dokumentversionskontrolle: Verwenden Sie ein Versionssteuerungssystem, um Änderungen in Dokumenten systematisch nachzuverfolgen. Dies hilft bei der Aufrechterhaltung des Verlaufs von Änderungen und kann den Updateprozess vereinfachen.
- Echtzeitaktualisierungen:
- Streamverarbeitung: Verwenden Sie Datenstromverarbeitungstechnologien, um die Vektordatenbank in Echtzeit zu aktualisieren, da Änderungen an den Dokumenten vorgenommen werden. Dies kann für Anwendungen wichtig sein, bei denen Informationszeitachsen von größter Bedeutung sind.
- Liveabfragen: Implementieren Sie einen Mechanismus zum Abfragen von Livedaten für die aktuellsten Antworten, anstatt sich ausschließlich auf vorindizierte Vektoren zu verlassen, und kombinieren Sie dies möglicherweise mit zwischengespeicherten Ergebnissen zur Effizienz.
- Optimierungstechniken:
- Batchverarbeitung: Sammeln Sie Änderungen an, und verarbeiten Sie sie in Batches, um die Verwendung von Ressourcen zu optimieren und den Aufwand zu reduzieren, der durch häufige Updates verursacht wird.
- Hybridansätze: Kombinieren Sie verschiedene Strategien, z. B. die Verwendung inkrementeller Updates für kleinere Änderungen und vollständige Neuindizierung für wichtige Aktualisierungen oder strukturelle Änderungen im Dokumentkorpus.
Die Auswahl der richtigen Updatestrategie oder die Kombination von Strategien hängt von bestimmten Anforderungen wie der Größe des Dokumentkorpus, der Häufigkeit der Aktualisierungen, der Notwendigkeit von Echtzeitdaten und der Ressourcenverfügbarkeit ab. Jeder Ansatz hat seine Kompromisse hinsichtlich Komplexität, Kosten und Aktualisierungslatenz, sodass es wichtig ist, diese Faktoren basierend auf den spezifischen Anforderungen der Anwendung zu bewerten.
Rückschlusspipeline
Nachdem die Artikel in einer Vektordatenbank geblockt, vektorisiert und gespeichert wurden, dreht sich der Fokus auf Herausforderungen im Abschluss.
- Ist die Abfrage des Benutzers so geschrieben, dass die Ergebnisse aus dem System abgerufen werden, nach dem der Benutzer sucht?
- Verstößt die Abfrage des Benutzers gegen eine unserer Richtlinien?
- Wie schreiben wir die Abfrage des Benutzers um, um die Wahrscheinlichkeit zu verbessern, die nächsten Übereinstimmungen in der Vektordatenbank zu finden?
- Wie bewerten wir die Abfrageergebnisse, um sicherzustellen, dass der Artikelabschnitt an die Abfrage ausgerichtet ist?
- Wie bewerten und ändern wir die Abfrageergebnisse, bevor wir sie an das LLM übergeben, um sicherzustellen, dass die relevantesten Details im Abschluss des LLM enthalten sind?
- Wie bewerten wir die Antwort des LLM, um sicherzustellen, dass der Abschluss des LLM die ursprüngliche Abfrage des Benutzers beantwortet?
- Wie stellen wir sicher, dass die Antwort des LLM unseren Richtlinien entspricht?
Wie Sie sehen können, gibt es viele Aufgaben, die Entwickler berücksichtigen müssen, hauptsächlich in Form von:
- Vorverarbeitung von Eingaben zur Optimierung der Wahrscheinlichkeit, dass die gewünschten Ergebnisse erzielt werden
- Ausgaben nach der Verarbeitung, um die gewünschten Ergebnisse sicherzustellen
Denken Sie daran, dass die gesamte Ableitungspipeline in Echtzeit ausgeführt wird. Obwohl es keine richtige Möglichkeit gibt, die Logik zu entwerfen, die die Schritte vor und nach der Verarbeitung ausführt, ist es wahrscheinlich, dass es sich um eine Kombination aus Programmierlogik und zusätzlichen Aufrufen eines LLM handelt. Einer der wichtigsten Aspekte ist dann der Kompromiss zwischen der Erstellung der möglichst genauen und kompatiblen Pipeline sowie der Kosten und Latenz, die erforderlich sind, um dies zu ermöglichen.
Sehen wir uns jede Phase an, um bestimmte Strategien zu identifizieren.
Abfragevorbearbeitungsschritte
Die Vorverarbeitung der Abfrage erfolgt unmittelbar nach der Übermittlung der Abfrage durch den Benutzer, wie in diesem Diagramm dargestellt:

Ziel dieser Schritte ist es, sicherzustellen, dass der Benutzer Fragen im Rahmen unseres Systems stellt (und nicht versucht, das System zu "Jailbreak" zu machen, um es zu einem unbeabsichtigten Vorgang zu machen) und die Abfrage des Benutzers vorzubereiten, um die Wahrscheinlichkeit zu erhöhen, dass er die bestmöglichen Artikelabschnitte mithilfe der Kosinus-Ähnlichkeit / "nächster Nachbar" Suche findet.
Richtlinienüberprüfung – Dieser Schritt kann Logik umfassen, die bestimmte Inhalte identifiziert, entfernt, kennzeichnet oder ablehnt. Einige Beispiele können das Entfernen von persönlich identifizierbaren Informationen, das Entfernen von Expletiven und das Identifizieren von "Jailbreak"-Versuchen umfassen. Jailbreaking bezieht sich auf die Methoden, die Benutzer verwenden können, um die integrierten Sicherheits-, ethischen oder betrieblichen Richtlinien des Modells zu umgehen oder zu manipulieren.
Erneutes Schreiben von Abfragen – Dies könnte alles sein, indem Sie Akronyme erweitern und Slang entfernen, um die Frage neu zu ausdrücken, um sie abstrakter zu stellen, um allgemeine Konzepte und Prinzipien ("Schritt-Zurück-Eingabeaufforderung") zu extrahieren.
Eine Variation bei der Rücksuchaufforderung ist hypothetische Dokumenteinbettungen (HyDE), die die LLM verwendet, um die Frage des Benutzers zu beantworten, eine Einbettung für diese Antwort (das hypothetische Einbetten von Dokumenten) erstellt und diese Einbettung verwendet, um eine Suche mit der Vektordatenbank durchzuführen.
Unterabfragen
Dieser Verarbeitungsschritt betrifft die ursprüngliche Abfrage. Wenn die ursprüngliche Abfrage lang und komplex ist, kann sie programmgesteuert in mehrere kleinere Abfragen unterteilt werden, und dann alle Antworten kombinieren.
Betrachten Sie beispielsweise eine Frage im Zusammenhang mit wissenschaftlichen Entdeckungen, insbesondere im Bereich der Physik. Die Abfrage des Benutzers könnte lauten: "Wer hat wichtigere Beiträge zur modernen Physik, Albert Einstein oder Niels Bohr geleistet?"
Diese Abfrage kann so komplex sein, dass sie direkt verarbeitet werden kann, da "signifikante Beiträge" subjektiv und vielfältig sein können. Das Aufteilen in Unterabfragen kann dies verwaltbarer machen:
- Unterabfrage 1: "Was sind die wichtigsten Beiträge von Albert Einstein zur modernen Physik?"
- Unterabfrage 2: "Was sind die wichtigsten Beiträge von Niels Bohr zur modernen Physik?"
Die Ergebnisse dieser Unterabfragen würden die wichtigsten Theorien und Entdeckungen jedes Physikers detailliert erläutern. Zum Beispiel:
- Für Einstein können Beiträge die Theorie der Relativität, des photoelektrischen Effekts und E=mc^2 enthalten.
- Für Bohr könnten Beiträge sein Modell des Wasserstoffatoms, seine Arbeit zur Quantenmechanik und sein Komplementaritätsprinzip umfassen.
Sobald diese Beiträge skizziert sind, können sie bewertet werden, um Folgendes zu bestimmen:
- Unterabfrage 3: "Wie haben Einsteins Theorien die Entwicklung der modernen Physik beeinflusst?"
- Unterabfrage 4: "Wie haben Bohrs Theorien die Entwicklung der modernen Physik beeinflusst?"
Diese Unterabfragen würden den Einfluss der Arbeit jedes Wissenschaftlers auf das Feld untersuchen, z. B. wie Einsteins Theorien zu Fortschritten in der Kosmologie und Quantentheorie geführt haben und wie Bohrs Arbeit zum Verständnis der atomischen Struktur und Quantenmechanik beitrug.
Die Kombination der Ergebnisse dieser Unterabfragen kann dazu beitragen, dass das Sprachmodell eine umfassendere Antwort dazu bildet, wer wichtigere Beiträge zur modernen Physik geleistet hat, basierend auf dem Umfang und den Auswirkungen ihrer theoretischen Fortschritte. Diese Methode vereinfacht die ursprüngliche komplexe Abfrage, indem sie sich mit spezifischeren, antwortbaren Komponenten befasst und diese Ergebnisse dann zu einer kohärenten Antwort synthetisiert.
Abfragerouter
Es ist möglich, dass Ihre Organisation entscheidet, seinen Inhaltskorpus in mehrere Vektorspeicher oder ganze Abrufsysteme aufzuteilen. In diesem Fall können Entwickler einen Abfragerouter verwenden, bei dem es sich um einen Mechanismus handelt, der intelligent bestimmt, welche Indizes oder Abrufmodule basierend auf der bereitgestellten Abfrage verwendet werden sollen. Die primäre Funktion eines Abfragerouters besteht darin, den Abruf von Informationen zu optimieren, indem sie die am besten geeignete Datenbank oder den am besten geeigneten Index auswählen, der die besten Antworten auf eine bestimmte Abfrage liefern kann.
Der Abfragerouter funktioniert in der Regel an einem Punkt, nachdem die Abfrage vom Benutzer formuliert wurde, aber bevor er an alle Abrufsysteme gesendet wird. Hier ist ein vereinfachter Workflow:
- Abfrageanalyse: Die LLM oder eine andere Komponente analysiert die eingehende Abfrage, um den Inhalt, den Kontext und die Art der informationen zu verstehen, die wahrscheinlich erforderlich sind.
- Indexauswahl: Basierend auf der Analyse wählt der Abfragerouter einen oder mehrere aus potenziell mehreren verfügbaren Indizes aus. Jeder Index kann für verschiedene Arten von Daten oder Abfragen optimiert werden, z. B. sind einige eher für faktenbezogene Abfragen geeignet, während andere in der Bereitstellung von Meinungen oder subjektiven Inhalten excelieren.
- Abfrageversand: Die Abfrage wird dann an den ausgewählten Index verteilt.
- Ergebnisaggregation: Antworten aus den ausgewählten Indizes werden abgerufen und möglicherweise aggregiert oder weiter verarbeitet, um eine umfassende Antwort zu bilden.
- Antwortgenerierung: Der letzte Schritt umfasst das Generieren einer kohärenten Antwort basierend auf den abgerufenen Informationen, möglicherweise die Integration oder Synthesisierung von Inhalten aus mehreren Quellen.
Ihre Organisation verwendet möglicherweise mehrere Abrufmodule oder Indizes für die folgenden Anwendungsfälle:
- Spezialisierung des Datentyps: Einige Indizes können sich auf Nachrichtenartikel, andere in akademischen Arbeiten und noch andere in allgemeinen Webinhalten oder bestimmten Datenbanken wie solchen für medizinische oder rechtliche Informationen spezialisiert haben.
- Optimierung des Abfragetyps: Bestimmte Indizes können für schnelle faktenbezogene Nachschlagevorgänge optimiert werden (z. B. Datumsangaben, Ereignisse), während andere für komplexe Grundaufgaben oder Abfragen, die umfassende Domänenkenntnisse erfordern, besser geeignet sind.
- Algorithmische Unterschiede: Verschiedene Abrufalgorithmen können in verschiedenen Engines verwendet werden, z. B. vektorbasierte Ähnlichkeitssuchen, herkömmliche schlüsselwortbasierte Suchvorgänge oder komplexere Semantikverständnismodelle.
Stellen Sie sich ein RAG-basiertes System vor, das in einem medizinischen Beratungskontext verwendet wird. Das System hat Zugriff auf mehrere Indizes:
- Ein medizinischer Forschungspapierindex, der für detaillierte und technische Erläuterungen optimiert ist.
- Ein klinischer Fallstudienindex, der praxisnahe Beispiele für Symptome und Behandlungen bereitstellt.
- Ein allgemeiner Integritätsinformationsindex für grundlegende Abfragen und Informationen zur öffentlichen Gesundheit.
Wenn ein Benutzer eine technische Frage zu den chemischen Wirkungen eines neuen Medikaments stellt, kann der Abfragerouter den Index des medizinischen Forschungspapiers aufgrund seiner Tiefe und technischen Fokus priorisieren. Für eine Frage zu typischen Symptomen einer gemeinsamen Krankheit kann der allgemeine Gesundheitsindex jedoch für seinen breiten und leicht verständlichen Inhalt gewählt werden.
Schritte nach dem Abrufen von Verarbeitungsschritten
Die Nachabrufverarbeitung erfolgt, nachdem die Retriever-Komponente relevante Inhaltsblöcke aus der Vektordatenbank wie im Diagramm dargestellt abruft:

Bei abgerufenen Kandidateninhaltsblöcken müssen die nächsten Schritte überprüft werden, ob die Artikelblöcke beim Erweitern der LLM-Eingabeaufforderung nützlich sind und dann mit der Vorbereitung der Aufforderung beginnen, die dem LLM angezeigt werden soll.
Entwickler müssen mehrere Aspekte der Eingabeaufforderung berücksichtigen. Eine Eingabeaufforderung, die zu viele ergänzende Informationen enthält, und einige (möglicherweise die wichtigsten Informationen) können ignoriert werden. Auf ähnliche Weise könnte eine Aufforderung, die irrelevante Informationen enthält, die Antwort nicht beeinträchtigen.
Eine weitere Überlegung ist die Nadel in einem Heuhaufenproblem , ein Begriff, der auf eine bekannte Eigenheit einiger LLMs verweist, bei denen der Inhalt am Anfang und Ende einer Eingabeaufforderung eine größere Gewichtung für den LLM hat als der Inhalt in der Mitte.
Schließlich muss die maximale Kontextfensterlänge des LLM und die Anzahl der Token, die erforderlich sind, um außerordentlich lange Eingabeaufforderungen (insbesondere beim Umgang mit Abfragen im Großen) abzuschließen, berücksichtigt werden.
Um diese Probleme zu beheben, kann eine Pipeline nach dem Abruf die folgenden Schritte umfassen:
- Filterergebnisse – In diesem Schritt stellen Entwickler sicher, dass die von der Vektordatenbank zurückgegebenen Artikelblöcke für die Abfrage relevant sind. Wenn nicht, wird das Ergebnis beim Verfassen der Eingabeaufforderung für die LLM ignoriert.
- Erneute Rangfolge – Bewerten Sie die Artikelblöcke, die aus dem Vektorspeicher abgerufen wurden, um sicherzustellen, dass relevante Details in der Nähe der Ränder (Anfang und Ende) der Eingabeaufforderung leben.
- Eingabeaufforderungskomprimierung – Verwenden eines kleinen, kostengünstigen Modells zum Kombinieren und Zusammenfassen mehrerer Artikelblöcke in einer einzigen komprimierten Eingabeaufforderung, bevor sie an die LLM gesendet werden.
Schritte nach abschluss der Verarbeitung
Nach abschluss der Verarbeitung erfolgt nach der Abfrage des Benutzers, und alle Inhaltsblöcke wurden an die LLM gesendet, wie im folgenden Diagramm dargestellt:

Nachdem die Aufforderung vom LLM abgeschlossen wurde, ist es an der Zeit, den Abschluss zu überprüfen, um sicherzustellen, dass die Antwort korrekt ist. Eine Pipeline nach abschluss der Verarbeitung kann die folgenden Schritte umfassen:
- Fact check - This could take many forms, but the intent is to identify specific claims made in the article that are presented as facts and then to check those facts for accuracy. Wenn der Faktenüberprüfungsschritt fehlschlägt, kann es sinnvoll sein, die LLM erneut abzufragen, um eine bessere Antwort zu erhalten oder eine Fehlermeldung an den Benutzer zurückzugeben.
- Richtlinienüberprüfung – Dies ist die letzte Verteidigungslinie, um sicherzustellen, dass Antworten keine schädlichen Inhalte enthalten, unabhängig davon, ob der Benutzer oder die Organisation.
Auswertung
Die Auswertung der Ergebnisse eines nicht deterministischen Systems ist nicht so einfach wie beispielsweise Komponenten- oder Integrationstests, mit denen die meisten Entwickler vertraut sind. Es gibt mehrere Faktoren zu berücksichtigen:
- Sind die Benutzer mit den Ergebnissen zufrieden, die sie erhalten?
- Erhalten Benutzer genaue Antworten auf ihre Fragen?
- Wie erfassen wir Benutzerfeedback? Gibt es Richtlinien, die einschränken, welche Daten wir über Benutzerdaten sammeln können?
- Für die Diagnose von unbefriedigenden Antworten haben wir Einblick in die gesamte Arbeit, die in die Beantwortung der Frage ging? Behalten wir ein Protokoll der einzelnen Phasen in der Ableitungspipeline von Eingaben und Ausgaben, damit wir die Ursachenanalyse durchführen können?
- Wie können wir Änderungen am System vornehmen, ohne dass regressions- oder Beeinträchtigungen der Ergebnisse auftreten?
Erfassen und Handeln von Feedback von Benutzern
Wie bereits erwähnt, müssen Entwickler möglicherweise mit dem Datenschutzteam ihrer Organisation zusammenarbeiten, um Feedbackerfassungsmechanismen und Telemetrie, Protokollierung usw. zu entwerfen, um forensische und Ursachenanalysen für eine bestimmte Abfragesitzung zu ermöglichen.
Der nächste Schritt besteht darin, eine Bewertungspipeline zu entwickeln. Die Notwendigkeit einer Bewertungspipeline ergibt sich aus der Komplexität und zeitintensiven Natur der Analyse von feedback und den Ursachen der Antworten, die von einem KI-System bereitgestellt werden. Diese Analyse ist von entscheidender Bedeutung, da jede Antwort untersucht wird, um zu verstehen, wie die KI-Abfrage die Ergebnisse erzeugt hat, die Angemessenheit der aus der Dokumentation verwendeten Inhaltsblöcke und die Strategien, die bei der Aufteilung dieser Dokumente verwendet werden.
Darüber hinaus umfasst sie alle zusätzlichen Vor- oder Nachbearbeitungsschritte, die die Ergebnisse verbessern könnten. Diese detaillierte Untersuchung deckt häufig Inhaltslücken auf, insbesondere, wenn keine geeignete Dokumentation als Reaktion auf die Abfrage eines Benutzers vorhanden ist.
Die Erstellung einer Bewertungspipeline ist daher unerlässlich, um den Umfang dieser Aufgaben effektiv zu verwalten. Eine effiziente Pipeline würde benutzerdefinierte Tools verwenden, um Metriken auszuwerten, die die Qualität der antworten, die von der KI bereitgestellt werden. Dieses System würde den Prozess optimieren, um zu bestimmen, warum eine bestimmte Antwort auf die Frage eines Benutzers gegeben wurde, welche Dokumente verwendet wurden, um diese Antwort zu generieren, und die Effektivität der Ableitungspipeline, die die Abfragen verarbeitet.
Goldenes Dataset
Eine Strategie zur Bewertung der Ergebnisse eines nicht deterministischen Systems wie ein RAG-Chat-System besteht darin, ein "goldenes Dataset" zu implementieren. Ein goldenes Dataset ist ein kuratierter Satz von Fragen mit genehmigten Antworten, Metadaten (z. B. Thema und Fragetyp), Verweise auf Quelldokumente, die als Grundwahrkeit für Antworten dienen können, und sogar Variationen (unterschiedliche Ausdrücke, um die Vielfalt zu erfassen, wie Benutzer die gleichen Fragen stellen können).
Das "goldene Dataset" stellt das "best case scenario" dar und ermöglicht Es Entwicklern, das System auszuwerten, um zu sehen, wie gut es funktioniert, und Regressionstests durchzuführen, wenn neue Features oder Updates implementiert werden.
Bewertung von Schäden
Harms Modeling ist eine Methodik, die darauf abzielt, potenzielle Schäden zu erkennen, Mängel in einem Produkt zu erkennen, die Risiken für Einzelpersonen darstellen können, und proaktive Strategien zur Abmilderung solcher Risiken zu entwickeln.
Um die Auswirkungen der Technologie, insbesondere KI-Systeme, zu bewerten, würden mehrere Schlüsselkomponenten basierend auf den Grundsätzen der Schadensmodellierung enthalten, wie in den bereitgestellten Ressourcen beschrieben.
Zu den wichtigsten Merkmalen eines Tools zur Schadenbewertung gehören u. U.:
Identifizierung der Beteiligten: Das Tool würde Benutzern helfen, verschiedene von der Technologie betroffene Interessenträger zu identifizieren und zu kategorisieren, einschließlich direkter Benutzer, indirekt betroffener Parteien und anderer Entitäten wie zukünftige Generationen oder nicht menschliche Faktoren wie Umweltbedenken ().
Schadenskategorien und Beschreibungen: Es würde eine umfassende Liste potenzieller Schäden enthalten, z. B. Datenschutzverlust, emotionale Not oder wirtschaftliche Ausbeutung. Das Tool könnte den Benutzer durch verschiedene Szenarien leiten, die veranschaulichen, wie die Technologie diese Schäden verursachen könnte, um sowohl beabsichtigte als auch unbeabsichtigte Folgen zu bewerten.
Schweregrad- und Wahrscheinlichkeitsbewertungen: Mit dem Tool können Benutzer den Schweregrad und die Wahrscheinlichkeit der einzelnen identifizierten Schäden bewerten, sodass sie priorisieren können, welche Probleme zuerst behandelt werden sollen. Dies kann qualitative Bewertungen umfassen und von Daten unterstützt werden, sofern verfügbar.
Entschärfungsstrategien: Beim Identifizieren und Bewerten von Schäden würde das Tool potenzielle Gegenstrategien vorschlagen. Dazu können Änderungen am Systementwurf, mehr Sicherheitsmaßnahmen oder alternative technologische Lösungen gehören, die identifizierte Risiken minimieren.
Feedbackmechanismen: Das Tool sollte Mechanismen zum Sammeln von Feedback von Beteiligten enthalten, um sicherzustellen, dass der Bewertungsprozess dynamisch ist und auf neue Informationen und Perspektiven reagiert.
Dokumentation und Berichterstattung: Zur Unterstützung der Transparenz und Rechenschaftspflicht würde das Tool die Erstellung detaillierter Berichte erleichtern, die den Schadenbewertungsprozess, die Ergebnisse und Maßnahmen dokumentieren, um potenzielle Risiken zu mindern.
Diese Features würden nicht nur dazu beitragen, Risiken zu erkennen und zu mindern, sondern auch bei der Gestaltung ethischer und verantwortungsvoller KI-Systeme, indem sie ein breites Spektrum von Auswirkungen von Anfang an in Betracht ziehen.
Weitere Informationen finden Sie unter:
Testen und Überprüfen der Sicherheitsvorkehrungen
In diesem Artikel wurden mehrere Prozesse beschrieben, die darauf abzielen, die Möglichkeit zu verringern, dass das RAG-basierte Chatsystem ausgenutzt oder kompromittiert werden könnte. Red-Teaming spielt eine entscheidende Rolle bei der Sicherstellung, dass die Entschärfungen wirksam sind. Red-Teaming beinhaltet die Simulation der Aktionen eines Gegners, die auf die Anwendung abzielen, um potenzielle Schwachstellen oder Schwachstellen aufzudecken. Dieser Ansatz ist besonders wichtig bei der Bewältigung des erheblichen Risikos von Jailbreaking.
Um die Sicherheitsvorkehrungen eines RAG-basierten Chatsystems effektiv zu testen und zu überprüfen, müssen Entwickler diese Systeme unter verschiedenen Szenarien streng bewerten, in denen diese Richtlinien getestet werden könnten. Dies gewährleistet nicht nur die Robustheit, sondern hilft auch bei der Feinabstimmung der Reaktionen des Systems, die streng definierten ethischen Standards und betrieblichen Verfahren einzuhalten.
Abschließende Überlegungen, die Ihre Entscheidungen im Anwendungsentwurf beeinflussen können
Nachfolgend finden Sie eine kurze Liste der Punkte, die Sie berücksichtigen sollten, und andere Punkte aus diesem Artikel, die sich auf Ihre Entscheidungen im Anwendungsentwurf auswirken:
- Erkennen Sie die nicht deterministische Natur der generativen KI in Ihrem Entwurf an, planen Sie Die Variabilität in ausgaben und richten Sie Mechanismen ein, um Konsistenz und Relevanz in Antworten sicherzustellen.
- Bewerten Sie die Vorteile der Vorverarbeitung von Benutzeraufforderungen gegen die potenzielle Erhöhung der Latenz und Kosten. Das Vereinfachen oder Ändern von Eingabeaufforderungen vor der Übermittlung kann die Antwortqualität verbessern, aber komplexität und Zeit zum Antwortzyklus hinzufügen.
- Untersuchen Sie Strategien zum Parallelisieren von LLM-Anforderungen, um die Leistung zu verbessern. Dieser Ansatz kann die Latenz verringern, erfordert jedoch eine sorgfältige Verwaltung, um eine höhere Komplexität und potenzielle Kostenauswirkungen zu vermeiden.
Wenn Sie sofort mit dem Erstellen einer generativen KI-Lösung experimentieren möchten, empfehlen wir, einen Blick auf "Erste Schritte mit dem Chat" mit Ihrem eigenen Datenbeispiel für Python zu werfen. Es gibt versionen des Lernprogramms auch in .NET, Java und JavaScript.