Hochverfügbarkeit und Notfallwiederherstellung von IoT Hub
Als ersten Schritt zur Implementierung einer belastbaren IoT-Lösung müssen Architekten, Entwickler und Geschäftsinhaber die Betriebszeitziele für die von ihnen erstellten Lösungen definieren. Diese Ziele können in erster Linie auf Grundlage bestimmter Geschäftsziele für jedes Szenario definiert werden. In diesem Zusammenhang bietet der Artikel Geschäftskontinuität mit Azure – technische Dokumentation einen allgemeinen Überblick über Geschäftskontinuität und Notfallwiederherstellung. Das Dokument Notfallwiederherstellung und Hochverfügbarkeit für Azure-Anwendungen enthält Architekturanleitungen zu Strategien für Azure-Anwendungen in Bezug auf Notfallwiederherstellung und Hochverfügbarkeit.
Dieser Artikel beschreibt die Funktionen für Hochverfügbarkeit und Notfallwiederherstellung, die der Dienst IoT Hub bietet. In diesem Artikel werden schwerpunktmäßig die folgenden Themen beschrieben:
- Regionale Hochverfügbarkeit
- Regionenübergreifende Notfallwiederherstellung
- Erzielen regionenübergreifender Hochverfügbarkeit
Abhängig von den Betriebszeitzielen, die Sie für Ihre IoT-Lösungen definieren, sollten Sie festlegen, welche der in diesem Artikel aufgeführten Optionen am besten zu Ihren Geschäftszielen passt. Die Integration einer dieser Hochverfügbarkeits-/Notfallwiederherstellungsalternativen in Ihre IoT-Lösung erfordert eine sorgfältige Bewertung der folgenden Aspekte und ihrer Wichtigkeit:
- Erforderliche Resilienz
- Implementierungs- und Wartungsaufwand
- Wirkung des Wareneinsatzes
Regionale Hochverfügbarkeit
Der Dienst IoT Hub bietet regionale Hochverfügbarkeit, indem in fast allen Dienstschichten Redundanzen implementiert werden. Das von IoT Hub veröffentlichte SLA wird mithilfe dieser Redundanzen eingehalten. Für die Entwickler einer IoT-Lösung entsteht kein zusätzlicher Aufwand, um die Vorteile dieser Hochverfügbarkeitsfunktionen zu nutzen. Obwohl IoT Hub eine relativ hohe Betriebszeitgarantie bietet, können hier wie bei jeder verteilten Verarbeitungsplattform auch vorübergehende Fehler auftreten. Wenn Sie gerade erst mit der Migration Ihrer Lösungen von einer lokalen Lösung zur Cloud beginnen, müssen Sie sich statt der Optimierung der „durchschnittlichen Zeit zwischen Ausfällen“ auf die Optimierung der „durchschnittlichen Zeit bis zur Wiederherstellung“ konzentrieren. Mit anderen Worten, vorübergehende Fehler gelten als normal bei einem hybriden Cloudeinsatz. Entsprechende Wiederholungsmuster müssen in die Komponenten integriert werden, die mit einer Cloudanwendung interagieren, um vorübergehende Fehler zu behandeln.
Verfügbarkeitszonen
IoT Hub unterstützt Azure-Verfügbarkeitszonen. Eine Verfügbarkeitszone ist ein Hochverfügbarkeitsangebot, das Ihre Anwendungen und Daten vor Ausfällen von Rechenzentren schützt. Eine Region mit Verfügbarkeitszonenunterstützung besteht aus drei Zonen, die diese Region unterstützen. Jede Zone stellt ein oder mehrere Rechenzentren an einem eindeutigen physischen Standort mit unabhängiger Stromversorgung, Kühlung und Netzwerkbetrieb bereit. Diese Konfiguration sorgt für Replikation und Redundanz innerhalb der Region.
Verfügbarkeitszonen bieten zwei Vorteile: Datenresilienz und reibungslosere Bereitstellungen.
Datenresilienz entsteht durch das Ersetzen der zugrunde liegenden Speicherdienste durch von Verfügbarkeitszonen unterstütztem Speicher. Datenresilienz ist für IoT-Lösungen wichtig, weil diese Lösungen häufig in komplexen, dynamischen und unsicheren Umgebungen ausgeführt werden, in denen Fehler oder Unterbrechungen erhebliche Folgen haben können. Unabhängig davon, ob eine IoT-Lösung eine Fertigungshalle, Einzelhandels- oder Restaurantumgebungen, Gesundheitssysteme oder Infrastruktur unterstützt, ist die Verfügbarkeit und Qualität der Daten erforderlich, um Ausfälle zu beheben und zuverlässige und konsistente Dienste bereitzustellen.
Reibungslosere Bereitstellungen sind möglich, wenn die zugrunde liegende Hardware des Rechenzentrums durch neuere Hardware ersetzt wird, die Verfügbarkeitszonen unterstützt. Diese Hardwareverbesserungen minimieren die Kundenbeeinträchtigungen, die durch das Trennen und Wiederverbinden von Geräten sowie durch andere mit der Bereitstellung verbundene Ausfallzeiten entstehen. Sowohl aus Sicherheitsgründen als auch zur Verbesserung der Funktionen stellt das IoT Hub-Entwicklungsteams jeden Monat mehrere Updates für jeden IoT Hub bereit. Von Verfügbarkeitszonen unterstützte Hardware wird in 15 Updatedomänen unterteilt, sodass jedes Update reibungsloser verläuft und Ihre Workflows nur minimal beeinträchtigt. Weitere Informationen zu Updatedomänen finden Sie unter Verfügbarkeitsgruppen.
Die Unterstützung von Verfügbarkeitszonen für IoT Hub wird automatisch für neue IoT Hub-Ressourcen aktiviert, die in den folgenden Azure-Regionen erstellt werden:
| Region | Datenresilienz | Reibungslosere Bereitstellungen |
|---|---|---|
| Australien (Osten) | ||
| Brasilien Süd | ||
| Kanada, Mitte | ||
| Indien, Mitte | ||
| USA (Mitte) | ||
| East US | ||
| Frankreich, Mitte | ||
| Deutschland, Westen-Mitte | ||
| Japan, Osten | ||
| Korea, Mitte | ||
| Nordeuropa | ||
| Norwegen, Osten | ||
| Katar, Mitte | ||
| USA, Süden-Mitte | ||
| Asien, Südosten | ||
| UK, Süden | ||
| Europa, Westen | ||
| USA, Westen 2 | ||
| USA, Westen 3 |
Regionenübergreifende Notfallwiederherstellung
Es kann in einigen seltenen Fällen dazu kommen, dass ein Rechenzentrum aufgrund von Stromausfällen oder anderen Fehlern beim Inventar längere Zeit ausfällt. Solche Ereignisse sind selten, bei denen die zuvor beschriebene regionale Hochverfügbarkeit nicht immer hilfreich ist. IoT Hub bietet mehrere Lösungen für die Wiederherstellung nach solchen längeren Ausfallzeiten.
Die Kunden können dabei zwischen zwei Wiederherstellungsoptionen wählen: Von Microsoft initiiertes Failover und manuelles Failover. Der grundlegende Unterschied zwischen den beiden Möglichkeiten ist, dass im ersten Fall Microsoft der Initiator ist und im zweiten der Benutzer. Das manuelle Failover bietet außerdem eine schnellere RTO (Recovery Time Objective) als das von Microsoft initiierte Failover. Die spezifischen RTO der jeweiligen Option werden in den folgenden Abschnitten erläutert. Wenn eine dieser Optionen zum Ausführen eines Failovers einer IoT Hub-Instanz aus der primären Region ausgeübt wird, wird der Hub in der entsprechenden geografisch gekoppelten Azure-Region voll funktionsfähig.
Beide Failoveroptionen bieten die folgende Recovery Point Objectiv (RPO):
| Datentyp | Recovery Point Objective (RPO) |
|---|---|
| Identitätsregistrierung | 0-5 Minuten Datenverlust |
| Daten des Gerätezwillings | 0-5 Minuten Datenverlust |
| C2D-Nachrichten (Cloud-to-Device)1 | 0-5 Minuten Datenverlust |
| Übergeordnete1 und Geräteaufträge | 0-5 Minuten Datenverlust |
| D2C-Nachrichten | Alle ungelesenen Nachrichten gehen verloren |
| Cloud-zu-Gerät-Feedbacknachrichten | Alle ungelesenen Nachrichten gehen verloren |
1 Cloud-zu-Gerät-Nachrichten und übergeordnete Aufträge werden im Rahmen des manuellen Failovers nicht wiederhergestellt.
Sobald der Failovervorgang für die IoT Hub-Instanz abgeschlossen ist, wird erwartet, dass alle Vorgänge des Geräts und der Back-End-Anwendungen ohne manuellen Eingriff fortgesetzt werden. Dies bedeutet, dass Ihre Gerät-zu-Cloud-Nachrichten weiterhin funktionieren sollten und die gesamte Geräteregistrierung intakt ist. Ereignisse, die über Event Grid ausgegeben werden, können über dieselben zuvor konfigurierten Abonnements genutzt werden, solange diese Event Grid-Abonnements weiterhin verfügbar sind. Bei benutzerdefinierten Endpunkten ist keine zusätzliche Behandlung erforderlich.
Achtung
- Der Event Hubs-kompatible Name und Endpunkt des in IoT Hub integrierten Ereignisendpunkts ändern sich nach dem Failover. Wenn Sie Telemetrienachrichten vom integrierten Endpunkt über den Event Hubs-Client oder den Ereignisprozessorhost empfangen, sollten Sie die IoT Hub-Verbindungszeichenfolge verwenden, um die Verbindung herzustellen. So wird sichergestellt, dass Ihre Back-End-Anwendungen weiterhin ausgeführt werden, ohne dass ein manueller Eingriff nach dem Failover erforderlich ist. Wenn Sie den mit Event Hub kompatiblen Namen und Endpunkt in Ihrer Anwendung direkt verwenden, müssen Sie zum Fortfahren den neuen mit Event Hub kompatiblen Endpunkt nach dem Failover abrufen. Weitere Informationen finden Sie unter Manuelles Failover und Event Hub.
- Wenn Sie für die Verbindung des integrierten Events-Endpunkts Azure Functions oder Azure Stream Analytics verwenden, müssen Sie möglicherweise einen Neustart durchführen. Der Grund: Während eines Failovers sind frühere Offsets nicht mehr gültig.
- Beim Routing zum Speicher sollten die Blobs oder Dateien aufgelistet und anschließend durchlaufen werden, um sicherzustellen, dass alle Blobs oder Dateien gelesen werden, ohne dass eine Partition vorhanden ist. Der Partitionsbereich könnte sich möglicherweise bei einem von Microsoft initiierten Failover oder einem manuellen Failover ändern. Sie können die Liste der Blobs oder die Liste der ADLS Gen2-APIs mithilfe der Liste der Blobs-APIs aufzählen, um die gewünschte Liste von Dateien zu erhalten. Weitere Informationen finden Sie unter Azure Storage als Routingendpunkt.
Von Microsoft initiiertes Failover
Das von Microsoft initiierte Failover wendet Microsoft in seltenen Fällen an, um ein Failover für alle IoT-Hubs einer betroffenen Region in die entsprechende geografisch gekoppelte Region auszuführen. Dieser Prozess ist eine Standardoption, für die kein Eingriff durch Benutzer*innen erforderlich ist. Microsoft behält sich das Recht vor, zu bestimmen, wann diese Option angewendet wird. Dieser Mechanismus bedarf nicht der Zustimmung des Benutzers, bevor ein Failover für den Benutzerhub ausgeführt wird. Das von Microsoft initiierte Failover weist eine RTO von 2 bis 26 Stunden auf.
Die große RTO-Zeitspanne ist dadurch bedingt, dass Microsoft das Failover für alle betroffenen Kunden in der entsprechenden Region ausführt. Wenn Sie eine weniger wichtige IoT-Lösung ausführen, die eine Downtime von etwa einem Tag toleriert, ist es für Sie in Ordnung, eine Abhängigkeit von dieser Option einzugehen, um die allgemeinen Notfallwiederherstellungsziele für Ihre IoT-Lösung zu erfüllen. Die Gesamtzeit, nach der Laufzeitvorgänge nach Auslösung dieses Prozesses wieder vollständig funktionsfähig sind, wird im Abschnitt „Zeit bis zur Wiederherstellung“ beschrieben.
Nur Benutzer, die IoT-Hubs in den Regionen „Brasilien, Süden“ und „Asien, Südosten (Singapur)“ bereitstellen, können dieses Feature deaktivieren. Weitere Informationen finden Sie unter Deaktivieren der Notfallwiederherstellung.
Hinweis
Azure IoT Hub speichert Kundendaten nicht außerhalb der Geografie, in der Sie die Dienstinstanz bereitstellen. Weitere Informationen finden Sie unter Regionsübergreifende Replikation in Azure.
Manuelles Failover
Wenn Ihre geschäftlichen Betriebszeitziele durch das von Microsoft initiierte Failover nicht erfüllt werden, können Sie das manuelle Failover nutzen, um den Failoverprozess selbst auszulösen. Die RTO beträgt für diese Option 10 Minuten bis ein paar Stunden. Die RTO ist derzeit eine Funktion der Geräte, die für die IoT Hub-Instanz registriert sind und für die ein Failover ausgeführt wird. Für einen Hub, der etwa 100.000 Geräte hostet, beträgt die RTO ca. 15 Minuten. Die Gesamtzeit, nach der Laufzeitvorgänge nach Auslösung dieses Prozesses wieder vollständig funktionsfähig sind, wird im Abschnitt „Zeit bis zur Wiederherstellung“ beschrieben.
Die manuelle Failoveroption ist immer verfügbar, unabhängig davon, ob in der primären Region Downtime auftritt. Daher lässt sich diese Option für ein geplantes Failover nutzen. Ein Beispiel für die Verwendung geplanter Failover ist die Durchführung regelmäßiger Failoverdrills. Beachten Sie jedoch, dass ein geplantes Failover zu einer Hubdowntime für die von der RTO für diese Option definierte Zeitdauer und zu Datenverlust führt, wie in der obigen RPO-Tabelle definiert. Sie könnten eine IoT Hub-Testinstanz einrichten, um die geplante Failoveroption regelmäßig auszuführen, damit Sie sich darauf verlassen können, dass Ihre End-to-End-Lösungen bei einem echten Notfall einsatzbereit sind.
Das manuelle Failover steht ohne zusätzliche Kosten für IoT-Hubs zur Verfügung, die nach dem 18. Mai 2017 erstellt wurden.
Eine Schritt-für-Schritt-Anleitung finden Sie unter Tutorial: Ausführen eines manuellen Failovers für eine IoT Hub-Instanz
Manuelles Failover und Event Hubs
Der Event Hubs-kompatible Name und Endpunkt des in IoT Hub integrierten Ereignisendpunkts ändern sich nach dem manuellen Failover. Dies liegt daran, dass der Event Hubs-Client nicht über IoT Hub-Ereignisse informiert wird. Dasselbe gilt für andere cloudbasierte Clients wie Functions und Azure Stream Analytics. Um den Endpunkt und den Namen abzurufen, können Sie das Azure-Portal oder das .NET SDK verwenden.
Verwenden des Portals
Weitere Informationen zur Verwendung des Portals zum Abrufen des Event Hub-kompatiblen Endpunkts und des Event Hub-kompatiblen Namens finden Sie unter Verbinden mit dem integrierten Endpunkt.
Verwenden des .NET SDK
Um die IoT Hub-Verbindungszeichenfolge zum erneuten Erfassen des Event Hubs-kompatiblen Endpunkts zu verwenden, nutzen Sie ein Beispiel unter https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubs. Im Codebeispiel wird die Verbindungszeichenfolge verwendet, um den neuen Event Hubs-Endpunkt abzurufen und die Verbindung wiederherzustellen. Visual Studio muss installiert sein.
Ausführen von Testdrills
Testdrills sollten nicht in IoT-Hubs ausgeführt werden, die in Ihrer Produktionsumgebung verwendet werden.
Verwenden Sie kein manuelles Failover, um IoT Hub zu einer anderen Region zu migrieren.
Das manuelle Failover sollte nicht als Mechanismus verwendet werden, um Ihren Hub dauerhaft zwischen den geografisch gekoppelten Azure-Regionen zu migrieren. Unter der Annahme, dass sich die Geräte in der Nähe der primären Region des Hubs befinden, erhöht sich die Latenz für Vorgänge, die für den IoT-Hub ausgeführt werden, wenn ein Failover des Hubs auf eine sekundäre Region erfolgt.
Failback
Sie können ein Failback zur alten primären Region ausführen, indem Sie die Failoveraktion ein zweites Mal auslösen. Wenn das ursprüngliche Failover für eine Wiederherstellung nach einem längeren Ausfall in der ursprünglichen primären Region ausgeführt wurde, wird empfohlen, dass für den Hub ein Failback auf den ursprünglichen Standort ausgeführt wird, sobald dieser sich vom Ausfall erholt hat.
Wichtig
- Benutzer dürfen nur zwei erfolgreiche Failover und Failbacks pro Tag ausführen.
- Direkt aufeinanderfolgende Failover-/Failbackvorgänge sind nicht zulässig. Zwischen diesen Vorgängen muss eine Stunde gewartet werden.
Zeit bis zur Wiederherstellung
Während der FQDN (und damit die Verbindungszeichenfolge) der IoT Hub-Instanz nach dem Failover identisch bleibt, ändert sich die zugrunde liegende IP-Adresse. Die Zeit, nach der Laufzeitvorgänge für Ihre IoT Hub-Instanz nach dem Failover vollständig funktionsfähig sind, kann mit der folgenden Funktion ausgedrückt werden:
Zeit bis zur Wiederherstellung = RTO [10 Minuten–2 Stunden für manuelles Failover | 2–26 Stunden für von Microsoft initiiertes Failover] + Verzögerung bei DNS-Verteilung + von Clientanwendung benötigte Zeit zur Aktualisierung zwischengespeicherter IoT Hub-IP-Adressen.
Wichtig
Die IoT-SDKs speichern nicht die IP-Adresse der IoT Hub-Instanz. Es wird empfohlen, die IP-Adresse der IoT Hub-Instanz nicht mit Benutzercodes mit einer SDK-Schnittstelle zwischenzuspeichern.
Deaktivieren der Notfallwiederherstellung
IoT Hub bietet von Microsoft initiiertes Failover und manuelles Failover durch Replizieren von Daten in die gekoppelte Region für jeden IoT-Hub. Für einige Regionen können Sie die Datenreplikation außerhalb der Region verhindern, indem Sie die Notfallwiederherstellung beim Erstellen eines IoT-Hubs deaktivieren. Die folgenden Regionen unterstützen diese Funktion:
- Brasilien, Süden; gekoppelte Region, „USA, Süden-Mitte“.
- Asien, Südosten (Singapur); gekoppelte Region, „Asien, Osten“ (Hongkong SAR).
Um die Notfallwiederherstellung in unterstützten Regionen zu deaktivieren, stellen Sie sicher, dass die Option Notfallwiederherstellung aktiviert deaktiviert ist, wenn Sie Ihren IoT-Hub erstellen:
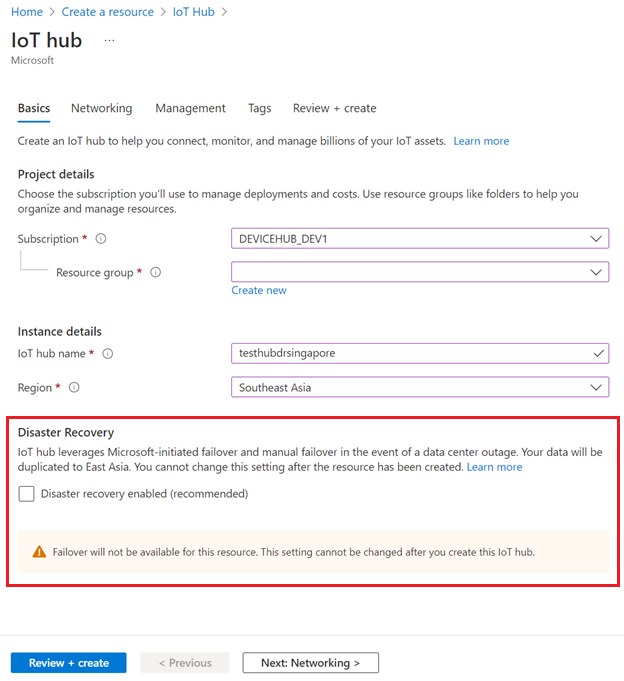
Sie können die Notfallwiederherstellung auch deaktivieren, wenn Sie einen IoT-Hub mithilfe einer ARM-Vorlage erstellen.
Die Failoverfunktion ist nicht verfügbar, wenn Sie die Notfallwiederherstellung für einen IoT-Hub deaktivieren.
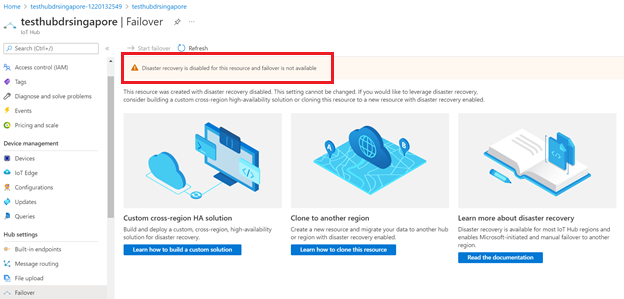
Sie können die Notfallwiederherstellung nur deaktivieren, um die Datenreplikation außerhalb der gekoppelten Region in „Brasilien, Süden“ oder „Asien, Südosten“ zu verhindern, während Sie einen IoT-Hub erstellen. Wenn Sie einen vorhandenen IoT-Hub so konfigurieren möchten, dass die Notfallwiederherstellung deaktiviert wird, müssen Sie einen neuen IoT-Hub mit deaktivierter Notfallwiederherstellung erstellen und Ihren vorhandenen IoT-Hub manuell migrieren. Anleitungen finden Sie unter Migrieren eines IoT Hubs.
Erzielen regionenübergreifender Hochverfügbarkeit
Wenn das von Microsoft initiierte Failover oder das manuelle Failover Ihre geschäftlichen Betriebszeitziele nicht erfüllt, sollten Sie einen automatischen und regionsübergreifenden Failovermechanismus pro Gerät implementieren. Eine ausführliche Erläuterung von Bereitstellungstopologien in IoT-Lösungen würde den Rahmen dieses Artikels sprengen. In diesem Artikel wird das Bereitstellungsmodell für das regionale Failover für Hochverfügbarkeit und Notfallwiederherstellung behandelt.
In einem regionalen Failovermodell wird das Lösungs-Back-End in erster Linie an einem Rechenzentrumsstandort ausgeführt. Eine sekundäre IoT Hub-Einheit und ein Back-End werden an einem anderen Rechenzentrumsstandort bereitgestellt. Wenn die IoT Hub-Instanz in der primären Region ausfällt oder die Netzwerkverbindung des Geräts mit der primären Region unterbrochen wird, verwenden Geräte einen sekundären Dienstendpunkt. Sie können die Verfügbarkeit der Lösung durch die Implementierung eines regionsübergreifenden Failovermodells verbessern, statt innerhalb einer Region zu bleiben.
Beachten Sie die folgenden Punkte, wenn Sie ein Modell für regionales Failover mit IoT Hub implementieren möchten:
Eine sekundäre Routinglogik für IoT Hub und Geräte: Bei einer Dienstunterbrechung in der primären Region müssen Geräte eine Verbindung mit der sekundären Region herstellen. Da die meisten beteiligten Dienste zustandsorientiert sind, wird der Failoverprozess zwischen Regionen häufig von Lösungsadministratoren ausgelöst. Die beste Möglichkeit, Geräte über den neuen Endpunkt zu informieren und gleichzeitig die Kontrolle über den Prozess zu behalten, besteht darin, für die Geräte eine regelmäßige Prüfung eines Concierge-Diensts auf den derzeit aktiven Endpunkt durchführen zu lassen. Der Concierge-Dienst kann eine Webanwendung sein, die repliziert und deren Erreichbarkeit mithilfe von DNS-Umleitungsverfahren (z.B. per Azure Traffic Manager) gewährleistet wird.
Hinweis
Der IoT Hub-Dienst ist kein unterstützter Endpunkttyp in Azure Traffic Manager. Es wird empfohlen, den vorgeschlagenen Concierge-Dienst mit Azure Traffic Manager zu integrieren, indem Sie die Endpunktintegritätstest-API implementieren.
Replikation der Identitätsregistrierung: Um verwendet werden zu können, muss die sekundäre IoT Hub-Einheit alle Geräteidentitäten enthalten, die eine Verbindung mit der Lösung herstellen können. Für die Lösung sollten georeplizierte Backups von Geräteidentitäten vorgehalten und auf die sekundäre IoT Hub-Einheit hochgeladen werden, bevor der aktive Endpunkt für die Geräte gewechselt wird. Die Funktionen zum Exportieren der Geräteidentität von IoT Hub sind in diesem Zusammenhang praktisch. Weitere Informationen finden Sie unter IoT Hub-Entwicklerhandbuch – Identitätsregistrierung.
Zusammenführungslogik: Wenn die primäre Region wieder verfügbar ist, müssen die Status und Daten, die am sekundären Standort erstellt wurden, zurück zur primären Region migriert werden. Dieser Status und die Daten beziehen sich hauptsächlich auf Geräteidentitäten und Anwendungsmetadaten, die mit der primären IoT Hub-Einheit und etwaigen anderen anwendungsspezifischen Datenspeichern in der primären Region zusammengeführt werden müssen.
Zur Vereinfachung dieses Schritts empfiehlt sich die Verwendung idempotenter Vorgänge. Idempotente Vorgänge verringern die Nebeneffekte für die letztendliche konsistente Verteilung von Ereignissen sowie für Duplikate oder die außerordentliche Bereitstellung von Ereignissen. Außerdem sollte die Anwendungslogik so entworfen werden, dass potenzielle Inkonsistenzen oder ein „geringfügig“ veralteter Zustand toleriert werden. Dieser Fall kann aufgrund der zusätzlichen Zeit eintreten, die das System für die Wiederherstellung basierend auf der RPO benötigt.
Auswählen der geeigneten Option für Hochverfügbarkeit/Notfallwiederherstellung
Diese Zusammenfassung der in diesem Artikel vorgestellten Optionen für Hochverfügbarkeit und Notfallwiederherstellung dient als Referenz für die Auswahl der für Ihre Lösung geeigneten Option.
| Option für Hochverfügbarkeit/Notfallwiederherstellung | RTO | RPO | Manueller Eingriff | Implementierungskomplexität | Kostenauswirkung |
|---|---|---|---|---|---|
| Von Microsoft initiiertes Failover | 2–26 Stunden | Weitere Informationen finden Sie in der obigen RPO-Tabelle. | Nein | Keine | Keine |
| Manuelles Failover | 10 Minuten–2 Stunden | Weitere Informationen finden Sie in der obigen RPO-Tabelle. | Ja | Sehr gering. Sie müssen diesen Vorgang lediglich über das Portal auslösen. | Keine |
| Regionenübergreifende Hochverfügbarkeit | < 1 Min. | Abhängig von der Replikationsrate Ihrer benutzerdefinierten Hochverfügbarkeitslösung | Nein | High | > 1-malig anfallende Kosten für 1 IoT Hub-Instanz |