Ausführen von Azure Machine Learning-Modellen in Fabric mithilfe von Batchendpunkten (Vorschau)
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie Azure Machine Learning-Batchbereitstellungen über Microsoft Fabric nutzen. Obwohl der Workflow Modelle verwendet, die für Batchendpunkte bereitgestellt werden, unterstützt er auch die Verwendung von Batchpipelinebereitstellungen über Fabric.
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Voraussetzungen
- Erwerben Sie ein Microsoft Fabric-Abonnement. Registrieren Sie sich alternativ für eine kostenlose Microsoft Fabric-Testversion.
- Melden Sie sich bei Microsoft Fabric an.
- Ein Azure-Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
- Ein Azure Machine Learning-Arbeitsbereich. Wenn Sie keinen Arbeitsbereich haben, führen Sie die Schritte unter Verwalten von Arbeitsbereichen aus, um einen Arbeitsbereich zu erstellen.
- Stellen Sie sicher, dass Sie im Arbeitsbereich über die folgenden Berechtigungen verfügen:
- Erstellen/Verwalten von Batchendpunkten und Batchbereitstellungen: Verwenden Sie die Rolle für Besitzer oder Mitwirkende oder eine benutzerdefinierte Rolle, die
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*zulässt. - Erstellen von ARM-Bereitstellungen in der Arbeitsbereichsressourcengruppe: Verwenden Sie die Rolle für Besitzer oder Mitwirkende oder eine benutzerdefinierte Rolle, die
Microsoft.Resources/deployments/writein der Ressourcengruppe zulässt, in der der Arbeitsbereich bereitgestellt wird.
- Erstellen/Verwalten von Batchendpunkten und Batchbereitstellungen: Verwenden Sie die Rolle für Besitzer oder Mitwirkende oder eine benutzerdefinierte Rolle, die
- Stellen Sie sicher, dass Sie im Arbeitsbereich über die folgenden Berechtigungen verfügen:
- Ein auf einem Batchendpunkt bereitgestelltes Modell. Wenn Sie kein Modell haben, führen Sie die Schritte unter Bereitstellen von Modellen für die Bewertung in Batchendpunkten aus, um ein Modell zu erstellen.
- Laden Sie das Beispieldataset heart-unlabeled.csv herunter, um es für die Bewertung zu verwenden.
Aufbau
Azure Machine Learning kann nicht direkt auf Daten zugreifen, die in OneLake von Fabric gespeichert sind. Sie können jedoch die OneLake-Funktion verwenden, um Verknüpfungen in einem Lakehouse zum Lesen und Schreiben von Daten zu erstellen, die in Azure Data Lake Gen2 gespeichert sind. Da Azure Machine Learning Azure Data Lake Gen2-Speicher unterstützt, können Sie mit diesem Setup Fabric und Azure Machine Learning zusammen verwenden. Die Datenarchitektur ist wie folgt:

Datenzugriff konfigurieren
Damit Fabric und Azure Machine Learning dieselben Daten lesen und schreiben können, ohne sie kopieren zu müssen, können Sie OneLake-Verknüpfungen und Azure Machine Learning-Datenspeichernutzen. Indem Sie eine OneLake-Verknüpfung und einen Datenspeicher auf dasselbe Speicherkonto verweisen, können Sie sicherstellen, dass sowohl Fabric als auch Azure Machine Learning dieselben zugrunde liegenden Daten für Lese- und Schreibvorgänge verwenden.
In diesem Abschnitt erstellen oder ermitteln Sie ein Speicherkonto zum Speichern der Informationen, die vom Batchendpunkt genutzt und Fabric-Benutzer*innen in OneLake angezeigt werden. Fabric unterstützt nur Speicherkonten mit aktivierten hierarchischen Namen, z. B. Azure Data Lake Gen2.
Erstellen einer OneLake-Verknüpfung zum Speicherkonto
Öffnen Sie in Fabric die Oberfläche für Synapse-Datentechnik.
Wählen Sie im linken Bereich Ihren Fabric-Arbeitsbereich aus, um ihn zu öffnen.
Öffnen Sie das Lakehouse, das Sie zum Konfigurieren der Verbindung verwenden. Wenn Sie noch kein Lakehouse haben, gehen Sie zur Oberfläche für Datentechnik, um ein Lakehouse zu erstellen. In diesem Beispiel verwenden Sie ein Lakehouse mit dem Namen trusted.
Öffnen Sie in der linken Navigationsleiste Weitere Optionen für Dateien, und wählen Sie dann Neue Verknüpfung aus, um den Assistenten aufzurufen.
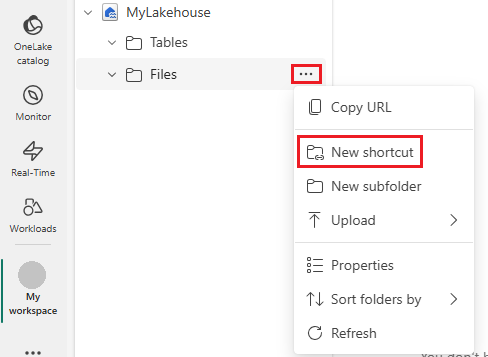
Wählen Sie die Option Azure Data Lake Storage Gen2 aus.

Fügen Sie im Abschnitt Verbindungseinstellungen die URL ein, die dem Azure Data Lake Gen2-Speicherkonto zugeordnet ist.
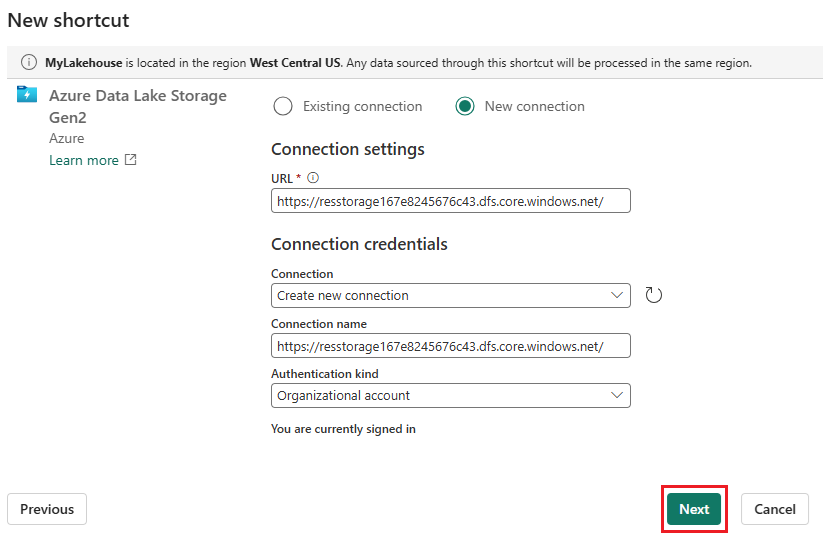
Gehen Sie im Abschnitt Anmeldeinformationen für die Verbindung wie folgt vor:
- Wählen Sie unter Verbindung die Option Neue Verbindung herstellen aus.
- Übernehmen Sie unter Verbindungsname den aufgefüllten Standardwert.
- Wählen Sie für Authentifizierungsart die Option Unternehmenskonto aus, um die Anmeldeinformationen des verbundenen Benutzers oder der verbundenen Benutzerin über OAuth 2.0 zu verwenden.
- Wählen Sie Anmelden aus, um sich anzumelden.
Wählen Sie Weiter aus.
Konfigurieren Sie bei Bedarf den Pfad zur Verknüpfung relativ zum Speicherkonto. Verwenden Sie diese Einstellung, um den Ordner zu konfigurieren, auf den die Verknüpfung verweist.
Konfigurieren Sie den Namen der Verknüpfung. Dieser Name ist ein Pfad innerhalb des Lakehouse. Nennen Sie in diesem Beispiel die Verknüpfung datasets.
Speichern Sie die Änderungen.



Erstellen eines Datenspeichers, der auf das Speicherkonto verweist
Öffnen Sie Azure Machine Learning Studio.
Navigieren Sie zu Ihrem Azure Machine Learning-Arbeitsbereich.
Navigieren Sie zum Abschnitt Daten.
Wählen Sie die Registerkarte Datenspeicher aus.
Wählen Sie Erstellen aus.
Konfigurieren Sie den Datenspeicher wie folgt:
Geben Sie unter Datenspeichername den Namen trusted_blob ein.
Wählen Sie unter Datenspeichertyp die Option Azure Blob Storage aus.
Tipp
Warum sollten Sie Azure Blob Storage anstelle von Azure Data Lake Gen2 konfigurieren? Batchendpunkte können nur Vorhersagen in Blob Storage-Konten schreiben. Jedes Azure Data Lake Gen2-Speicherkonto ist jedoch auch ein Blob Storage-Konto. Daher sind sie austauschbar.
Wählen Sie das Speicherkonto über den Assistenten unter Verwendung der Abonnement-ID, des Speicherkontos und des Blob-Container- (Dateisystem) aus.

Klicken Sie auf Erstellen.
Stellen Sie sicher, dass die Compute-Instanz, auf der der Batchendpunkt ausgeführt wird, über Berechtigungen zum Einbinden der Daten in dieses Speicherkonto verfügt. Der Zugriff wird weiterhin von der Identität gewährt, die den Endpunkt aufruft. Die Compute-Instanz, in der der Batchendpunkt ausgeführt wird, muss aber dennoch über die Berechtigung zum Einbinden des von Ihnen bereitgestellten Speicherkontos verfügen. Weitere Informationen finden Sie unter Zugreifen auf Speicherdienste.
Hochladen des Beispieldatasets
Laden Sie einige Beispieldaten für den Endpunkt hoch, um sie als Eingabe zu verwenden:
Navigieren Sie zu Ihrem Fabric-Arbeitsbereich.
Wählen Sie das Lakehouse aus, in dem Sie die Verknüpfung erstellt haben.
Rufen Sie die Verknüpfung datasets auf.
Erstellen Sie einen Ordner zum Speichern des Beispieldatasets, das Sie bewerten möchten. Geben Sie dem Ordner den Namen uci-heart-unlabeled.
Verwenden Sie die Option Daten abrufen, und wählen Sie Dateien hochladen uas, um das Beispieldataset heart-unlabeled.csv hochzuladen.
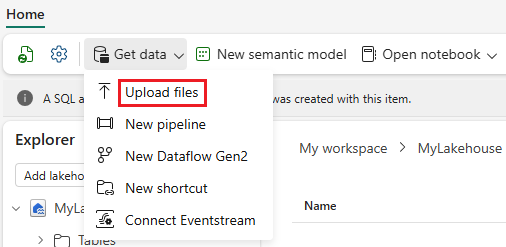
Laden Sie das Beispieldataset hoch.

Die Beispieldatei kann nun genutzt werden. Notieren Sie sich den Pfad zu dem entsprechenden Speicherort.


Erstellen einer Fabric-zu-Batch-Rückschlusspipeline
In diesem Abschnitt erstellen Sie eine Fabric-zu-Batch-Rückschlusspipeline in Ihrem vorhandenen Fabric-Arbeitsbereich und rufen Batchendpunkte auf.
Kehren Sie zur Oberfläche Datentechnik zurück (wenn Sie bereits von ihr weg navigiert sind). Wählen Sie dazu das Symbol für die Oberflächenauswahl in der unteren linken Ecke der Homepage aus.
Öffnen Sie Ihren Fabric-Arbeitsbereich.
Wählen Sie im Abschnitt Neu der Homepage die Option Datenpipeline aus.
Geben Sie einen Namen für die Pipeline ein, und wählen Sie Erstellen aus.

Wählen Sie auf der Symbolleiste der Designer-Canvas die Registerkarte Aktivitäten aus.
Wählen Sie am Ende der Registerkarte weitere Optionen und dann Azure Machine Learning aus.
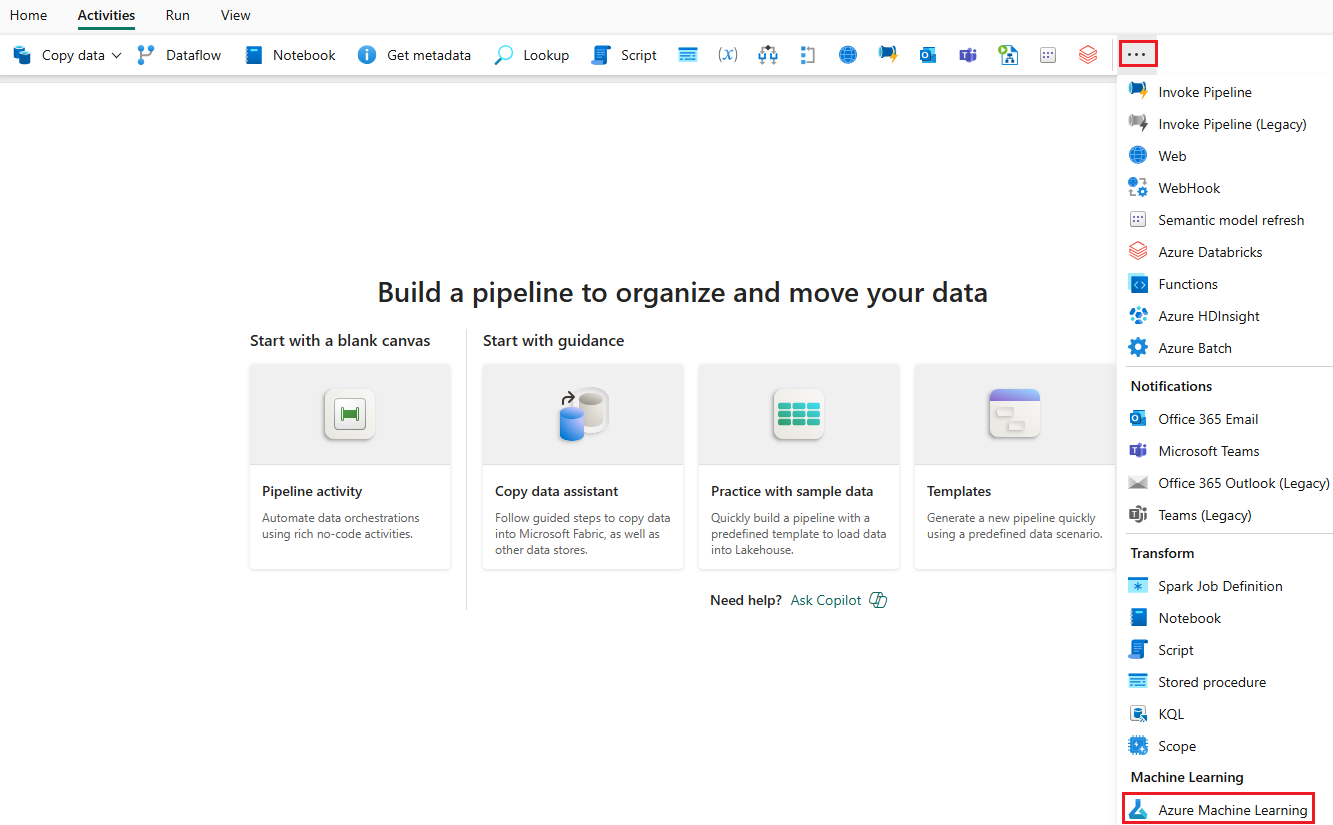
Wechseln Sie zur Registerkarte Einstellungen, und konfigurieren Sie die Aktivität wie folgt:
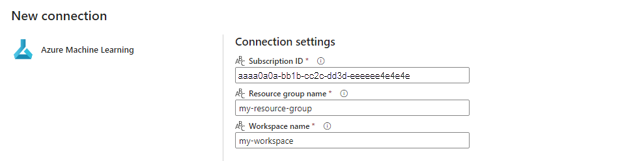
Wählen Sie neben Azure Machine Learning-Verbindung die Option Neu aus, um eine neue Verbindung mit dem Azure Machine Learning-Arbeitsbereich zu erstellen, der Ihre Bereitstellung enthält.
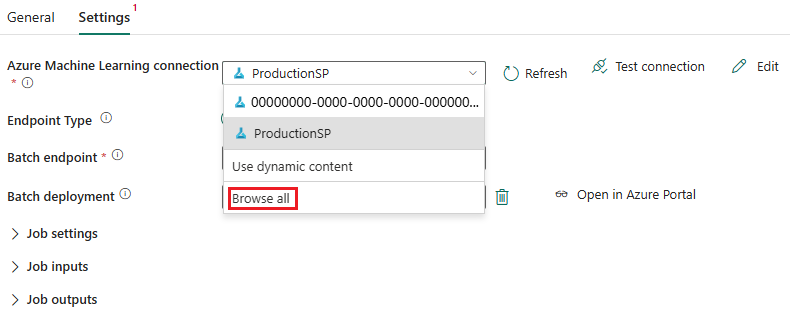
Geben Sie im Abschnitt Verbindungseinstellungen des Erstellungs-Assistenten die Werte für Abonnement-ID, Ressourcengruppenname und Arbeitsbereichsname für Ihre Endpunktbereitstellung an.
Wählen Sie im Abschnitt Anmeldeinformationen für die Verbindung die Option Unternehmenskonto als Wert für die Authentifizierungsart für Ihre Verbindung aus. Das Unternehmenskonto verwendet die Anmeldeinformationen des verbundenen Benutzers oder der verbundenen Benutzerin. Alternativ können Sie einen Dienstprinzipal verwenden: In Produktionseinstellungen wird die Verwendung eines Dienstprinzipals empfohlen. Stellen Sie unabhängig vom Authentifizierungstyp sicher, dass die mit der Verbindung verknüpfte Identität über die Rechte zum Aufrufen des von Ihnen bereitgestellten Batchendpunkts verfügt.
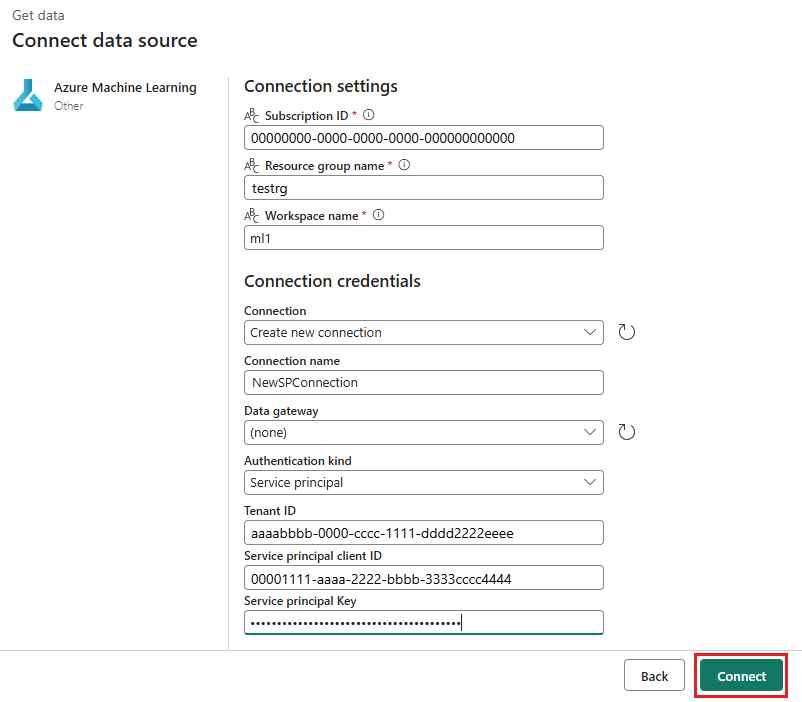
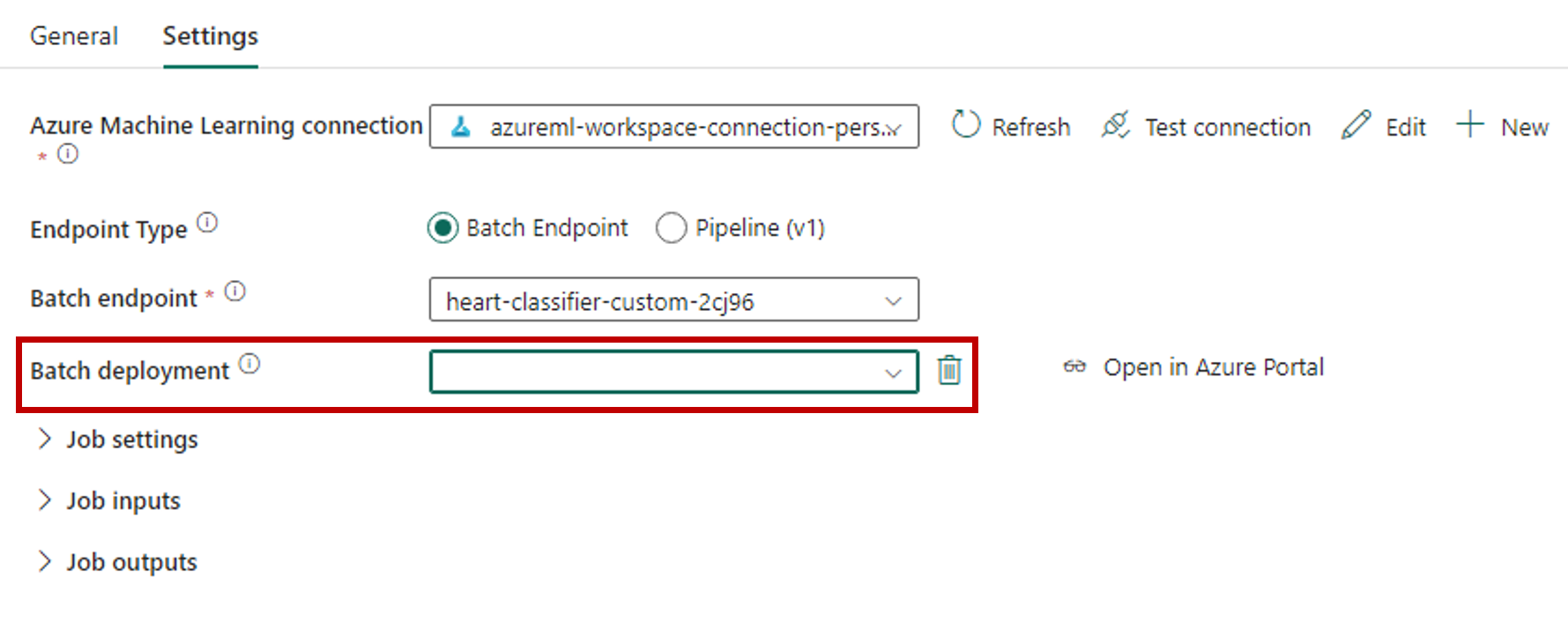
Klicken Sie auf Speichern, um die Verbindung zu speichern. Sobald die Verbindung ausgewählt wird, füllt Fabric automatisch die verfügbaren Batchendpunkte im ausgewählten Arbeitsbereich auf.
Wählen Sie unter Batchendpunkt den Batchendpunkt aus, den Sie aufrufen möchten. Wählen Sie in diesem Beispiel heart-classifier-... aus.
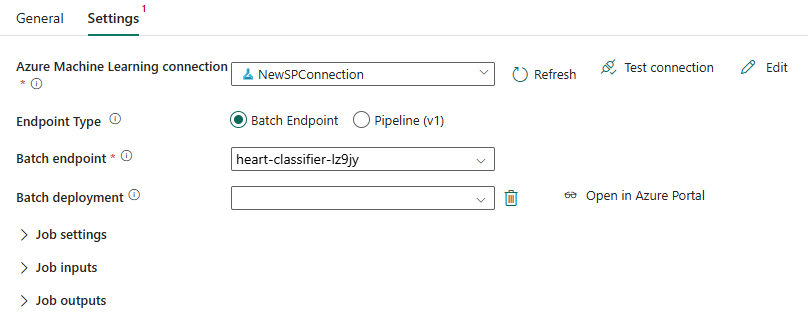
Der Abschnitt Batchbereitstellung wird automatisch mit den verfügbaren Bereitstellungen unter dem Endpunkt aufgefüllt.
Wählen Sie für Batchbereitstellung bei Bedarf eine bestimmte Bereitstellung aus der Liste aus. Wenn Sie keine Bereitstellung auswählen, ruft Fabric die Standardbereitstellung unter dem Endpunkt auf, sodass der Ersteller oder die Erstellerin des Batchendpunkts entscheiden kann, welche Bereitstellung aufgerufen wird. In den meisten Szenarien sollten Sie dieses Standardverhalten beibehalten.







Konfigurieren von Ein- und Ausgaben für den Batchendpunkt
In diesem Abschnitt konfigurieren Sie Ein- und Ausgaben für den Batchendpunkt. Eingaben für Batchendpunkte liefern Daten und Parameter, die zum Ausführen des Prozesses erforderlich sind. Die Azure Machine Learning-Batchpipeline in Fabric unterstützt sowohl Modellbereitstellungen als auch Pipelinebereitstellungen. Die Anzahl und Art der von Ihnen bereitgestellten Eingaben hängen vom Bereitstellungstyp ab. In diesem Beispiel verwenden Sie eine Modellbereitstellung, die genau eine Eingabe erfordert und eine Ausgabe generiert.
Weitere Informationen zu Ein- und Ausgaben für Batchendpunkte finden Sie unter Grundlegendes zu Eingaben und Ausgaben in Batchendpunkten.
Konfigurieren des Eingabeabschnitts
Konfigurieren Sie den Abschnitt Auftragseingaben wie folgt:
Erweitern Sie den Abschnitt Auftragseingaben.
Wählen Sie Neu aus, um Ihrem Endpunkt eine neue Eingabe hinzuzufügen.
Nennen Sie die Eingabe
input_data. Da Sie eine Modellbereitstellung verwenden, können Sie einen beliebigen Namen verwenden. Bei Pipelinebereitstellungen müssen Sie jedoch den genauen Namen der Eingabe angeben, die Ihr Modell erwartet.Wählen Sie das Dropdownmenü neben der Eingabe aus, die Sie soeben hinzugefügt haben, um die Eigenschaft der Eingabe (Felder für Name und Wert) zu öffnen.
Geben Sie
JobInputTypein das Feld Name ein, um den Typ der Eingabe anzugeben, die Sie erstellen.Geben Sie
UriFolderin das Feld Wert ein, um anzugeben, dass die Eingabe ein Ordnerpfad ist. Andere unterstützte Werte für dieses Feld sind UriFile (ein Dateipfad) oder Literal (beliebiger Literalwert wie eine Zeichenfolge oder eine ganze Zahl). Sie müssen den richtigen Typ verwenden, den Ihre Bereitstellung erwartet.Wählen Sie das Pluszeichen neben der Eigenschaft aus, um eine weitere Eigenschaft für diese Eingabe hinzuzufügen.
Geben Sie
Uriin das Feld Name ein, um den Pfad zu den Daten anzugeben.Geben Sie
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled(Pfad zu den Daten) in das Feld Wert ein. Hier verwenden Sie einen Pfad, der zu dem Speicherkonto führt, das sowohl mit OneLake in Fabric als auch mit Azure Machine Learning verknüpft ist. azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled ist der Pfad zu CSV-Dateien mit den erwarteten Eingabedaten für das Modell, das für den Batchendpunkt bereitgestellt wird. Sie können auch einen direkten Pfad zum Speicherkonto verwenden, z. B.https://<storage-account>.dfs.azure.com.
Tipp
Wenn die Eingabe vom Typ Literal ist, ersetzen Sie die Eigenschaft
Uridurch „Value“.
Wenn für Ihren Endpunkt mehr Eingaben erforderlich sind, wiederholen Sie die vorherigen Schritte für die einzelnen Eingaben. In diesem Beispiel erfordern Modellbereitstellungen genau eine Eingabe.
Konfigurieren des Ausgabeabschnitts
Konfigurieren Sie den Abschnitt Auftragsausgaben wie folgt:
Erweitern Sie den Abschnitt Auftragsausgaben.
Wählen Sie Neu aus, um Ihrem Endpunkt eine neue Ausgabe hinzuzufügen.
Benennen Sie die Ausgabe
output_data. Da Sie eine Modellbereitstellung verwenden, können Sie einen beliebigen Namen verwenden. Bei Pipelinebereitstellungen müssen Sie jedoch den genauen Namen der Ausgabe angeben, die Ihr Modell generiert.Wählen Sie das Dropdownmenü neben der Ausgabe aus, die Sie soeben hinzugefügt haben, um die Eigenschaft der Ausgabe (Felder für Name und Wert) zu öffnen.
Geben Sie
JobOutputTypein das Feld Name ein, um den Typ der Ausgabe anzugeben, die Sie erstellen.Geben Sie
UriFilein das Feld Wert ein, um anzugeben, dass die Ausgabe ein Dateipfad ist. Der andere unterstützte Wert für dieses Feld ist UriFolder (ein Ordnerpfad). Im Gegensatz zum Abschnitt „Auftragseingabe“ wird Literal (ein beliebiger Literalwert wie eine Zeichenfolge oder eine ganze Zahl) nicht als Ausgabe unterstützt.Wählen Sie das Pluszeichen neben der Eigenschaft aus, um eine weitere Eigenschaft für diese Ausgabe hinzuzufügen.
Geben Sie
Uriin das Feld Name ein, um den Pfad zu den Daten anzugeben.Geben Sie
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')(Pfad zum Speichern der Ausgabe) in das Feld Wert ein. Azure Machine Learning-Batchendpunkte unterstützen nur die Verwendung von Datenspeicherpfaden als Ausgaben. Da Ausgaben eindeutig sein müssen, um Konflikte zu vermeiden, haben Sie einen dynamischen Ausdruck (@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')) zum Erstellen des Pfads verwendet.
Wenn Ihr Endpunkt mehr Ausgaben zurückgibt, wiederholen Sie die vorherigen Schritte für die einzelnen Ausgaben. In diesem Beispiel generieren Modellbereitstellungen genau eine Ausgabe.
(Optional) Konfigurieren der Auftragseinstellungen
Sie können auch die Auftragseinstellungen konfigurieren, indem Sie die folgenden Eigenschaften hinzufügen:
Für Modellbereitstellungen:
| Einstellung | Beschreibung |
|---|---|
MiniBatchSize |
Die Größe des Batches. |
ComputeInstanceCount |
Die Anzahl der Compute-Instanzen, die von der Bereitstellung angefordert werden sollen. |
Für Pipelinebereitstellungen:
| Einstellung | Beschreibung |
|---|---|
ContinueOnStepFailure |
Gibt an, ob die Pipeline die Verarbeitung von Knoten nach einem Fehler beenden soll. |
DefaultDatastore |
Gibt den Standarddatenspeicher an, der für Ausgaben verwendet werden soll. |
ForceRun |
Gibt an, ob die Pipeline die Ausführung aller Komponenten erzwingen soll, auch wenn die Ausgabe von einer vorherigen Ausführung abgeleitet werden kann. |
Nach der Konfiguration können Sie die Pipeline testen.