Anmerkung
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel enthält Leitfäden mit bewährten Methoden, mit denen Sie die Leistung optimieren, Kosten senken und Ihr Azure Storage-Konto mit aktiviertem Data Lake Storage schützen können.
Allgemeine Vorschläge zur Data Lake-Strukturierung finden Sie in den folgenden Artikeln:
- Übersicht über Azure Data Lake Storage für das Datenverwaltungs- und Analyseszenario
- Bereitstellen von drei Azure Data Lake Storage-Konten für jede Datenzielzone
Zugehörige Dokumentation
Azure Data Lake Storage ist kein dedizierter Dienst- oder Kontotyp. Es handelt sich vielmehr um eine Reihe von Funktionen zur Unterstützung von Analyseworkloads mit hohem Durchsatz. Die Dokumentation zu Data Lake Storage enthält bewährte Methoden und einen Leitfaden für die Verwendung dieser Funktionen. Informationen zu allen anderen Aspekten der Kontoverwaltung, z. B. Einrichten der Netzwerksicherheit, Planen von Hochverfügbarkeit und Notfallwiederherstellung, finden Sie in der Dokumentation zu Blob Storage.
Auswerten der Funktionsunterstützung und bekannter Probleme
Konfigurieren Sie Ihr Konto für die Verwendung von Blob Storage-Funktionen nach dem folgenden Muster.
Im Artikel Unterstützung von Blob Storage-Funktionen in Azure Storage-Konten erfahren Sie, ob eine Funktion in Ihrem Konto vollständig unterstützt wird. Einige Funktionen werden in Konten mit aktiviertem Data Lake Storage noch nicht oder nur teilweise unterstützt. Die Funktionsunterstützung wird ständig erweitert, daher sollten Sie diesen Artikel regelmäßig auf Updates überprüfen.
Im Artikel Bekannte Probleme mit Azure Data Lake Storage können Sie feststellen, ob Einschränkungen oder besondere Hinweise für die Funktion vorliegen, die Sie verwenden möchten.
Prüfen Sie die Artikel zu Funktionen auf Leitfäden, die sich speziell auf Konten mit aktiviertem Data Lake Storage beziehen.
Grundlegendes zu den in der Dokumentation verwendeten Begriffen
In den verschiedenen Inhaltssätzen werden Sie einige kleinere begriffliche Unterschiede feststellen. In der Dokumentation zu Blob Storage, wird beispielsweise der Begriff Blob anstelle von Datei verwendet. Technisch gesehen werden die Dateien, die Sie in Ihrem Speicherkonto erfassen, im Konto zu Blobs. Daher ist der Begriff richtig. Der Begriff Blob kann jedoch zu Verwirrung führen, wenn Sie an den Begriff Datei gewöhnt sind. Außerdem wird der Begriff Container zur Bezeichnung eines Dateisystems verwendet. Diese beiden Begriffe sind als Synonyme zu verstehen.
Premium-Konten
Wenn für Ihre Workloads geringe einheitliche Wartezeiten und/oder eine große Anzahl von Eingabe-/Ausgabevorgängen pro Sekunde erforderlich sind, sollten Sie die Verwendung eines Premium-Kontos für Blockblobspeicher in Erwägung ziehen. Bei dieser Art von Konto werden Daten über Hochleistungshardware verfügbar gemacht. Daten werden auf SSD-Datenträgern (Solid State Drives) gespeichert, die für niedrige Latenz optimiert sind. Der Durchsatz ist bei SSDs im Vergleich zu herkömmlichen Festplatten höher. Die Speicherkosten für Premiumleistung sind höher, aber die Transaktionskosten sind niedriger. Wenn Ihre Anwendungen und Workloads also eine große Anzahl von Transaktionen ausführen, kann sich ein Blockblob-Konto mit Premiumleistung lohnen.
Wenn Ihr Speicherkonto für Analysen verwendet werden soll, wird dringend empfohlen, Azure Data Lake Storage zusammen mit einem Premium-Konto für Blockblobspeicher zu verwenden. Diese Kombination aus Premium-Konto für Blockblobspeicher und Data Lake Storage-fähigem Konto wird als Premium-Ebene für Azure Data Lake Storage bezeichnet.
Optimierung für die Datenerfassung
Bei der Erfassung von Daten aus einem Quellsystem können die Hardware und die Netzwerkhardware der Quelle sowie die Netzwerkkonnektivität mit Ihrem Speicherkonto einen Engpass darstellen.
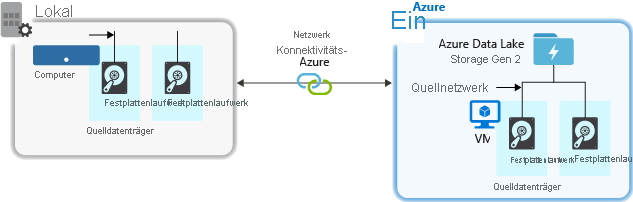
Quellhardware
Unabhängig davon, ob Sie in Azure lokale Computer oder VMs verwenden, sollten Sie die entsprechende Hardware sorgfältig auswählen. Erwägen Sie die Nutzung von SSD-Datenträgern (Solid State Drive) und von Datenträgerhardware mit schnelleren Spindeln. Verwenden Sie für die Netzwerkhardware die schnellstmöglichen Netzwerkschnittstellencontroller (NIC). Für Azure werden virtuelle Azure D14-Computer mit entsprechend leistungsstarker Datenträger- und Netzwerkhardware empfohlen.
Netzwerkkonnektivität mit dem Speicherkonto
Bei der Netzwerkkonnektivität zwischen Ihren Quelldaten und Ihrem Speicherkonto kann es gelegentlich zu einem Engpass kommen. Wenn Ihre Quelldaten lokal gespeichert sind, sollten Sie eine dedizierte Verknüpfung mit Azure ExpressRoute in Erwägung ziehen. Sind Ihre Quelldaten in Azure gespeichert, erzielen Sie eine optimale Leistung, wenn sich die Daten in derselben Azure-Region befinden wie das Data Lake Storage-Konto.
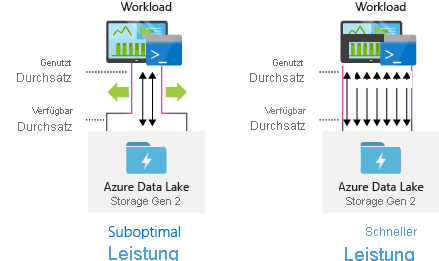
Konfigurieren von Datenerfassungstools für maximale Parallelisierung
Verwenden Sie für eine optimale Leistung den gesamten verfügbaren Durchsatz, indem Sie möglichst viele Lese- und Schreibvorgänge parallel ausführen.
In der folgenden Tabelle finden Sie eine Zusammenfassung der wichtigsten Einstellungen für einige gängige Erfassungstools:
| Werkzeug | Einstellungen |
|---|---|
| DistCp | -m (Mapper) |
| Azure Data Factory | Parallelkopien |
| Sqoop | fs.azure.block.size, -m (Mapper) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Hinweis
Die Gesamtleistung der Erfassungsvorgänge hängt von anderen Faktoren ab, die speziell für das Tool gelten, das Sie zum Erfassen von Daten verwenden. Den jeweils neuesten Leitfaden finden Sie in der Dokumentation zu den einzelnen Tools, die Sie verwenden möchten.
Sie können Ihr Konto skalieren, um den erforderlichen Durchsatz für sämtliche Analyseszenarios bereitzustellen. Die Standardkonfiguration eines Kontos mit Data Lake Storage-Aktivierung bietet genügend Durchsatz, um die Anforderungen eines breiten Spektrums an Anwendungsfällen zu erfüllen. Bei Erreichen des Standardlimits kann das Konto für die Bereitstellung eines höheren Durchsatzes konfiguriert werden. Wenden Sie sich hierfür an den Azure-Support.
Strukturieren von Datasets
Sie können die Struktur der Daten vorab planen. Dateiformat, Dateigröße und Verzeichnisstruktur können sich auf Leistung und Kosten auswirken.
Dateiformate
Daten können in verschiedenen Formaten erfasst werden. Daten können in lesbaren Formaten wie JSON, CSV oder XML oder in komprimierten Binärformaten wie .tar.gz vorliegen. Außerdem können Daten in verschiedenen Größen gespeichert werden. Daten können aus umfangreichen Dateien (einige Terabyte) bestehen, z. B. Daten aus einem Export einer SQL-Tabelle aus lokalen Systemen. Daten können auch in Form einer großen Anzahl kleiner Dateien (wenige Kilobyte) vorliegen, z. B. Daten aus Echtzeitereignissen aus einer IoT-Lösung (Internet der Dinge). Durch Auswahl eines entsprechenden Dateiformats und einer geeigneten Dateigröße können Sie die Effizienz und die Kosten optimieren.
Hadoop unterstützt eine Reihe von Dateiformaten, die für die Speicherung und Verarbeitung strukturierter Daten optimiert sind. Einige gängige Formate sind Avro, Parquet und ORC (Optimized Row Columnar). Bei all diesen Formaten handelt es sich um maschinenlesbare Binärdateiformate. Zur Verringerung der Dateigröße sind sie komprimiert. Sie verfügen über ein in jede Datei eingebettetes Schema, sodass sie selbstbeschreibend sind. Die Formate unterscheiden sich in der Speicherung der Daten. In Avro werden Daten in einem zeilenbasierten Format gespeichert, in Parquet und ORC dagegen in einem spaltenbasierten Format.
Das Avro-Dateiformat können Sie für schreibintensive Ein-/Ausgabemuster oder für Abfragemuster verwenden, bei denen der Abruf mehrerer Datensatzzeilen in ihrer Gesamtheit erforderlich ist. Das Avro-Format eignet sich beispielsweise gut für einen Nachrichtenbus wie Event Hubs oder Kafka für das sukzessive Schreiben mehrerer Ereignisse oder Nachrichten.
Die Dateiformate Parquet und ORC eignen sich für leseintensive Ein-/Ausgabemuster oder für Abfragemuster, die sich auf eine Teilmenge von Spalten in den Datensätzen beschränken. Lesetransaktionen können so optimiert werden, dass bestimmte Spalten abgerufen werden, ohne dass der gesamte Datensatz gelesen wird.
Apache Parquet ist ein Open-Source-Dateiformat, das für Analysepipelines mit vielen Lesevorgängen optimiert wurde. Die spaltenbasierte Speicherstruktur von Parquet ermöglicht das Überspringen nicht relevanter Daten. Ihre Abfragen sind wesentlich effizienter, da der Umfang der Daten eingegrenzt werden kann, die vom Speicher an die Analytics-Engine gesendet werden. Da zudem ähnliche Datentypen (für eine Spalte) zusammen gespeichert werden, unterstützt Parquet effiziente Schemas zur Datenkomprimierung und -codierung. Auf diese Weise werden die Kosten für die Datenspeicherung gesenkt. Dienste wie Azure Synapse Analytics, Azure Databricks und Azure Data Factory verfügen über native Funktionen, die Parquet-Dateiformate nutzen.
Dateigröße
Größere Dateien ermöglichen bessere Leistung und geringere Kosten.
In der Regel wird bei Analyse-Engines wie HDInsight für jede Datei ein Verwaltungsaufwand verursacht, der z. B. das Auflisten, das Überprüfen des Zugriffs sowie verschiedene Metadatenvorgänge umfasst. Wenn Sie Ihre Daten in zahlreichen kleinen Dateien speichern, kann sich dies negativ auf die Leistung auswirken. Im Allgemeinen sollten Sie Ihre Daten in größeren Dateien organisieren, um eine bessere Leistung zu erzielen (256 MB bis 100 GB). Dateien mit einer Größe von mehr als 100 GB können von einigen Engines und Anwendungen unter Umständen nicht effizient verarbeitet werden.
Durch Erhöhung der Dateigröße lassen sich auch die Transaktionskosten reduzieren. Lese- und Schreibvorgänge werden in Schritten von 4 MB abgerechnet, d. h., Sie zahlen für einen Vorgang unabhängig davon, ob die Datei 4 MB oder nur wenige Kilobyte umfasst. Preisinformationen finden Sie unter Azure Data Lake Storage – Preise.
Mitunter können Datenpipelines Rohdaten mit vielen kleinen Dateien nur begrenzt nutzen. Im Allgemeinen sollte Ihr System einen Prozess zum Aggregieren kleiner Dateien zu großen zur Verwendung durch nachgelagerte Anwendungen aufweisen. Für die Verarbeitung von Daten in Echtzeit können Sie mithilfe einer Echtzeit-Streaming-Engine (z. B. Azure Stream Analytics oder Spark Streaming) zusammen mit einem Nachrichtenbroker (z. B. Event Hubs oder Apache Kafka) Ihre Daten als größere Dateien speichern. Wenn Sie kleine Dateien in größere aggregieren, sollten Sie zum Speichern ein leseoptimiertes Format wie Apache Parquet für die Downstreamverarbeitung auswählen.
Verzeichnisstruktur
Für jede Workload gelten unterschiedliche Anforderungen in Bezug auf die Nutzung der Daten. Nachfolgend sind einige häufig verwendete Layouts angegeben, die beim Internet der Dinge (IoT), bei Batch-Szenarien oder bei der Optimierung für Zeitreihendaten zu berücksichtigen sind.
IoT-Struktur
Bei den IoT-Workloads können große Datenmengen erfasst werden, die sich über zahlreiche Produkte, Geräte, Organisationen und Kunden erstrecken. Es ist wichtig, das Layout des Verzeichnisses im Voraus zu planen, um die Organisation, die Sicherheit und die effiziente Verarbeitung der Daten für die nachgeschalteten Verbraucher zu gewährleisten. Das folgende Layout kann hierbei als allgemeine Vorlage dienen:
- {Region}/{SubjectMatter(s)}/jjjj/{mm}/{tt}/{hh}/
Die Zieltelemetrie für ein Flugzeugtriebwerk im Vereinigten Königreich kann beispielsweise wie die folgende Struktur aussehen:
- UK/Planes/BA1293/Engine1/2017/08/11/12/
In diesem Beispiel können Sie Zugriffssteuerungslisten verwenden, um Regionen und Themen für bestimmte Benutzer und Gruppen einfacher zu schützen, indem Sie das Datum an das Ende der Verzeichnisstruktur setzen. Wenn Sie die date-Struktur an den Anfang setzen, wäre es viel schwieriger, diese Regionen und Themen zu schützen. Wenn Sie beispielsweise nur Zugriff auf UK-Daten oder bestimmte Ebenen bereitstellen möchten, müssten Sie eine separate Berechtigung für zahlreiche Verzeichnisse in jedem Stundenverzeichnis anwenden. Diese Struktur würde auch die Anzahl der Verzeichnisse im Laufe der Zeit exponentiell erhöhen.
Struktur von Batchaufträgen
Ein häufig verwendeter Ansatz bei der Batchverarbeitung besteht im Platzieren von Daten in einem Verzeichnis vom Type „Eingang“ (In). Nachdem die Daten verarbeitet wurden, werden die neuen Daten dann in einem Verzeichnis des Typs „Ausgang“ (Out) angeordnet, damit sie von nachgelagerten Prozessen genutzt werden können. Diese Verzeichnisstruktur wird manchmal bei Aufträgen verwendet, bei denen einzelne Dateien verarbeitet werden müssen und ggf. kein Massively Parallel Processing für große Datasets erforderlich ist. Wie bei der oben empfohlenen IoT-Struktur auch, verfügt eine gute Verzeichnisstruktur über übergeordnete Verzeichnisse für Dinge wie Region und Themen (z. B. Organisation, Produkt oder Hersteller). Berücksichtigen Sie in der Struktur das Datum und die Uhrzeit, um eine bessere Organisation, gefilterte Suchen, Sicherheit und Automatisierung der Verarbeitung zu ermöglichen. Der Granularitätsgrad für die Datumsstruktur wird durch das Intervall bestimmt, nach dem die Daten hochgeladen oder verarbeitet werden, z.B. stündlich, täglich oder auch monatlich.
Es kann vorkommen, dass die Dateiverarbeitung nicht erfolgreich ist, weil Daten beschädigt sind oder ein unerwartetes Format haben. In diesen Fällen kann für die Verzeichnisstruktur die Nutzung des Ordners /bad vorteilhaft sein, in den die Dateien zur weiteren Untersuchung verschoben werden können. Über den Batchauftrag können ggf. auch die Berichterstellung oder die Benachrichtigungsvorgänge für diese fehlerhaften Dateien (bad files) abgewickelt werden, um einen manuellen Eingriff zu ermöglichen. Erwägen Sie die Verwendung der folgenden Vorlagenstruktur:
- {Region}/{SubjectMatter(s)}/In/jjjj/{mm}/{tt}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/jjjjj/{mm}/{tt}/{hh}/
- {Region}/{SubjectMatter (e)}/Bad/jjjj/{mm}/{tt}/{hh}/
Es kann beispielsweise sein, dass ein Marketingunternehmen tägliche Datenextrakte aus Kundenupdates von seinen Kunden in Nordamerika erhält. Vor und nach der Verarbeitung kann dies ggf. wie im folgenden Codeausschnitt aussehen:
- NA/Extrakte/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extrakte/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
Bei der normalen Verarbeitung von Batchdaten direkt in Datenbanken, z. B. Hive oder herkömmlichen SQL-Datenbanken, sind die Verzeichnisse /in oder /out nicht erforderlich, da die Ausgabe bereits in einem separaten Ordner für die Hive-Tabelle oder externe Datenbank angeordnet wird. Beispielsweise würden tägliche Extraktionen von Kunden in ihren jeweiligen Verzeichnissen landen. Anschließend würde ein Dienst wie Azure Data Factory, Apache Oozie oder Apache Airflow einen täglichen Hive- oder Spark-Auftrag auslösen, um die Daten zu verarbeiten und in eine Hive-Tabelle zu schreiben.
Struktur von Zeitreihendaten
Bei Hive-Workloads können Sie durch Bereinigen der Partition von Zeitreihendaten eine Leistungsverbesserung erreichen, da einige Abfragen nur eine Teilmenge der Daten lesen.
Diese Pipelines, die Zeitreihendaten erfassen, versehen ihre Dateien oftmals mit einer strukturierten Benennung für Dateien und Ordner. Nachfolgend wird ein gängiges Beispiel für Daten vorgestellt, die nach Datum strukturiert sind:
/DataSet/JJJJ/MM/TT/datafile_JJJJ_MM_TT.tsv
Beachten Sie, dass Informationen zu Datum/Uhrzeit sowohl im Ordnernamen als auch im Dateinamen angegeben werden.
Im Folgenden wird ein allgemeines Muster für Datums- und Uhrzeitangaben vorgestellt:
/DataSet/JJJJ/MM/TT/HH/mm/datafile_JJJ_MM_TT_HH_mm.tsv
Auch hier sollte die Wahl, die Sie bei der Ordner- und Dateiorganisation treffen, für größere Dateien und eine angemessene Anzahl von Dateien in den einzelnen Ordnern optimiert sein.
Einrichten der Sicherheit
Lesen Sie zunächst die Empfehlungen im Artikel Sicherheitsempfehlungen für Blob Storage. Dort finden Sie bewährte Methoden zum Schutz Ihrer Daten vor versehentlichem oder böswilligem Löschen, zum Schutz von Daten hinter einer Firewall und zur Verwendung von Microsoft Entra ID als Grundlage der Identitätsverwaltung.
Lesen Sie dann den Artikel Zugriffssteuerungsmodell in Azure Data Lake Storage, um spezifische Leitfäden für Konten mit aktiviertem Data Lake Storage zu erhalten. In diesem Artikel erfahren Sie, wie Sie Rollen der rollenbasierten Azure-Zugriffssteuerung (Azure RBAC) zusammen mit Zugriffssteuerungslisten (ACLs) verwenden, um Sicherheitsberechtigungen für Verzeichnisse und Dateien in Ihrem hierarchischen Dateisystem zu erzwingen.
Erfassen, Verarbeiten und Analysieren
Es gibt viele verschiedene Datenquellen und verschiedene Möglichkeiten, wie diese Daten in einem Data Lake Storage-fähigen Konto erfasst werden können.
Sie können zum Beispiel große Datensätze von HDInsight- und Hadoop-Clustern oder kleinere Sätze von Ad-hoc-Daten für Prototyping-Anwendungen erfassen. Sie können gestreamte Daten erfassen, die von verschiedenen Quellen wie Anwendungen, Geräten und Sensoren erzeugt werden. Für diese Art von Daten können Sie Tools verwenden, um die Daten ereignisweise in Echtzeit zu erfassen und zu verarbeiten und dann die Ereignisse in Stapeln in Ihr Konto zu schreiben. Sie können auch Webserverprotokolle erfassen, die Informationen wie den Verlauf von Seitenanforderungen enthalten. Für Protokolldaten sollten Sie das Schreiben benutzerdefinierter Skripte oder Anwendungen in Betracht ziehen, um sie hochzuladen, so dass Sie die Flexibilität haben, Ihre Daten-Upload-Komponente als Teil Ihrer größeren Big Data-Anwendung einzubinden.
Sobald die Daten in Ihrem Konto verfügbar sind, können Sie mit diesen Daten Analysen durchführen, Visualisierungen erstellen und sogar Daten auf Ihren lokalen Rechner oder auf andere Repositories wie eine Azure SQL-Datenbank oder SQL Server-Instanz herunterladen.
In der folgenden Tabelle werden Tools empfohlen, die Sie zum Erfassen, Analysieren, Visualisieren und Herunterladen von Daten verwenden können. Verwenden Sie die Links in dieser Tabelle, um Anleitungen zur Konfiguration und Verwendung der einzelnen Tools zu erhalten.
| Zweck | Tools & Tool-Anleitung |
|---|---|
| Ad-hoc-Daten erfassen | Azure Portal, Azure PowerShell, Azure CLI, REST, Azure Storage Explorer, Apache DistCp, AzCopy |
| Erfassen relationaler Daten | Azure Data Factory |
| Erfassen von Webserver-Protokollen | Azure PowerShell, Azure CLI, REST, Azure SDKs (.NET, Java, Python, und Node.js), Azure Data Factory |
| Erfassen von HDInsight-Clustern | Azure Data Factory, Apache DistCp, AzCopy |
| Erfassen von Hadoop-Clustern | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator für Azure, Azure Data Box |
| Erfassen großer Datenmengen (mehrere Terabytes) | Azure ExpressRoute |
| Verarbeiten und Analysieren von Daten | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Visualisieren von Daten | Power BI, Azure Data Lake Storage Abfragebeschleunigung |
| Herunterladen von Daten | Azure-Portal, PowerShell, Azure CLI, REST, Azure SDKs (.NET, Java, Python und Node.js), Azure Storage Explorer, AzCopy, Azure Data Factory, Apache DistCp |
Hinweis
Diese Tabelle enthält nicht die komplette Liste der Azure-Dienste, die Data Lake Storage unterstützen. Eine Liste der unterstützten Azure-Dienste und deren Unterstützungsgrad finden Sie unter Azure-Dienste mit Unterstützung für Azure Data Lake Storage.
Überwachen von Telemetriedaten
Die Überwachung von Verbrauch und Leistung ist ein wichtiger Bestandteil der Operationalisierung Ihres Diensts. Beispiele hierfür sind häufig ausgeführte Vorgänge, Vorgänge mit hoher Latenz oder Vorgänge, die eine dienstseitige Drosselung zur Folge haben.
Alle Telemetriedaten für Ihr Speicherkonto sind über Azure Storage-Protokolle in Azure Monitor verfügbar. Mit dieser Funktion wird das Speicherkonto in Log Analytics und Event Hubs integriert. Gleichzeitig können Sie Protokolle in einem anderen Speicherkonto archivieren. Die vollständige Liste der Metriken und Ressourcenprotokolle und das zugehörige Schema finden Sie unter Überwachen von Daten in Azure Storage – Referenz.
Wo Sie die Protokolle speichern, hängt davon ab, wie Sie darauf zugreifen möchten. Wenn Sie beispielsweise nahezu in Echtzeit auf die Protokolle zugreifen und Ereignisse in Protokollen mit anderen Metriken aus Azure Monitor korrelieren möchten, können Sie die Protokolle in einem Log Analytics-Arbeitsbereich speichern. Fragen Sie dann die Protokolle mithilfe von KQL ab und erstellen Sie Abfragen, die die Tabelle StorageBlobLogs in Ihrem Arbeitsbereich enumerieren.
Wenn Sie die Protokolle für Abfragen nahezu in Echtzeit und für die Langzeitaufbewahrung speichern möchten, können Sie die Diagnoseeinstellungen so konfigurieren, dass Protokolle an einen Log Analytics-Arbeitsbereich sowie an ein Speicherkonto gesendet werden.
Wenn Sie über eine andere Abfrage-Engine wie Splunk auf die Protokolle zugreifen möchten, können Sie die Diagnoseeinstellungen so konfigurieren, dass Protokolle an einen Event Hub gesendet sowie vom Event Hub im ausgewählten Ziel erfasst werden.
Azure Storage-Protokolle in Azure Monitor können über das Azure-Portal, PowerShell, die Azure-Befehlszeilenschnittstelle und Azure Resource Manager-Vorlagen aktiviert werden. Für bedarfsgerechte Bereitstellungen kann Azure Policy mit vollständiger Unterstützung für Wartungstasks verwendet werden. Weitere Informationen finden Sie unter ciphertxt/AzureStoragePolicy.