Was ist ML.NET, und wie funktioniert es?
ML.NET ermöglicht es Ihnen, .NET-Anwendungen in Online- oder Offlineszenarien mit Machine Learning zu versehen. Mit dieser Funktion können Sie automatische Vorhersagen unter Verwendung der Daten treffen, die für Ihre Anwendung verfügbar sind. ML-Anwendungen verwenden Muster in den Daten, um Vorhersagen zu treffen, und müssen daher nicht explizit programmiert werden.
Zentraler Bestandteil von ML.NET ist ein Machine Learning-Modell. Das Modell gibt die Schritte an, die erforderlich sind, um Ihre Eingabedaten in eine Vorhersage umzuwandeln. Mit ML.NET können Sie ein benutzerdefiniertes Modell trainieren, indem Sie einen Algorithmus angeben, oder Sie können bereits trainierte TensorFlow- und ONNX-Modelle importieren.
Sobald Sie über ein Modell verfügen, können Sie es Ihrer Anwendung hinzufügen, um Vorhersagen zu treffen.
ML.NET kann unter Windows, Linux und macOS mit .NET oder unter Windows mit .NET Framework ausgeführt werden. 64-Bit wird auf allen Plattformen unterstützt. 32-Bit wird unter Windows unterstützt (mit Ausnahme der Funktionen für TensorFlow, LightGBM und ONNX).
Die folgende Tabelle enthält Beispiele für die Art von Vorhersagen, die Sie mit ML.NET erstellen können.
| Vorhersagetyp | Beispiel |
|---|---|
| Klassifizierung/Kategorisierung | Automatisches Unterteilen von Kundenfeedback in positive und negative Kategorien |
| Regression/Vorhersage von kontinuierlichen Werten | Vorhersagen des Hauspreises basierend auf Größe und Standort |
| Erkennung von Anomalien | Erkennen von betrügerischen Banktransaktionen |
| Empfehlungen | Empfehlen von Produkten, die Onlinekäufern basierend auf ihren vorherigen Käufen wahrscheinlich kaufen möchten |
| Zeitreihen/sequenzielle Daten | Vorhersagen zu Wetter oder Produktumsatz |
| Bildklassifizierung | Kategorisieren von Pathologien in medizinischen Bildern |
| Textklassifizierung | Kategorisieren von Dokumenten auf der Grundlage ihres Inhalts. |
| Satzähnlichkeit | Messen Sie die Ähnlichkeit zweier Sätze. |
Hallo ML.NET-Welt
Der Code im folgenden Codeausschnitt veranschaulicht die einfachste ML.NET-Anwendung. In diesem Beispiel erstellt ein Modell der linearen Regression Hauspreisvorhersagen auf der Basis von Größe- und Preisdaten.
using System;
using Microsoft.ML;
using Microsoft.ML.Data;
class Program
{
public class HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
MLContext mlContext = new MLContext();
// 1. Import or create training data
HouseData[] houseData = {
new HouseData() { Size = 1.1F, Price = 1.2F },
new HouseData() { Size = 1.9F, Price = 2.3F },
new HouseData() { Size = 2.8F, Price = 3.0F },
new HouseData() { Size = 3.4F, Price = 3.7F } };
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model
var model = pipeline.Fit(trainingData);
// 4. Make a prediction
var size = new HouseData() { Size = 2.5F };
var price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size*1000} sq ft= {price.Price*100:C}k");
// Predicted price for size: 2500 sq ft= $261.98k
}
}
Codeworkflow
Im folgenden Diagramm werden die Anwendungscodestruktur und der iterative Prozess der Modellentwicklung dargestellt:
- Sammeln und Laden von Trainingsdaten in einem IDataView-Objekt
- Angeben einer Pipeline von Vorgängen zum Extrahieren von Features und Anwenden eines Machine Learning-Algorithmus
- Trainieren eines Modells durch Aufrufen von Fit() auf der Pipeline
- Auswerten des Modells und Iterieren zur Verbesserung
- Speichern des Modells im Binärformat zur Verwendung in einer Anwendung
- Rückladen des Modells in ein ITransformer-Objekt
- Treffen von Vorhersagen durch Aufrufen von CreatePredictionEngine.Predict()
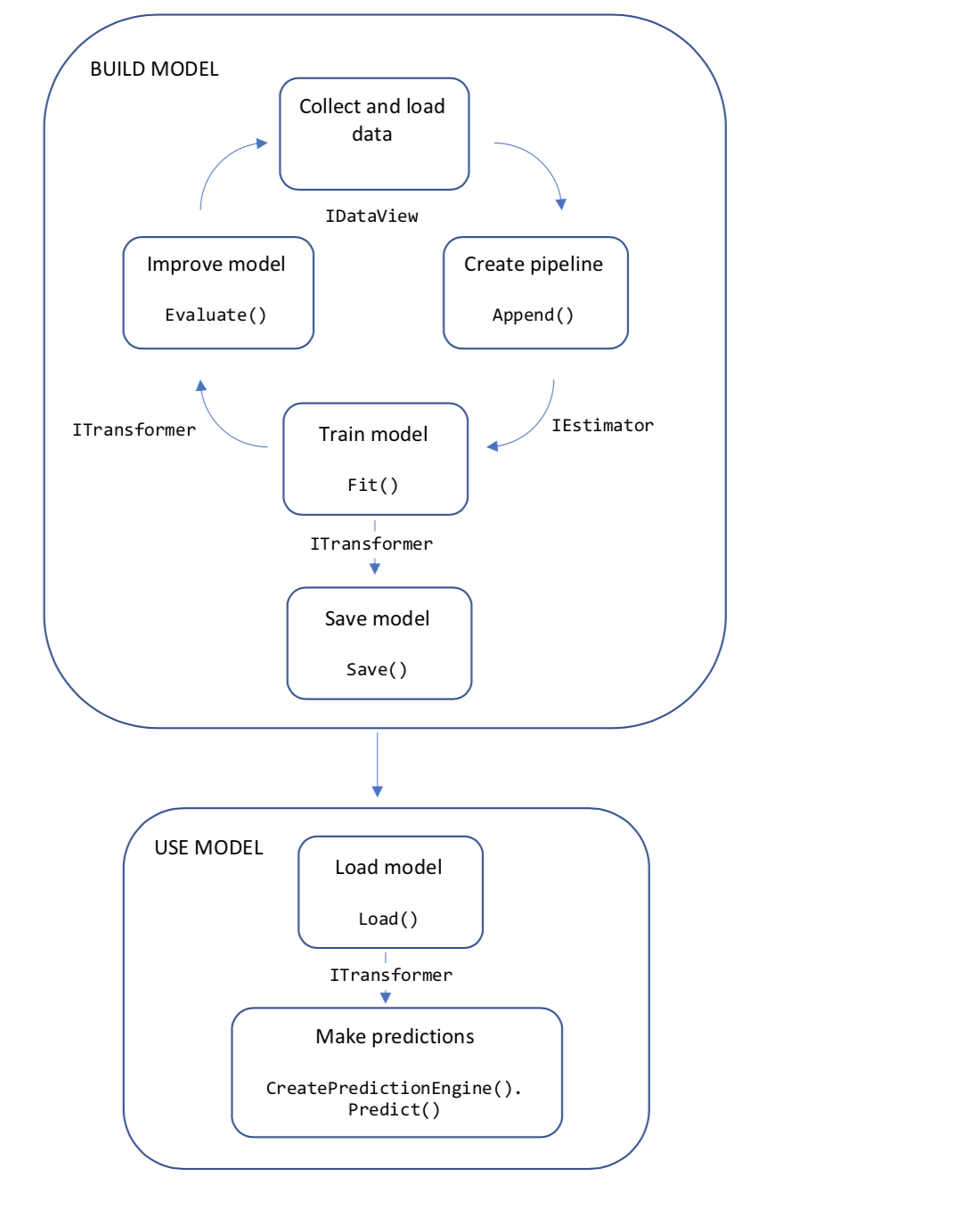
Wir werden diese Konzepte nun näher betrachten.
Machine Learning-Modell
Ein ML.NET-Modell ist ein Objekt, das Transformationen enthält, die auf Ihre Eingabedaten angewendet werden, damit sie die vorhergesagte Ausgabe erreichen.
Standard
Das einfachste Modell ist die zweidimensionale lineare Regression, wobei wie im obigen Hauspreisbeispiel eine kontinuierliche Menge zu einer anderen proportional ist.

Das Modell ist einfach: $Price = b + Size * w$. Die Parameter „$b$“ und „$w$“ werden durch Anpassung einer Linie an eine Gruppe von (size, price)-Paaren geschätzt. Die zum Finden der Parameter des Modells verwendeten Daten werden als Trainingsdaten bezeichnet. Die Eingaben eines Machine Learning-Modells werden als Features bezeichnet. In diesem Beispiel ist $Size$ das einzige Feature. Die zum Trainieren eines Machine Learning-Modells verwendeten Ground-Truth-Werte werden als Labels bezeichnet. Hier sind die $Price$-Werte im Trainingsdataset die Labels.
Komplexer
Ein komplexeres Modell klassifiziert finanzielle Transaktionen mithilfe der Transaktionstextbeschreibung in Kategorien.
Jede Transaktionsbeschreibung wird durch Entfernen redundante Wörter und Zeichen und Zählen von Kombinationen aus Word und Zeichen in einen Satz von Features aufgeschlüsselt. Die Featuregruppe wird zum Trainieren eines linearen Modells auf der Basis des Kategoriensatzes in den Trainingsdaten verwendet. Je mehr eine neue Beschreibung denjenigen im Trainingssatz ähnelt, desto eher wird sie derselben Kategorie zugewiesen.

Hauspreismodell und Textklassifizierungsmodell sind beide lineare Modelle. Je nach Art Ihrer Daten und des Problems, das Sie lösen, können Sie auch Entscheidungsstrukturmodelle, verallgemeinert additive Modelle, und andere verwenden. Weitere Informationen zu den Modellen finden Sie unter Aufgaben.
Datenvorbereitung
In den meisten Fällen können die Daten, die Ihnen zur Verfügung stehen, nicht direkt zum Trainieren von Machine Learning-Modellen verwendet werden. Die unformatierten Daten müssen vorbereitet, d. h. vorverarbeitet werden, bevor Sie sie verwenden können, um die Parameter Ihres Modells zu finden. Möglicherweise müssen Ihre Daten von Zeichenfolgenwerten in eine numerische Darstellung konvertiert werden. Vielleicht enthalten Ihre Eingabedaten redundante Informationen. Sie müssen möglicherweise die Dimensionen der Eingabedaten reduzieren oder erweitern. Ihre Daten müssen vielleicht normalisiert oder skaliert werden.
Die ML.NET-Tutorials informieren Sie über verschiedene Datenverarbeitungspipelines für Text-, Bild-, numerische und Zeitreihendaten, die für bestimmte Machine Learning-Aufgaben verwendet werden.
Unter Vorbereiten von Daten finden Sie allgemeinere Informationen zur Anwendung der Datenvorbereitung.
Im Ressourcenabschnitt finden Sie einen Anhang mit allen verfügbaren Transformationen.
Modellauswertung
Wie können Sie nach dem Trainieren Ihres Modells wissen, wie gut es zukünftige Vorhersagen treffen wird? Mit ML.NET können Sie Ihr Modell anhand einiger neuer Testdaten auswerten.
Jede Art von Machine Learning-Aufgabe verfügt über Metriken zum Auswerten der Genauigkeit des Modells anhand eines Testdatasets.
In unserem Hauspreisbeispiel haben wir die Regressionsaufgabe verwendet. Um das Modell auszuwerten, fügen Sie dem ursprünglichen Beispiel den folgenden Code hinzu.
HouseData[] testHouseData =
{
new HouseData() { Size = 1.1F, Price = 0.98F },
new HouseData() { Size = 1.9F, Price = 2.1F },
new HouseData() { Size = 2.8F, Price = 2.9F },
new HouseData() { Size = 3.4F, Price = 3.6F }
};
var testHouseDataView = mlContext.Data.LoadFromEnumerable(testHouseData);
var testPriceDataView = model.Transform(testHouseDataView);
var metrics = mlContext.Regression.Evaluate(testPriceDataView, labelColumnName: "Price");
Console.WriteLine($"R^2: {metrics.RSquared:0.##}");
Console.WriteLine($"RMS error: {metrics.RootMeanSquaredError:0.##}");
// R^2: 0.96
// RMS error: 0.19
Die Auswertungsmetriken zeigen, dass der Fehler gering ist, und dass die Korrelation zwischen der vorhergesagten Ausgabe und der Testausgabe hoch ist. Nun, das war einfach. In realen Beispielen sind weitere Optimierungen erforderlich, um gute Modellmetriken zu erzielen.
ML.NET-Architektur
In diesem Abschnitt werden die Architekturmuster von ML.NET beschrieben. Wenn Sie ein erfahrener .NET-Entwickler sind, werden Ihnen einige dieser Muster vertraut und einige weniger vertraut sein.
Eine ML.NET-Anwendung beginnt mit einem MLContext-Objekt. Dieses Singletonobjekt enthält Kataloge. Ein Katalog ist eine Factory zum Laden und Speichern von Daten, für Transformationen, Trainer und Modellvorgangskomponenten. Jedes Katalogobjekt verfügt über Methoden, um die verschiedenen Arten von Komponenten zu erstellen.
| Aufgabe | Katalog |
|---|---|
| Laden und Speichern von Daten | DataOperationsCatalog |
| Datenaufbereitung | TransformsCatalog |
| Binäre Klassifizierung | BinaryClassificationCatalog |
| Multiklassenklassifizierung | MulticlassClassificationCatalog |
| Anomalieerkennung | AnomalyDetectionCatalog |
| Clusterbildung | ClusteringCatalog |
| Vorhersage | ForecastingCatalog |
| Rangfolge | RankingCatalog |
| Regression | RegressionCatalog |
| Empfehlung | RecommendationCatalog |
| Zeitreihe | TimeSeriesCatalog |
| Modellverwendung | ModelOperationsCatalog |
Sie können in jeder der oben genannten Kategorien zu den Erstellungsmethoden navigieren. Bei Verwendung von Visual Studio werden die Kataloge über IntelliSense angezeigt.
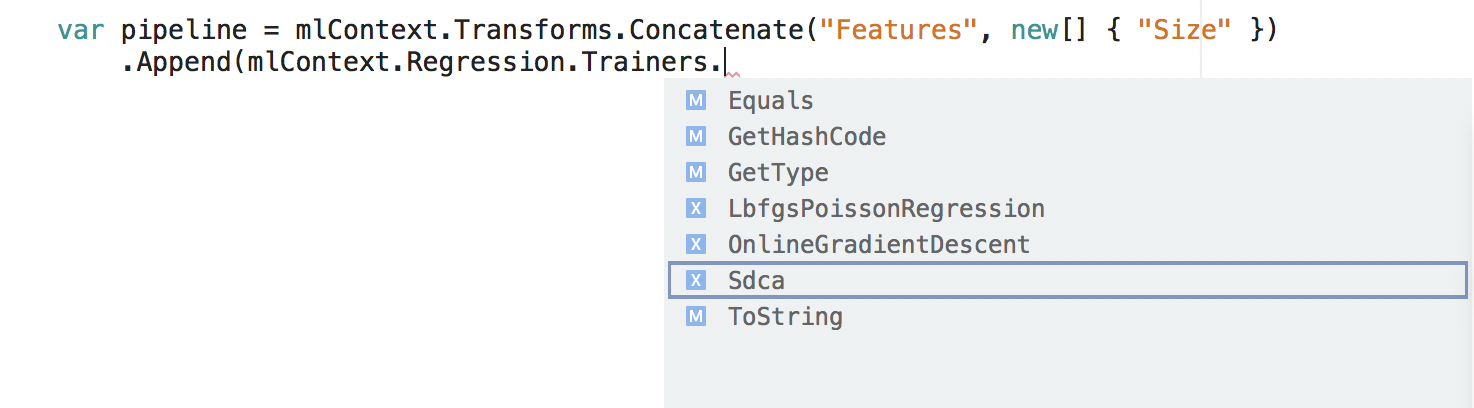
Erstellen der Pipeline
Jeder Katalog beinhaltet eine Reihe von Erweiterungsmethoden, mit denen Sie eine Trainingspipeline erstellen können.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
Im Codeausschnitt sind Concatenate und Sdca Methoden im Katalog. Sie erstellen jeweils ein IEstimator-Objekt, das der Pipeline angefügt wird.
An diesem Punkt wurden die Objekte erstellt, aber es ist keine Ausführung erfolgt.
Trainieren des Modells
Nachdem die Objekte in der Pipeline erstellt wurden, können Daten zum Trainieren des Modells verwendet werden.
var model = pipeline.Fit(trainingData);
Beim Aufruf von Fit() werden die Eingabetrainingsdaten verwendet, um die Parameter des Modells zu schätzen. Dies wird als Trainieren des Modells bezeichnet. Bedenken Sie, dass das oben gezeigte lineare Regressionsmodell zwei Modellparameter hatte: bias und weight. Nach dem Fit()-Aufruf sind die Werte der Parameter bekannt. Die meisten Modelle haben viel mehr Parameter.
Weitere Informationen zum Modelltraining finden Sie unter Trainieren eines Modells.
Das resultierende Modellobjekt implementiert die ITransformer-Schnittstelle. Das Modell transformiert also Eingabedaten in Vorhersagen.
IDataView predictions = model.Transform(inputData);
Verwenden des Modells
Sie können Eingabedaten in einem Massenvorgang in Vorhersagen umwandeln oder jede Eingabe einzeln. Im Hauspreisbeispiel haben wir beides getan: im Massenvorgang zum Auswerten des Modells und einzeln, um eine neue Vorhersage zu treffen. Wir betrachten nun die einzelnen Vorhersagen.
var size = new HouseData() { Size = 2.5F };
var predEngine = mlContext.CreatePredictionEngine<HouseData, Prediction>(model);
var price = predEngine.Predict(size);
Die CreatePredictionEngine()-Methode nimmt eine Eingabe- und eine Ausgabeklasse entgegen. Die Feldnamen oder Codeattribute bestimmen die Namen der Datenspalten, die beim Trainieren des Modells und der Vorhersage verwendet werden. Weitere Informationen finden Sie unter Treffen von Vorhersagen mit einem trainierten Modell.
Datenmodelle und Schema
Das Herzstück einer ML.NET-Machine Learning-Pipeline sind DataView-Objekte.
Jede Transformation in der Pipeline weist ein Eingabeschema (Datennamen, -typen und -größen, die die Transformation bei der Eingabe erwartet) und ein Ausgabeschema (nach der Transformation erzeugte Datennamen, -typen und -größen) auf.
Wenn das Ausgabeschema einer Transformation in der Pipeline nicht dem Eingabeschema der nächsten Transformation entspricht, löst ML.NET eine Ausnahme aus.
Ein Datenansichtsobjekt enthält Spalten und Zeilen. Jede Spalte hat einen Namen, einen Typ und eine Länge. Beispiel: Die Eingabespalten im Hauspreisbeispiel sind Size und Price („Größe“ und „Preis“). Beide sind Typen, und sie sind eher Skalar- als Vektormengen.
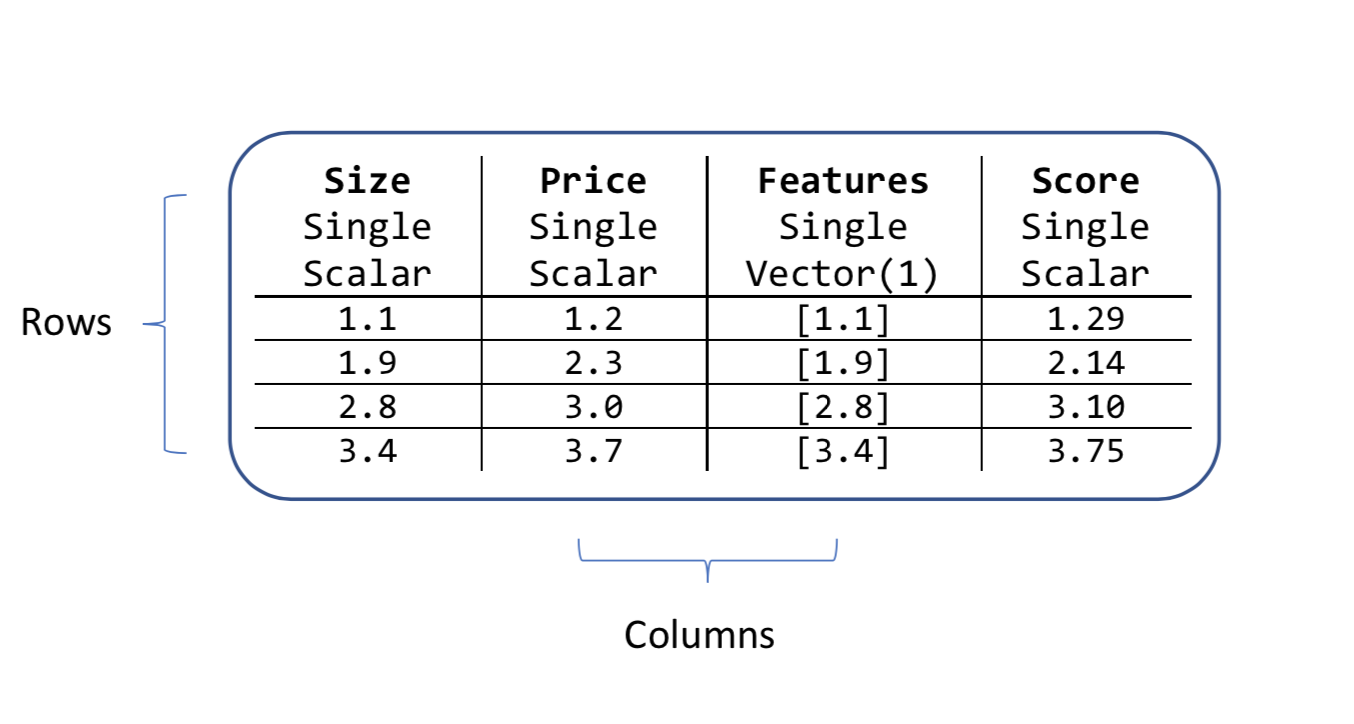
Alle ML.NET-Algorithmen suchen nach einer Eingabespalte, die ein Vektor ist. Standardmäßig wird diese Vektorspalte Features genannt. Darum haben wir im Hauspreisbeispiel die Spalte Size in eine neue Spalte namens Features verkettet.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
Alle Algorithmen erstellen auch neue Spalten, nachdem sie eine Vorhersage ausgeführt haben. Die festgelegten Namen dieser neuen Spalten hängen vom Typ des Machine Learning-Algorithmus ab. Für die Regressionsaufgabe wird eine der neuen Spalten aufgerufen, Score, wie im Preisdatenattribut dargestellt.
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
Weitere Informationen über Ausgabespalten anderer Machine Learning-Aufgaben finden Sie im Handbuch Machine Learning-Aufgaben in ML.NET.
Eine wichtige Eigenschaft von DataView-Objekten ist, dass sie verzögert ausgewertet werden. Datenansichten werden nur beim Trainieren und Auswerten des Modells und bei der Datenvorhersage geladen und verarbeitet. Beim Schreiben und Testen Ihrer ML.NET-Anwendung können Sie mit dem Visual Studio-Debugger einen Blick auf jedes Datenansichtsobjekt werfen, indem Sie die Preview-Methode aufrufen.
var debug = testPriceDataView.Preview();
Sie können die debug-Variable im Debugger beobachten und ihren Inhalt untersuchen. Verwenden Sie die Preview-Methode nicht im Produktionscode, da sie die Leistung erheblich beeinträchtigt.
Modellimplementierung
In realen Anwendungen sind Ihr Modelltrainings- und Auswertungscode von Ihrer Vorhersage getrennt. Diese beiden Aktivitäten werden in der Tat häufig durch separate Teams ausgeführt. Ihr Modellbereitstellungsteam kann das Modell zur Verwendung in der Vorhersageanwendung speichern.
mlContext.Model.Save(model, trainingData.Schema,"model.zip");
Nächste Schritte
Erfahren Sie in den Tutorials, wie Sie mit anderen Machine Learning-Aufgaben Anwendungen mit realistischeren Datasets erstellen.
Informieren Sie sich in den Schrittanleitungen ausführlicher über bestimmte Themen.
Wenn Sie extrem interessiert sind, können Sie direkt in die API-Referenzdokumentation eintauchen.