Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie eine Anomalieerkennungsanwendung für Produktumsatzdaten erstellen. In diesem Lernprogramm wird eine .NET-Konsolenanwendung mit C# in Visual Studio erstellt.
In diesem Tutorial erfahren Sie, wie:
- Laden der Daten
- Erstellen einer Transformation für die Anomalieerkennung von Spitzen
- Erkennen von Spitzenanomalien mithilfe der Transformation
- Erstellen einer Transformation für die Anomalieerkennung von Änderungspunkten
- Erkennen von Änderungspunktanomalien mit der Transformation
Den Quellcode für dieses Lernprogramm finden Sie im Repository dotnet/samples .
Voraussetzungen
Visual Studio 2022 oder höher mit installierter .NET Desktop Development-Workload .
Hinweis
Das Datenformat in product-sales.csv basiert auf dem Datensatz "Shampoo Sales Over a Three Year Period", der aus DataMarket stammt und von der Time Series Data Library (TSDL), erstellt von Rob Hyndman, bereitgestellt wurde.
"Shampoo Sales over a Three Year Period" Dataset lizenziert unter der DataMarket Default Open License.
Erstellen einer Konsolenanwendung
Erstellen Sie eine C# -Konsolenanwendung namens "ProductSalesAnomalyDetection". Klicken Sie auf die Schaltfläche Weiter .
Wählen Sie .NET 8 als zu verwendende Framework aus. Klicken Sie auf die Schaltfläche " Erstellen ".
Erstellen Sie ein Verzeichnis mit dem Namen "Daten " in Ihrem Projekt, um Ihre Datasetdateien zu speichern.
Installieren Sie das Microsoft.ML NuGet-Paket:
Hinweis
In diesem Beispiel wird die neueste stabile Version der erwähnten NuGet-Pakete verwendet, sofern nichts anderes angegeben ist.
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf Ihr Projekt, und wählen Sie "NuGet-Pakete verwalten" aus. Wählen Sie "nuget.org" als Paketquelle aus, wählen Sie die Registerkarte "Durchsuchen" aus, suchen Sie nach Microsoft.ML , und wählen Sie "Installieren" aus. Wählen Sie im Dialogfeld "Vorschauänderungen" die Schaltfläche "OK" und dann im Dialogfeld "Lizenzakzeptanz" die Schaltfläche "Ich stimme zu", wenn Sie den Lizenzbedingungen für die aufgeführten Pakete zustimmen. Wiederholen Sie diese Schritte für Microsoft.ML.TimeSeries.
Fügen Sie die folgenden
usingDirektiven am Anfang der Program.cs Datei hinzu:using Microsoft.ML; using ProductSalesAnomalyDetection;
Laden Sie Ihre Daten herunter
Laden Sie das Dataset herunter, und speichern Sie es im Zuvor erstellten Datenordner :
Klicken Sie mit der rechten Maustaste auf product-sales.csv , und wählen Sie "Link speichern (oder Ziel) als..." aus.
Stellen Sie sicher, dass Sie die Datei *.csv entweder im Datenordner speichern oder nachdem Sie sie an anderer Stelle gespeichert haben, die Datei *.csv in den Ordner "Daten " verschieben.
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das *.csv Datei, und wählen Sie "Eigenschaften" aus. Ändern Sie unter Erweitert den Wert von In Ausgabeordner kopieren in Kopieren, wenn neuer.
Die folgende Tabelle ist eine Datenvorschau aus Ihrer *.csv-Datei.
| Month | ProductSales |
|---|---|
| 1. Januar | 271 |
| 2. Januar | 150.9 |
| ..... | ..... |
| 1. Februar | 199.3 |
| ..... | ..... |
Erstellen von Klassen und Definieren von Pfaden
Definieren Sie als Nächstes Ihre Datenstrukturen für Eingabe- und Vorhersageklassen.
Fügen Sie Ihrem Projekt eine neue Klasse hinzu:
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt, und wählen Sie dann "Neues Element hinzufügen > " aus.
Wählen Sie im Dialogfeld "Neues Element hinzufügen" " Klasse " aus, und ändern Sie das Feld "Name " in ProductSalesData.cs. Klicken Sie anschließend auf Hinzufügen.
Die ProductSalesData.cs Datei wird im Code-Editor geöffnet.
Fügen Sie oben
usingdie folgende Direktive hinzu:using Microsoft.ML.Data;Entfernen Sie die vorhandene Klassendefinition, und fügen Sie den folgenden Code hinzu, der zwei Klassen
ProductSalesDataundProductSalesPredictionder ProductSalesData.cs Datei enthält:public class ProductSalesData { [LoadColumn(0)] public string? Month; [LoadColumn(1)] public float numSales; } public class ProductSalesPrediction { //vector to hold alert,score,p-value values [VectorType(3)] public double[]? Prediction { get; set; } }ProductSalesDataGibt eine Eingabedatenklasse an. Das LoadColumn-Attribut gibt an, welche Spalten (nach Spaltenindex) im Dataset geladen werden sollen.ProductSalesPredictionGibt die Vorhersagedatenklasse an. Bei der Anomalieerkennung besteht die Vorhersage aus einer Warnung, um anzugeben, ob eine Anomalie vorliegt, einem Rohwert und einem p-Wert. Je näher der p-Wert auf 0 liegt, desto wahrscheinlicher ist eine Anomalie aufgetreten.Erstellen Sie zwei globale Felder, um den zuletzt heruntergeladenen Datasetdateipfad und den gespeicherten Modelldateipfad zu speichern:
-
_dataPathhat den Pfad zum Dataset, der zum Trainieren des Modells verwendet wird. -
_docsizeenthält die Anzahl der Datensätze in der Datasetdatei. Sie verwenden_docSize, umpvalueHistoryLengthzu berechnen.
-
Fügen Sie der Zeile direkt unter den
usingDirektiven den folgenden Code hinzu, um diese Pfade anzugeben:string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv"); //assign the Number of records in dataset file to constant variable const int _docsize = 36;
Initialisieren der Variablen
Ersetzen Sie die
Console.WriteLine("Hello World!")Zeile durch den folgenden Code, um diemlContextVariable zu deklarieren und zu initialisieren:MLContext mlContext = new MLContext();Die MLContext-Klasse ist ein Ausgangspunkt für alle ML.NET-Vorgänge, und das Initialisieren von
mlContexterstellt eine neue ML.NET-Umgebung, die für die Modell-Erstellungs-Workflow-Objekte freigegeben werden kann. Es ist konzeptionell ähnlich wieDBContextim Entity Framework.
Laden der Daten
Daten in ML.NET werden als IDataView-Schnittstelle dargestellt.
IDataView ist eine flexible, effiziente Möglichkeit, tabellarische Daten (numerisch und Text) zu beschreiben. Daten können aus einer Textdatei oder aus anderen Quellen (z. B. SQL-Datenbank- oder Protokolldateien) in ein IDataView Objekt geladen werden.
Fügen Sie nach dem Erstellen der
mlContextVariablen den folgenden Code hinzu:IDataView dataView = mlContext.Data.LoadFromTextFile<ProductSalesData>(path: _dataPath, hasHeader: true, separatorChar: ',');Das LoadFromTextFile() -Element definiert das Datenschema und liest es in der Datei. Es nimmt die Datenpfadvariablen auf und gibt einen
IDataViewzurück.
Anomalieerkennung in Zeitreihen
Anomalieerkennung kennzeichnet unerwartete oder ungewöhnliche Ereignisse oder Verhaltensweisen. Es gibt Hinweise, wo man nach Problemen sucht und ihnen hilft, die Frage "Ist dies seltsam?" zu beantworten.

Anomalieerkennung ist der Prozess der Erkennung von Zeitreihen-Datenausreißern; verweist auf eine bestimmte Eingabezeitreihe, in der das Verhalten nicht erwartungsgemäß oder "seltsam" ist.
Anomalieerkennung kann auf viele Arten nützlich sein. Beispiel:
Wenn Sie ein Auto haben, möchten Sie vielleicht wissen: Ist dieser Ölstandsanzeige-Wert normal oder habe ich ein Leck? Wenn Sie den Stromverbrauch überwachen, sollten Sie wissen: Gibt es einen Ausfall?
Es gibt zwei Arten von Zeitreihenanomalien, die erkannt werden können:
Spitzen deuten auf temporäre Ausbrüche anomalen Verhaltens im System hin.
Änderungspunkte geben den Beginn der dauerhaften Änderungen im Laufe der Zeit im System an.
In ML.NET sind die Algorithmen für die IID-Spitzenerkennung oder IID-Änderungspunkterkennung für unabhängige und identisch verteilte Datasets geeignet. Sie gehen davon aus, dass ihre Eingabedaten eine Abfolge von Datenpunkten sind, die unabhängig von einer stationären Verteilung entnommen werden.
Im Gegensatz zu den Modellen in den anderen Lernprogrammen arbeiten die Zeitreihen-Anomaliedetektortransformationen direkt auf Eingabedaten. Die IEstimator.Fit() Methode benötigt keine Schulungsdaten, um die Transformation zu erzeugen. Es benötigt jedoch das Datenschema, das von einer Datenansicht, die aus einer leeren Liste von ProductSalesData generiert wurde, bereitgestellt wird.
Sie analysieren dieselben Produktumsatzdaten, um Spitzen und Änderungspunkte zu erkennen. Der Erstellungs- und Schulungsmodellprozess ist für die Erkennung von Spitzen- und Änderungspunkten identisch; Der Hauptunterschied ist der spezifische Erkennungsalgorithmus, der verwendet wird.
Detektion von Spitzen
Ziel der Spitzenerkennung ist es, plötzliche, aber temporäre Brüche zu identifizieren, die sich erheblich von den meisten Zeitreihen-Datenwerten unterscheiden. Es ist wichtig, diese verdächtigen seltenen Elemente, Ereignisse oder Beobachtungen rechtzeitig zu erkennen, um minimiert zu werden. Der folgende Ansatz kann verwendet werden, um eine Vielzahl von Anomalien zu erkennen, z. B. Ausfälle, Cyberangriffe oder virale Webinhalte. Die folgende Abbildung ist ein Beispiel für Spitzen in einem Zeitreihen-Dataset:
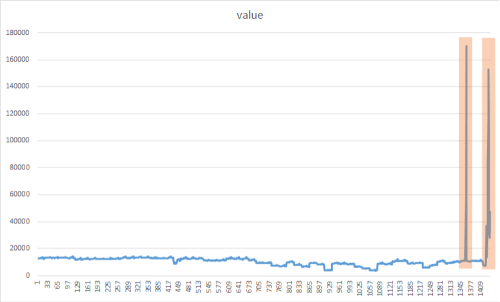
Hinzufügen der CreateEmptyDataView()-Methode
Fügen Sie die folgende Methode hinzu:Program.cs
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
Das Erzeugt ein leeres CreateEmptyDataView() Datenansichtsobjekt mit dem richtigen Schema, das als Eingabe für die IEstimator.Fit() Methode verwendet werden soll.
Erstelle die DetectSpike()-Methode
Die DetectSpike()-Methode:
- Erstellt die Transformation aus der Schätzung.
- Erkennt Spitzen basierend auf historischen Umsatzdaten.
- Zeigt die Ergebnisse an.
Erstellen Sie die
DetectSpike()Methode am ende der Program.cs Datei mit dem folgenden Code:DetectSpike(MLContext mlContext, int docSize, IDataView productSales) { }Verwenden Sie den IidSpikeEstimator , um das Modell für die Spitzenerkennung zu trainieren. Fügen Sie sie der
DetectSpike()Methode mit dem folgenden Code hinzu:var iidSpikeEstimator = mlContext.Transforms.DetectIidSpike(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, pvalueHistoryLength: docSize / 4);Erstellen Sie die Spitzenerkennungstransformation, indem Sie folgendes als nächste Codezeile in der
DetectSpike()Methode hinzufügen:Tipp
Die
confidenceParameterpvalueHistoryLengthwirken sich auf die Erkennung von Spitzen aus.confidencebestimmt, wie sensibel Ihr Modell spitzen ist. Je niedriger das Vertrauen ist, desto wahrscheinlicher ist es, dass der Algorithmus "kleinere" Spitzen erkennt. DerpvalueHistoryLengthParameter definiert die Anzahl der Datenpunkte in einem gleitenden Fenster. Der Wert dieses Parameters ist in der Regel ein Prozentsatz des gesamten Datasets. Je niedriger derpvalueHistoryLength, desto schneller vergisst das Modell vorherige große Spitzen.ITransformer iidSpikeTransform = iidSpikeEstimator.Fit(CreateEmptyDataView(mlContext));Fügen Sie die folgende Codezeile hinzu, um die
productSalesDaten als nächste Zeile in derDetectSpike()Methode zu transformieren:IDataView transformedData = iidSpikeTransform.Transform(productSales);Der vorherige Code verwendet die Transform()- Methode, um Vorhersagen für mehrere Eingabezeilen eines Datasets zu erstellen.
Konvertieren Sie Ihre
transformedDataDaten mithilfe derIEnumerable-Methode mit dem folgenden Code in eine stark typierte Anzeige.var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Erstellen Sie eine Kopfzeile mit dem folgenden Console.WriteLine() Code:
Console.WriteLine("Alert\tScore\tP-Value");Sie zeigen die folgenden Informationen in Ihren Spitzenerkennungsergebnissen an.
-
Alertgibt eine Spitzenwarnung für einen bestimmten Datenpunkt an. -
Scoreist derProductSalesWert für einen bestimmten Datenpunkt im Dataset. -
P-ValueDas "P" steht für Wahrscheinlichkeit. Je näher der p-Wert auf 0 liegt, desto wahrscheinlicher ist der Datenpunkt eine Anomalie.
-
Verwenden Sie den folgenden Code, um durch die
predictionsIEnumerablezu iterieren und die Ergebnisse anzuzeigen:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}"; if (p.Prediction[0] == 1) { results += " <-- Spike detected"; } Console.WriteLine(results); } } Console.WriteLine("");Fügen Sie den Aufruf der
DetectSpike()Methode unterhalb des Aufrufs derLoadFromTextFile()Methode hinzu:DetectSpike(mlContext, _docsize, dataView);
Ergebnisse der Spitzenerkennung
Ihre Ergebnisse sollten dem Folgenden ähnlich sein. Während der Verarbeitung werden Nachrichten angezeigt. Möglicherweise werden Warnmeldungen oder Verarbeitungsnachrichten angezeigt. Einige der Nachrichten wurden aus den folgenden Ergebnissen aus Gründen der Übersichtlichkeit entfernt.
Detect temporary changes in pattern
=============== Training the model ===============
=============== End of training process ===============
Alert Score P-Value
0 271.00 0.50
0 150.90 0.00
0 188.10 0.41
0 124.30 0.13
0 185.30 0.47
0 173.50 0.47
0 236.80 0.19
0 229.50 0.27
0 197.80 0.48
0 127.90 0.13
1 341.50 0.00 <-- Spike detected
0 190.90 0.48
0 199.30 0.48
0 154.50 0.24
0 215.10 0.42
0 278.30 0.19
0 196.40 0.43
0 292.00 0.17
0 231.00 0.45
0 308.60 0.18
0 294.90 0.19
1 426.60 0.00 <-- Spike detected
0 269.50 0.47
0 347.30 0.21
0 344.70 0.27
0 445.40 0.06
0 320.90 0.49
0 444.30 0.12
0 406.30 0.29
0 442.40 0.21
1 580.50 0.00 <-- Spike detected
0 412.60 0.45
1 687.00 0.01 <-- Spike detected
0 480.30 0.40
0 586.30 0.20
0 651.90 0.14
Änderungspunkterkennung
Change points sind dauerhafte Änderungen in einer Zeitreihenereignisstrom-Verteilung von Werten, z. B. Niveauänderungen und Trends. Diese dauerhaften Änderungen dauern viel länger als spikes und könnten auf katastrophale Ereignisse hinweisen.
Change points sind in der Regel nicht für das bloße Auge sichtbar, können aber in Ihren Daten anhand von Ansätzen wie der folgenden Methode erkannt werden. Die folgende Abbildung ist ein Beispiel für eine Änderungspunkterkennung:
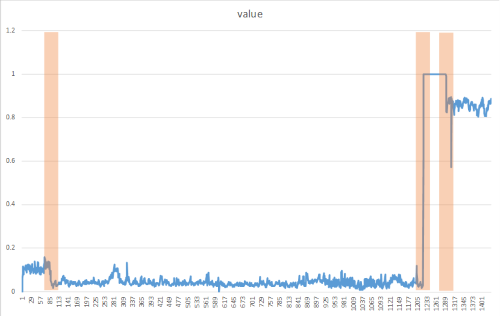
Erstellen Sie die Methode DetectChangepoint()
Die DetectChangepoint() Methode führt die folgenden Aufgaben aus:
- Erstellt die Transformation aus der Schätzung.
- Erkennt Änderungspunkte basierend auf historischen Umsatzdaten.
- Zeigt die Ergebnisse an.
Erstellen Sie die
DetectChangepoint()Methode direkt nach derDetectSpike()Methodendeklaration mithilfe des folgenden Codes:void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales) { }Erstellen Sie den iidChangePointEstimator in der
DetectChangepoint()Methode mit dem folgenden Code:var iidChangePointEstimator = mlContext.Transforms.DetectIidChangePoint(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, changeHistoryLength: docSize / 4);Erstellen Sie wie zuvor die Transformation aus der Schätzung, indem Sie die folgende Codezeile in der
DetectChangePoint()Methode hinzufügen:Tipp
Die Erkennung von Änderungspunkten erfolgt mit einer leichten Verzögerung, da das Modell sicherstellen muss, dass die aktuelle Abweichung eine dauerhafte Änderung ist und nicht nur einige zufällige Spitzen vor dem Erstellen einer Warnung. Der Wert dieser Verzögerung ist gleich dem
changeHistoryLengthParameter. Durch das Erhöhen des Werts dieses Parameters werden zwar Änderungen bei beständigeren Veränderungen erkannt, jedoch mit einer längeren Verzögerung bei den Warnmeldungen.var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));Verwenden Sie die
Transform()Methode, um die Daten zu transformieren, indem Sie den folgenden Code hinzufügen:DetectChangePoint()IDataView transformedData = iidChangePointTransform.Transform(productSales);Wie sie bereits zuvor ausgeführt haben, konvertieren Sie Sie
transformedDatamit derIEnumerableMethode mit dem folgenden Code stark typisch in eine stark typierteCreateEnumerable()Anzeige:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Erstellen Sie eine Anzeigekopfzeile mit dem folgenden Code als nächste Zeile in der
DetectChangePoint()Methode:Console.WriteLine("Alert\tScore\tP-Value\tMartingale value");In den Ergebnissen der Änderungspunkterkennung werden die folgenden Informationen angezeigt:
-
Alertgibt eine Änderungspunktbenachrichtigung für einen bestimmten Datenpunkt an. -
Scoreist derProductSalesWert für einen bestimmten Datenpunkt im Dataset. -
P-ValueDas "P" steht für Wahrscheinlichkeit. Je näher der P-Wert auf 0 liegt, desto wahrscheinlicher ist der Datenpunkt eine Anomalie. -
Martingale valuewird verwendet, um zu identifizieren, wie "seltsam" ein Datenpunkt ist, basierend auf der Abfolge von P-Werten.
-
Iterieren Sie durch die
predictionsIEnumerableund zeigen Sie die Ergebnisse mit dem folgenden Code an:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}"; if (p.Prediction[0] == 1) { results += " <-- alert is on, predicted changepoint"; } Console.WriteLine(results); } } Console.WriteLine("");Fügen Sie den folgenden Aufruf der
DetectChangepoint()Methode nach dem Aufruf derDetectSpike()Methode hinzu:DetectChangepoint(mlContext, _docsize, dataView);
Ergebnisse der Änderungspunkterkennung
Ihre Ergebnisse sollten dem Folgenden ähnlich sein. Während der Verarbeitung werden Nachrichten angezeigt. Möglicherweise werden Warnmeldungen oder Verarbeitungsnachrichten angezeigt. Einige Nachrichten wurden aus den folgenden Ergebnissen aus Gründen der Übersichtlichkeit entfernt.
Detect Persistent changes in pattern
=============== Training the model Using Change Point Detection Algorithm===============
=============== End of training process ===============
Alert Score P-Value Martingale value
0 271.00 0.50 0.00
0 150.90 0.00 2.33
0 188.10 0.41 2.80
0 124.30 0.13 9.16
0 185.30 0.47 9.77
0 173.50 0.47 10.41
0 236.80 0.19 24.46
0 229.50 0.27 42.38
1 197.80 0.48 44.23 <-- alert is on, predicted changepoint
0 127.90 0.13 145.25
0 341.50 0.00 0.01
0 190.90 0.48 0.01
0 199.30 0.48 0.00
0 154.50 0.24 0.00
0 215.10 0.42 0.00
0 278.30 0.19 0.00
0 196.40 0.43 0.00
0 292.00 0.17 0.01
0 231.00 0.45 0.00
0 308.60 0.18 0.00
0 294.90 0.19 0.00
0 426.60 0.00 0.00
0 269.50 0.47 0.00
0 347.30 0.21 0.00
0 344.70 0.27 0.00
0 445.40 0.06 0.02
0 320.90 0.49 0.01
0 444.30 0.12 0.02
0 406.30 0.29 0.01
0 442.40 0.21 0.01
0 580.50 0.00 0.01
0 412.60 0.45 0.01
0 687.00 0.01 0.12
0 480.30 0.40 0.08
0 586.30 0.20 0.03
0 651.90 0.14 0.09
Glückwunsch! Sie haben nun erfolgreich Machine Learning-Modelle zum Erkennen von Spitzen und Änderungspunktanomalien in Verkaufsdaten erstellt.
Den Quellcode für dieses Lernprogramm finden Sie im Repository dotnet/samples .
In diesem Tutorial haben Sie Folgendes gelernt:
- Laden der Daten
- Trainieren des Modells für die Spitzenanomalieerkennung
- Erkennen von Spitzenanomalien mit dem trainierten Modell
- Trainieren des Modells für die Anomalieerkennung von Änderungspunkten
- Erkennen von Änderungspunktanomalien mit dem trainierten Modus
Nächste Schritte
Sehen Sie sich das GitHub-Repository für Machine Learning-Beispiele an, um ein Beispiel zur Anomalieerkennung von Saisonalitätsdaten zu untersuchen.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.