Verknüpfte Dienste in Azure Data Factory und Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, was verknüpfte Dienste sind, wie sie im JSON-Format definiert und in Azure Data Factory und Azure Synapse Analytics verwendet werden.
Weitere Informationen finden Sie im Einführungsartikel zu Azure Data Factory oder Azure Synapse.
Übersicht
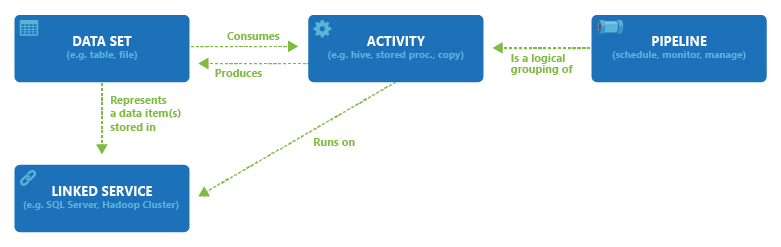
Azure Data Factory und Azure Synapse Analytics können eine oder mehrere Pipelines umfassen. Bei einer Pipeline handelt es sich um eine logische Gruppierung von Aktivitäten, die zusammen eine Aufgabe bilden. Die Aktivitäten in einer Pipeline definieren Aktionen, die Sie auf Ihre Daten anwenden. Sie können beispielsweise mit einer Kopieraktivität Daten aus SQL Server in Azure Blob Storage kopieren. Anschließend könnten Sie eine Hive-Aktivität verwenden, die ein Hive-Skript für einen Azure HDInsight-Cluster ausführt, um Daten aus dem Blob Storage zu verarbeiten, um Ausgabedaten zu produzieren. Schließlich könnten Sie die Ausgabedaten mit einer zweiten Kopieraktivität in Azure Synapse Analytics kopieren, auf dessen Basis Business Intelligence-Berichtslösungen (BI) erstellt werden. Weitere Informationen zu Pipelines und Aktivitäten finden Sie unter Pipelines und Aktivitäten.
Ein Dataset ist eine benannte Ansicht von Daten, die einfach auf die Daten verweist, die Sie in Ihren Aktivitäten als Ein- und Ausgabe verwenden möchten.
Bevor Sie ein Dataset erstellen, müssen Sie einen verknüpften Dienst erstellen, um Ihren Datenspeicher mit der Data Factory oder einem Synapse-Arbeitsbereich zu verknüpfen. Verknüpfte Dienste ähneln Verbindungszeichenfolgen, mit denen die Verbindungsinformationen definiert werden, die der Dienst zum Herstellen einer Verbindung mit externen Ressourcen benötigt. Sie können sich dies wie folgt vorstellen: Das Dataset stellt die Struktur der Daten innerhalb des verknüpften Datenspeichers dar, und der verknüpfte Dienst definiert die Verbindung mit der Datenquelle. Ein mit Azure Storage verknüpfter Dienst verbindet z. B. ein Speicherkonto mit dem Dienst. Ein Azure-Blob-Dataset repräsentiert den Blobcontainer und den Ordner innerhalb des Azure Storage-Kontos, das die zu verarbeitenden Eingabeblobs enthält.
Hier ist ein Beispielszenario. Um Daten aus dem Blobspeicher in eine SQL-Datenbank zu kopieren, erstellen Sie zwei verknüpfte Dienste: Azure Storage und Azure SQL-Datenbank. Erstellen Sie anschließend zwei Datasets: Azure-Blobdataset (das sich auf den mit Azure Storage verknüpften Dienst bezieht) und Azure SQL-Tabellendataset (das sich auf den mit Azure SQL-Datenbank verknüpften Dienst bezieht). Die mit Azure Storage und Azure SQL-Datenbank verknüpften Dienste enthalten Verbindungszeichenfolgen, die der Dienst zur Laufzeit nutzt, um eine Verbindung mit Ihrer Instanz von Azure Storage bzw. Azure SQL-Datenbank herzustellen. Das Azure-Blobdataset gibt den Blobcontainer und Blobordner an, der die Eingabeblobs in Ihrer Blob Storage-Instanz enthält. Das Azure SQL-Tabellendataset gibt die SQL-Tabelle in Ihrer SQL-Datenbank an, in die die Daten kopiert werden sollen.
Das folgende Diagramm zeigt die Beziehung zwischen Pipeline, Aktivität, Dataset und verknüpftem Dienst im Dienst:
Verknüpfter Dienst mit Benutzeroberfläche
Um einen neuen verknüpften Dienst in Azure Data Factory Studio zu erstellen, wählen Sie die Registerkarte Verwalten und dann Verknüpfte Dienste aus, auf der alle vorhandenen verknüpften Dienste angezeigt werden, die Sie definiert haben. Wählen Sie + Neu aus, um einen neuen verknüpften Dienst zu erstellen.
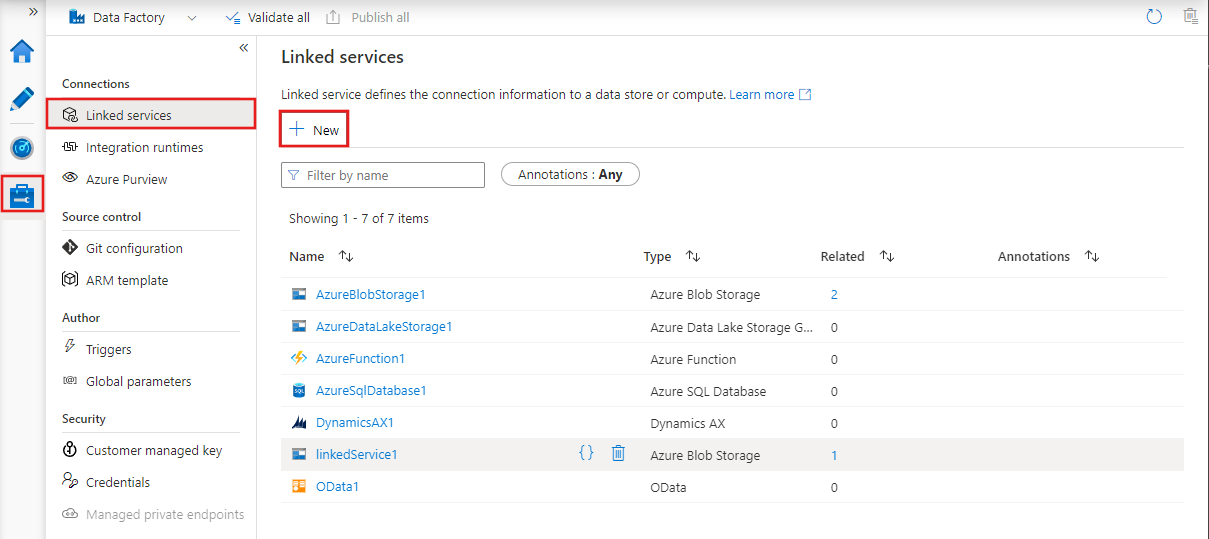
Nachdem Sie + New ausgewählt haben, um einen neuen verknüpften Dienst zu erstellen, können Sie einen der unterstützten Connectors auswählen und dessen Details entsprechend konfigurieren. Anschließend können Sie den verknüpften Dienst in allen Pipelines verwenden, die Sie erstellen.


JSON-Text für verknüpfte Dienste
Ein verknüpfter Dienst wird wie folgt im JSON-Format definiert:
{
"name": "<Name of the linked service>",
"properties": {
"type": "<Type of the linked service>",
"typeProperties": {
"<data store or compute-specific type properties>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
In der folgenden Tabelle werden die Eigenschaften im obigen JSON-Code beschrieben:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| name | Name des verknüpften Diensts. Siehe Benennungsregeln. | Ja |
| type | Typ des verknüpften Diensts. Beispiel: AzureBlobStorage (Datenspeicher) oder AzureBatch (Compute). Siehe die Beschreibung von „typeProperties“. | Ja |
| typeProperties | Die Typeigenschaften unterscheiden sich für jeden Datenspeicher- oder Computetyp. Informationen zu den unterstützten Datenspeichertypen und ihren Typeigenschaften finden Sie unter Unterstützte Datenspeicher und Formate. Navigieren Sie zum Artikel über den Datenspeicherconnector, um mehr über die für einen Datenspeicher spezifischen Typeigenschaften zu erfahren. Informationen zu den unterstützten Computetypen und ihren Typeigenschaften finden Sie unter Verknüpfte Computedienste. |
Ja |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Sie können die Azure Integration Runtime oder selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel für einen verknüpften Dienst
Der folgende verknüpfte Dienst ist ein mit Azure Blob Storage verknüpfter Dienst. Beachten Sie, dass der Typ auf „Azure Blob Storage“ festgelegt ist. Die Typeigenschaften für den verknüpften Azure Blob Storage-Dienst umfassen eine Verbindungszeichenfolge. Der Dienst verwendet diese Verbindungszeichenfolge, um zur Laufzeit eine Verbindung mit dem Datenspeicher herzustellen.
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Erstellen von verknüpften Diensten
Verknüpfte Dienste sowie sämtliche Aktivitäten, Datasets oder Datenflüsse, die auf diese verweisen, können auf der Benutzeroberfläche von Azure Data Factory über den Verwaltungshub erstellt werden.
Sie können verknüpfte Dienste mit einem dieser Tools oder SDKs erstellen: .NET API, PowerShell, REST API, Azure Resource Manager Template und Azure Portal.
Beim Erstellen eines verknüpften Diensts benötigt der Benutzer eine entsprechende Autorisierung für den vorgesehenen Dienst. Wenn kein ausreichender Zugriff gewährt wird, kann der Benutzer die verfügbaren Ressourcen nicht sehen und muss die Option für die manuelle Eingabe verwenden.
Verknüpfte Dienste von Datenspeichern
Die Liste der unterstützten Datenspeicher finden Sie im Artikel Übersicht über Connectors. Wählen Sie auf einen Datenspeicher, um mehr über die unterstützten Verbindungseigenschaften zu erfahren.
Verknüpfte Computedienste
Weitere Informationen zu den verschiedenen Compute-Umgebungen, mit denen Sie sich von Ihrem Dienst aus verbinden können, sowie zu den verschiedenen Konfigurationen finden Sie unter Unterstützte Compute-Umgebungen.
Zugehöriger Inhalt
In den folgenden Tutorials finden Sie schrittweise Anleitungen zum Erstellen von Pipelines und Datasets mit einem dieser Tools oder SDKs.