Kopieren von Daten in oder aus Azure Data Explorer mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- und Synapse Analytics-Pipelines verwenden, um Daten in oder aus Azure Data Explorer zu kopieren. Er baut auf dem Artikel zur Übersicht über die Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Tipp
Weitere allgemeine Informationen zur Integration von Azure Data Explorer mit dem Dienst finden Sie unter Integrieren von Azure Data Explorer.
Unterstützte Funktionen
Dieser Azure Data Explorer-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② |
| Zuordnungsdatenfluss (Quelle/Senke) | ① |
| Lookup-Aktivität | ① ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Sie können Daten aus jedem unterstützten Quelldatenspeicher in Azure Data Explorer kopieren. Zudem können Sie Daten aus Azure Data Explorer in jeden unterstützten Senkendatenspeicher kopieren. Die für die Kopieraktivität als Quellen oder Senken unterstützten Datenspeicher finden Sie in der Tabelle Unterstützte Datenspeicher.
Hinweis
Das Kopieren von Daten in oder aus Azure Data Explorer über einen lokalen Datenspeicher mithilfe der selbstgehosteten Integration Runtime wird in Version 3.14 und höher unterstützt.
Mit dem Azure Data Explorer-Connector ist Folgendes möglich:
- Kopieren Sie Daten mithilfe der Authentifizierung mit Microsoft Entra-Anwendungstoken mit einem Dienstprinzipal.
- Als Quelle: Abrufen von Daten mithilfe einer KQL-Abfrage (Kusto)
- Als Senke: Anfügen von Daten an eine Zieltabelle
Erste Schritte
Tipp
Eine exemplarische Vorgehensweise zur Verwendung des Azure Data Explorer-Connectors finden Sie unter Kopieren von Daten in/aus Azure Data Explorer und Massenkopieren aus einer Datenbank zu Azure Data Explorer.
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts für Azure Data Explorer über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen verknüpften Dienst für Azure Data Explorer auf der Benutzeroberfläche im Azure-Portal zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus und klicken Sie dann auf „Neu“:
Suchen Sie nach Explorer, und wählen Sie den Connector für Azure Data Explorer (Kusto) aus.
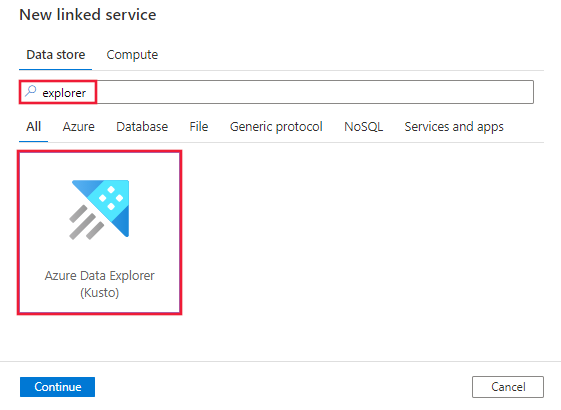
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
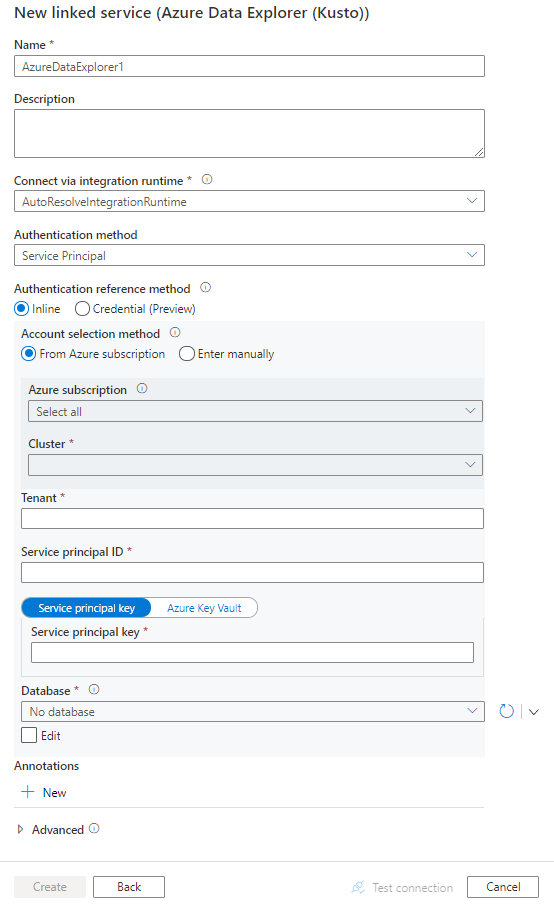
Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Entitäten speziell für den Azure Data Explorer-Connector verwendet werden.
Eigenschaften des verknüpften Diensts
Der Azure Data Explorer-Connector unterstützt die folgenden Authentifizierungstypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten:
- Dienstprinzipalauthentifizierung
- Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
- Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Dienstprinzipalauthentifizierung
Zur Verwendung der Dienstprinzipalauthentifizierung führen Sie die folgenden Schritte aus, um einen Dienstprinzipal zu erstellen und Berechtigungen zu erteilen:
Registrieren einer Anwendung bei der Microsoft Identity Platform. Eine Anleitung finden Sie unter Schnellstart: Registrieren einer Anwendung bei Microsoft Identity Platform. Notieren Sie sich die folgenden Werte, die Sie zum Definieren des verknüpften Diensts verwenden können:
- Anwendungs-ID
- Anwendungsschlüssel
- Mandanten-ID
Erteilen Sie dem Dienstprinzipal die geeigneten Berechtigungen in Azure Data Explorer. Unter Verwalten der Berechtigungen für Datenbanken in Azure Data Explorer finden Sie ausführliche Informationen zu Rollen und Berechtigungen sowie zur Verwaltung von Berechtigungen. Gehen Sie wie folgt vor:
- Weisen Sie der Datenbank als Quelle mindestens die Rolle Database viewer (Anzeigender Datenbankbenutzer) zu.
- Weisen Sie der Datenbank als Senke mindestens die Rolle Datenbankbenutzer zu.
Hinweis
Wenn Sie die Benutzeroberfläche für die Erstellung verwenden, wird standardmäßig Ihr Anmeldebenutzerkonto verwendet, um Azure Data Explorer-Cluster, -Datenbanken und -Tabellen aufzulisten. Sie können die Objekte mithilfe des Dienstprinzipals auflisten, indem Sie auf das Dropdownfeld neben der Aktualisierungsschaltfläche klicken, oder den Namen manuell eingeben, wenn Sie für diese Vorgänge nicht berechtigt sind.
Folgende Eigenschaften werden für den mit Azure Data Explorer verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureDataExplorer festgelegt werden. | Ja |
| endpoint | Endpunkt-URL des Azure Data Explorer-Clusters im Format https://<clusterName>.<regionName>.kusto.windows.net |
Ja |
| database | Name der Datenbank | Ja |
| tenant | Geben Sie die Mandanteninformationen (Domänenname oder Mandanten-ID) für Ihre Anwendung an. Dies wird in der Kusto-Verbindungszeichenfolge als „Autoritäts-ID“ bezeichnet. Sie können ab abrufen, indem Sie im Azure-Portal mit dem Mauszeiger auf den Bereich oben rechts zeigen. | Ja |
| servicePrincipalId | Geben Sie die Client-ID der Anwendung an. Dies wird in der Kusto-Verbindungszeichenfolge als „Client-ID der Microsoft Entra-Anwendung“ bezeichnet. | Ja |
| servicePrincipalKey | Geben Sie den Schlüssel der Anwendung an. Dies wird in der Kusto-Verbindungszeichenfolge als „Microsoft Entra-Anwendungsschlüssel“ bezeichnet. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern, oder verweisen Sie auf sicher in Azure Key Vault gespeicherte Daten. | Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel: Verwenden der Dienstprinzipal-Schlüsselauthentifizierung
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
Weitere Informationen zu verwalteten Identitäten für Azure-Ressourcen finden Sie unter Verwaltete Identitäten für Azure-Ressourcen.
Führen Sie die folgenden Schritte zum Gewähren von Berechtigungen aus, um die Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität zu verwenden:
Rufen Sie die Informationen zur verwalteten Identität ab, indem Sie den Wert der Objekt-ID der verwalteten Identität kopieren, der zusammen mit Ihrer Factory oder Ihrem Synapse-Arbeitsbereich generiert wurde.
Erteilen Sie der verwalteten Identität die geeigneten Berechtigungen in Azure Data Explorer. Unter Verwalten der Berechtigungen für Datenbanken in Azure Data Explorer finden Sie ausführliche Informationen zu Rollen und Berechtigungen sowie zur Verwaltung von Berechtigungen. Gehen Sie wie folgt vor:
- Weisen Sie der Datenbank als Quelle die Rolle Anzeigender Datenbankbenutzer zu.
- Weisen Sie der Datenbank als Senke die Rollen Datenbankerfasser und Anzeigender Datenbankbenutzer zu.
Hinweis
Wenn Sie die Benutzeroberfläche für die Erstellung verwenden, wird Ihr Anmeldebenutzerkonto verwendet, um Azure Data Explorer-Cluster, -Datenbanken und -Tabellen aufzulisten. Geben Sie den Namen manuell ein, wenn Sie keine Berechtigung für diese Vorgänge besitzen.
Folgende Eigenschaften werden für den mit Azure Data Explorer verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureDataExplorer festgelegt werden. | Ja |
| endpoint | Endpunkt-URL des Azure Data Explorer-Clusters im Format https://<clusterName>.<regionName>.kusto.windows.net |
Ja |
| database | Name der Datenbank | Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel: Verwenden der Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Weitere Informationen zu verwalteten Identitäten für Azure-Ressourcen finden Sie unter Verwaltete Identitäten für Azure-Ressourcen
Führen Sie die folgenden Schritte aus, um die Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität zu verwenden:
Erstellen Sie eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten, und gewähren Sie ihnen Berechtigungen in Azure Data Explorer. Unter Verwalten der Berechtigungen für Datenbanken in Azure Data Explorer finden Sie ausführliche Informationen zu Rollen und Berechtigungen sowie zur Verwaltung von Berechtigungen. Gehen Sie wie folgt vor:
- Weisen Sie der Datenbank als Quelle mindestens die Rolle Database viewer (Anzeigender Datenbankbenutzer) zu.
- Weisen Sie der Datenbank als Senke mindestens die Rolle Database ingestor (Datenbankerfasser) zu.
Weisen Sie Ihrer Data Factory oder Ihrem Synapse-Arbeitsbereich eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten zu, und erstellen Sie Anmeldeinformationen für jede benutzerseitig zugewiesene verwaltete Identität.
Folgende Eigenschaften werden für den mit Azure Data Explorer verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureDataExplorer festgelegt werden. | Ja |
| endpoint | Endpunkt-URL des Azure Data Explorer-Clusters im Format https://<clusterName>.<regionName>.kusto.windows.net |
Ja |
| database | Name der Datenbank | Ja |
| Anmeldeinformationen | Geben Sie die benutzerseitig zugewiesene verwaltete Identität als Anmeldeinformationsobjekt an. | Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel: Verwenden der Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält die Eigenschaften, die mit dem Azure Data Explorer-Dataset unterstützt werden.
Legen Sie zum Kopieren von Daten in Azure Data Explorer die type-Eigenschaft des Datasets auf AzureDataExplorerTable fest.
Folgende Eigenschaften werden unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureDataExplorerTable festgelegt werden. | Ja |
| table | Der Name der Tabelle, auf die der verknüpfte Dienst verweist. | Quelle: Ja, Senke: Nein |
Beispiel für Dataseteigenschaften:
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste der verfügbaren Abschnitte und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Pipelines und Aktivitäten. Dieser Abschnitt enthält eine Liste der Eigenschaften, die mit Azure Data Explorer-Quellen und -Senken unterstützt werden.
Azure Data Explorer als Quelle
Legen Sie zum Kopieren von Daten aus Azure Data Explorer die type-Eigenschaft in der Quelle der Kopieraktivität auf AzureDataExplorerSource fest. Folgende Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf Folgendes festgelegt werden: AzureDataExplorerSource | Ja |
| Abfrage | Eine in einem KQL-Format angegebene schreibgeschützte Anforderung. Verwenden Sie die benutzerdefinierte KQL-Abfrage als Verweis. | Ja |
| queryTimeout | Die Wartezeit vor dem Timeout der Abfrageanforderung. Der Standardwert ist 10 Minuten (00:10:00), der zulässige maximale Wert 1 Stunde (01:00:00). | Nein |
| noTruncation | Gibt an, ob das zurückgegebene Resultset abgeschnitten werden soll. Standardmäßig wird das Ergebnis nach 500.000 Datensätzen oder 64 Megabyte (MB) abgeschnitten. Das Abschneiden wird dringend empfohlen, um das richtige Verhalten für die Aktivität sicherzustellen. | Nein |
Hinweis
Standardmäßig ist die Azure Data Explorer-Quelle auf 500.000 Datensätze oder 64 MB begrenzt. Um alle Datensätze ohne Abschneiden abzurufen, können Sie set notruncation; am Anfang Ihrer Abfrage angeben. Weitere Informationen finden Sie unter Abfragegrenzwerte.
Beispiel:
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
Azure Data Explorer als Senke
Legen Sie zum Kopieren von Daten in Azure Data Explorer die type-Eigenschaft in der Senke der Kopieraktivität auf AzureDataExplorerSink fest. Folgende Eigenschaften werden im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Senke der Kopieraktivität muss auf Folgendes festgelegt werden: AzureDataExplorerSink. | Ja |
| ingestionMappingName | Der Name einer vorab erstellten Zuordnung für eine Kusto-Tabelle. Zum Zuordnen der Spalten aus der Quelle zu Azure Data Explorer (gilt für alle unterstützten Quellspeicher und -formate, einschließlich der Formate CSV, JSON und Avro) können Sie die Kopieraktivität Spaltenzuordnung (implizit anhand des Namens oder explizit wie konfiguriert) und/oder Azure Data Explorer-Zuordnungen verwenden. | Nein |
| additionalProperties | Ein Eigenschaftenbehälter, mit dem Sie beliebige Erfassungseigenschaften angeben können, die nicht bereits von der Azure Data Explorer-Senke festgelegt sind. Dies kann besonders nützlich sein, um Erfassungstags anzugeben. Weitere Informationen finden Sie in der Dokumentation zur Datenerfassung im Azure Data Explorer. | Nein |
Beispiel:
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Eigenschaften von Mapping Data Flow
Beim Transformieren von Daten im Zuordnungsdatenfluss können Sie in Tabellen Azure Data Explorer lesen und in diese schreiben. Weitere Informationen finden Sie unter Quellentransformation und Senkentransformation in Zuordnungsdatenflüssen. Sie können ein Azure Data Explorer-Dataset oder ein Inlinedataset als Quelle und Senkentyp verwenden.
Quellentransformation
In der folgenden Tabelle werden die von der Azure Data Explorer-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Tabelle | Wenn Sie „Tabelle“ als Eingabe auswählen, holt der Datenfluss alle Daten aus der Tabelle, die im Azure Data Explorer-Datenset oder in den Quelloptionen angegeben ist, wenn ein Inlinedataset verwendet wird. | Nein | String | (nur für Inlinedataset) tableName |
| Abfrage | Eine in einem KQL-Format angegebene schreibgeschützte Anforderung. Verwenden Sie die benutzerdefinierte KQL-Abfrage als Verweis. | Nein | String | Abfrage |
| Timeout | Die Wartezeit vor dem Timeout der Abfrageanforderung. Die Standardeinstellung ist 172.000 Minuten (2 Tage). | Nein | Integer | timeout |
Azure Data Explorer-Quellskriptbeispiele
Wenn Sie ein Azure Data Explorer-Dataset als Quelltyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
Wenn Sie ein Inlinedataset verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
Senkentransformation
In der folgenden Tabelle werden die von der Azure Data Explorer-Senke unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Einstellungen bearbeiten. Bei Verwendung eines Inlinedatasets werden zusätzliche Einstellungen angezeigt. Diese entsprechen den Eigenschaften, die im Abschnitt zu den Dataseteigenschaften beschrieben sind.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Aktion table | Bestimmt, ob die Zieltabelle vor dem Schreiben neu erstellt werden soll oder alle Zeilen aus der Zieltabelle entfernt werden sollen. - Keine: Es wird keine Aktion an der Tabelle vorgenommen. - Neu erstellen: Die Tabelle wird gelöscht und neu erstellt. Erforderlich, wenn eine neue Tabelle dynamisch erstellt wird. - Abschneiden: Alle Zeilen werden aus der Zieltabelle entfernt. |
Nein | true oder false |
Neu erstellen truncate |
| Pre- und Post-SQL-Skripts | Geben Sie mehrere Skripte mit Kusto-Steuerungsbefehlen an, die ausgeführt werden, bevor Daten in Ihre Senkendatenbank geschrieben werden (Vorverarbeitung) und nachdem dies geschieht (Nachbearbeitung). | Nein | String | preSQLs; postSQLs |
| Timeout | Die Wartezeit vor dem Timeout der Abfrageanforderung. Die Standardeinstellung ist 172.000 Minuten (2 Tage). | Nein | Integer | timeout |
Azure Data Explorer-Senkenskriptbeispiele
Wenn Sie ein Azure Data Explorer-Dataset als Senkentyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Wenn Sie ein Inlinedataset verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Eigenschaften der Lookup-Aktivität
Weitere Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität in Azure Data Factory.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die die Copy-Aktivität als Quellen und Senken unterstützt, finden Sie unter Unterstützte Datenspeicher.
Weitere Informationen finden Sie unter Kopieren von Daten in Azure Data Explorer mithilfe von Azure Data Factory und Synapse Analytics.