Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
In diesem Artikel wird beschrieben, wie Sie "Kopieraktivität" verwenden, um Daten von und auf den sicheren FTP-Server (SFTP) zu kopieren und Data Flow zum Transformieren von Daten in SFTP-Server zu verwenden. Weitere Informationen finden Sie im Einführungsartikel zu Azure Data Factory oder Azure Synapse Analytics.
Unterstützte Funktionen
Dieser SFTP-Anschluss wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | Infrarot |
|---|---|
| Copy-Aktivität (Quelle/Senke) | (1) (2) |
| Datenflusszuordnung (Quelle/Senke) | ① |
| Lookup-Aktivität | (1) (2) |
| GetMetadata-Aktivität | (1) (2) |
| Aktivität löschen | (1) (2) |
(1) Azure Integrationslaufzeit (2) Selbst gehostete Integrationslaufzeit
Der SFTP-Connector unterstützt insbesondere Folgendes:
- Kopieren von Dateien vom und zum SFTP-Server mit der Basic-Authentifizierung, einem öffentlichen SSH-Schlüssel oder der Multi-Faktor-Authentifizierung.
- Kopieren von Dateien im jeweiligen Zustand oder Analysieren oder Generieren von Dateien mit den unterstützten Dateiformaten und Codecs für die Komprimierung.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, einem Azure virtuellen Netzwerk oder amazon Virtual Private Cloud befindet, müssen Sie eine self-gehostete Integrationslaufzeit konfigurieren, um eine Verbindung damit herzustellen.
Wenn Ihr Datenspeicher ein verwalteter Clouddatendienst ist, können Sie die Azure Integration Runtime verwenden. Wenn der Zugriff auf IPs beschränkt ist, die in den Firewallregeln genehmigt wurden, können Sie der Zulassungsliste Azure Integration Runtime-IPs hinzufügen.
Sie können auch das Feature managed virtual network integration runtime in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbst gehostete Integrationslaufzeit zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Erste Schritte
Zum Ausführen der Kopieraktivität mit einer Pipeline können Sie eines der folgenden Tools oder SDKs verwenden:
- Datenkopier-Tool
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST-API
- Azure Resource Manager Vorlage
Erstellen eines verknüpften SFTP-Diensts über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen SFTP-verknüpften Dienst in der benutzeroberfläche des Azure Portals zu erstellen.
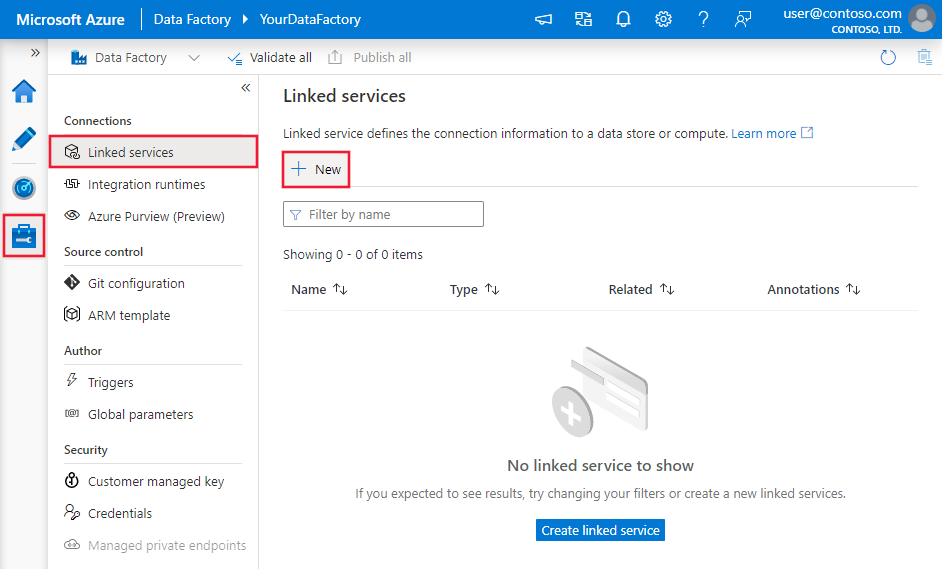
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte "Verwalten", und wählen Sie "Verknüpfte Dienste" aus, und klicken Sie dann auf "Neu":
Suchen Sie nach SFTP und wählen Sie den „SFTP-Connector“ aus.
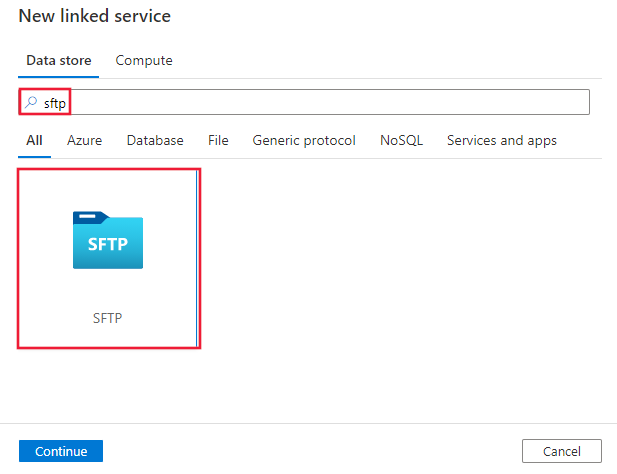
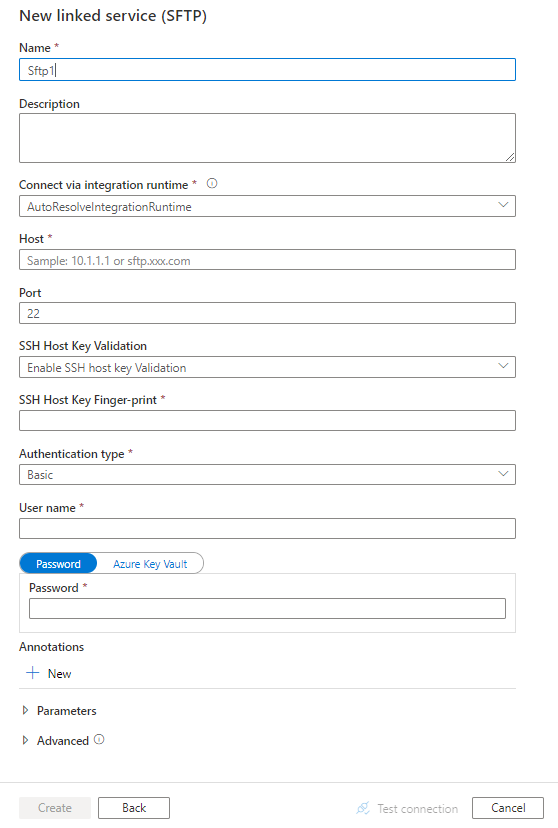
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu den Eigenschaften, die zum Definieren von Entitäten speziell für SFTP verwendet werden.
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit SFTP verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf Sftp festgelegt werden. | Ja |
| host | Der Name oder die IP-Adresse des SFTP-Servers. | Ja |
| port | Der Port, an dem der SFTP-Server lauscht. Der zulässige Wert ist eine ganze Zahl (Integer), und der Standardwert ist 22. |
Nein |
| skipHostKeyValidation | Angabe, ob die Überprüfung des Hostschlüssels übersprungen werden soll. Zulässige Werte sind true und false (Standard). |
Nein |
| Hostschlüssel-Fingerabdruck | Angabe des Fingerabdrucks des Hostschlüssels. | Ja, sofern die „skipHostKeyValidation“ auf „false“ festgelegt ist. |
| Authentifizierungstyp | Gibt den Authentifizierungstyp an. Zulässige Werte sind Basic, öffentlicher SSH-Schlüssel und mehrstufig. Weitere Eigenschaften finden Sie im Abschnitt Verwenden der Standardauthentifizierung. JSON-Beispiele finden Sie im Abschnitt Verwenden der Authentifizierung mit öffentlichem SSH-Schlüssel. |
Ja |
| connectVia | Die Integrationslaufzeit, die verwendet werden soll, um eine Verbindung mit dem Datenspeicher herzustellen. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn der integration runtime nicht angegeben ist, verwendet der Dienst die Standard-Azure Integration Runtime. | Nein |
Verwenden der Standardauthentifizierung
Um die Standardauthentifizierung zu verwenden, legen Sie die Eigenschaft authenticationType auf Basic fest, und geben zusätzlich zu den im vorherigen Abschnitt eingeführten generischen SFTP-Connectoreigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| userName | Der Benutzer, der Zugriff auf den SFTP-Server hat. | Ja |
| Passwort | Das Kennwort für den Benutzer (userName). Markieren Sie dieses Feld als SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in einem Azure-Schlüsseltresor gespeichertes Geheimnis. | Ja |
Beispiel:
{
"name": "SftpLinkedService",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "<sftp server>",
"port": 22,
"skipHostKeyValidation": false,
"hostKeyFingerPrint": "ssh-rsa 2048 xx:00:00:00:xx:00:x0:0x:0x:0x:0x:00:00:x0:x0:00",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of integration runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verwenden der Authentifizierung mit öffentlichem SSH-Schlüssel
Legen Sie zum Verwenden der Authentifizierung mit öffentlichem SSH-Schlüssel die Eigenschaft „authenticationType“ auf SshPublicKey fest, und geben Sie neben den im letzten Abschnitt beschriebenen allgemeinen Eigenschaften des SFTP-Connectors die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| userName | Der Benutzer, der Zugriff auf den SFTP-Server hat. | Ja |
| privateKeyPath | Geben Sie den absoluten Pfad der privaten Schlüsseldatei ein, auf die die Integration Runtime zugreifen kann. Dies ist nur anwendbar, wenn für „connectVia“ eine Integration Runtime vom Typ „selbstgehostet“ angegeben wird. | Geben Sie entweder privateKeyPath oder privateKeyContent an. |
| Inhalt des privaten Schlüssels | Inhalt des Base64-codierten privaten SSH-Schlüssels. Der private SSH-Schlüssel sollte das Format „OpenSSH“ aufweisen. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in einem Azure-Schlüsseltresor gespeichertes Geheimnis. | Geben Sie entweder privateKeyPath oder privateKeyContent an. |
| Passphrase | Geben Sie die Passphrase zum Entschlüsseln des privaten Schlüssels ein, wenn Schlüsseldatei oder Schlüsselinhalt mit einer Passphrase geschützt sind. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in einem Azure-Schlüsseltresor gespeichertes Geheimnis. | Ja, wenn die private Schlüsseldatei oder der Schlüsselinhalt mit einer Passphrase geschützt sind. |
Hinweis
Der SFTP-Connector unterstützt nur RSA/DSA OpenSSH-Schlüssel. Stellen Sie sicher, dass der Inhalt Ihrer Schlüsseldatei mit „-----BEGIN [RSA/DSA] PRIVATE KEY-----“ beginnt. Wenn die Datei mit dem privaten Schlüssel eine Datei im PPK-Format ist, verwenden Sie das Tool PuTTY für die Konvertierung aus dem PPK- in das OpenSSH-Format.
Beispiel 1: SshPublicKey-Authentifizierung unter Verwendung des Dateipfads des privaten Schlüssels
{
"name": "SftpLinkedService",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "<sftp server>",
"port": 22,
"skipHostKeyValidation": true,
"authenticationType": "SshPublicKey",
"userName": "xxx",
"privateKeyPath": "D:\\privatekey_openssh",
"passPhrase": {
"type": "SecureString",
"value": "<pass phrase>"
}
},
"connectVia": {
"referenceName": "<name of integration runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel 2: SshPublicKey-Authentifizierung unter Verwendung des Inhalts des privaten Schlüssels
{
"name": "SftpLinkedService",
"type": "Linkedservices",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "<sftp server>",
"port": 22,
"skipHostKeyValidation": true,
"authenticationType": "SshPublicKey",
"userName": "<username>",
"privateKeyContent": {
"type": "SecureString",
"value": "<base64 string of the private key content>"
},
"passPhrase": {
"type": "SecureString",
"value": "<pass phrase>"
}
},
"connectVia": {
"referenceName": "<name of integration runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verwenden der mehrstufigen Authentifizierung
Um die mehrstufige Authentifizierung zu verwenden, bei der es sich um eine Kombination aus grundlegenden und SSH-Authentifizierungen mit öffentlichem Schlüssel handelt, geben Sie den Benutzernamen, das Kennwort und die privaten Schlüsselinformationen an, wie oben beschrieben.
Beispiel: mehrstufige Authentifizierung
{
"name": "SftpLinkedService",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "<host>",
"port": 22,
"authenticationType": "MultiFactor",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"privateKeyContent": {
"type": "SecureString",
"value": "<base64 encoded private key content>"
},
"passPhrase": {
"type": "SecureString",
"value": "<passphrase for private key>"
}
},
"connectVia": {
"referenceName": "<name of integration runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel Datasets.
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Durch Trennzeichen getrenntes Textformat
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Folgende Eigenschaften werden für SFTP unter den location-Einstellungen im formatbasierten Dataset unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft unter location im Dataset muss auf SftpLocation festgelegt werden. |
Ja |
| folderPath | Der Pfad zum Ordner. Wenn Sie einen Platzhalter verwenden möchten, um den Ordner zu filtern, überspringen Sie diese Einstellung, und geben Sie den Pfad in den Aktivitätsquelleneinstellungen an. | Nein |
| Dateiname | Der Dateiname im angegebenen Ordnerpfad. Wenn Sie einen Platzhalter verwenden möchten, um Dateien zu filtern, überspringen Sie diese Einstellung, und geben Sie den Dateinamen in den Aktivitätsquelleneinstellungen an. | Nein |
Beispiel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<SFTP linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "SftpLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der SFTP-Quelle unterstützt werden.
SFTP als Quelle
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Durch Trennzeichen getrenntes Textformat
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Folgende Eigenschaften werden für SFTP unter den storeSettings-Einstellungen in der formatbasierten Kopierquelle unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft unter storeSettings muss auf SftpReadSettings festgelegt werden. |
Ja |
| Lokalisieren Sie die zu kopierenden Dateien | ||
| OPTION 1: statischer Pfad |
Kopieren Sie aus dem im Dataset angegebenen Ordner/Dateipfad. Wenn Sie alle Dateien aus einem Ordner kopieren möchten, geben Sie zusätzlich für wildcardFileName den Wert * an. |
|
| OPTION 2: Wildcard – wildcardFolderPath |
Der Ordnerpfad mit Platzhalterzeichen, um Quellordner zu filtern. Zulässige Platzhalter sind * (entspricht null oder mehr Zeichen) und ? (entspricht null oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr tatsächlicher Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Nein |
| OPTION 2: Wildcard – wildcardFileName |
Der Dateiname mit Platzhalterzeichen unter dem angegebenen folderPath/wildcardFolderPath für das Filtern von Quelldateien. Zulässige Platzhalter sind: * (entspricht null oder mehr Zeichen) und ? (entspricht null oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr tatsächlicher Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Ja |
| OPTION 3: eine Liste von Dateien – fileListPath |
Diese Eigenschaft gibt an, dass eine angegebene Dateigruppe kopiert werden soll. Verweisen Sie auf eine Textdatei, die eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile, mit dem relativen Pfad zu dem im Dataset konfigurierten Pfad. Wenn Sie diese Option verwenden, geben Sie nicht den Dateinamen im Dataset an. Weitere Beispiele finden Sie unter Beispiele für Dateilisten. |
Nein |
| Zusätzliche Einstellungen | ||
| rekursiv | Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Wenn „recursive“ auf „true“ festgelegt ist und es sich bei der Senke um einen dateibasierten Speicher handelt, wird ein leerer Ordner oder Unterordner nicht in die Senke kopiert oder dort erstellt. Zulässige Werte sind true (Standard) und false. Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| DateienNachAbschlussLöschen | Gibt an, ob die Binärdateien nach dem erfolgreichen Verschieben in den Zielspeicher aus dem Quellspeicher gelöscht werden. Die Dateien werden einzeln gelöscht, sodass Sie bei einem Fehler der Kopieraktivität feststellen werden, dass einige Dateien bereits ins Ziel kopiert und aus der Quelle gelöscht wurden, wohingegen sich andere weiter im Quellspeicher befinden. Diese Eigenschaft ist nur im Szenario zum Kopieren von Binärdateien gültig. Standardwert: FALSE. |
Nein |
| modifiedDatetimeStart | Die Dateien werden anhand des Attributs Zuletzt bearbeitet gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format 2018-12-01T05:00:00Z angewandt. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewandt wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEnd NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd einen datetime-Wert aufweist, aber modifiedDatetimeStart NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist.Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| modifiedDatetimeEnd | Wie oben. | Nein |
| partitionserkennungAktivieren | Geben Sie bei partitionierten Dateien an, ob die Partitionen anhand des Dateipfads analysiert und als zusätzliche Quellspalten hinzugefügt werden sollen. Zulässige Werte sind false (Standard) und true. |
Nein |
| partitionRootPath | Wenn die Partitionsermittlung aktiviert ist, geben Sie den absoluten Stammpfad an, um partitionierte Ordner als Datenspalten zu lesen. Falls nicht anders angegeben, gilt standardmäßig: - Wenn Sie den Dateipfad im Dataset oder die Liste der Dateien in der Quelle verwenden, ist der Partitionsstammpfad der im Dataset konfigurierte Pfad. Wenn Sie einen Platzhalterordnerfilter verwenden, ist der Stammpfad der Partition der Unterpfad vor dem ersten Platzhalter. Angenommen, Sie konfigurieren den Pfad im Dataset als „root/folder/year=2020/month=08/day=27“: - Wenn Sie den Stammpfad der Partition als „root/folder/year=2020“ angeben, generiert die Kopieraktivität zusätzlich zu den Spalten in den Dateien die beiden weiteren Spalten month und day mit den Werten „08“ bzw. „27“.- Wenn kein Stammpfad für die Partition angegeben ist, wird keine zusätzliche Spalte generiert. |
Nein |
| maximale gleichzeitige Verbindungen | Die Maximalanzahl gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
| Chunking deaktivieren | Beim Kopieren von Daten vom SFTP-Server versucht der Dienst, zuerst die Dateilänge abzurufen, dann die Datei in mehrere Teile aufzuteilen und diese parallel zu lesen. Geben Sie an, ob der SFTP-Server das Abrufen der Dateilänge oder das Lesen aus einem bestimmten Offset unterstützt. Zulässige Werte sind false (Standard) und true. |
Nein |
Beispiel:
"activities":[
{
"name": "CopyFromSFTP",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "SftpReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv",
"disableChunking": false
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
SFTP als Senke
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Durch Trennzeichen getrenntes Textformat
- JSON-Format
- ORC-Format
- Parquet-Format
Folgende Eigenschaften werden für SFTP unter den storeSettings-Einstellungen in einer formatbasierten Kopiersenke unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Eigenschaft type unter storeSettings muss auf SftpWriteSettings festgelegt werden. |
Ja |
| Kopieverhalten | Definiert das Kopierverhalten, wenn es sich bei der Quelle um Dateien aus einem dateibasierten Datenspeicher handelt. Zulässige Werte sind: - PreserveHierarchy (Standard): Behält die Dateihierarchie im Zielordner bei. Der relative Pfad der Quelldatei zum Quellordner ist mit dem relativen Pfad der Zieldatei zum Zielordner identisch. - FlattenHierarchy: Alle Dateien aus dem Quellordner befinden sich auf der ersten Ebene des Zielordners. Die Namen für die Zieldateien werden automatisch generiert. - MergeFiles: Alle Dateien aus dem Quellordner werden in einer Datei zusammengeführt. Wenn der Dateiname angegeben wurde, entspricht der zusammengeführte Dateiname dem angegebenen Namen. Andernfalls wird der Dateiname automatisch generiert. |
Nein |
| maximale gleichzeitige Verbindungen | Die Maximalanzahl gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
| useTempFileRename | Geben Sie an, ob Sie temporäre Dateien hochladen und umbenennen oder direkt in den Zielordner oder Dateispeicherort schreiben möchten. Standardmäßig schreibt der Dienst zuerst in temporäre Dateien und benennt sie dann um, wenn der Upload abgeschlossen ist. Diese Sequenz hilft, (1) Konflikte zu vermeiden, die zu einer beschädigten Datei führen könnten, wenn andere Prozesse in dieselbe Datei schreiben, und (2) sicherzustellen, dass die Originalversion der Datei während der Übertragung vorhanden ist. Wenn Ihr SFTP-Server keine Umbenennungsvorgänge unterstützt, deaktivieren Sie diese Option, und stellen Sie sicher, dass keine gleichzeitigen Schreibvorgänge für die Zieldatei ausgeführt werden. Weitere Informationen finden Sie im Tipp zur Problembehandlung am Ende dieser Tabelle. | Nein. Der Standardwert lautet true. |
| operationTimeout | Bei der Wartezeit vor jeder Schreibanforderung an den SFTP-Server tritt ein Timeout auf. Der Standardwert ist 60 Minuten (01:00:00). | Nein |
Tipp
Wenn Sie beim Schreiben von Daten in SFTP den Fehler „UserErrorSftpPathNotFound“, „UserErrorSftpPermissionDenied“ oder „SftpOperationFail“ erhalten und der von Ihnen verwendete SFTP-Benutzer über die entsprechende Berechtigung verfügt, überprüfen Sie, ob Ihr Umbenennungsvorgang für die Unterstützungsdatei des SFTP-Servers funktioniert. Wenn dies nicht der Fall ist, deaktivieren Sie die Option Upload with temp file (useTempFileRename), und versuchen Sie es erneut. Weitere Informationen zu dieser Eigenschaft finden Sie in der obigen Tabelle. Wenn Sie eine selbst gehostete Integrationslaufzeit für die Copy activity verwenden, stellen Sie sicher, dass Sie Version 4.6 oder höher verwenden.
Beispiel:
"activities":[
{
"name": "CopyToSFTP",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "BinarySink",
"storeSettings":{
"type": "SftpWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Beispiele für Ordner- und Dateifilter
In diesem Abschnitt wird das Verhalten beschrieben, das sich aus der Verwendung von Platzhalterfiltern mit Ordnerpfaden und Dateinamen ergibt.
| folderPath | Dateiname | rekursiv | Ordnerstruktur der Quelle und Filterergebnis (Dateien in Fett werden abgerufen.) |
|---|---|---|---|
Folder* |
(leer, Standardeinstellung verwenden) | false | FolderA Datei1.csv File2.json Unterverzeichnis1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
(leer, Standardeinstellung verwenden) | wahr | FolderA Datei1.csv File2.json Unterverzeichnis1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
*.csv |
false | FolderA Datei1.csv Datei2.json Unterverzeichnis1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
*.csv |
wahr | FolderA Datei1.csv Datei2.json Unterverzeichnis1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Beispiele für Dateilisten
In dieser Tabelle wird das Verhalten beschrieben, das sich aus der Verwendung eines Dateilistenpfads in der Copy activity Quelle ergibt. Es wird angenommen, dass Sie die folgende Quellordnerstruktur verwenden und die Dateien kopieren möchten, deren Namen fett formatiert sind:
| Beispielquellstruktur | Inhalt in „FileListToCopy.txt“ | Azure Data Factory Konfiguration |
|---|---|---|
| root FolderA Datei1.csv Datei2.json Unterverzeichnis1 File3.csv File4.json File5.csv Metadaten DateilisteZumKopieren.txt |
Datei1.csv Unterordner1/Datei3.csv Unterordner1/Datei5.csv |
Im Datensatz: – Ordnerpfad: root/FolderAIm Quellbereich der Kopieraktivität: – Dateilistenpfad: root/Metadata/FileListToCopy.txt Der Dateilistenpfad verweist auf eine Textdatei im selben Datenspeicher, der eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile, mit dem relativen Pfad zu dem im Dataset konfigurierten Pfad. |
Eigenschaften des Mapping-Datenflusses
Wenn Sie Daten in Zuordnungsdatenflüsse transformieren, können Sie Dateien aus SFTP in den folgenden Formaten lesen und schreiben:
Formatspezifische Einstellungen finden Sie in der Dokumentation für das jeweilige Format. Weitere Informationen finden Sie unter Quelltransformation in einem Zuordnungsdatenfluss und Senkentransformation in einem Zuordnungsdatenfluss.
Hinweis
Die Überprüfung des SSH-Hostschlüssels wird jetzt im Zuordnungsdatenfluss nicht unterstützt.
Hinweis
Um auf den lokalen SFTP-Server zuzugreifen, müssen Sie Azure Data Factory- oder Synapse-Arbeitsbereich Managed Virtual Network mit einem privaten Endpunkt verwenden. Ausführliche Schritte finden Sie in diesem Tutorial.
Quellentransformation
In der folgenden Tabelle sind die von einer SFTP-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten. Bei Verwendung eines Inlinedatasets werden zusätzliche Einstellungen angezeigt. Diese entsprechen den Eigenschaften, die im Abschnitt zu den Dataseteigenschaften beschrieben sind.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Platzhalterpfad | Mithilfe eines Platzhaltermusters wird ADF angewiesen, die einzelnen übereinstimmenden Ordner und Dateien in einer einzigen Quelltransformation zu durchlaufen. Dies ist eine effektive Methode zur Verarbeitung von mehreren Dateien in einem einzigen Datenfluss. | Nein | String[] | wildcardPaths |
| Stammverzeichnispfad der Partition | Wenn Ihre Dateiquelle partitionierte Ordner mit dem Format key=value (z. B. year=2019) enthält, können Sie die oberste Ebene dieser Partitionsordnerstruktur einem Spaltennamen im Datenstrom Ihres Datenflusses zuweisen. |
Nein | String | partitionRootPath |
| Finden keiner Dateien zulässig | „true“ gibt an, dass kein Fehler ausgelöst wird, wenn keine Dateien gefunden werden. | Nein |
true oder false |
ignoreNoFilesFound |
| Liste mit den Dateien | Dies ist eine Dateigruppe. Erstellen Sie eine Textdatei mit einer Liste der relativen Pfade der zu verarbeitenden Dateien. Verweisen Sie auf diese Textdatei. | Nein |
true oder false |
Dateiliste |
| Spalte, in der der Dateiname gespeichert wird | Speichern Sie den Namen der Quelldatei in einer Spalte in den Daten. Geben Sie hier einen neuen Spaltennamen ein, um die Zeichenfolge für den Dateinamen zu speichern. | Nein | String | rowUrlColumn |
| Nach Abschluss | Wählen Sie aus, ob Sie nach dem Ausführen des Datenflusses nichts mit der Quelldatei anstellen, die Quelldatei löschen oder die Quelldateien verschieben möchten. Die Pfade für das Verschieben sind relativ. | Nein | Löschen: true oder false Verschieben: ['<from>', '<to>'] |
Dateien löschen DateienVerschieben |
| Nach der letzten Änderung filtern | Sie können einen Datumsbereich angeben, um die zu verarbeitenden Dateien nach der letzten Änderung zu filtern. Alle Zeitangaben sind in UTC. | Nein | Timestamp | modifiedAfter modifiedBefore |
Skriptbeispiel für SFTP-Quelle
Wenn Sie das SFTP-Dataset als Quelltyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
source(allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: true,
purgeFiles: true,
fileList: true,
modifiedAfter: (toTimestamp(1647388800000L)),
modifiedBefore: (toTimestamp(1647561600000L)),
partitionRootPath: 'partdata',
wildcardPaths:['partdata/**/*.csv']) ~> SFTPSource
Senkentransformation
In der folgenden Tabelle sind die von einer SFTP-Senke unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Einstellungen bearbeiten. Bei Verwendung eines Inlinedatasets werden zusätzliche Einstellungen angezeigt. Diese entsprechen den Eigenschaften, die im Abschnitt zu den Dataseteigenschaften beschrieben sind.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Ordner löschen | Bestimmt, ob der Zielordner vor dem Schreiben der Daten gelöscht wird. | Nein |
true oder false |
Abkürzen |
| Dateinamenoption | Das Namensformat der geschriebenen Daten. Standardmäßig eine Datei pro Partition im Format part-#####-tid-<guid>. |
Nein | Muster: Zeichenfolge Pro Partition: Zeichenfolge[] Datei als Spaltendaten benennen: String Ordnername aus Spaltendaten: String Ausgabe in eine einzige Datei: ['<fileName>'] |
filePattern Partition-Dateinamen rowUrlColumn rowFolderUrlColumn PartitionDateinamen |
| Alle in Anführungszeichen | Bestimmt, ob alle Werte in Anführungszeichen eingeschlossen werden sollen. | Nein |
true oder false |
quoteAll |
Skriptbeispiel für SFTP-Sink
Wenn Sie das SFTP-Dataset als Senkentyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
filePattern:'loans[n].csv',
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SFTPSink
Eigenschaften der Lookup-Aktivität
Weitere Informationen zu den Eigenschaften der Lookup-Aktivität finden Sie unter Lookup-Aktivität.
Eigenschaften der GetMetadata-Aktivität
Weitere Informationen zu den Eigenschaften der GetMetadata-Aktivität finden Sie unter GetMetadata-Aktivität.
Aktivitätseigenschaften löschen
Weitere Informationen zu den Eigenschaften der Löschaktivität finden Sie unter Löschaktivität.
Legacy-Modelle
Hinweis
Die folgenden Modelle werden aus Gründen der Abwärtskompatibilität weiterhin unverändert unterstützt. Es wird empfohlen, das zuvor diskutierte neue Modell zu verwenden, da die Erstellungsbenutzeroberfläche nun das neue Modell generiert.
Legacy-Datasetmodell
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft des Datasets muss auf FileShare festgelegt werden. | Ja |
| folderPath | Der Pfad zum Ordner. Ein Platzhalterfilter wird unterstützt. Zulässige Platzhalter sind: * (entspricht 0 oder mehr Zeichen) und ? (entspricht 0 oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr tatsächlicher Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Beispiele: Stammordner/Unterordner/. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Ja |
| Dateiname |
Name oder Platzhalterfilter für die Dateien unter dem angegebenen „folderPath“. Wenn Sie für diese Eigenschaft keinen Wert angeben, verweist das Dataset auf alle Dateien im Ordner. Für Filter sind folgende Platzhalter zulässig: * (entspricht 0 oder mehr Zeichen) und ? (entspricht 0 oder einem einzelnen Zeichen).- Beispiel 1: "fileName": "*.csv"- Beispiel 2: "fileName": "???20180427.txt"Verwenden Sie ^ als Escapezeichen, wenn der tatsächliche Ordnername einen Platzhalter oder dieses Escapezeichen enthält. |
Nein |
| modifiedDatetimeStart | Die Dateien werden anhand des Attributs Zuletzt bearbeitet gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format 2018-12-01T05:00:00Z angewandt. Die generelle Leistung der Datenverschiebung wird beeinträchtigt, wenn Sie diese Einstellung aktivieren und einen Dateifilter auf eine große Anzahl von Dateien anwenden möchten. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewandt wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEnd NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd einen datetime-Wert aufweist, aber modifiedDatetimeStart NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist. |
Nein |
| modifiedDatetimeEnd | Die Dateien werden anhand des Attributs Zuletzt bearbeitet gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format 2018-12-01T05:00:00Z angewandt. Die generelle Leistung der Datenverschiebung wird beeinträchtigt, wenn Sie diese Einstellung aktivieren und einen Dateifilter auf eine große Anzahl von Dateien anwenden möchten. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewandt wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEnd NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd einen datetime-Wert aufweist, aber modifiedDatetimeStart NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist. |
Nein |
| format | Wenn Sie Dateien unverändert zwischen dateibasierten Speichern kopieren möchten (binäre Kopie), können Sie den Formatabschnitt bei den Definitionen von Eingabe- und Ausgabedatasets überspringen. Für das Analysieren von Dateien mit einem bestimmten Format werden die folgenden Dateiformattypen unterstützt: TextFormat, JsonFormat, AvroFormat, OrcFormat und ParquetFormat. Sie müssen die type -Eigenschaft unter „format“ auf einen dieser Werte festlegen. Weitere Informationen finden Sie in den Abschnitten "Textformat", "JSON-Format", "Avro-Format", " Orc-Format" und " Parkett" . |
Nein (nur für Szenarien mit Binärkopien) |
| Komprimierung | Geben Sie den Typ und den Grad der Komprimierung für die Daten an. Weitere Informationen finden Sie unter Unterstützte Dateiformate und Codecs für die Komprimierung. Unterstützte Typen sind GZip, Deflate, BZIP2 und ZipDeflate. Unterstützte Grade sind Optimal und Schnellste. |
Nein |
Tipp
Wenn Sie alle Dateien eines Ordners kopieren möchten, geben Sie nur folderPath an.
Wenn Sie eine einzelne Datei mit einem bestimmten Namen kopieren möchten, geben Sie folderPath mit der Ordnerkomponente und fileName mit dem Dateinamen an.
Wenn Sie eine Teilmenge der Dateien eines Ordners kopieren möchten, geben Sie folderPath mit dem Ordner und fileName mit einem Platzhalterfilter an.
Hinweis
Wenn Sie die fileFilter-Eigenschaft für den Dateifilter verwendet haben, wird sie weiterhin unterstützt, aber wir empfehlen, dass Sie von jetzt an die neue Filterfunktion verwenden, die zu fileName hinzugefügt wurde.
Beispiel:
{
"name": "SFTPDataset",
"type": "Datasets",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<SFTP linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Älteres Copy activity Quellmodell
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf FileSystemSource festgelegt werden. | Ja |
| rekursiv | Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Wenn „recursive“ auf true festgelegt ist und es sich bei der Senke um einen dateibasierten Speicher handelt, werden leere Ordner und Unterordner nicht in die Senke kopiert oder dort erstellt. Zulässige Werte sind true (Standard) und false. |
Nein |
| maximale gleichzeitige Verbindungen | Die Maximalanzahl gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
Beispiel:
"activities":[
{
"name": "CopyFromSFTP",
"type": "Copy",
"inputs": [
{
"referenceName": "<SFTP input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quellen und Senken für die Copy-Aktivität unterstützt werden, finden Sie hier Unterstützte Datenspeicher.