Unterstützte Dateiformate und Komprimierungscodecs in Azure Data Factory und Synapse Analytics (Legacy)
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Dieser Artikel gilt für die folgenden Connectors: Amazon S3, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP und SFTP.
Wichtig
Der Dienst hat ein neues formatbasiertes Datasetmodell eingeführt, siehe entsprechenden Formatartikel mit Details:
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- JSON-Format
- ORC-Format
- Parquet-Format
Die in diesem Artikel erwähnten restlichen Konfigurationen werden nach wie vor aus Gründen der Abwärtskompatibilität unterstützt. Es wird jedoch empfohlen, in Zukunft das neue Modell zu verwenden.
Textformat (Legacy)
Hinweis
Informationen zum neuen Modell finden Sie im Artikel zum Textformat mit Trennzeichen. Die folgenden Konfigurationen für dateibasierte Datenspeicherdatasets werden aus Gründen der Abwärtskompatibilität unverändert unterstützt. Es wird jedoch empfohlen, in Zukunft das neue Modell zu verwenden.
Wenn Sie aus einer Textdatei lesen oder in eine Textdatei schreiben möchten, legen Sie die type-Eigenschaft im Abschnitt format des Datasets auf TextFormat fest. Sie können auch die folgenden optionalen Eigenschaften im Abschnitt format angeben. Informationen zum Konfigurieren finden Sie im Abschnitt TextFormat-Beispiel.
| Eigenschaft | BESCHREIBUNG | Zulässige Werte | Erforderlich |
|---|---|---|---|
| columnDelimiter | Das Zeichen, das in einer Datei zum Trennen von Spalten verwendet wird. Sie können ein selten vorkommendes, nicht druckbares Zeichen verwenden, das möglicherweise nicht in Ihren Daten vorkommt. Geben Sie beispielsweise „\u0001“ an, das den Anfang der Überschrift (Start of Heading, SOH) bedeutet. | Es ist nur ein Zeichen zulässig. Der Standardwert ist das Komma (,) . Wenn Sie ein Unicode-Zeichen verwenden möchten, finden Sie unter Unicode-Zeichen den zugehörigen Code. |
Nein |
| rowDelimiter | Das Zeichen, das zum Trennen von Zeilen in einer Datei verwendet wird. | Es ist nur ein Zeichen zulässig. Der Standardwert ist einer der folgenden: [„\r\n“, „\r“, „\n“] beim Lesen und „\r\n“ beim Schreiben. | Nein |
| escapeChar | Das Sonderzeichen, mit dem ein Spaltentrennzeichen im Inhalt der Eingabedatei mit Escapezeichen versehen werden kann. Sie können nicht gleichzeitig „escapeChar“ und „quoteChar“ für eine Tabelle angeben. |
Es ist nur ein Zeichen zulässig. Für dieses Feld gibt es keinen Standardwert. Beispiel: Wenn Sie das Komma (,) als Spaltentrennzeichen gewählt haben, das Kommazeichen jedoch im Text verwenden möchten (Beispiel: "Hello, world"), können Sie „$“ als Escapezeichen definieren und die Zeichenfolge "Hello$, world" in der Quelle verwenden. |
Nein |
| quoteChar | Das Zeichen, mit dem ein Zeichenfolgenwert in Anführungszeichen gesetzt wird. Die Spalten- und Zeilentrennzeichen innerhalb der Anführungszeichen werden als Teil des Zeichenfolgenwerts behandelt. Diese Eigenschaft gilt sowohl für Eingabe- als auch Ausgabedatasets. Sie können nicht gleichzeitig „escapeChar“ und „quoteChar“ für eine Tabelle angeben. |
Es ist nur ein Zeichen zulässig. Für dieses Feld gibt es keinen Standardwert. Beispiel: Wenn Sie das Komma (,) als Spaltentrennzeichen gewählt haben, das Kommazeichen jedoch im Text (Beispiel: <Hello, world>) verwenden möchten, können Sie das doppelte Anführungszeichen (") als Escapezeichen definieren und die Zeichenfolge "Hello, world" in der Quelle verwenden. |
Nein |
| nullValue | Ein oder mehrere Zeichen, mit denen ein NULL-Wert dargestellt wird. | Ein oder mehrere Zeichen. Die Standardwerte lauten „\N“ und „NULL“ beim Lesen und „\N“ beim Schreiben. | Nein |
| encodingName | Geben Sie den Codierungsnamen an. | Ein gültiger Codierungsname. Siehe Encoding.EncodingName-Eigenschaft. Beispiel: windows-1250 oder shift_jis. Der Standardwert lautet UTF-8. | Nein |
| firstRowAsHeader | Gibt an, ob die erste Zeile als Kopfzeile betrachtet werden soll. Bei einem Eingabedataset liest der Dienst die erste Zeile als Header. Bei einem Ausgabedataset schreibt der Dienst die erste Zeile als Header. Beispielszenarien finden Sie unter Szenarien für die Verwendung von firstRowAsHeader und skipLineCount. |
True False (Standard) |
Nein |
| skipLineCount | Gibt an, wie viele nicht leere Zeilen beim Lesen von Daten aus Eingabedateien übersprungen werden sollen. Wenn „skipLineCount“ und „firstRowAsHeader“ gleichzeitig angegeben sind, werden die Zeilen zuerst übersprungen, und anschließend werden die Kopfzeileninformationen aus der Eingabedatei gelesen. Beispielszenarien finden Sie unter Szenarien für die Verwendung von firstRowAsHeader und skipLineCount. |
Integer | Nein |
| treatEmptyAsNull | Gibt an, ob Null- oder leere Zeichenfolgen beim Lesen von Daten aus einer Eingabedatei als NULL-Werte behandelt werden sollen. | True (Standard) False |
Nein |
TextFormat-Beispiel
In der folgenden JSON-Definition für ein Dataset sind einige der optionalen Eigenschaften angegeben.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
Zur Verwendung von escapeChar anstelle von quoteChar ersetzen Sie die Zeile mit quoteChar durch das folgende escapeChar-Element:
"escapeChar": "$",
Szenarien für die Verwendung von firstRowAsHeader und skipLineCount
- Sie kopieren Daten aus einer Quelle, bei der es sich nicht um eine Datei handelt, in eine Textdatei und möchten eine Kopfzeile mit den Schemametadaten hinzufügen (Beispiel: SQL-Schema). Legen Sie für dieses Szenario
firstRowAsHeaderim Ausgabedataset als „true“ fest. - Sie kopieren aus einer Textdatei mit einer Kopfzeile in eine Senke, bei der es sich nicht um eine Datei handelt, und möchten diese Zeile löschen. Legen Sie
firstRowAsHeaderim Eingabedataset als „true“ fest. - Sie kopieren aus einer Textdatei und möchten einige Zeilen am Anfang überspringen, die keine Daten oder Kopfzeileninformationen enthalten. Geben Sie mit
skipLineCountdie Anzahl von Zeilen an, die übersprungen werden sollen. Wenn der Rest der Datei eine Kopfzeile enthält, können Sie auchfirstRowAsHeaderangeben. Wenn sowohlskipLineCountals auchfirstRowAsHeaderangegeben sind, werden erst die Zeilen übersprungen und dann die Kopfzeileninformationen aus der Eingabedatei gelesen.
JSON-Format (Legacy)
Hinweis
Informationen zum neuen Modell finden Sie im Artikel zum JSON-Format. Die folgenden Konfigurationen für dateibasierte Datenspeicherdatasets werden aus Gründen der Abwärtskompatibilität unverändert unterstützt. Es wird jedoch empfohlen, in Zukunft das neue Modell zu verwenden.
Informationen zum unveränderten Importieren/Exportieren einer JSON-Datei in/aus Azure Cosmos DB finden Sie im Abschnitt „Importieren oder Exportieren von JSON-Dokumenten“ im Artikel Verschieben von Daten in/aus Azure Cosmos DB.
Wenn Sie JSON-Dateien analysieren oder die Daten im JSON-Format schreiben möchten, legen Sie für die type-Eigenschaft im Abschnitt format den Wert JsonFormat fest. Sie können auch die folgenden optionalen Eigenschaften im Abschnitt format angeben. Informationen zum Konfigurieren finden Sie im Abschnitt JsonFormat-Beispiel.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| filePattern | Geben Sie das Muster der in jeder JSON-Datei gespeicherten Daten an. Zulässige Werte sind setOfObjects und arrayOfObjects. Der Standardwert ist setOfObjects. Weitere Informationen zu diesen Mustern finden Sie im Abschnitt JSON-Dateimuster. | Nein |
| jsonNodeReference | Falls Sie Daten durchlaufen und aus den Objekten in einem Arrayfeld mit demselben Muster extrahieren möchten, legen Sie den JSON-Pfad dieses Arrays fest. Diese Eigenschaft wird nur beim Kopieren von Daten aus JSON-Dateien unterstützt. | Nein |
| jsonPathDefinition | Geben Sie den JSON-Pfadausdruck für jede Spaltenzuordnung mit einem benutzerdefinierten Spaltennamen (beginnend mit einem Kleinbuchstaben) an. Diese Eigenschaft wird nur beim Kopieren von Daten aus JSON-Dateien unterstützt. Sie können zudem Daten aus dem Objekt oder Array extrahieren. Bei Feldern unter dem Stammobjekt beginnen Sie mit Stamm „$“. Bei Feldern innerhalb des Arrays, die anhand der jsonNodeReference-Eigenschaft ausgewählt werden, beginnen Sie mit dem Arrayelement. Informationen zum Konfigurieren finden Sie im Abschnitt JsonFormat-Beispiel. |
Nein |
| encodingName | Geben Sie den Codierungsnamen an. Die Liste der gültigen Codierungsnamen finden Sie unter: Encoding.EncodingName-Eigenschaft. Beispiel: Windows-1250 oder Shift-JIS. Der Standardwert lautet: UTF-8. | Nein |
| nestingSeparator | Zeichen, das zur Trennung der Schachtelungsebenen verwendet wird. Der Standardwert ist „.“ (Punkt). | Nein |
Hinweis
Für den Fall, dass anwendungsübergreifende Daten in Arrays in mehreren Zeilen vorliegen (Fall 1 -> Beispiel 2 in JsonFormat-Beispielen), können Sie nur einzelne Arrays über die Eigenschaft jsonNodeReference erweitern.
JSON-Dateimuster
Die Kopieraktivität kann die Muster der folgenden JSON-Dateien analysieren:
Typ I: setOfObjects
Jede Datei enthält ein einzelnes Objekt oder mehrere durch Zeilen getrennte/verkettete Objekte. Wenn diese Option in einem Ausgabedataset ausgewählt wird, erzeugt die Kopieraktivität eine einzelne JSON-Datei mit jedem Objekt pro Zeile (durch Zeilen getrennt).
JSON-Beispiel mit einzelnem Objekt
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }JSON-Beispiel mit getrennten Zeilen
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}JSON-Beispiel mit Verkettung
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Typ II: arrayOfObjects
Jede Datei enthält ein Array von Objekten.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
JsonFormat-Beispiel
Fall 1: Kopieren von Daten aus JSON-Dateien
Beispiel 1: Extrahieren von Daten aus Objekt und Array
In diesem Beispiel wird ein einzelnes JSON-Stammobjekt einem einzelnen Datensatz in einem tabellarischen Ergebnis zugeordnet. Wenn Sie eine JSON-Datei mit dem folgenden Inhalt haben:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
und ihn im folgenden Format in eine Azure SQL-Tabelle kopieren möchten, indem Sie Daten aus Objekten und dem Array extrahieren:
| id | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
Das Eingabedataset vom Typ JsonFormat ist wie folgt definiert: (Teildefinition ausschließlich mit den relevanten Teilen). Dies gilt insbesondere in folgenden Fällen:
- Abschnitt
structuredefiniert die benutzerdefinierten Spaltennamen und den entsprechenden Datentyp beim Konvertieren in tabellarische Daten. Dieser Abschnitt ist optional, solange Sie keine Spaltenzuordnung ausführen müssen. Weitere Informationen finden Sie unter Zuordnen von Spalten im Quelldataset zu Spalten im Zieldataset. jsonPathDefinitiongibt den JSON-Pfad für jede Spalte an, die anzeigt, wo die Daten extrahiert werden sollen. Um Daten aus dem Array zu kopieren, können Sie mitarray[x].propertyden Wert der angegebenen Eigenschaft aus demxth-Objekt extrahieren oder mitarray[*].propertyin einem beliebigen Objekt mit entsprechender Eigenschaft nach dem Wert suchen.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Beispiel 2: Übergreifendes Anwenden mehrerer Objekte mit dem gleichen Muster über das Array
In diesem Beispiel wird ein einzelnes JSON-Stammobjekt im tabellarischen Ergebnis in mehrere Datensätze transformiert. Wenn Sie eine JSON-Datei mit dem folgenden Inhalt haben:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
und Sie ihn in eine Azure SQL-Tabelle im folgenden Format kopieren möchten, indem Sie die Daten im Array vereinfachen und mit den allgemeinen Stamminformationen verknüpfen möchten:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
Das Eingabedataset vom Typ JsonFormat ist wie folgt definiert: (Teildefinition ausschließlich mit den relevanten Teilen). Dies gilt insbesondere in folgenden Fällen:
- Abschnitt
structuredefiniert die benutzerdefinierten Spaltennamen und den entsprechenden Datentyp beim Konvertieren in tabellarische Daten. Dieser Abschnitt ist optional, solange Sie keine Spaltenzuordnung ausführen müssen. Weitere Informationen finden Sie unter Zuordnen von Spalten im Quelldataset zu Spalten im Zieldataset. jsonNodeReferencegibt an, dass die Iteration und Extraktion von Daten aus den Objekten mit dem Muster unter Arrayorderlineserfolgt.jsonPathDefinitiongibt den JSON-Pfad für jede Spalte an, die anzeigt, wo die Daten extrahiert werden sollen. In diesem Beispiel unterliegenordernumber,orderdateundcitydem Stammobjekt mit dem JSON-Pfad, der mit$.beginnt.order_pdundorder_pricebeginnen hingegen mit dem Pfad, der sich aus dem Array-Element ohne$.ableitet.
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Beachten Sie folgende Punkte:
- Wenn
structureundjsonPathDefinitionim Dataset nicht definiert sind, erkennt die Copy-Aktivität das Schema des ersten Objekts und vereinfacht das gesamte Objekt. - Wenn die JSON-Eingabe ein Array aufweist, konvertiert die Kopieraktivität standardmäßig den gesamten Array-Wert in eine Zeichenfolge. Sie können Daten mit
jsonNodeReferenceund/oderjsonPathDefinitiondaraus extrahieren oder diesen Schritt überspringen, indem Sie ihn injsonPathDefinitionnicht angeben. - Wenn auf derselben Ebene doppelte Namen vorkommen, wählt die Kopieraktivität den letzten aus.
- Bei Eigenschaftennamen wird zwischen Groß- und Kleinschreibung unterschieden. Zwei Eigenschaften mit demselben Namen und unterschiedlicher Groß- und Kleinschreibung werden als zwei getrennte Eigenschaften behandelt.
Fall 2: Schreiben von Daten in eine JSON-Datei
Wenn Sie in der SQL-Datenbank über die folgende Tabelle verfügen:
| id | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
Und für jeden Datensatz erwarten Sie, ein JSON-Objekt im folgenden Format zu schreiben:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
Das Ausgabedataset vom Typ JsonFormat ist wie folgt definiert: (Teildefinition ausschließlich mit den relevanten Teilen). Genauer gesagt definiert der Abschnitt structure die angepassten Eigenschaftennamen in der Zieldatei, und nestingSeparator (der Standardwert ist „.“) wird verwendet, um die nächste Ebene ab dem Namen zu kennzeichnen. Dieser Abschnitt ist optional, solange Sie den Namen der Eigenschaft im Vergleich zum Quellspaltennamen nicht ändern oder einige der Eigenschaften verschachteln möchten.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Parquet-Format (Legacy)
Hinweis
Informationen zum neuen Modell finden Sie im Artikel zum Parquet-Format. Die folgenden Konfigurationen für dateibasierte Datenspeicherdatasets werden aus Gründen der Abwärtskompatibilität unverändert unterstützt. Es wird jedoch empfohlen, in Zukunft das neue Modell zu verwenden.
Wenn Sie ORC-Dateien analysieren oder die Daten im ORC-Format schreiben möchten, legen Sie für die formattype-Eigenschaft OrcFormat fest. Sie müssen im Abschnitt „Format“ innerhalb des Abschnitts „typeProperties“ keine Eigenschaften angeben. Beispiel:
"format":
{
"type": "ParquetFormat"
}
Beachten Sie folgende Punkte:
- Komplexe Datentypen werden nicht unterstützt (MAP, LIST).
- Ein Leerzeichen im Spaltennamen wird nicht unterstützt.
- Für die Parquet-Datei stehen die folgenden mit der Komprimierung zusammenhängenden Optionen zur Verfügung: NONE, SNAPPY, GZIP und LZO. Der Dienst unterstützt das Lesen von Daten aus Parquet-Dateien in jedem der oben genannten komprimierten Formate mit Ausnahme von LZO. Zum Lesen der Daten wird der Komprimierungscodec in den Metadaten verwendet. Beim Schreiben in eine Parquet-Datei wählt der Dienst hingegen SNAPPY (Standardeinstellung für das Parquet-Format) aus. Derzeit gibt es keine Option zum Überschreiben dieses Verhaltens.
Wichtig
Wenn Sie bei Kopiervorgängen mithilfe einer selbstgehosteten Integration Runtime, z.B. zwischen lokalen Datenspeichern und der Cloud, Parquet-Dateien nicht unverändert kopieren, müssen Sie die 64-Bit-Version der JRE 8 (Java Runtime Environment) oder OpenJDK auf Ihrem IR-Computer installieren. Weitere Details finden Sie im folgenden Absatz.
Für die Kopiervorgänge in der selbstgehosteten Integration Runtime mit Serialisierung/Deserialisierung von Parquet-Dateien sucht der Service die Java Runtime Environment, indem es zunächst die Registrierung (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) auf JRE überprüft. Wird diese nicht gefunden, wird im nächsten Versuch die Systemvariable JAVA_HOME auf OpenJDK überprüft.
- Für JRE: Die 64-Bit-Integration Runtime erfordert die 64-Bit-JRE. Diese steht hier zur Verfügung.
- Für OpenJDK: Die Unterstützung ist seit Version 3.13 der Integration Runtime verfügbar. Packen Sie die Datei „jvm.dll“ zusammen mit allen anderen erforderlichen OpenJDK-Assemblys in einem selbstgehosteten IR-Computer, und legen Sie die Umgebungsvariable JAVA_HOME des Systems entsprechend fest.
Tipp
Wenn Sie Daten mit der selbstgehosteten Integration Runtime in das/aus dem Parquet-Format kopieren und ein Fehler mit dem Text „Fehler beim Aufrufen von Java, Meldung: java.lang.OutOfMemoryError:Java-Heapspeicher“ auftritt, können Sie auf dem Computer, auf dem sich die selbstgehosteten IR befindet, eine Umgebungsvariable _JAVA_OPTIONS hinzufügen, um die min./max. Heapgröße für JVM anzupassen, sodass eine solche Kopie möglich ist, und dann die Pipeline erneut ausführen.
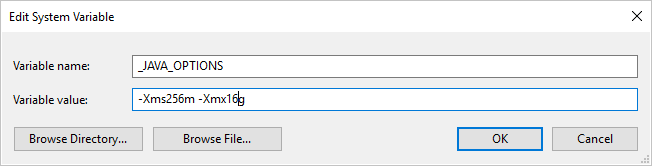
Beispiel: Legen Sie für die Variable _JAVA_OPTIONS den Wert -Xms256m -Xmx16g fest. Das Flag Xms gibt den anfänglichen Speicherzuweisungspool für eine Java Virtual Machine (JVM) an, während Xmx den maximalen Speicherzuweisungspool angibt. Das bedeutet, dass die JVM mit einer Speichergröße von Xms gestartet wird und eine maximale Speichergröße von Xmx verwenden kann. Standardmäßig verwendet der Dienst mindestens 64 MB und höchstens 1 GB.
Datentypzuordnung für Parquet-Dateien
| Zwischendatentyp des Diensts | Primitiver Parquet-Typ | Ursprünglicher Parquet-Typ (Deserialisieren) | Ursprünglicher Parquet-Typ (Serialisieren) |
|---|---|---|---|
| Boolean | Boolean | – | – |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/binär | UInt64 | Decimal |
| Single | Float | – | – |
| Double | Double | – | – |
| Decimal | Binary | Decimal | Decimal |
| String | Binary | Utf8 | Utf8 |
| Datetime | Int96 | – | – |
| TimeSpan | Int96 | – | – |
| DateTimeOffset | Int96 | – | – |
| ByteArray | Binary | – | – |
| Guid | Binary | Utf8 | Utf8 |
| Char | Binary | Utf8 | Utf8 |
| CharArray | Nicht unterstützt | – | – |
ORC-Format (Legacy)
Hinweis
Informationen zum neuen Modell finden Sie im Artikel zum ORC-Format. Die folgenden Konfigurationen für dateibasierte Datenspeicherdatasets werden aus Gründen der Abwärtskompatibilität unverändert unterstützt. Es wird jedoch empfohlen, in Zukunft das neue Modell zu verwenden.
Wenn Sie ORC-Dateien analysieren oder die Daten im ORC-Format schreiben möchten, legen Sie für die formattype-Eigenschaft OrcFormat fest. Sie müssen im Abschnitt „Format“ innerhalb des Abschnitts „typeProperties“ keine Eigenschaften angeben. Beispiel:
"format":
{
"type": "OrcFormat"
}
Beachten Sie folgende Punkte:
- Komplexe Datentypen werden nicht unterstützt (STRUCT, MAP, LIST, UNION).
- Ein Leerzeichen im Spaltennamen wird nicht unterstützt.
- Für die ORC-Datei stehen drei mit der Komprimierung zusammenhängende Optionen zur Verfügung: NONE, ZLIB, SNAPPY. Der Dienst unterstützt das Lesen von Daten aus ORC-Dateien in jedem der oben genannten komprimierten Formate. Zum Lesen der Daten wird der Komprimierungscodec in den Metadaten verwendet. Beim Schreiben in eine ORC-Datei wählt der Dienst hingegen ZLIB (Standardeinstellung für ORC) aus. Derzeit gibt es keine Option zum Überschreiben dieses Verhaltens.
Wichtig
Wenn Sie bei Kopiervorgängen mithilfe einer selbstgehosteten Integration Runtime, z.B. zwischen lokalen Datenspeichern und der Cloud, ORC-Dateien nicht unverändert kopieren, müssen Sie die 64-Bit-Version der JRE 8 (Java Runtime Environment) oder OpenJDK auf Ihrem IR-Computer installieren. Weitere Details finden Sie im folgenden Absatz.
Für die Kopiervorgänge in der selbstgehosteten IR mit Serialisierung/Deserialisierung von ORC-Dateien sucht der Dienst die JRE, indem er zunächst die Registrierung (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) auf JRE überprüft. Wird diese nicht gefunden, wird im nächsten Versuch die Systemvariable JAVA_HOME auf OpenJDK überprüft.
- Für JRE: Die 64-Bit-Integration Runtime erfordert die 64-Bit-JRE. Diese steht hier zur Verfügung.
- Für OpenJDK: Die Unterstützung ist seit Version 3.13 der Integration Runtime verfügbar. Packen Sie die Datei „jvm.dll“ zusammen mit allen anderen erforderlichen OpenJDK-Assemblys in einem selbstgehosteten IR-Computer, und legen Sie die Umgebungsvariable JAVA_HOME des Systems entsprechend fest.
Datentypzuordnung für ORC-Dateien
| Zwischendatentyp des Diensts | ORC-Typen |
|---|---|
| Boolean | Boolean |
| SByte | Byte |
| Byte | Short |
| Int16 | Short |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Long |
| Int64 | Long |
| UInt64 | String |
| Single | Float |
| Double | Double |
| Decimal | Decimal |
| String | String |
| Datetime | Timestamp |
| DateTimeOffset | Timestamp |
| TimeSpan | Timestamp |
| ByteArray | Binary |
| Guid | String |
| Char | Char(1) |
Avro-Format (Legacy)
Hinweis
Informationen zum neuen Modell finden Sie im Artikel zum AVRO-Format. Die folgenden Konfigurationen für dateibasierte Datenspeicherdatasets werden aus Gründen der Abwärtskompatibilität unverändert unterstützt. Es wird jedoch empfohlen, in Zukunft das neue Modell zu verwenden.
Wenn Sie Avro-Dateien analysieren oder die Daten im Avro-Format schreiben möchten, legen Sie für die formattype-Eigenschaft AvroFormat fest. Sie müssen im Abschnitt „Format“ innerhalb des Abschnitts „typeProperties“ keine Eigenschaften angeben. Beispiel:
"format":
{
"type": "AvroFormat",
}
Um das Avro-Format in einer Hive-Tabelle zu verwenden, sehen Sie sich zuvor das Apache Hive-Tutorial an.
Beachten Sie folgende Punkte:
- Komplexe Datentypen werden nicht unterstützt (Datensätze, Enumerationen, Arrays, Zuordnungen, Unions und Konstanten).
Unterstützung der Komprimierung (Legacy)
Der Dienst unterstützt das Komprimieren und Dekomprimieren während des Kopiervorgangs. Wenn Sie die compression-Eigenschaft in einem Eingabedataset angeben, kann die Kopieraktivität die komprimierten Daten aus der Quelle lesen und dekomprimieren. Bei Angabe der Eigenschaft in einem Ausgabedataset kann die Kopieraktivität Daten erst komprimieren und dann in die Senke schreiben. Es folgen einige Beispielszenarios:
- Lesen Sie GZIP-komprimierte Daten aus einem Azure-Blob, dekomprimieren Sie sie, und schreiben Sie die resultierenden Daten in Azure SQL-Datenbank. Sie definieren das Azure-Blob-Eingabedataset mit der
compressiontype-Eigenschaft als GZIP. - Lesen Sie Daten aus einer Nur-Text-Datei aus einem lokalen Dateisystem, komprimieren Sie sie mithilfe des GZip-Formats, und schreiben Sie die komprimierten Daten in einen Azure-Blob. Sie definieren ein Azure-Blob-Ausgabedataset mit der
compressiontype-Eigenschaft als GZip. - Lesen Sie die ZIP-Datei vom FTP-Server, dekomprimieren Sie sie, um die Dateien zu extrahieren, und stellen Sie die Dateien in Azure Data Lake Store bereit. Sie definieren ein FTP-Eingabedataset mit der
compressiontype-Eigenschaft als ZipDeflate. - Lesen Sie GZIP-komprimierte Daten aus einem Azure-Blob, dekomprimieren Sie sie, komprimieren Sie sie mit BZIP2, und schreiben Sie die resultierenden Daten in einen Azure-Blob. Sie definieren das Azure-Blob-Eingabedataset mit Einstellung von
compressiontypeauf GZIP und das Ausgabedataset mit Einstellung voncompressiontypeauf BZIP2.
Um die Komprimierung für ein Dataset anzugeben, verwenden Sie im JSON-Dataset die Eigenschaft für die Komprimierung wie im folgenden Beispiel:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Der Abschnitt für die Komprimierung enthält zwei Eigenschaften:
Typ: Der Komprimierungscodec, z.B. GZIP, Deflate, BZIP2 oder ZipDeflate. Hinweis: Bei der Verwendung der Kopieraktivität zum Dekomprimieren einer oder mehrerer ZipDeflate-Dateien und zum Schreiben in den dateibasierten Senkendatenspeicher werden Dateien in den folgenden Ordner extrahiert:
<path specified in dataset>/<folder named as source zip file>/.Ebene: Das Komprimierungsverhältnis, z.B. Optimal oder Schnellstes.
Schnellstes: Der Komprimierungsvorgang wird schnellstmöglich abgeschlossen, auch wenn die resultierende Datei nicht optimal komprimiert ist.
Optimal: Die Daten sollten optimal komprimiert sein, auch wenn der Vorgang eine längere Zeit in Anspruch nimmt.
Weitere Informationen finden Sie im Thema Komprimierungsstufe .
Hinweis
Für Daten im AvroFormat, OrcFormat oder ParquetFormat werden keine Komprimierungseinstellungen unterstützt. Beim Lesen der Daten in diesen Formaten erkennt und verwendet der Dienst den Komprimierungscodec in den Metadaten. Für das Schreiben in Dateien in diesen Formaten wählt der Dienst den Standardkomprimierungscodec für das jeweilige Format aus. Beispiel: ZLIB für OrcFormat und SNAPPY für ParquetFormat.
Nicht unterstützte Dateitypen und Komprimierungsformate
Sie können mit den Erweiterbarkeitsfunktionen Dateien transformieren, die nicht unterstützt werden. Zwei Optionen sind Azure Functions und benutzerdefinierte Aufgaben mithilfe von Azure Batch.
Sehen Sie sich ein Beispiel an, in dem mithilfe einer Azure-Funktion der Inhalt einer tar-Datei extrahiert wird. Weitere Informationen finden Sie unter Aktivität „Azure Function“ in Azure Data Factory.
Sie können diese Funktionalität auch mit einer benutzerdefinierten Dotnet-Aktivität erstellen. Weitere Informationen sind hier verfügbar.
Zugehöriger Inhalt
Informationen zu den aktuell unterstützten Dateiformaten und Komprimierungen finden Sie unter Unterstützte Dateiformate und Komprimierungen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für