Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Logic Apps (Verbrauch + Standard)
Die Art und Weise, wie eine Integrationsarchitektur Ausfallzeiten oder Probleme aufgrund von abhängigen Systemen behandelt, kann eine Herausforderung darstellen. Damit Sie stabile und robuste Integrationen erstellen können, bei denen Probleme und Fehler korrekt behandelt werden, verfügt Azure Logic Apps über eine professionelle Benutzeroberfläche für den Umgang mit Fehlern und Ausnahmen.
Wiederholungsrichtlinien
Für die einfachste Ausnahme und Fehlerbehandlung können Sie die Wiederholungsrichtlinie verwenden, wenn diese Funktion für einen Trigger oder eine Aktion vorhanden ist, z. B. die HTTP-Aktion. Wenn die ursprüngliche Anforderung des Triggers oder der Aktion veraltet ist oder fehlschlägt, was zu einer Antwort 408, 429 oder 5xx führt, gibt die Wiederholungsrichtlinie mittels Richtlinieneinstellungen an, dass der Trigger oder die Aktion die Anforderung erneut senden soll.
Wiederholungsrichtlinienlimits
Weitere Informationen zu Wiederholungsrichtlinien, Einstellungen, Grenzwerten und anderen Optionen, finden Sie unter Grenzwerte von Wiederholungsrichtlinien.
Typen von Wiederholungsrichtlinien
Connectorvorgänge, die Wiederholungsrichtlinien unterstützen, verwenden die Standardrichtlinie, es sei denn, Sie wählen eine andere Wiederholungsrichtlinie aus.
| Wiederholungsrichtlinie | BESCHREIBUNG |
|---|---|
| Standard | Für die meisten Vorgänge ist die Standardwiederholungsrichtlinie eine Richtlinie mit exponentiellem Intervall, die bis zu vier Wiederholungsversuche mit exponentiell wachsenden Intervallen sendet. Diese Intervalle werden um 7,5 Sekunden skaliert, aber auf einen Wert zwischen 5 und 45 Sekunden begrenzt. Mehrere Vorgänge verwenden eine andere Standardwiederholungsrichtlinie, z. B. eine Richtlinie mit festem Intervall. Weitere Informationen hierzu finden Sie unter Wiederholungsrichtlinientyp „Standard“. |
| None | Die Anforderung wird nicht erneut gesendet. Weitere Informationen hierzu finden Sie unter Keine: Keine Wiederholungsrichtlinie. |
| Exponentielles Intervall | Diese Richtlinie wartet für den Zeitraum eines zufälligen Intervalls, das aus einem exponentiell wachsenden Bereich ausgewählt wird, bevor die nächste Anforderung gesendet wird. Weitere Informationen hierzu finden Sie unter Richtlinientyp „Exponentielles Intervall“. |
| Festes Intervall | Bei dieser Richtlinie wird für den Zeitraum des angegebenen Intervalls gewartet, bevor die nächste Anforderung gesendet wird. Weitere Informationen hierzu finden Sie unter „ „Festes Intervall“. |
Ändern des Wiederholungsrichtlinientyps im Designer
Öffnen Sie Ihre Logik-App-Ressource im Azure-Portal.
Führen Sie auf der Ressourcen-Randleiste die folgenden Schritte aus, um den Workflow-Designer basierend auf Ihrer Logik-App zu öffnen:
Verbrauch: Wählen Sie unter "Entwicklungstools" den Designer aus, um Ihren Workflow zu öffnen.
Standard
Wählen Sie unter WorkflowsWorkflows aus.
Wählen Sie auf der Seite "Workflows " Ihren Workflow aus.
Wählen Sie unter "Extras" den Designer aus, um Ihren Workflow zu öffnen.
Führen Sie auf dem Auslöser oder der Aktion, in dem Sie den Typ der Wiederholungsrichtlinie ändern möchten, die folgenden Schritte aus, um die Einstellungen zu öffnen:
Wählen Sie im Designer den Vorgang aus.
Wählen Sie im Bereich "Vorgangsinformationen " die Option "Einstellungen" aus.
Wählen Sie unter Netzwerk in der Erneute Versuchsrichtlinie den gewünschten Richtlinientyp aus.
Ändern des Wiederholungsrichtlinientyps im Codeansichts-Editor
Vergewissern Sie sich, ob der Trigger oder die Aktion Wiederholungsrichtlinien unterstützt, indem Sie die vorherigen Schritte im Designer ausführen.
Öffnen Sie Ihren Logik-App-Workflow im Codeansichts-Editor.
Fügen Sie in der Trigger- oder Aktionsdefinition das
retryPolicyJSON-Objekt zum Trigger- oder Aktionsobjektinputshinzu. Wenn keinretryPolicyObjekt vorhanden ist, verwendet der Trigger oder die Aktion diedefaultWiederholungsrichtlinie."inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}Erforderlich
Eigenschaft Wert type Beschreibung type<Retry-Richtlinientyp> String Der Wiederholungsrichtlinientyp, den Sie verwenden möchten: default,none,fixedoderexponential.count<Wiederholungsversuche> Integer Für die Richtlinientypen fixedundexponentialdie Anzahl der Wiederholungsversuche, wobei es sich um einen Wert von 1–90 handelt. Weitere Informationen finden Sie unter Festes Intervall und Exponentielles Intervall.interval<Wiederholungsintervall> String Für die Richtlinientypen fixedundexponentialder Wert des Wiederholungsintervalls im ISO 8601-Format. Für dieexponential-Richtlinie können Sie auch optionale Höchst- und Mindestintervalle angeben. Weitere Informationen finden Sie unter Festes Intervall und Exponentielles Intervall.
Verbrauch: 5 Sekunden (PT5S) bis 1 Tag (P1D).
Standard: Für zustandsbehaftete Workflows, 5 Sekunden (PT5S) bis 1 Tag (P1D). Für zustandslose Workflows, 1 Sekunde (PT1S) bis 1 Minute (PT1M).Optional
Eigenschaft Wert type BESCHREIBUNG maximumInterval<Maximales Intervall> String Für die exponential-Richtlinie das größte Intervall für das zufällig ausgewählte Intervall im ISO 8601-Format. Der Standardwert ist 1 Tag (P1D). Weitere Informationen finden Sie unter Exponentielles Intervall.minimumInterval<Mindestintervall> String Für die exponential-Richtlinie das kleinste Intervall für das zufällig ausgewählte Intervall im ISO 8601-Format. Der Standardwert ist 5 Sekunden (PT5S). Weitere Informationen finden Sie unter Exponentielles Intervall.
Standard-Wiederholungsrichtlinie
Connectorvorgänge, die Wiederholungsrichtlinien unterstützen, verwenden die Standardrichtlinie, es sei denn, Sie wählen eine andere Wiederholungsrichtlinie aus. Für die meisten Vorgänge ist die Standardwiederholungsrichtlinie eine Richtlinie mit exponentiellem Intervall, die bis zu vier Wiederholungsversuche mit exponentiell wachsenden Intervallen sendet. Diese Intervalle werden um 7,5 Sekunden skaliert, aber auf einen Wert zwischen 5 und 45 Sekunden begrenzt. Mehrere Vorgänge verwenden eine andere Standardwiederholungsrichtlinie, z. B. eine Richtlinie mit festem Intervall.
In Ihrer Workflowdefinition definiert die Trigger- oder Aktionsdefinition nicht explizit die Standardrichtlinie, aber das folgende Beispiel zeigt, wie sich die Standardwiederholungsrichtlinie für die HTTP-Aktion verhält:
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
Keine – Keine Wiederholungsrichtlinie
Um anzugeben, dass die Aktion bzw. der Trigger für fehlgeschlagene Anforderungen keine Wiederholungsversuche durchführen soll, legen Sie <retry-policy-type> auf none fest.
Wiederholungsrichtlinie mit festem Intervall
Um anzugeben, dass die Aktion bzw. der Trigger für den Zeitraum des angegebenen Intervalls wartet, bevor die nächste Anforderung gesendet wird, legen Sie <retry-policy-type> auf fixed fest.
Beispiel
Bei dieser Wiederholungsrichtlinie wird zwei weitere Male versucht, die aktuellen Neuigkeiten abzurufen, nachdem die erste Anforderung fehlgeschlagen ist, und zwischen den Versuchen wird jeweils eine Verzögerung von 30 Sekunden verwendet:
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
Wiederholungsrichtlinie mit exponentiellem Intervall
Die Wiederholungsrichtlinie mit exponentiellem Intervall gibt an, dass der Trigger oder die Aktion ein zufälliges Intervall wartet, bevor die nächste Anforderung gesendet wird. Das zufällige Intervall wird aus einem exponentiell wachsenden Bereich ausgewählt. Optional können Sie die standardmäßigen Mindest- und Höchstintervalle außer Kraft setzen, indem Sie ihre eigenen Mindest- und Höchstintervalle angeben, basierend darauf, ob Sie über einen Verbrauchs- oder Standard-Logik-App-Workflow verfügen.
| Name | Grenzwert für „Verbrauch“ | Grenzwert für „Standard“ | Notizen |
|---|---|---|---|
| Minimale Verzögerung | Standardwert: 1 Tag | Standardwert: 1 Stunde | Verwenden Sie zum Ändern des Standardgrenzwerts in einem Logik-App-Verbrauchsworkflow den Wiederholungsrichtlinienparameter. Informationen zum Ändern des Standardgrenzwerts in einem Logik-App-Standardworkflow finden Sie unter Bearbeiten von Einstellungen für Hosts und Apps für Logik-Apps in Azure Logic Apps-Instanzen mit einem einzelnen Mandanten. |
| Minimale Verzögerung | Standardwert: 5 Sekunden | Standardwert: 5 Sekunden | Verwenden Sie zum Ändern des Standardgrenzwerts in einem Logik-App-Verbrauchsworkflow den Wiederholungsrichtlinienparameter. Informationen zum Ändern des Standardgrenzwerts in einem Logik-App-Standardworkflow finden Sie unter Bearbeiten von Einstellungen für Hosts und Apps für Logik-Apps in Azure Logic Apps-Instanzen mit einem einzelnen Mandanten. |
Bereiche der Zufallsvariablen
In der folgenden Tabelle wird für die Wiederholungsrichtlinie mit exponentiellem Intervall der allgemeine Algorithmus gezeigt, den Azure Logic Apps verwendet, um eine einheitliche Zufallsvariable im angegebenen Bereich für jede Wiederholung zu generieren. Der angegebene Bereich kann bis zur Anzahl der Wiederholungen gehen oder diese auch einschließen.
| Wiederholungsanzahl | Minimales Intervall | Maximales Intervall |
|---|---|---|
| 1 | max(0, <Minimum-Interval>) | min(Intervall, <Maximum-Intervall>) |
| 2 | max(interval, <minimum-interval>) | min(2 * interval, <maximum-interval>) |
| 3 | max(2 * Intervall, <Mindestintervall>) | min(4 * interval, <maximum-interval>) |
| 4 | max(4 * Intervall, <Mindestintervall>) | min(8 * interval, <Maximalintervall>) |
| .... | .... | .... |
Verwalten des Verhaltens „Ausführen nach“
Wenn Sie aktionen im Workflow-Designer hinzufügen, deklarieren Sie implizit die Sequenz für die Ausführung dieser Aktionen. Sobald die Ausführung einer Aktion abgeschlossen ist, wird diese Aktion mit einem der folgenden Status markiert: Erfolgreich (Succeeded), Fehlgeschlagen (Failed), Übersprungen (Skipped) oder Timeout (TimedOut). Mit anderen Worten, die Vorgängeraktion muss zuerst mit einem der zulässigen Status abgeschlossen werden, bevor die Nachfolgeaktion ausgeführt werden kann.
Standardmäßig wird eine Aktion, die Sie im Designer hinzufügen, nur ausgeführt, wenn die vorherige Aktion mit dem Status "Erfolgreich" abgeschlossen ist. Dieses Verhalten Ausführen nach gibt die Ausführungsreihenfolge der Aktionen in einem Workflow genau an.
Im Designer können Sie das Standardverhalten "Ausführen nach" für eine Aktion ändern, indem Sie die Einstellung 'Ausführen nach' der Aktion bearbeiten. Diese Einstellung ist nur für nachfolgende Aktionen verfügbar, die der ersten Aktion in einem Workflow folgen. Die erste Aktion in einem Workflow wird immer ausgeführt, nachdem der Trigger erfolgreich ausgeführt wurde. Die Einstellung Ausführen nach ist also für die erste Aktion nicht verfügbar und gilt nicht für sie.
In der zugrunde liegenden JSON-Definition einer Aktion entspricht die Einstellung Ausführen nach der runAfter-Eigenschaft. Diese Eigenschaft gibt eine oder mehrere Vorgängeraktionen an, die zuerst mit einem der spezifisch zugelassenen Status abgeschlossen werden müssen, bevor die Folgeaktion ausgeführt werden kann. Die runAfter Eigenschaft ist ein JSON-Objekt, das Flexibilität bietet, indem Sie alle Vorgängeraktionen angeben können, die abgeschlossen werden müssen, bevor die Nachfolgeraktion ausgeführt wird. Dieses Objekt definiert auch ein Array zulässiger Status.
Wenn eine Aktion beispielsweise ausgeführt werden soll, nachdem aktion A erfolgreich ausgeführt wurde und auch die Aktion B erfolgreich ist oder fehlschlägt, wenn Sie an der JSON-Definition einer Aktion arbeiten, richten Sie die folgende runAfter Eigenschaft ein:
{
// Other parts in action definition
"runAfter": {
"Action A": ["Succeeded"],
"Action B": ["Succeeded", "Failed"]
}
}
Verhalten „Ausführen nach“ für die Fehlerbehandlung
Wenn eine Aktion einen nicht behandelten Fehler oder eine nicht behandelte Ausnahme auslöst, wird die Aktion als Fehlgeschlagen markiert, und alle nachfolgenden Aktionen mit Übersprungen. Wenn dieses Verhalten bei einer Aktion mit parallelen Branches auftritt, folgt die Azure Logic Apps-Engine den anderen Branches, um deren Abschlussstatus zu ermitteln. Wenn ein Branch beispielsweise mit einer Übersprungen-Aktion endet, hängt der Abschlussstatus dieses Branchs vom Status der Aktion ab, die vor dieser übersprungenen Aktion ausgeführt wurde. Nachdem die Ausführung des Workflows abgeschlossen wurde, ermittelt die Engine den Status der gesamten Ausführung, indem die Status aller Branches ausgewertet werden. Wenn irgendein Branch zu einem Fehler geführt hat, wird die gesamte Ausführung des Workflows als Fehlgeschlagen markiert.

Um sicherzustellen, dass eine Aktion unabhängig vom Status ihrer Vorgängeraktion ausgeführt werden kann, können Sie das Verhalten „Ausführen nach“ einer Aktion anpassen, sodass die nicht erfolgreichen Status der zuvor ausgeführten Aktionen behandelt werden können. Auf diese Weise wird die Aktion ausgeführt, wenn der Status des Vorgängers Erfolgreich, Fehlgeschlagen, Übersprungen, TimedOut oder alle diese Status ist.
Wenn Sie z. B. die Office 365 Outlook-Aktion E-Mail senden ausführen möchten, nachdem die vorangegangene Excel Online-Aktion Zeile in Tabelle einfügen als Fehlgeschlagen gekennzeichnet wurde anstatt als Erfolgreich, ändern Sie das „Ausführen nach“-Verhalten, indem Sie entweder den Designer oder den Codeansichts-Editor verwenden.
Ändern des „Ausführen nach“-Verhaltens im Designer
Öffnen Sie Ihre Logik-App-Ressource im Azure-Portal.
Führen Sie auf der Ressourcen-Randleiste die folgenden Schritte aus, um den Workflow-Designer basierend auf Ihrer Logik-App zu öffnen:
Verbrauch: Wählen Sie unter "Entwicklungstools" den Designer aus, um Ihren Workflow zu öffnen.
Standard
Wählen Sie auf der Ressourcen-Seitenleiste unter Workflows die Option Workflows aus.
Wählen Sie auf der Seite "Workflows " Ihren Workflow aus.
Wählen Sie unter "Extras" den Designer aus, um Ihren Workflow zu öffnen.
Führen Sie auf dem Trigger oder der Aktion, in dem bzw. der Sie das Verhalten für „Ausführen nach“ ändern möchten, die folgenden Schritte aus, um die Einstellungen des Vorgangs zu öffnen:
Wählen Sie im Designer den Vorgang aus.
Wählen Sie im Bereich "Vorgangsinformationen " die Option "Einstellungen" aus.
Der Abschnitt "Ausführen nach " enthält eine Liste mit "Aktionen auswählen ", in der die verfügbaren Vorgängervorgänge für den aktuell ausgewählten Vorgang angezeigt werden, z. B.:
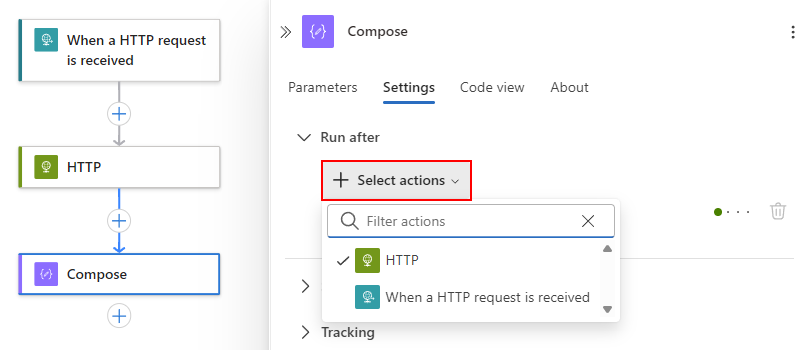
Erweitern Sie unter der Liste "Aktionen auswählen " den aktuellen Vorgängervorgang, bei dem es sich um HTTP in diesem Beispiel handelt:
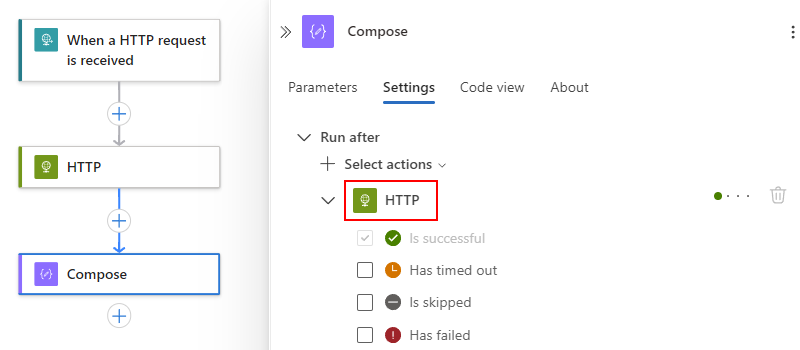
Standardmäßig ist der Status von „Ausführen nach“ auf ist erfolgreich festgelegt. Dieser Wert bedeutet, dass der Vorgängervorgang erfolgreich abgeschlossen werden muss, bevor die aktuelle Aktion ausgeführt werden kann.
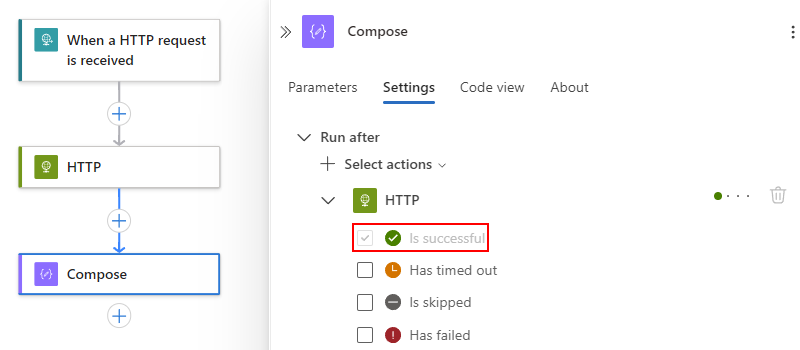
Wenn Sie das Verhalten „Ausführen nach“ in gewünschte Status ändern möchten, wählen Sie diese Status aus.
Im folgenden Beispiel wird ist fehlerhaft ausgewählt.
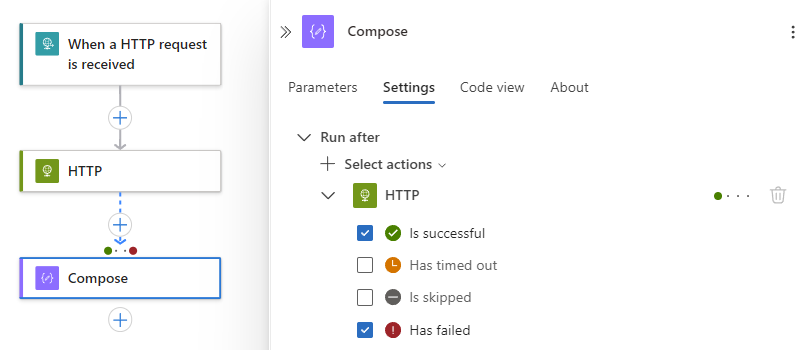
Um anzugeben, dass der aktuelle Vorgang nur ausgeführt wird, wenn die Vorgängeraktion mit dem Status "Fehlgeschlagen", " Übersprungen" oder " Hat Timeout " abgeschlossen ist, wählen Sie diese Status aus, und deaktivieren Sie dann den Standardstatus, z. B.:
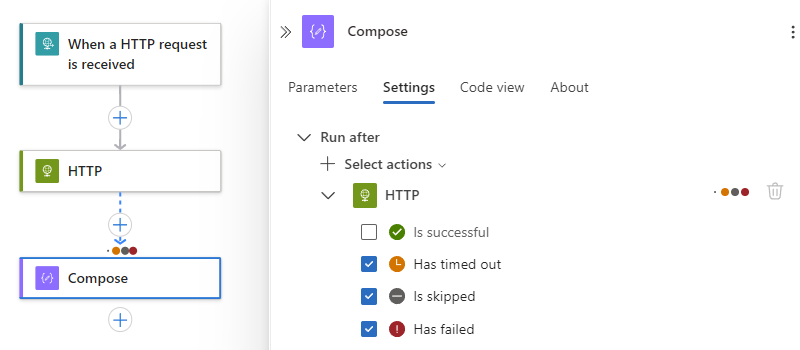
Hinweis
Bevor Sie den Standardstatus löschen, stellen Sie sicher, dass Sie zuerst einen anderen Status auswählen. Sie müssen immer mindestens einen Status ausgewählt haben.
Um festzulegen, dass mehrere Vorgängervorgänge ausgeführt und abgeschlossen werden müssen, wobei jeder seinen eigenen Status „Ausführen nach“ hat, führen Sie die folgenden Schritte aus:
Öffnen Sie die Liste "Aktionen auswählen ", und wählen Sie die gewünschten Vorgängervorgänge aus.
Wählen Sie die „Ausführen nach“-Status für jeden Vorgang aus.
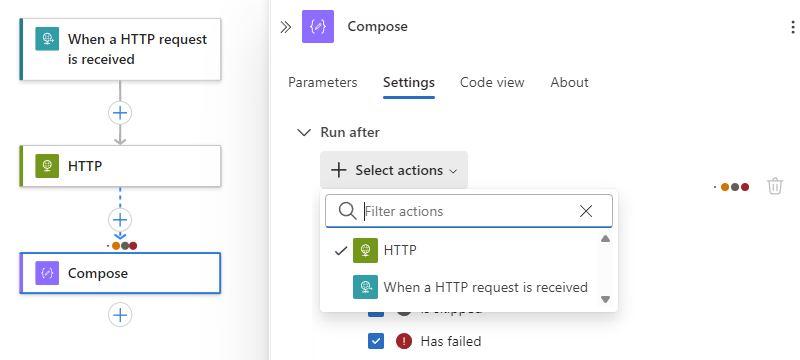
Wenn Sie fertig sind, schließen Sie den Vorgangsinformationsbereich.






Ändern des „Ausführen nach“-Verhaltens im Codeansichts-Editor
Führen Sie auf der Ressourcen-Randleiste die folgenden Schritte aus, um den Codeansicht-Editor basierend auf Ihrer Logik-App zu öffnen:
Verbrauch: Wählen Sie unter "Entwicklungstools" die Codeansicht aus, um Ihren Workflow im JSON-Editor zu öffnen.
Standard
Wählen Sie unter WorkflowsWorkflows aus.
Wählen Sie auf der Seite "Workflows " Ihren Workflow aus.
Wählen Sie unter "Tools" die Codeansicht aus, um Ihren Workflow im JSON-Editor zu öffnen.
Bearbeiten Sie in der JSON-Definition der Aktion die Eigenschaft
runAfter, die folgende Syntax aufweist:"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }Ändern Sie für dieses Beispiel die
runAfter-Eigenschaft vonSucceededinFailed:"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }Wenn Sie angeben möchten, dass die Aktion ausgeführt wird, wenn die Vorgängeraktion als
Failed,SkippedoderTimedOutmarkiert ist, fügen Sie die anderen Status hinzu:"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
Auswerten von Aktionen mit Bereichen und ihren Ergebnissen
Ähnlich wie beim Ausführen von Schritten nach einzelnen Aktionen mit der „Ausführen nach“-Eigenschaft können Sie Aktionen innerhalb eines Bereichs (scope) gruppieren. Sie können Bereiche verwenden, wenn Sie Aktionen logisch gruppieren, den Aggregatstatus des Bereichs feststellen und basierend auf diesem Status Aktionen ausführen möchten. Nachdem die Ausführung aller Aktionen in einem Bereich beendet ist, erhält der Bereich selbst seinen eigenen Status.
Zum Überprüfen des Status eines Bereichs können Sie die gleichen Kriterien wie zum Überprüfen des Ausführungsstatus eines Workflows verwenden, z. B. Erfolgreich, Fehlerhaft usw.
Bei erfolgreicher Ausführung aller Aktionen des Bereichs wird der Status des Bereichs als Erfolgreich gekennzeichnet. Wenn die letzte Aktion in einem Bereich als Fehlerhaft oder Abgebrochen markiert wird, wird der Status des Bereichs als Fehlerhaft gekennzeichnet.
Zum Abfangen von Ausnahmen in einem als Fehlerhaft gekennzeichneten Bereich und zum Ausführen von Aktionen, die diese Fehler behandeln, können Sie die „Ausführen nach“-Einstellung dieses Fehlerhaften Bereichs verwenden. Auf diese Weise können Sie, wenn eine beliebige Aktion im Bereich fehlschlägt, und Sie die „Ausführen nach“-Einstellung für diesen Bereich verwenden, eine einzelne Aktion zum Abfangen von Fehlern erstellen.
Grenzwerte für Bereiche finden Sie unter Grenzwerte und Konfiguration.
Einrichten eines Bereichs mit „Ausführen nach“ für die Ausnahmebehandlung
Öffnen Sie im Azure-Portal Ihre Logik-App-Ressource und den Workflow im Designer.
Ihr Workflow muss bereits über einen Trigger verfügen, der den Workflow startet.
Führen Sie im Designer diese allgemeinen Schritte aus, um eine Steuerungsaktion vom Typ Bereichsaktion hinzuzufügen.
Führen Sie in der Bereichsaktion diese allgemeinen Schritte aus, um die auszuführenden Aktionen hinzuzufügen, z. B.:

In der folgenden Liste sind einige Beispielaktionen aufgeführt, die Sie in eine Bereichsaktion einschließen können:
- Rufen Sie Daten von einer API ab.
- Verarbeiten Sie die Daten.
- Speichern Sie die Daten in einer Datenbank.
Definieren Sie nun die Regeln für „Ausführen nach“ zum Ausführen der Aktionen im Bereich.
Wählen Sie im Designer den Titel Bereich aus. Wenn der Informationsbereich für den Bereich geöffnet wird, wählen Sie Einstellungen aus.
Wenn im Workflow mehrere Vorgängeraktionen ausgeführt werden, wählen Sie in der Liste Aktionen auswählen die Aktion aus, nach der Sie die Bereichsaktionen ausführen möchten.
Wählen Sie für die ausgewählte Aktion alle Aktionsstatus aus, bei denen die Bereichsaktionen ausgeführt werden.
Mit anderen Worten. Jeder der ausgewählten Status, die aus der ausgewählten Aktion resultieren, führt dazu, dass die Aktionen im Bereich ausgeführt werden.
Im folgenden Beispiel werden die Bereichsaktionen ausgeführt, nachdem die HTTP-Aktion mit einem der ausgewählten Status abgeschlossen wurde:

Abrufen von Kontext und Ergebnissen auf Fehler
Das Abfangen der Fehler aus einem Bereich ist zwar nützlich, doch häufig wäre auch mehr Kontext hilfreich, um genau zu verstehen, welche Aktionen fehlgeschlagen und welche Fehler aufgetreten sind bzw. welche Statuscodes zurückgegeben wurden. Die result()-Funktion gibt die Ergebnisse der Aktionen auf oberster Ebene in einer bereichsbezogenen Aktion zurück. Diese Funktion akzeptiert den Namen des Bereichs als einzelnen Parameter und gibt ein Array mit den Ergebnissen dieser Aktionen auf oberster Ebene zurück. Diese Aktionsobjekte besitzen dieselben Attribute, die auch von der actions()-Funktion zurückgegeben werden, z. B. Start- und Endzeit der Aktion, Status, Eingaben, Korrelations-IDs und Ausgaben.
Hinweis
Die result()-Funktion gibt nur die Ergebnisse der Aktionen der obersten Ebene zurück, keine aus tiefer geschachtelten Aktionen wie Schalter- oder Bedingungsaktionen (switch/condition).
Um Kontextinformationen zu den in einem Bereich fehlgeschlagenen Aktionen zu erhalten, können Sie den @result()-Ausdruck mit dem Namen des Bereichs und der „Ausführen nach“-Einstellung verwenden. Um das zurückgegebene Array nach Aktionen zu filtern, die den Status Fehlgeschlagen aufweisen, können Sie die Aktion Array filtern hinzufügen. Zum Ausführen einer Aktion für eine zurückgegebene Aktion, bei der ein Fehler aufgetreten ist, wenden Sie eine For each-Schleife auf das zurückgegebene gefilterte Array an.
Das folgende JSON-Beispiel sendet eine HTTP POST-Anforderung mit dem Antworttext für alle fehlgeschlagenen Aktionen in der Bereichsaktion My_Scope. Auf das Beispiel folgt eine detaillierte Erklärung.
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
Die folgenden Schritte beschreiben, was in diesem Beispiel geschieht:
Um das Ergebnis aller Aktionen in My_Scope abzurufen, wird für die Aktion Array filtern dieser Filterausdruck verwendet:
@result('My_Scope').Die Bedingung für Array filtern ist ein beliebiges
@result()-Element, dessen StatusFailedlautet. Mit dieser Bedingung wird das Array mit allen Aktionsergebnissen aus My_Scope bis hinab zu einem Array gefiltert, dass nur die fehlerhaften Aktionen als Ergebnisse enthält.Führen Sie eine
For_each-Schleifenaktion für die Ausgaben gefilterter Arrays aus. In diesem Schritt wird eine Aktion für jedes Ergebnis einer fehlgeschlagenen Aktion durchgeführt, das zuvor gefiltert wurde.Wenn eine einzelne Aktion im Bereich fehlgeschlagen ist, werden die Aktionen in der
For_each-Schleife nur einmal ausgeführt. Mehrere Aktionen mit Fehler lösen eine Aktion pro Fehler aus.Senden Sie HTTP POST für den
For_each-Elementantworttext. Dies ist der Ausdruck@item()['outputs']['body'].Die
@result()-Elementform ist mit der@actions()-Form identisch und kann auch genauso analysiert werden.Binden Sie zwei benutzerdefinierte Header mit dem Namen der fehlerhaften Aktion (
@item()['name']) und der Clientnachverfolgungs-ID der fehlerhaften Ausführung (@item()['clientTrackingId']) ein.
Zu Referenzzwecken ist hier ein Beispiel für ein einzelnes @result()-Element angegeben, das die Eigenschaften name, body und clientTrackingId enthält, die im vorherigen Beispiel analysiert werden. Außerhalb einer For_each-Aktion, gibt @result() ein Array dieser Objekte zurück.
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
Sie können die oben in diesem Artikel beschriebenen Ausdrücke verwenden, um unterschiedliche Muster für die Ausnahmebehandlung zu nutzen. Außerdem können Sie die Entscheidung treffen, eine einzelne Aktion für die Ausnahmebehandlung außerhalb des Bereichs durchzuführen, bei der das gesamte gefilterte Array mit Fehlern akzeptiert wird, und die For_each-Aktion zu entfernen. Darüber hinaus können Sie noch andere nützliche Eigenschaften aus der \@result()-Antwort einfügen, wie zuvor beschrieben.
Einrichten von Azure Monitor-Protokollen
Die vorherigen Muster sind nützliche Methoden zum Behandeln von Fehlern und Ausnahmen, die innerhalb einer Ausführung auftreten. Sie können jedoch auch Fehler identifizieren und darauf reagieren, die unabhängig von der Ausführung auftreten. Sie können die Protokolle und Metriken für Ihre Ausführungen überwachen oder mit einem von Ihnen bevorzugten Überwachungstool veröffentlichen, um jeweils den Ausführungsstatus auszuwerten.
Beispielsweise bietet Azure Monitor eine optimierte Möglichkeit zum Senden aller Workflowereignisse, einschließlich aller Ausführungs- und Aktionsstatus, an ein Ziel. Sie können Warnungen für bestimmte Metriken und Schwellenwerte in Azure Monitor einrichten. Sie können Workflowereignisse auch an einen Log Analytics-Arbeitsbereich oder ein Azure-Speicherkonto senden. Sie können auch alle Ereignisse über Azure Event Hubs in Azure Stream Analytics streamen. In Stream Analytics können Sie Liveabfragen auf der Grundlage von Anomalien, Mittelwerten oder Fehlern aus den Diagnoseprotokollen schreiben. Sie können Stream Analytics zum Senden von Informationen an andere Datenquellen verwenden, etwa an Warteschlangen, Themen, SQL, Azure Cosmos DB oder Power BI.
Weitere Informationen finden Sie unter Einrichten von Azure Monitor-Protokollen und Sammeln von Diagnosedaten für Azure Logic Apps.